









在https://blog.csdn.net/m0_37483148/article/details/108627915这篇文章中整理了今年上半年一些好的序列推荐论文
Intention Modeling from Ordered and Unordered Facets for Sequential Recommendation
1.引言
推荐系统作为一种重要的在线服务,在电子商务领域得到了广泛的应用。由于商品信息的爆炸式增长,推荐系统可以有效地帮助消费者选择适合自己的商品要求。但是,大多数用户在浏览电子商务网站时,不会明确表示自己的购买意向。因此,准确地学习用户潜在的动态意图成为在线推荐的一项重要任务系统。传统推荐系统,包括基于内容的推荐系统和基于协同过滤的推荐系统,假设用户项交互实际上是相互独立的,并以静态的方式对用户的偏好进行建模[18]。Zhou等人[28]提出了下一次点击预测的深度兴趣网络(DIN),它使用基于注意力的模型来捕捉与目标项目相关的兴趣,并获得自适应的兴趣表示来进行推荐。然而,在现实生活中,用户的购买行为往往与之前的购买顺序有关,用户的偏好会随着时间的推移而动态变化。近年来,人们提出了许多基于序列机制的模型来学习用户的潜在偏好,如Markov链模型[6,16]和递归神经网络(RNN)模型[12]。这些方法由于能够捕捉用户-项目交互序列中的顺序依赖关系而引起了广泛的关注。Rendle等人[16]提出了对个性化马尔可夫链进行因式分解,以同时捕获长期偏好和短期转变。Yu等人[24]提出了DREAM模型,它使用RNN来研究每个用户的动态表示和用户-项目交互的顺序行为。Zhou等人[27]提出了一种改进的方法来模拟用户兴趣的演变,目的是解决用户兴趣问题漂移。尽管现有的方法在顺序推荐任务中取得了良好的性能,如果要对用户潜在的动态意图进行建模,还需要考虑几个因素;如图1所示。

