







clustering
13.2 K-Means Algorithm
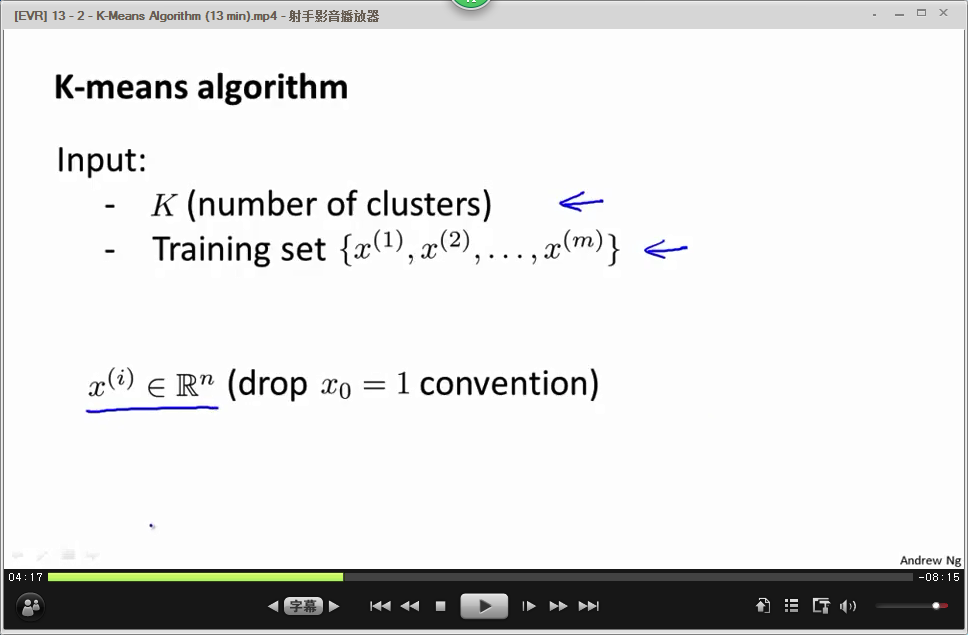
输入K和训练集,K代表聚类后的cluster数目。

μi
是指第i个聚类中心点,首先随机指定k个聚类的中心。
第一步:对于每个点,选取离这个点最近的中心为该点的分类。
第二步:根据分类后的结果,进行聚类中心
μi
的更新
13.3 Optimization Objective

