






目录
4.1、load Diffusers pretrained models
1、前言
本文详细讲解了使用Kohya_ss gui训练SD lora的流程,包含数据处理、参数解析、报错分析等部分,并且在参数部分加入了很多个人的经验和理解,希望能对大家有所帮助。同时本文还附带了BLIP运行所需的两个大权重文件,以解决BLIP无法运行的问题。
2、数据准备
2.1、原图预处理
收集的原始图片质量可能参差不齐,在进行下一步之前最好先进行一些简单的预处理,主要是对分辨率过低的图片进行处理,提高分辨率。这里介绍SD的批量图像放大。
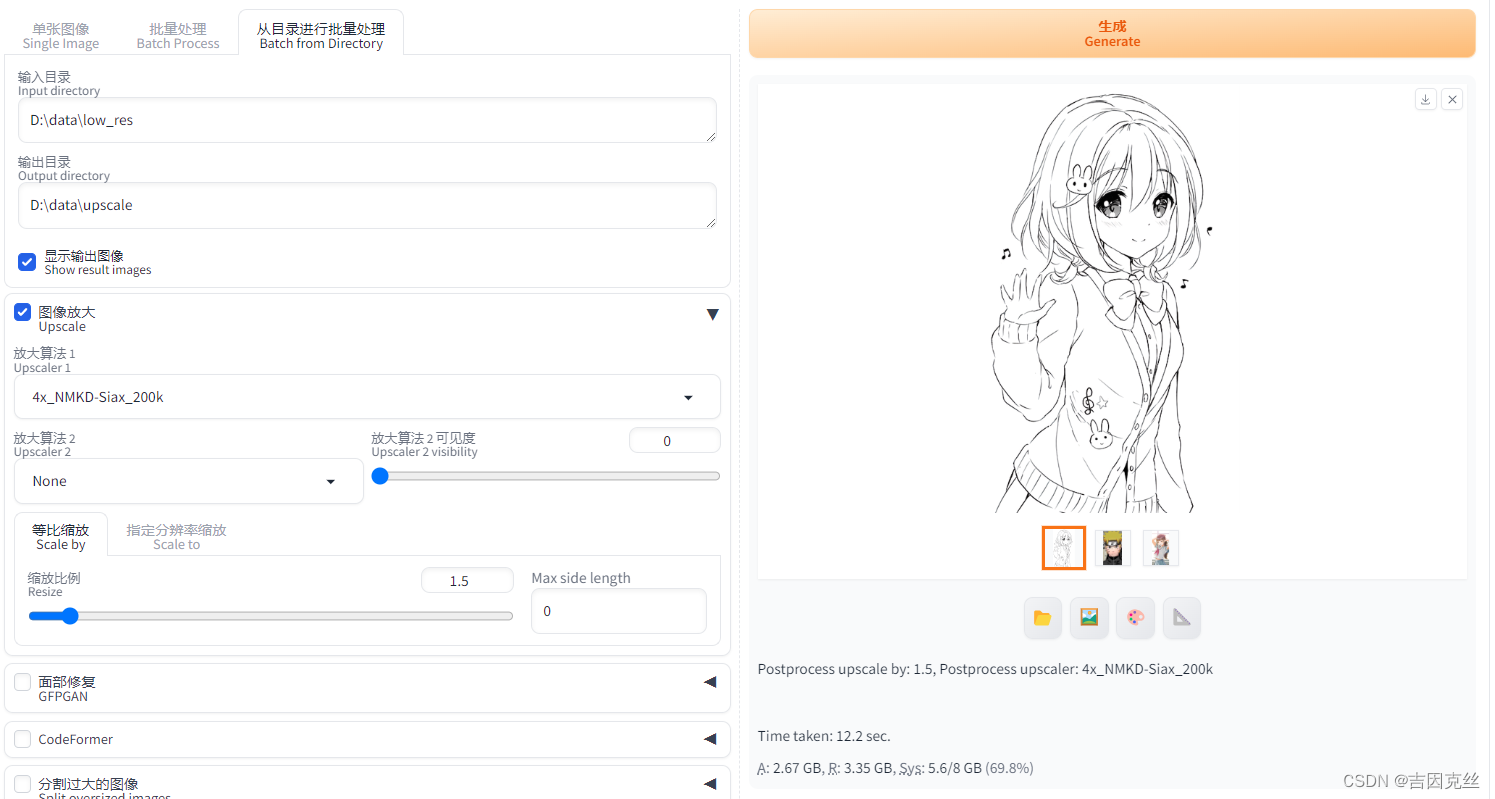
进入SD webui的附加功能(Extras)的从目录进行批量处理(Batch from Directory)页签,提前将需要提高分辨率的图片筛选出来放在一个文件夹内,填好对应输入目录和输出目录,如下图所示:

勾选图像放大(Upscale),在下拉菜单中设置放大算法及缩放比例(Scale by),放大算法可以选R-ESRGAN 4x+,如果是动漫图片可以选R-ESRGAN 4x+ Anime6B。填好后点击生成(Generate)。
注:本文主要介绍lora训练,此处所提供的图像放大方法并非最优,只是相对简单的一种方法。如果需要更好的图像放大效果,可以自行搜索Tiled Diffusion、Ultimate SD Upscaler、StableSR等方法。
2.2、图片打标签
对图片进行完预处理后下一步就是图片打标签,方法同样很多,这里还是介绍通过SD进行打标的方法。与上一步类似,打开附加功能-从目录进行批量处理,输入目录选择处理好后的图片目录(别忘记把不用放大的图片加进来),输出路径中的30表示这个文件夹内的每张图片每一轮训练30次。
取消勾选图像放大,勾选最下方的Caption,下拉菜单中勾选BLIP,这里BLIP代表以一句话的形式描述图片,如a man with a hat and a black jacket and a yellow and black jacket and a black and white background, Baiōken Eishun, anime visual, a character portrait, computer art
而Deepbooru表示以一个词一个词的形式描述,如a man, with a hat, black jacket……
两种都可以。个人习惯使用BLIP。
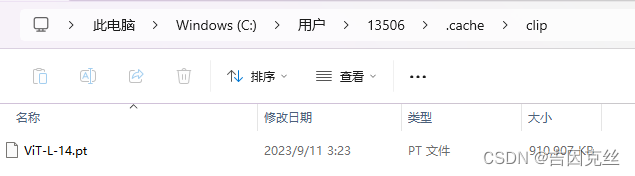