首先,受商品属性的影响,不同的用户可能有相似的购买意向,而其他用户的序列可能会影响当前的用户意向。如虚线2所示,两个用户通常在购买面包后购买牛奶,在购买新手机后购买手机壳。如果只考虑局部序列依赖,就不可能准确地理解用户的潜在意图。第二,用户不仅会为不同的项目生成不同的意向,而且还会针对特定项目的不同特征生成不同的意向。以不同的方式处理物品特征可能会促进更多的准确理解用户意图。当用户选择品牌时,可能会更在意品牌的价格。第三,用户的意图是灵活的,并且随着时间的推移而变化,因此,必须同时考虑用户的动态偏好和灵活的动机。现有的顺序推荐方法大多采用基于顺序机制的模型来描述序列依赖关系,从而忽略了项目之间的灵活依赖关系。这些方法高估了项目之间的顺序依赖的强度,这可能会导致产生噪声依赖和错误地学习用户意图[18]。如虚线3所示,考虑到示例中的女性最近购买的历史序列,很明显,手机和手机外壳之间有很强的相关性。如果我们过多地关注项目之间的顺序依赖关系,手机和手机外壳之间的相关性将是忽略了。相应地在上述三个问题的启发下,我们引入了一种从有序面和无序面进行意向建模(IMfOU)的方法来学习用户的动态潜在意图,并考虑了两种类型上下文信息:关于购买的顺序信息和周期性信息。具体来说,我们提出了一种基于图神经网络和注意机制的全局和局部项目嵌入方法。该方法可以全面捕捉信息中的顺序上下文,突出用户关心的项目特征。此外,我们还设计了有序偏好漂移学习(OPDL)和无序购买动机学习(UPML),分别获得用户的动态偏好和购买动机。它将用户的动态偏好和当前动机相结合,不仅考虑了商品之间的顺序依赖关系,而且考虑了柔性依赖关系,分别从订单和非订单两个方面对用户的购买意愿进行了更准确的建模。最后,通过匹配用户的购买意愿和目标商品,利用融合层来预测用户下一步是否会购买目标商品。
我们在真实世界的数据集上进行了大量的实验来评估我们提出的方法。评价结果表明,我们提出的方法比现有的序贯推荐方法具有更好的性能,平均提高了2.26%。
- 本文提出了一种新的基于局部嵌入的方法。它不仅考虑了局部序列信息,而且考虑了全局序列依赖关系序列。在另外,通过使用用户偏好,它自适应地突出重要功能。
- 设计有序偏好漂移学习(OPDL)和无序购买动机学习(UPML)来模拟用户的动态潜在意图。具体地说,OPDL 是PcGRU从GRU扩展到bilstm的输出,以模拟用户的偏好漂移。UPML利用注意机制获得了用户-项目交互中存在的柔性依赖,有效地防止了非线性依赖的影响。
- 通过分别从有序面和无序面对用户的潜在意图进行建模,可以有效地预测用户偏好的项目数据集结果表明,我们提出的IMfOU比现有的方法有显著的优越性。此外,这些结果表明,这两种上下文信息对用户的动态意图建模非常有利
3.准备工作
3.1问题定义
序贯推荐的目的是根据给定用户的历史交互顺序来预测用户是否会购买目标产品。用户项交互通常在一个序列中连续发生,每个用户都有一个相应的交互历史序列。用户u∈U的历史序列Su表示为Su={(i1,t1,c1),(i2,t2,c2),…,(it,tt,ct)},其中ij∈I记录当前用户购买的第j件物品,tj代表用户u购买物品j的时间,cj是物品j的类别.U和I表示由所有用户组成的用户集和分别由总项目组成的项目集。所有用户的全局交互序列表示H={S1,S2,…,Sn},其中n表示当前的数量用户。给定用户和他的历史交互序列,这个顺序推荐任务包括预测用户是否会购买下一个项目推荐。
3.2全局序列图构造
在现实世界中,用户-项目交互通常不会在隔离中发生,这意味着用户-项目交互之间存在顺序关系。因此,在本文中,我们为交互序列h中的所有项构造了全局序列图;这可以表示为G=(N,E),其中N表示所有节点的集合,E表示节点之间的所有边的集合。每个节点表示一个项目,边缘表示项目项互动。在此外,项目之间的交互频率不同,隐含的顺序上下文也不同。如果两个项目的交互频率较高,则说明这两个项目通常具有较高的相似性和相关性;相比之下,如果两个项目之间的交互频率较低,则表明这两个项目的相关性较弱,这将给顺序推荐带来噪音。因此,我们进一步使用项之间的交互时间作为图中边的权重,以表示它们之间的关联强度项目。全局序列图中的第i个节点可以表示为ni,而节点ni和nj之间的边可以表示为eij,其中边的权重表示交互时间尤其是在给定一个用户的历史序列Su={i1,i2,…,it},我们可以得到节点setNSu={n1,n2,…,nt}及其相邻节点setNa(Su)={Na1,Na2,…,Nat}。,例如,给定一个购买序列su={i1,i3,is,i3,i4}∈R5×Lof use ru∈U,给出了这个会话的图图2。在该图中,n1、ns、n3和n4分别对应于项目si1、is、i3和4,而节点ns j、ns1、ns2是节点的相邻节点。两个节点之间的边的方向表示项目的购买顺序,而节点之间的边数表示该边的权重。

3.3购买周期模型
在现实世界中,同一用户通常会以不同的频率购买不同的商品,而不同的用户会以不同的频率购买同一商品。因此,当用户购买某些商品时,考虑购买周期是至关重要的。给定一个用户及其历史交互序列su,可以得到用户对不同物品的时间交互顺序Iu,可以表示为T Iu={ti(i1),ti(i2),…,ti(it},其中t是用户购买的物品数量。而且itemij的用户交互时间序列可以表示为TI(ij)={t1,t2,…,tq},其中q表示用户重复购买itemij的次数。随后,用户和项目之间的平均购买时间间隔ap可以用公式(1)计算
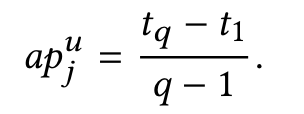
除此之外,物品的购买周期也取决于物品的购买周期。例如,电子产品的采购周期比食品的采购周期长。在本文中,用户维护项i的购买周期定义如下:

