









1公式展示
OKS的公式来源于AI Challenger。链接:AI Challenger.
主体思想为关键点位置的加权欧氏距离。
对一个人物p,OKS分数定义如下(与原公式略有改动):
O
K
S
p
=
Σ
i
e
x
p
{
−
d
p
i
2
/
(
2
S
p
2
σ
p
i
2
)
}
δ
(
v
p
i
=
1
,
v
p
i
′
=
1
)
Σ
i
δ
(
v
p
i
=
1
)
OKS _p= \frac{\Sigma_{i}exp\{-d_{pi}^{2}/(2S_p^{2}\sigma_{pi}^{2})\}\delta(v_{pi}=1,v_{pi}'=1)}{\Sigma_{i}\delta(v_{pi}=1)}
OKSp=Σiδ(vpi=1)Σiexp{−dpi2/(2Sp2σpi2)}δ(vpi=1,vpi′=1)
其中各个符合代表的意思,见下文详解。
2 计算思想(猜测)
2.1 预测点与真实点距离
一个人物的关键点有多个比如头顶、左肩、左肘、左腕。。。
假设头顶这个点编号为1,真实坐标为
(
x
1
,
y
1
)
(x_{1},y_{1})
(x1,y1),模型预测值为
(
x
1
′
,
y
1
′
)
(x_{1}',y_{1}')
(x1′,y1′).如图1圆形代表真实位置,三角形代表预测位置。
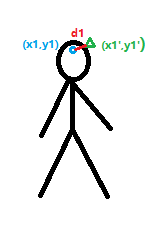
d
1
2
=
(
x
1
′
−
x
1
)
2
+
(
y
1
′
−
y
1
)
2
d_1^2 = (x_1'-x_1)^2+(y_1'-y_1)^2
d12=(x1′−x1)2+(y1′−y1)2
显然模型预测的位置与真实位置越近(距离越小)越好,反之越差,也就说距离与最后得分OKS成正比。
d
i
2
=
(
x
i
′
−
x
i
)
2
+
(
y
i
′
−
y
i
)
2
d_i^2 = (x_i'-x_i)^2+(y_i'-y_i)^2
di2=(xi′−xi)2+(yi′−yi)2
d
i
d_i
di表示人物编号为i的关键点欧式距离。
欧式距离的平方可以看成两维的,为了与下面提到的面积保持维度一致性,所以这里采用欧式距离的平方。
2.2 人体在图像中的大小
如果A模型预测某个关键点的欧式距离,和B模型预测某个关键点欧式距离一样,我们就说这两个模型一样好吗?不!
如图2,两个预测点欧式距离一样。但是如果右边的人物放大,预测点欧式距离也会变大!
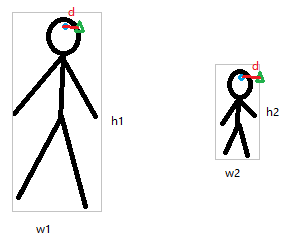
所以说欧式距离一样时,预测人物在图像中的大小越大越差,反之越好。人物面积大小与最后OKS得分成反比。
S
2
=
w
h
S^2 = wh
S2=wh
S
S
S代表人物在图像中所占面积的平方根。
S
2
S^2
S2代表面积。这样写与上面的欧式距离的平方在写法上保持一致。
此外面积单位是像素。
2.3 人工标注位置偏移
如果A模型和B模型预测的欧式距离一样,预测的人物面积一样,那么两个模型优劣是否就一样呢?不!
