






在自然语言处理(NLP)领域,模型微调(Fine-Tuning)是提升预训练模型在特定任务上表现的关键步骤。本文将详细介绍如何使用 Hugging Face Transformers 库进行模型微调训练,涵盖数据集下载、数据预处理、训练配置、评估、训练过程以及模型保存。我们将以 YelpReviewFull 数据集为例,逐步带您完成模型微调训练的整个过程。
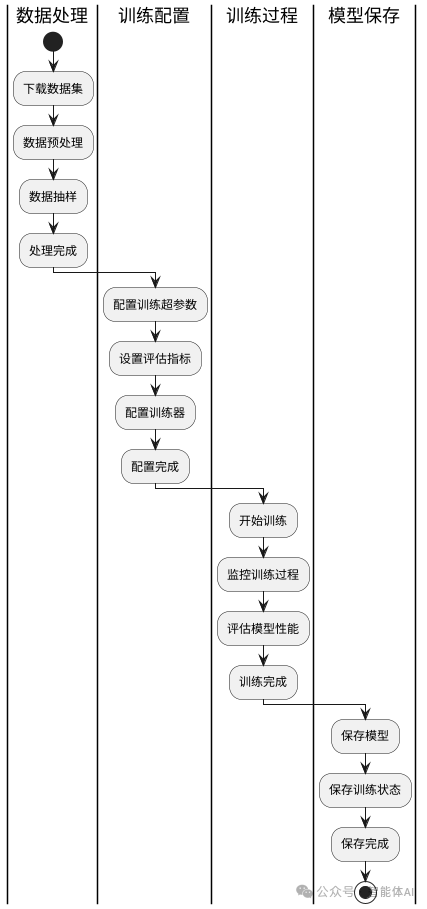
一、数据集下载
1.1 获取 YelpReviewFull 数据集
YelpReviewFull 数据集是一个经典的情感分析数据集,包含了大量来自 Yelp 的评论。数据集从 Yelp Dataset Challenge 2015 数据中提取,主要用于文本分类任务,目标是预测评论的情感分数。数据集的评论主要用英语编写,适合进行情感分类研究。
1.2 数据集结构与实例
数据集包含两个主要字段:
-
text: 评论的文本内容。
-
label: 评论的情感标签,范围从 1 到 5。
例如,一个典型的数据点如下:
{
'label': 0,
'text': 'I got \'new\' tires from them and within two weeks got a flat...'
}
1.3 数据拆分
数据集的总量为 700,000 条记录,其中包括 650,000 个训练样本和 50,000 个测试样本。在实际操作中,我们通常会将数据集随机拆分为训练集和测试集。例如,我们可以选择 130,000 个训练样本和 10,000 个测试样本用于模型训练和评估。
1.4 下载数据集代码
可以使用 Hugging Face 的 datasets 库来下载数据集:
from datasets import load_dataset
# 下载 YelpReviewFull 数据集
dataset = load_dataset("yelp_review_full")
二、数据预处理
2.1 数据预处理步骤
下载数据集后,我们需要对文本数据进行预处理,以便于模型的训练。预处理包括将文本转换为模型可以接受的输入格式。通常,我们使用 Tokenizer 对文本进行编码,并进行填充(padding)和截断(truncation)。
以下代码展示了如何使用 BERT Tokenizer 对数据集进行预处理:
from transformers import AutoTokenizer
# 加载预训练的 BERT Tokenizer
tokenizer = AutoTokenizer.from_pretrained("bert-base-cased")
def tokenize_function(examples):
"""
使用 Tokenizer 对文本进行编码,并进行填充和截断
"""
return tokenizer(examples["text"], padding="max_length", truncation=True)
# 对数据集进行预处理
tokenized_datasets = dataset.map(tokenize_function, batched=True)