根据用户的购买周期,得到用户的购买频率,捕捉用户偏好的变化过程,计算用户对不同商品的关注度得分
4方法
在本节中,我们首先概述我们提出的用于顺序推荐的imfou模型。然后详细描述了IMfOU的三个主要组成部分:全局和局部项嵌入、潜在用户意图建模和基于MLP的融合层。最后,我们分析了模型的损失函数和训练过程。
4.1概述
本文提出了一种新的序列推荐模型:有序和无序方面的意图建模(imfou),图2展示了我们提出的模型的结构。如图2所示,IMfOU包含三个主要层:全局和局部项嵌入(GLIE)层、潜在用户意图建模层和融合层。在这里,潜在用户意图建模主要由OPDL和UPML组成。此外,在GLIE中,每一项都可以表示为一个唯一的向量,它可以捕获所有用户的全局序列上下文信息,并突出用户意图追求的重要特征。在潜在用户意向建模层,有序偏好漂移学习(OPDL)和无序购买动机学习(UPML)分别获得用户的动态偏好和当前购买动机。它将基于有序的机制和基于无序的机制相结合,不仅考虑了顺序依赖,而且考虑了灵活的依赖关系。最后,基于MLP的融合模型结合用户的动态偏好和无序的购买动机,确定用户的购买意愿,并预测当前用户是否会购买目标项目。我们将在本文中使用的重要符号汇总在表1中

4.2全局和局部项嵌入
GLIE模型的目的是生成一个统一的向量空间,用于利用项目和突出用户关心的重要功能关于。上一个研究通常使用一种热编码来表示用户与项目之间的交互,而使用RNN等后续神经网络模型来提取项目之间的顺序关系。然而,一个热编码需要大量的内存来操作,并且不能充分表示项目之间潜在的顺序依赖关系。另一方面,像RNN这样的深度学习模型只考虑局部存在的序列信息顺序。在近年来,图神经网络以其优异的性能在社会网络分析和兴趣点推荐等推荐系统中得到了广泛的应用。本文提出了一种新的基于用户意图的全局局部项嵌入(GLIE)方法,通过捕获全局序列上下文信息和不同特征的用户意图,生成统一的表示项目的向量。胶质细胞的结构如图2所示。
除了本地用户历史序列中存在的序列上下文关系外,GLIE还利用所有用户的历史序列构造序列图,从中可以更全面地提取出序列关系推荐。如人们对不同的邻居有不同的意图,每个节点对目标节点的表示具有不同的重要性。在这里,我们介绍了节点级的注意机制,用来捕捉用户对不同邻居的意图,并将这些邻居的信息聚合起来生成目标的嵌入向量节点。首先,我们利用用户信息来学习重要性核心,它代表不同邻居。给一个相邻节点包含在邻域集合(Nas)中,可以学习到重要度s∈RK×1。其中k是节点的邻居节点数。这表示节点j对于节点ns的表示有多重要。节点对(ns,ns j)的重要性表示为以下:

其中Xn∈RK×dre表示所有相邻节点的矩阵,xj∈rdi是项ij的嵌入,对应于节点nj。v∈表示给定user u的嵌入,表示我们添加的用户信息,表示输入的维数。病态的邻居边的权重矩阵,这意味着时间序列之间的交互发生项目和是邻居节点.Xn (Xn)⊤是一项序列的不同物品的互动关系。WNu∈RK x d,WNs∈RK x 1,WNco∈RK x 1表示空间转移矩阵,将用户的嵌入、边权的嵌入以及不同物品的交互关系转化为一个空间。接下来,通过注意力得分可以计算出注意scoreA(at t)s∈RK x 1,如下所示

其中,k表示节点的邻居数,Cs∈Rd表示item的类型的嵌入,A(t)sj表示itemij对应的注意分数,⊕表示连接操作
对于一个特定的产品,用户会对不同的功能产生不同的关注;他们可能只关注特定的功能而忽略其他功能。为了更准确地了解用户对特征的关注差异,我们利用购买周期和用户信息来区分特定商品的特征,突出用户有意的特征,忽略用户不关心的特征。Item的特征注意力得分表达如下:

接下来,项目嵌入向量通过特性表现公式为

⊗表示element-wise积矩阵。利用GLIE,可以得到项目的统一嵌入向量。给定用户及其历史序列,我们可以生成GLIE后的交互序列,该序列可表示为e(Su)={eF1,eF2,…∈Rt×d,其中efs∈rd表示其目标的d维嵌入向量,表示其目标的四分之一。
4.3潜在意向模型
在现实世界中,用户的购买意向主要受其偏好和当前消费动机的影响。基于用户的购买周期,我们提出了有序偏好学习(OPDL)和无序购买动机学习(UPML)来模拟用户的潜在意愿。用户的潜在购买意愿与购买周期有关;同一用户经常会用不同的频率购买不同的商品,用户会以不同的频率购买同一件物品。例如,食品的购买频率显著高于手机的购买频率。用户的偏好是动态的,会随时间变化;这种变化很大程度上受到顺序相互作用的关系的影响。OPDL主要基于RNN模型来获取用户的动态偏好。该算法利用购买周期上下文信息获取用户对每件商品的购买意愿得分,并在神经网络中更新隐藏状态,可以全面捕获商品的顺序依赖,有效地解决偏好漂移问题。另一方面,当前的消费动机通常是暂时的、灵活的,而且受顺序依赖关系的影响较小。使用注意机制的UPML捕获了灵活的依赖关系,有效地防止了项之间产生噪音依赖。
4.3.1顺序偏好偏移学习。
通过捕获用户-物品交互中存在的序列上下文信息和购买周期上下文信息,可以使用Order PreferenceDrift Learning (OPDL)来获取用户动态偏好建模和偏好漂移过程,其结构如图3所示。