在上文计算的时候,用的所谓真实位置,也不过是人工标注的位置,而不同的关键点,人工标注位置与真实位置偏移不一样。因为人的肩部、臀部可标注的地方要比人的眼睛、鼻子大,因此人的肩部、臀部的偏移量往往比眼睛、鼻子多。
科学的做法是取一大批样本,然后度量不同关键点的标准偏差
σ
\sigma
σ。但是实际操作有困难。这里也存在一个悖论,如果能度量出人工标注位置的偏移,那在人工标注的时候就可以避免这个偏移。
故本文应用统计的方式计算
σ
=
E
(
d
/
s
)
\sigma=E(d/s)
σ=E(d/s).来代替这个标准偏差。
想法就是预测的离散程度越大,说明人工标注位置偏移越大。
人工标注位置的偏移度与最后OKS得分成反比。
本文列举两种统计方式:
如图3 圆形代表真实坐标值,空心三角形代表模型A的预测值,实心三角形代表模型B的预测值。

假设头顶编号为1,左脚踝编号为12。
(
x
1
,
1
,
y
1
,
1
)
(x_{1,1},y_{1,1})
(x1,1,y1,1)代表编号为1的关键点,第1个目标,真实坐标
(
x
1
,
1
A
,
y
1
,
1
A
)
(x_{1,1}^A,y_{1,1}^A)
(x1,1A,y1,1A)代表编号为1的关键点,第1个目标,A预测坐标
(
x
12
,
2
,
y
12
,
2
)
(x_{12,2},y_{12,2})
(x12,2,y12,2)代表编号为12的关键点,第2个目标,真实坐标
(
x
12
,
2
B
,
y
12
,
2
B
)
(x_{12,2}^B,y_{12,2}^B)
(x12,2B,y12,2B)代表编号为12的关键点,第2个目标,B预测坐标
两种统计方式:
第一种,考虑所有目标相同编号点的所有模型预测的离散程度。
r
i
,
j
m
=
(
x
i
,
j
m
−
x
i
,
j
)
2
+
(
y
i
,
j
m
−
y
i
,
j
)
2
w
i
h
i
r_{i,j}^m=\sqrt{\frac{(x_{i,j}^m-x_{i,j})^2+(y_{i,j}^m-y_{i,j})^2}{w_ih_i}}
ri,jm=wihi(xi,jm−xi,j)2+(yi,jm−yi,j)2
r
i
,
j
m
r_{i,j}^m
ri,jm代表模型m在目标j上关键点i的预测偏移值。
先求平均值,
r
1
‾
=
r
1
,
1
A
+
r
1
,
2
A
+
r
1
,
1
B
+
r
1
,
2
B
4
\overline{r_1}=\frac{r_{1,1}^A+r_{1,2}^A+r_{1,1}^B+r_{1,2}^B}{4}
r1=4r1,1A+r1,2A+r1,1B+r1,2B
r
12
‾
=
r
12
,
1
A
+
r
12
,
2
A
+
r
12
,
1
B
+
r
12
,
2
B
4
\overline{r_{12}}=\frac{r_{12,1}^A+r_{12,2}^A+r_{12,1}^B+r_{12,2}^B}{4}
r12=4r12,1A+r12,2A+r12,1B+r12,2B
在求均方差,
σ
1
=
E
(
d
1
S
)
=
(
r
1
,
1
A
−
r
1
‾
)
2
+
(
r
1
,
2
A
−
r
1
‾
)
2
+
(
r
1
,
1
B
−
r
1
‾
)
2
+
(
r
1
,
2
B
−
r
1
‾
)
2
4
\sigma_1=E(\frac{d_1}{S})=\sqrt{\frac{(r_{1,1}^A-\overline{r_1})^2+(r_{1,2}^A-\overline{r_1})^2+(r_{1,1}^B-\overline{r_1})^2+(r_{1,2}^B-\overline{r_1})^2}{4}}
σ1=E(Sd1)=4(r1,1A−r1)2+(r1,2A−r1)2+(r1,1B−r1)2+(r1,2B−r1)2
σ
12
=
E
(
d
12
S
)
=
(
r
12
,
1
A
−
r
12
‾
)
2
+
(
r
12
,
2
A
−
r
12
‾
)
2
+
(
r
12
,
1
B
−
r
12
‾
)
2
+
(
r
12
,
2
B
−
r
12
‾
)
2
4
\sigma_{12}=E(\frac{d_{12}}{S})=\sqrt{\frac{(r_{12,1}^A-\overline{r_{12}})^2+(r_{12,2}^A-\overline{r_{12}})^2+(r_{12,1}^B-\overline{r_{12}})^2+(r_{12,2}^B-\overline{r_{12}})^2}{4}}