2.2 数据抽样
在训练过程中,为了更好地控制训练过程,我们可以从数据集中抽样出一部分数据进行测试。例如,选择 1000 个样本进行小规模训练:
# 从数据集中抽样 1000 个训练样本
small_train_dataset = tokenized_datasets["train"].shuffle(seed=42).select(range(1000))
# 从数据集中抽样 1000 个测试样本
small_eval_dataset = tokenized_datasets["test"].shuffle(seed=42).select(range(1000))
三、训练评估指标设置
3.1 微调训练配置
在微调模型之前,我们需要配置训练参数,包括加载模型和设置训练超参数。以下代码展示了如何加载 BERT 模型,并为情感分类任务配置输出标签数量:
from transformers import AutoModelForSequenceClassification
# 加载 BERT 模型,并设置标签数量为 5(情感评分从 1 到 5)
model = AutoModelForSequenceClassification.from_pretrained("bert-base-cased", num_labels=5)
3.2 训练超参数配置(TrainingArguments)
我们使用 TrainingArguments 来配置训练超参数。这些参数包括训练批次大小、训练轮数、日志记录频率等。以下是一个示例配置:
from transformers import TrainingArguments
model_dir = "models/bert-base-cased-finetune-yelp"
# 配置训练参数
training_args = TrainingArguments(
output_dir=model_dir, # 模型保存路径
per_device_train_batch_size=16, # 每个设备的训练批次大小
num_train_epochs=5, # 训练轮数
logging_steps=100 # 每 100 步记录一次日志
)
四、训练器基本介绍
4.1 训练指标评估
Hugging Face 提供了 evaluate 库来计算模型的评估指标。例如,我们可以使用准确率(accuracy)作为评估指标。以下代码展示了如何使用 evaluate 库计算模型的准确率:
import numpy as np
import evaluate
# 加载准确率指标
metric = evaluate.load("accuracy")
def compute_metrics(eval_pred):
"""
计算准确率
"""
logits, labels = eval_pred
predictions = np.argmax(logits, axis=-1) # 将 logits 转换为预测值
return metric.compute(predictions=predictions, references=labels)
4.2 训练器(Trainer)
Trainer 类是 Hugging Face 提供的用于训练和评估模型的工具。我们需要将模型、训练参数、数据集以及计算指标的函数传递给 Trainer:
from transformers import Trainer
# 实例化 Trainer
trainer = Trainer(
model=model,
args=training_args,
train_dataset=small_train_dataset, # 训练数据集
eval_dataset=small_eval_dataset, # 验证数据集
compute_metrics=compute_metrics # 计算指标的函数
)
五、实战训练
5.1 训练过程中的指标监控
为了监控训练过程中的评估指标,我们可以配置 TrainingArguments 中的 evaluation_strategy 参数,以便在每个 epoch 结束时报告评估指标:
# 更新训练参数配置
training_args = TrainingArguments(
output_dir=model_dir,
evaluation_strategy="epoch", # 每个 epoch 结束时进行评估
per_device_train_batch_size=16,
num_train_epochs=3,
logging_steps=30 # 每 30 步记录一次日志
)
5.2 开始训练
使用 Trainer 类的 train 方法开始训练模型:
# 开始训练
trainer.train()
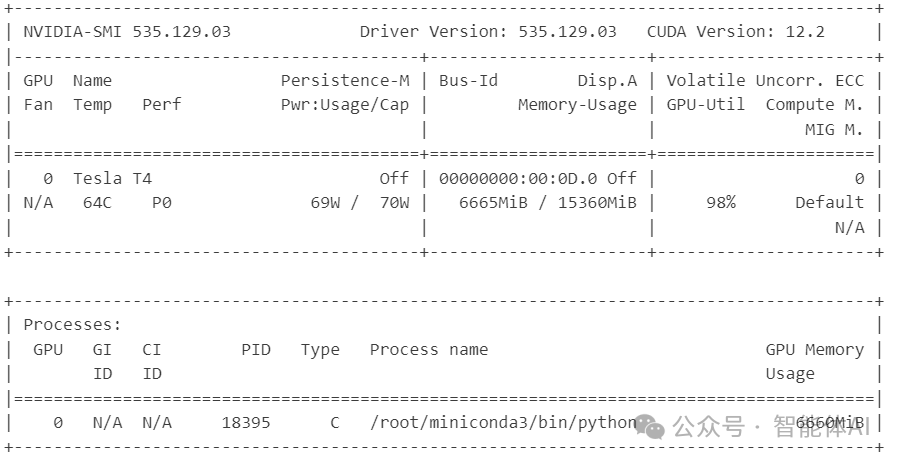
5.3 使用 nvidia-smi 监控 GPU 使用
在训练过程中,使用 nvidia-smi 命令监控 GPU 的使用情况,以确保训练过程的高效进行:
watch -n 1 nvidia-smi
六、模型保存
6.1 保存模型和训练状态
训练完成后,我们需要保存模型及其训练状态,以便后续加载和使用:
# 保存训练后的模型
trainer.save_model(model_dir)
# 保存训练状态
trainer.save_state()
通过 trainer.save_model 方法保存模型,您可以使用 from_pretrained() 方法重新加载模型。trainer.save_state() 方法保存训练状态,便于后续继续训练或评估。
七、完整代码汇总