给定购买序列Su,我们可以获得用户-项目交互的嵌入序列e(Su)={eF1,eF2,…∈Rt×d和周期序列Pu={P1,P2,…, Pt}∈Rt×d。首先,我们可以使用BiLSTM来捕获顺序依赖关系,从而获得用户对项目的一系列兴趣状态。由于bilistm可以同时进行正向学习和逆向学习,因此可以充分利用长期序列依赖和高维序列依赖。具体来说,BiLSTM的ell与LSTM的cell是相同的,LSTM的公式如下


然后将正向状态和反向状态串联起来,计算隐藏状态ehj∈R2dof BiLSTM,它可以捕获序列依赖关系来表示用户的偏好
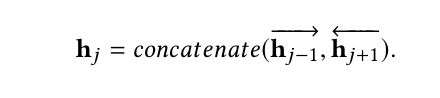
但是,BiLSTM的隐藏状态只捕捉到项目之间的依赖关系,无法了解用户偏好漂移的过程,无法准确捕捉动态偏好[27]。在环境上下文的影响下,用户对项目有不同的偏好,通常会随着时间的变化而变化。因此,在用户信息和用户购买周期的帮助下,我们提出了一个改进的名为PcGRUto的GRU模型来捕捉偏好漂移的过程,并对用户的动态偏好进行建模。首先,我们计算不同BiLSTM隐含层状态下useru的意向评分,用来表示用户对不同物品的意向。给定第j个BiLSTM 's隐藏层状态hj,其意图得分scorehj表示为
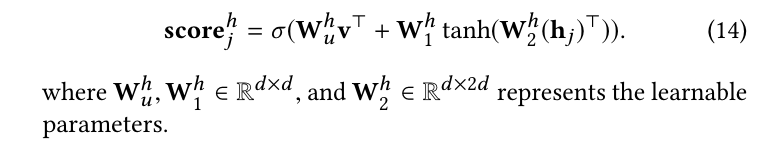
然后,我们将BiLSTM的隐藏状态作为PcGRU的输入。与LSTM类似,PcGRU使用两个门来控制PcGRU单元的状态流。
PcGRU的每一步,隐藏状态gj∈Rd 作为之前隐藏状态gj−1∈Rd的更新,当前输入hj∈R2d,意图得分scorehj∈Rd用户购买周期Pj∈Rd如下:

此时,我们可以通过对pcgru的隐藏状态进行平均,得到useru的动态preferenceDu∈rd的特征表示
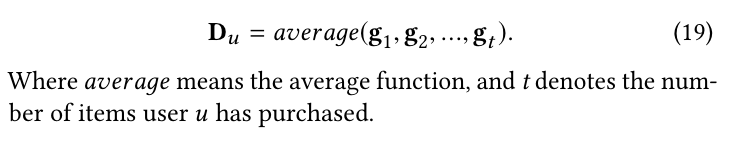
4.3.2无序购买动机学习。
消耗运动通常是暂时的和灵活的,并且较少受到顺序依赖关系的影响。无序购买动机学习(UPML)从用户最近的购买行为中获取隐含的灵活依赖关系,从而获取用户当前消费动机的表征。ofUPML的结构如图4所示。

我们使用基于用户信息和用户购买周期的关注层来突出显示用户关心的物品。给定用户最近购买的商品集合Sru={(it−l,tt−l),(it−l+1,tt−l+1),…,(it,tt)},可以得到item (Sru)的嵌入集合={eFt−l,eFt−l+1,…∈Rl×d和购买周期序列Pru={Pt−l,Pt−l+1,…, Pt}∈Rl∗d。我们选择最近商品的数量来衡量购买积极性。在UPML中,注意力分数∈Rlis计算为

