







天池比赛——用户情感可视化分析
目录
前言
这是一个天池里的教学赛,整体没什么难度,主要是对pandas,基本的数据分析的练习。
题目主要内容如下
- 词云可视化(评论中的关键词,不同情感的词云)
- 柱状图(不同主题,不同情感,不同情感词)
- 相关性系数热力图(不同主题,不同情感,不同情感词)
其中数据源主要如下
| 字段名称 | 类型 | 描述 | 说明 |
|---|---|---|---|
| content_id | Int | 数据ID | / |
| content | String | 文本内容 | / |
| subject | String | 主题 | 提取或依据上下文归纳出来的主题 |
| sentiment_value | Int | 情感分析 | 分析出的情感 |
| sentiment_word | String | 情感词 | 情感词 |
下面直接分析数据并完成内容
一、读取数据,查看基本情况并做数据预处理
当得到一个数据的时候,我们应该对数据包含什么信息,数据中是否有缺省值,某些列值有什么取值等情况进行查看
引入相关库
import numpy as np
import pandas as pd
from pylab import *
import matplotlib.pyplot as plt
import seaborn as sns
import jieba读取数据,基础分析数据
#读取数据
df = pd.read_csv('./data/earphone_sentiment.csv')
#查看数据前几行信息
df.head()
#查看数据基本信息
print(df.info())
print("----------------")
#查看数据缺指信息
print(df.isnull().sum())
print("----------------")
print(df['sentiment_word'].unique())
print("----------------")
print(df['sentiment_value'].value_counts())输出如下,这里主要分析了表格中缺省值和 sentiment_word这一列的取值,因为我们这里分析主要也是针对情感词来进行分析的(这个比赛比较简单还在与直接给出了情感词)
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 17176 entries, 0 to 17175
Data columns (total 5 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 content_id 17176 non-null int64
1 content 17176 non-null object
2 subject 17176 non-null object
3 sentiment_word 4966 non-null object
4 sentiment_value 17176 non-null int64
dtypes: int64(2), object(3)
memory usage: 671.1+ KB
None
----------------
content_id 0
content 0
subject 0
sentiment_word 12210
sentiment_value 0
dtype: int64
----------------
dtype: int64
0 12210
1 4376
-1 590
Name: sentiment_value, dtype: int64
----------------
不评价 12210
好 3302
不错 569
差 415
强 244
牛 133
垃圾 32
高级 31
追求 26
呵呵 24
难听 22
骗 21
噪音 16
用心 16
舒适 16
疼 14
音染 14
水准 12
轰 10
精致 7
惊艳 7
良心 7
无语 6
无奈 5
不舒服 4
小巧 3
充足 3
上当 2
辣鸡 2
模糊 2
混浊 1
Name: sentiment_word, dtype: int64空值处理,数据映射
由输出的数据可以分析出,我们可以根据sentiment_value的值对sentiment_word进行划分为3类,分别为0对于没有评价,我们这里当作是中性评价,1对于好评,-1对应差评。所以再做以下数据预处理——填上空值,对sentiment_value做映射
# 填上空值
df['sentiment_word'].fillna('不评价', inplace=True)
# 将sentiment_value映射
map_sentiment_value = {-1: '差评', 0: '中评', 1: '好评'}
df['sentiment_value'] = df['sentiment_value'].map(map_sentiment_value)
做个关于情感词和主题之间的透视表,可以很直观的看出,每个主题中好评,差评,中评的情况
# 做sentiment_value的透视表
df_pivot_table = df.pivot_table(index='subject', columns='sentiment_value', values='sentiment_word',
aggfunc=np.count_nonzero)
df_r_pivot_tabel = df.pivot_table(index='sentiment_value', columns='subject', values='sentiment_word',
aggfunc=np.count_nonzero)sentiment_value 中评 好评 差评
subject
价格 495 256 42
其他 9493 2837 326
功能 83 63 10
外形 85 68 5
舒适 10 37 22
配置 1452 759 121
音质 592 356 64
subject 价格 其他 功能 外形 舒适 配置 音质
sentiment_value
中评 495 9493 83 85 10 1452 592
好评 256 2837 63 68 37 759 356
差评 42 326 10 5 22 121 64对评论进行分词分析
我们还需要对数据中content评论部分进行分析,而评论中有许多不必要的内容,我们就需要对此分词并去除停用词(也就是一些连接词,以帮助我们分析),对评论分词,主要应用jieba这个分词包。停用词用的是常用的中文停用词。在下面链接中可以获取。
stopwords = []
with open('./data/mStopwords.txt', encoding='utf-8') as f:
for line in f:
stopwords.append(line.strip('\n').split()[0])
# 切词
rows, cols = df.shape
cutwords = []
for i in range(rows):
content = df['content'][i]
g_cutword = jieba.cut_for_search(content)
cutword = [x for x in g_cutword if (len(x) > 1) and x not in stopwords]
cutwords.append(cutword)
s1 = pd.Series(cutwords)
df['cutwords'] = s1
print(s1.value_counts())用jieba这个包,很容易将分词搞定,结果如下。
0 [Silent, Angel, 期待, 光临, 共赏, 美好, 声音]
1 [HD650, 1k, 失真, 声道, 左声道, 声道, 右声道, 左右, 超出, 官方, ...