从公式可以看出优化目标就是最小化所有数据与其聚类中心的欧氏距离和。
13.4 Random Initialization
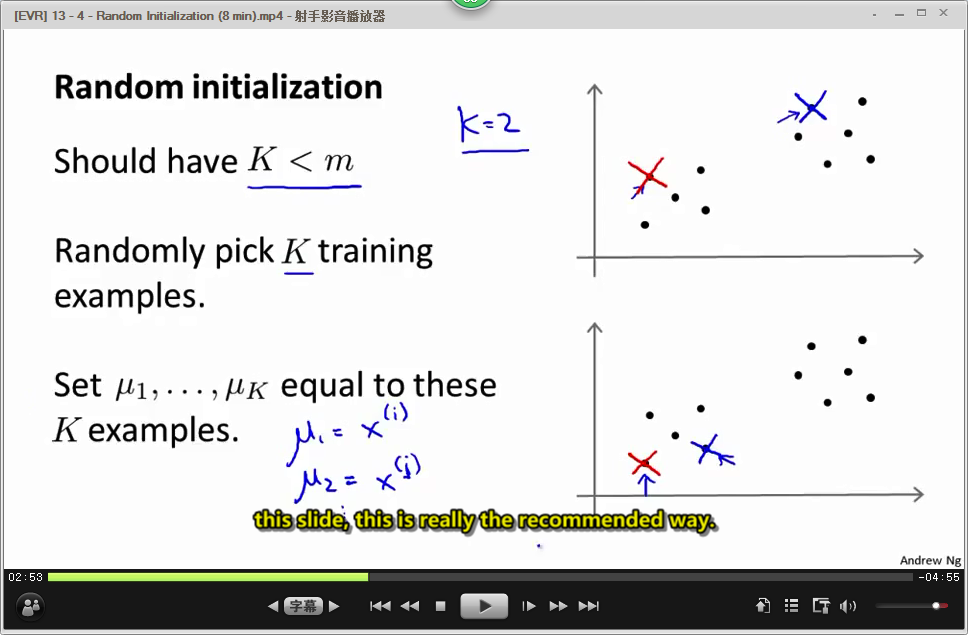
随机选取k个点作为中心
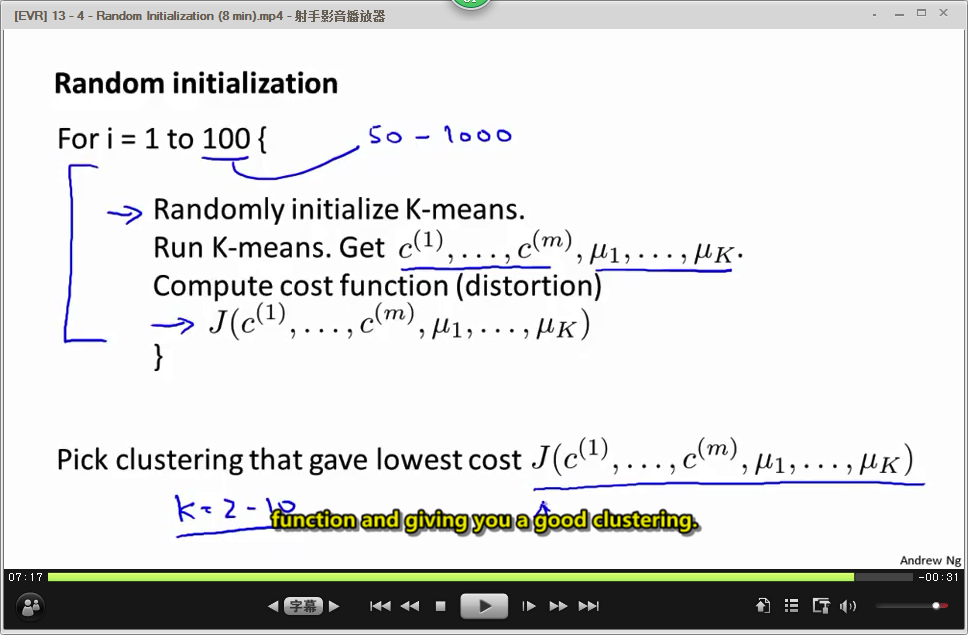
避免得到局部最优解的办法是:进行多次初始化,多次优化,从中选取最好的结果。
13.5 Choosing the Number of Clusters
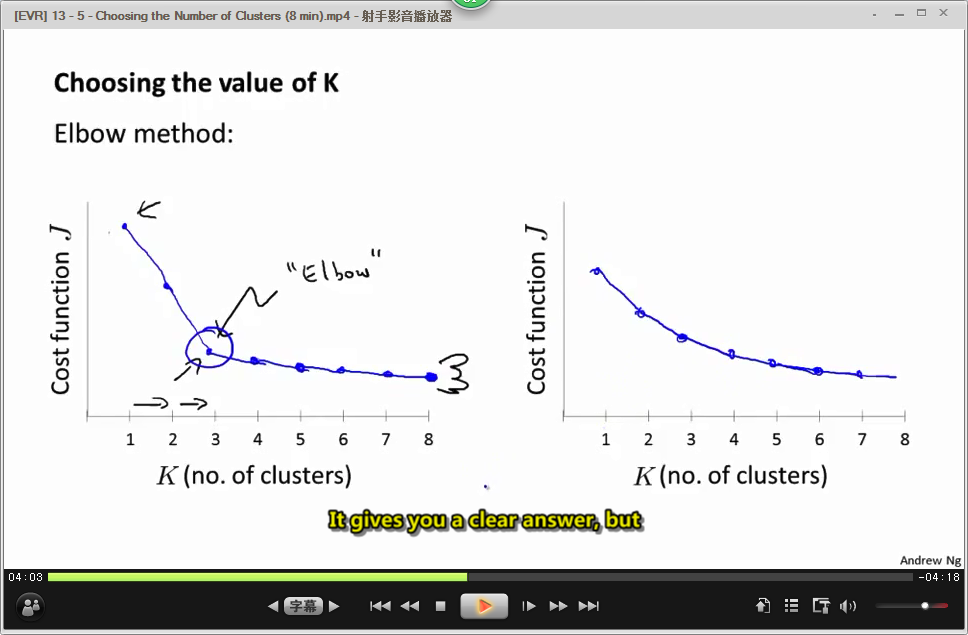
可视化,自己选。















 1951
1951

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