4.4融合层
在得到用户的动态偏好和购买动机后,我们通过将用户动态表现Du∈Rd和用户购买动机Mu∈Rd连接起来,就可以得到用户的购买意图。然后我们使用MLP来预测useru将来是否购买目标itemit+1。在本文中,我们把推荐任务变成一个二元分类问题,与预测结果代表如下:

5实验
在本节中,我们在三个数据集上评估我们提出的方法的顺序推荐。数据集在本文中,我们使用三个来自真实应用的数据集来评估我们提出的方法,这些数据集的统计量是inTable 2所示。

这些数据集都来自亚马逊,因此在它们的领域和稀疏性方面差异很大。Amazon数据集是一个公共数据集,包含条目评论和来自Amazon的元数据。它经常被用作推荐系统的基准数据集。元数据描述了商品的信息,如类别、价格和商品id,而评论描述了交互信息,如用户、商品和时间。我们选择三个子类别来验证IMfOU的表现,即电子、电影和服装,并根据时间对用户评论进行排序,得到交互序列。给定交互序列,包括titems(i1,i2,…,ik,…,it)和(t+1)-th项,任务是预测用户是否会购买(k+1)-th项。用k=1,2,…生成训练数据集n−2为每个用户。在测试集中,给定useru的物品se-quence(i1,i2,…,it),我们的目的是预测用户是否会购买(t+1)第一个物品。
5.2比较方法
我们将我们提出的IMfOU与7种主流顺序推荐方法,以及IMfOUmodel的4个变量进行比较。这些方法简要描述如下:
5.2.1基线。
·包括部分宽模型和部分深模型。深度模型基于theMLP模型进行特征匹配,而宽模型是一个线性模型,使用人工设计的跨产品特征来更好地表示用户-物品的交互。
•PNN[14]使用一个嵌入层来学习分类数据的分布式表示,和一个产品层来捕获字段间类别之间的交互模式。
•DIN[28]使用一种注意机制来捕捉用户行为对顺序推荐的重要性,并获得一个自适应的用户兴趣表示向量。
•CA-RNN[11]基于上下文感知模型,并使用自适应上下文特定的输入矩阵和转换矩阵来更好地捕获上下文信息。•NARMNARM[10]是一个基于rnn的模型,它采用注意机制从隐藏状态捕获主要目的,并将其与序列行为结合,作为序列建议的最终表示。
•DIEN[27]使用两个GRU层分别作为兴趣提取层和兴趣进化层来建模用户的连续行为。
·BST[1]使用transformer模型捕获用户行为序列中存在的序列关系。[25]使用一个时间感知控制器和thecontext感知控制器来控制状态转换,并进一步提出了一个基于注意力的框架来融合用户的长期和短期偏好。
5.2.2 IMfOU模型的变体。
•没有GLIE的IMfOU是去掉GLIE的IMfOU,它只使用了嵌入层,用来证明GLIE有利于顺序推荐。
·GLIE+BiLSTM模型是使用BiLSTM代替OPDL和UMPL的方法。目的是证明潜在用户意向模型对顺序推荐的有效性。
·GLIE+UPML使用全局顺序项嵌入来获取商品的表示向量,仅通过UPML获取当前购买动机。
·GLIE+OPDL模型是去掉UPML后的IMfOU,用来证明UPML对顺序推荐有益。
5.3实验设置
在实验中,我们使用Tensorflow来实现模型。实验环境是一个Linux服务器,使用Intel i9-9900kCPU和GTX2080Ti 11G gpu。所有嵌入向量的潜在维数设置为64,优化器为Adam。在我们的方法中,我们在以下参数中搜索最佳性能。学习速率选择{10−5,10−4,10−3,10−2},正则化选择{1e−5,1e−4,…,1e−2,1e−1}。批大小为128。相邻节点{3,4,5,6,7,8}和最近购买的商品数的最大值为{0,5,10,15,20,25}。user-item的最大长度被设置为450。用户嵌入维数设置为64,和其他有关项目信息嵌入维度是64.
5.4评价指标
本文,我们将推荐任务变成二进制clas-sification问题来预测用户是否购买nextitem,和我们的模型的输出有两个州(买或不买)。因此,我们使用AUC作为一个评价指标,衡量一个正实例比一个随机选择的负实例排名高的概率。此外,我们还使用F1-score作为评价指标。F1-score是precision和recall的调和平均值。