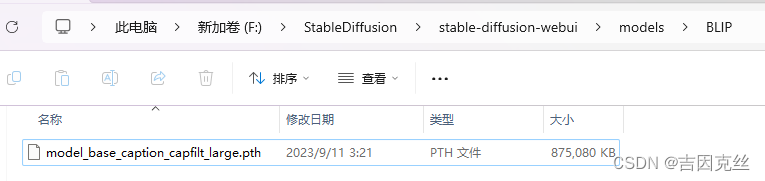
运行时在后台可以看到SD加载了models\BLIP下的model_base_caption_capfilt_large.pth文件,第一次运行,下载失败时可以手动下载此文件放在对应路径下。但可能会发现把对应文件下好放在对应目录下后运行时SD仍在下载文件。其实这时SD下的并非是这个model_base_caption_capfilt_large.pth,而是在缓存区内的ViT-L-14.pt文件。这两个文件大小差不多,很容易搞混,需要注意。我的这两个文件分享如下:
链接:https://pan.baidu.com/s/18XuUkk7nqOVQYOVifO05pg
提取码:2118
完成后会在输出目录中看到照片+同名txt标签的组合形式,如果时间允许,最好再逐个检查一下标签文件,看看有没有错漏。标签的修改也是个大项,如这里不展开,简单提一下:标签中没提到的东西会被模型认为是主体整体的一部分。比如你训练一个人物lora,每张数据都打着把红伞,但标签中没写出“Red Umbrella”,那么模型就会认为红伞也是这个人物的一部分,出的每张图都有这把伞。不理解也没关系,通常来说不去研究标签工程也能训练出很好的模型。
2.3、添加触发词
可以不仔细修改标签,但最好给每个标签前面加上一个无意义的触发词,这样使用lora的时候输入此触发词通常可以更好的让模型明白正在使用这个lora。
2.3.1、批量文首添加
在txt最前面添加东西(不换行):随便找个地方新建一个add_test.bat,编辑里面的内容如下,
其中fjdad换成想要添加的触发词,下面的路径换成txt标签所在的路径,双击运行即可。
@echo off
setlocal enabledelayedexpansion
rem 设置要添加的内容
set "content=fjdad, "
rem 设置要处理的文件夹路径
set "folder_path=D:\data\anime\30_anime"
rem 遍历文件夹中的所有txt文件
for %%f in ("%folder_path%\*.txt") do (
rem 读取文件的内容
set "file_content="
for /f "delims=" %%i in (%%f) do (
set "file_content=!file_content!%%i"
)
rem 将内容添加到文件的开头
echo !content!!file_content!>temp.txt
move /y temp.txt %%f >nul
)
echo Done.