2 [达音科, 17, 周年, 数据, 好看, 便宜]
3 [bose, beats, apple, 消費者, 根本, 知道, 有曲線, 存在]
4 [不错, 数据]
...
17171 [3000, 价位, hd650, S7, 更好, 耳放]
17172 [hd800, 爆皮, 正常, 根线, 这种, 忧虑]
17173 [焊接, 一下, 就行了, 820, 原线, 全新, 800s, 原线, 99, 盒子, 没动]
17174 [赶紧, 出手]
17175 [sommer, 参考, diy, 两米, 成本, 600, 左右, 吊打, 原线]由于我们还要做不同情感的分析,所以我们根据sentiment_value的值,将表格划分为差评,中评和好评三个表。
# 根据情感划分切词
df_pos = df.loc[df['sentiment_value'] == '好评'].reset_index(drop=True)
df_neu = df.loc[df['sentiment_value'] == '中评'].reset_index(drop=True)
df_neg = df.loc[df['sentiment_value'] == '差评'].reset_index(drop=True)这里基本的预处理就结束了,也对数据有了一个直观的了解,后面就通过一些手段可视化上面的结果。
二、词云可视化
想利用词云可视化,主要是利用WordCloud这个开源包,这个包直接用pip安装有可能会出现问题,所以这部分我直接在百度的AIstudio上跑了。
这个库用起来也比较简单,只需要设定自己需要的txt文件和图案,调个包就好了。
里面的图片都是上网随便找的黑白图
pos_txt = '/'.join(np.concatenate(pos_df['cutwords']))
neg_txt = '/'.join(np.concatenate(neg_df['cutwords']))
neu_txt = '/'.join(np.concatenate(neu_df['cutwords']))
neu_mask = imread('./data/neu.png')
pos_mask = cv.imread('./data/pos.png')
neg_mask = cv.imread('./data/neg.png')
# 绘制好评词云
pos_wc = WordCloud(font_path='./data/simhei.ttf',background_color='white',mask=pos_mask).generate(pos_txt)
neg_wc = WordCloud(font_path='./data/simhei.ttf',background_color='white',mask=neg_mask).generate(neg_txt)
neu_wc = WordCloud(font_path='./data/simhei.ttf',background_color='white',mask=neu_mask).generate(neu_txt)
plt.subplot(1,3,1)
plt.imshow(pos_wc)
plt.title("Postive wordcloud")
plt.axis('off')
plt.subplot(1,3,2)
plt.imshow(neu_wc)
plt.axis('off')
plt.title("Neutural wordcloud")