下面是包含所有步骤的完整代码示例:
# 导入必要的库
from datasets import load_dataset
from transformers import AutoTokenizer, AutoModelForSequenceClassification, TrainingArguments, Trainer
import numpy as np
import evaluate
# 数据集下载
dataset = load_dataset("yelp_review_full")
# 数据预处理
tokenizer = AutoTokenizer.from_pretrained("bert-base-cased")
def tokenize_function(examples):
"""
使用 Tokenizer 对文本进行编码,并进行填充和截断
"""
return tokenizer(examples["text"], padding="max_length", truncation=True)
tokenized_datasets = dataset.map(tokenize_function, batched=True)
# 数据抽样
small_train_dataset = tokenized_datasets["train"].shuffle(seed=42).select(range(1000))
small_eval_dataset = tokenized_datasets["test"].shuffle(seed=42).select(range(1000))
# 模型加载与训练配置
model = AutoModelForSequenceClassification.from_pretrained("bert-base-cased", num_labels=5)
model_dir = "models/bert-base-cased-finetune-yelp"
training_args = TrainingArguments(
output_dir=model_dir,
per_device_train_batch_size=16,
num_train_epochs=5,
logging_steps=100
)
# 指标评估
metric = evaluate.load("accuracy")
def compute_metrics(eval_pred):
"""
计算准确率
"""
logits, labels = eval_pred
predictions = np.argmax(logits, axis=-1)
return metric.compute(predictions=predictions, references=labels)
# 实例化 Trainer
trainer = Trainer(
model=model,
args=training_args,
train_dataset=small_train_dataset,
eval_dataset=small_eval_dataset,
compute_metrics=compute_metrics
)
# 开始训练
trainer.train()
# 监控 GPU 使用
# 使用命令行工具: watch -n 1 nvidia-smi
# 保存模型和训练状态
trainer.save_model(model_dir)
trainer.save_state()
八、总结
本文详细介绍了使用 Hugging Face Transformers 库进行模型微调训练的完整流程,包括数据集下载、数据预处理、训练配置、评估、训练过程和模型保存等步骤。希望这些信息能帮助您更好地进行模型微调,提高模型在特定任务上的表现。
如何学习AI大模型?
大模型时代,火爆出圈的LLM大模型让程序员们开始重新评估自己的本领。 “AI会取代那些行业?”“谁的饭碗又将不保了?”等问题热议不断。
不如成为「掌握AI工具的技术人」,毕竟AI时代,谁先尝试,谁就能占得先机!
想正式转到一些新兴的 AI 行业,不仅需要系统的学习AI大模型。同时也要跟已有的技能结合,辅助编程提效,或上手实操应用,增加自己的职场竞争力。
但是LLM相关的内容很多,现在网上的老课程老教材关于LLM又太少。所以现在小白入门就只能靠自学,学习成本和门槛很高
那么针对所有自学遇到困难的同学们,我帮大家系统梳理大模型学习脉络,将这份 LLM大模型资料 分享出来:包括LLM大模型书籍、640套大模型行业报告、LLM大模型学习视频、LLM大模型学习路线、开源大模型学习教程等, 😝有需要的小伙伴,可以 扫描下方二维码领取🆓↓↓↓
👉[CSDN大礼包🎁:全网最全《LLM大模型入门+进阶学习资源包》免费分享(安全链接,放心点击)]()👈

学习路线

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。

👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。

1.AI大模型学习路线图
2.100套AI大模型商业化落地方案
3.100集大模型视频教程
4.200本大模型PDF书籍
5.LLM面试题合集
6.AI产品经理资源合集
👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓


















 405
405

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










{kind=link}