之后txt就都变成这样了:
txt如果已经像我上图一样了,就可以跳过加触发词这一节了,后面几小节都是协助把搞错了的txt标签调回来的。
2.3.2、批量删除第一行
慎用,小心把描述文本删了。
作用是删除文件夹内所有txt的第一行。适用的情况是从别处找的txt首行添加并非在第一行前面添加内容,而是直接新加了一个第一行,此时可以用此脚本批量删掉第一行。
也就是这种情况:

用法是创建一个delete_first.bat,里面的内容填充如下,将这个文件放在需要删除首行的txt文件的同目录,双击运行。(运行完记得把这个bat文件删了,那个目录内只要图片和图片的描述文件。)N表示删除的行数,如果要删除前3行就改成3。
@ECHO OFF
SET TxtDir="%~dp0"
SET /A N=1
ECHO
ECHO
ECHO ...
CD /D %TxtDir%
FOR /F "tokens=1 delims=" %%I IN ('DIR /A /B *.txt') DO ((MORE +%N% "%%I">"%%I_")&(DEL /A /F /Q "%%I")&(REN "%%I_" "%%I"))
ECHO
PAUSE2.3.3、批量替换
慎用,小心改变了描述文本。
作用是替换文件夹内所有txt的某些文本。适用的情况是想换个触发词,比如把fjdad换成dadfj,或者想把所有的woman换成1girl,此时可以用此脚本批量替换所有txt文件。
用法是创建一个replace_text.bat,里面的内容填充如下,将这个文件放在需要批量替换的txt文件的同目录,双击运行。(运行完记得把这个bat文件删了,那个目录内只要图片和图片的描述文件。)search表示要被替换的词,replace表示替换为的词。
@echo off
setlocal enabledelayedexpansion
set "search=fjdad"
set "replace=dadfj"
for %%f in (*.txt) do (
set "outfile=%%~nf.tmp"
(for /f "usebackq delims=" %%l in ("%%f") do (
set "line=%%l"
set "line=!line:%search%=%replace%!"
echo !line!
)) > "!outfile!"
move /y "!outfile!" "%%f" >nul
)
echo Replacement complete.