5.5结果和讨论我们首先给出了我们提出的方法与比较方法的对比结果,这些比较方法包括基线方法和IMfOU的变体方法。然后我们讨论最近购买的物品的数量。最后,我们将UPML中基于购买周期的意愿评分可视化,用以证明意愿评分确实有利于顺序推荐。
5.5.1与基线的比较。
为了证明我们所提出的方法比现有的方法有更好的性能,我们将所提出的方法与基线顺序推荐任务进行了比较。不同方法在AUC和f1方面的性能分别如表3和表4所示。可以看出,DIN和PNN都是没有序列机制的模型,而DIN在大多数数据集上的性能都优于PNN。PNN考虑项目之间的自发相互作用,并将所有项目视为平等。然而,除了考虑到产品之间的互动,DIN还捕捉用户的兴趣,以获得不同产品的注意力分数。这说明利用用户意愿来区分不同物品的吸引程度对顺序推荐有很大的帮助。NARM和DIEN通过RNN捕获了相等的依赖关系,其性能优于PNN和DIN。此外,CaRNN的推荐效果显著优于NARM和DIEN,说明环境上下文信息有利于推荐。然而,神经网络的阶数假设过于强大,限制了神经网络在弹性阶数序列中的应用。BST采用自注意机制捕获灵活的属性,在电子数据集和电影数据集上性能较好,在服装数据集上性能较差。从表3和表4中,我们可以观察到IMfOU在两个方面优于最先进的方法。与之前的研究不同,我们提出的方法结合了顺序模型(ODPL)和非顺序模型(UPML)来捕获顺序和灵活的依赖关系。此外,我们提出的方法不仅考虑了物品之间的顺序上下文信息,而且考虑了用户-物品交互中存在的时期上下文信息。
5.5.2与模型变体的比较。
我们还将提出的方法与不同的IMfOU模型进行了比较,目的是证明全局和局部项嵌入(GLIE)和潜在的用户意图建模组件对顺序推荐是必要和有效的。表5和表6分别显示了模型变量在AUC和f1方面的性能。从表5和表6可以看出,IMfOUis优于不带GLIE的IMfOU,而IMfOU的性能优于GLIE+OPDL。GLIE+OPDL模型优于GLIE+BiLSTM模型,这意味着我们提出的OPDL模型优于BiLSTM模型。PcGRU对用户意图的建模非常有益。IMfOU的性能显著优于GLIE+OPDL,说明UPML捕获的用户购买动机对学习用户的购买意愿有影响。电子和电影数据集GLIE+UPML比GLIE+OPDL模型性能更好;但GLIE+UPML对数据集的性能低于GLIE+OPDL。通过与这些变量的比较,我们可以得出我们所提出的GLIE和潜用户意图模型确实有利于序列推荐。


5.5.3与最近不同条目数量的比较
为了确定UPML应该处理的项数的最佳参数,我们进行了不同项数的实验。各实验的性能(AUC, f1)分别如图5(a)和图5(b)所示。从这些图表中,我们可以看到,结果是上升后下降,当最后一个项的数量为20时,我们可以获得最好的性能。电影数据集和电子数据集的结果明显大于服装数据集,这可能受到序列长度和不同数据集中的数据点数量的影响。此外,当最后一项的个数为5时,在Clothes和Moviesdatasets上的性能显著大于不使用UPML的模型。这表明无序购买动机对服装和电影数据集有重要影响,而对电子数据集的影响不大。5.5.4意愿得分可视化在UMPL中。为了证明UPML中基于购买周期的意愿评分确实能够在用户意向建模中区分不同重要程度的商品,我们将两个用户的历史序列从服装数据集中可视化。实验结果如图6所示。例如,第一个类别的项目是鞋,Mules&Clogs,拖鞋,帽子,新奇的,耳环,耳环,和太阳帽。目标项目类别是Engagement。我们可以观察到,当用户希望购买Engagement类别下的物品时,他们对管理戒指有更多的意愿,而对其他事物的意愿很少。第二组商品的类别是有纽扣的衬衫、针织衫、时尚围巾、披肩、新奇文胸、日常文胸、手提行李,目标商品类别是男士。在现实生活中,男性在商务旅行中可能会有更多的购买意愿,比如购买行李,男性购买胸罩的可能性非常小。从这两个实验的结果可以看出,我们提出的追求动机确实有利于用户意图建模。















 923
923











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