plt.subplot(1,3,3)
plt.imshow(neg_wc)
plt.title("Negative wordcloud")
plt.axis('off')
plt.show()
三、柱状图
柱状图主要分析不同主题下,不同情感评论的评论数,来看用户重点关注的地方是什么。
# 直接对透视表使用绘图即可
df_pivot_table.plot.bar()
for x, y in enumerate(df_pivot_table['中评'].values):
plt.text(x - 0.2, y, str(y), horizontalalignment='right')
for x, y in enumerate(df_pivot_table['好评'].values):
plt.text(x, y, str(y), horizontalalignment='center')
for x, y in enumerate(df_pivot_table['差评'].values):
plt.text(x + 0.2, y, str(y), horizontalalignment='left')
plt.title('不同主题,不同情感评论数')
plt.ylabel('评论数')
plt.show()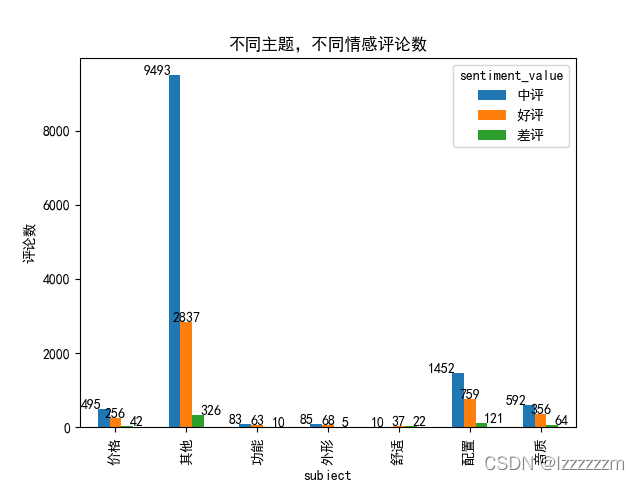
可以看到用户多集中在价格,配置和音质上评论,其他方面比较多评论。
然后我们可以看看在褒义词和贬义词中比较多的评论在说什么
# 取出褒义词和贬义词中的评论列
pos_word = df_pos['sentiment_word'].value_counts()
neg_word = df_neg['sentiment_word'].value_counts()
pos_word.plot.barh()
for x, y in enumerate(pos_word):
plt.text(y, x, str(y), horizontalalignment='left')
plt.xlabel('评论数')
plt.title('褒义词评论词统计')
plt.show()
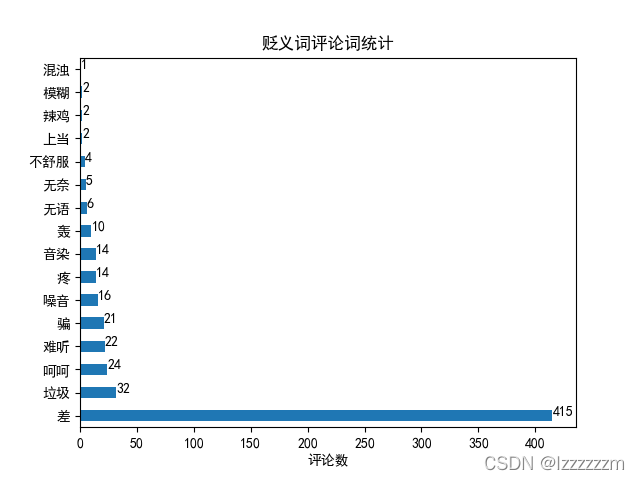
neg_word.plot.barh()
for x, y in enumerate(neg_word):
plt.text(y, x, str(y), horizontalalignment='left')
plt.xlabel('评论数')
plt.title('贬义词评论词统计')
plt.show()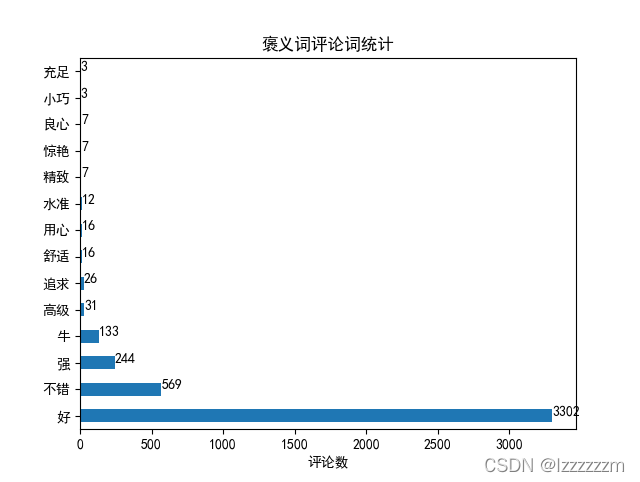
四、热力图
热力图的绘制,主要是来看耳机不同的方面的相关系数,主要调用seaborn这个包,对pandas也是兼容非常好。
# 热力图
sns.heatmap(df_r_pivot_tabel.corr(), annot=True)
plt.title('不同主题相关系数热力图')
plt.show()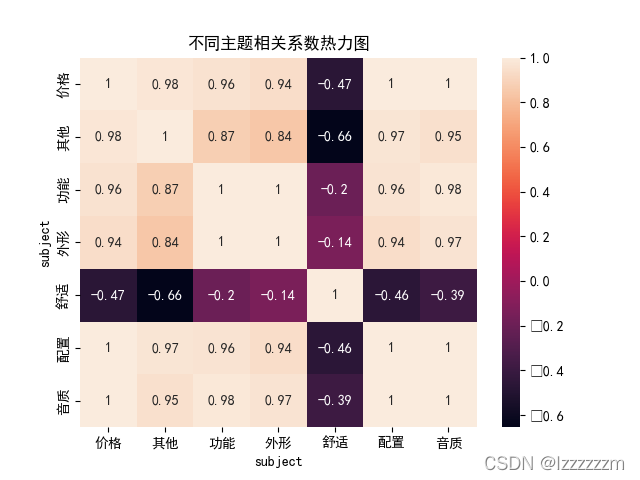
显然,舒适感,和其他的方面都成负相关的关系,而其他功能上基本都呈正相关关系。
总结
一个对于学习pandas和一些可视化,非常好的比赛。


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