σ12=E(Sd12)=4(r12,1A−r12)2+(r12,2A−r12)2+(r12,1B−r12)2+(r12,2B−r12)2
第二种,各自模型考虑各自模型的预测所有目标的相同编号点的离散程度。
先求平均值,
r
1
A
‾
=
r
1
,
1
A
+
r
1
,
2
A
2
\overline{r_1^A}=\frac{r_{1,1}^A+r_{1,2}^A}{2}
r1A=2r1,1A+r1,2A
r
12
A
‾
=
r
12
,
1
A
+
r
12
,
2
A
2
\overline{r_{12}^A}=\frac{r_{12,1}^A+r_{12,2}^A}{2}
r12A=2r12,1A+r12,2A
在求均方差,
σ
1
A
=
E
(
d
1
S
)
=
(
r
1
,
1
A
−
r
1
A
‾
)
2
+
(
r
1
,
2
A
−
r
1
A
‾
)
2
2
\sigma_1^A=E(\frac{d_1}{S})=\sqrt{\frac{(r_{1,1}^A-\overline{r_1^A})^2+(r_{1,2}^A-\overline{r_1^A})^2}{2}}
σ1A=E(Sd1)=2(r1,1A−r1A)2+(r1,2A−r1A)2
σ
12
A
=
E
(
d
12
S
)
=
(
r
12
,
1
A
−
r
12
A
‾
)
2
+
(
r
12
,
2
A
−
r
12
A
‾
)
2
2
\sigma_{12}^A=E(\frac{d_{12}}{S})=\sqrt{\frac{(r_{12,1}^A-\overline{r_{12}^A})^2+(r_{12,2}^A-\overline{r_{12}^A})^2}{2}}
σ12A=E(Sd12)=2(r12,1A−r12A)2+(r12,2A−r12A)2
通常用第二种方式即可。
2.4 克罗内克函数
× 人工标注数据的时候,每个关键点有三种属性
v
v
v:
v
=
0
v = 0
v=0,表示这个关键点不可见,不在图中,或者无法推测在哪;
v
=
1
v = 1
v=1,表示这个关键点可见;
v
=
2
v = 2
v=2,表示这个关键点不可见,但是可以推测出在哪;
× 预测出来的关键点也分两种属性
v
′
v'
v′:
v
′
=
0
v' = 0
v′=0,表示这个关键点未预测出来;
v
′
=
1
v' = 1
v′=1,表示这个关键点预测出来了;
在计算OKS的时候,分子只计算人工标注出来可见,且预测出来的点。分母只计算人工标注出可见的点。
克罗内克函数,
δ
(
v
i
=
1
)
=
{
1
,
i
f
v
i
=
1
0
,
i
f
v
i
≠
1
,
\delta(v_i=1)=\left\{ \begin{array}{lr} 1, if v_i=1 & \\ 0 ,if v_i \neq1, & \end{array} \right.
δ(vi=1)={1,ifvi=10,ifvi̸=1,
也就是
v
i
=
1
v_i=1
vi=1时,函数取值为1,
v
i
≠
1
v_i\neq1
vi̸=1时,函数取值为0.
2.5 归一化
指数函数
e
x
p
(
−
x
)
=
e
−
x
=
1
e
x
exp(-x)=e^-x=\frac{1}{e^x}
exp(−x)=e−x=ex1的作用是把
d
i
2
/
(
2
S
2
σ
i
2
)
d_{i}^{2}/(2S^{2}\sigma_{i}^{2})
di2/(2S2σi2)
的取值范围限定在0到1上,且使得距离,人体面积,人工标注偏移与OKS得分和上述分析的增减性保持一致。
3 平均准确率(AP)
平均准确率(AP)给定OKS阈值s,预测的结果在整个测试集上的平均准确率
(
A
P
@
s
)
(AP@s)
(AP@s)可由测试集中所有图片的OKS指标计算得到:
A
P
@
s
=
Σ
p
δ
(
O
K
S
p
>
s
)
Σ
p
1
AP@s=\frac{\Sigma_p\delta(OKS_p>s)}{\Sigma_p1}
AP@s=Σp1Σpδ(OKSp>s)
4 平均准确率(AP)的均值(mAP)
最终指标mAP的计算方式如下所示:
m
A
P
=
m
e
a
n
{
A
P
@
(
0.50
:
0.05
:
0.95
)
}
mAP=mean\{AP@(0.50:0.05:0.95)\}
mAP=mean{AP@(0.50:0.05:0.95)}
从给定阈值0.5到0.95按照0.05步长递计算AP后,再取平均值。

















 431
431

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