pause3、训练参数
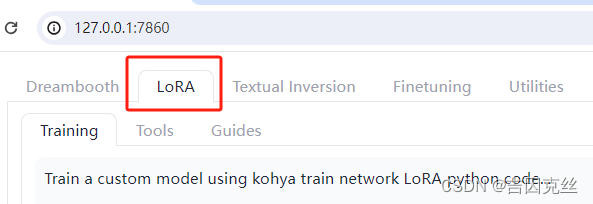
3.1、切换到LoRA
实在是被忘记这个折磨太多次了,这里一定要单开一章说一下。Kohya_ss GUI的Dreambooth和LoRA的训练界面基本上长得差不多,很容易弄混,在一切开始之前,务必在最上面切换到LoRA页签,进入LoRA的训练。
3.2、路径
3.2.1、底模路径
Pretrained model name or path:这里是选择底模的名字或者路径,stabilityai开头的就是选名字,然后训练脚本会自动去huggingface里下载对应的底模,如果使用这种方式,确保你的网络可以访问huggingface。同时第一次运行会比较久,因为要下载模型。
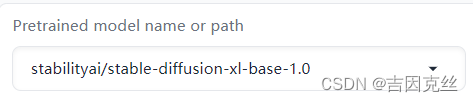
另一种方式是直接填写本地底模的路径,也就是像这个样子。
![]()
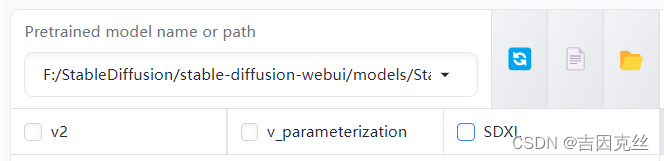
然后需要你选择你这个底模的类型,是V2还是SDXL,如果是SD1.5那就都不勾选。
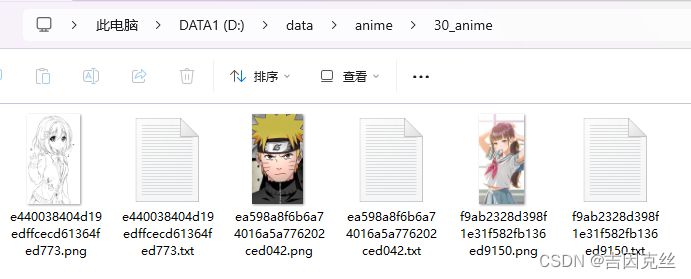
3.2.2、图片路径
Image folder (containing training images subfolders):这个就是存放训练图片的路径,需要注意,只选到30_xxx前面的那一级,比如像这个架构,此处就填D:\data\anime
这是因为这个30_anime可能并不是这个lora唯一的数据,比如说我们要训练一个人的lora,可以新建一个文件夹30_face,里面只存放人脸的数据,然后再新建一个文件夹10_body,里面存放身体的数据,让模型主要去学习人脸,每张人脸学习30次,每张身体只学习10次。(也可以通过数据量来达到类似的效果,只用一个数据集,里面放20张人脸,只放5张身体)
也就是像这样,那此处的路径就填D:\data\human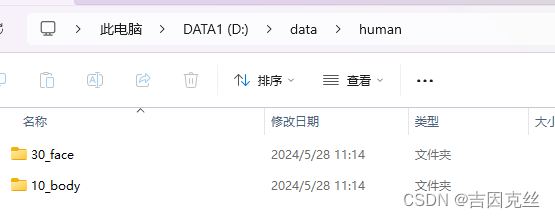
3.2.3、其它路径
点开Folders页签,里面有:
Output folder to output trained model,保存输出权重文件的路径。
Regularisation folder(Optional. containing reqularization images),存放正则化图片的路径,(这个一般用不上,我所了解只有在训练Dreambooth的时候用的比较多,是用于比如训练一个施瓦辛格的模型时,数据集描述全都是Schwarzenegger,a man,……那最后训练出的模型不管输入Schwarzenegger,还是a man,都会生成施瓦辛格的样子,如果想要模型也能生成其他男人,就需要在训练的时候加入正则化图片,通常是底模直接生成a man的图片,以作区分。)
Logging folder (Optional. to enable logging and output Tensorboard log),存放日志的路径,用于在Tensorboard中查看训练信息。这是可选的,可用可不用。多次训练调节优化器、学习率等观察它们的不同表现时可以用上。
3.3、杂项
Trained Model output name:输出模型的名字,根据情况改就行了。
Training comment:不知道,没用过。
Save trained model as:训练好的权重的保存格式,一般都选safetensors。
Save precision:保存的精度,一般都选fp16。
3.4、参数
也就是Parameters页签展开。
Presets:预设,可以用一些预设的参数,我一般不用,就保持为none。
LoRA type:LoRA的类型,通常来说都是Standard
LoRA network weights:迁移学习模型的路径,比如上一次训练中第三轮的模型表现得挺好的,但是最后第10轮学崩了,可以调整参数后在这里填上第三轮模型的路径,相当于从第三轮模型的基础上开始训练,有些时候这个功能效果挺好的。
DIM from weights:勾选后网络的dim rank就会和LoRA network weights中设置的模型的dim rank保持一致。(实际上不勾选,而两者的Network rank不一致时会报错。如果要迁移学习,还是得保证两个网络的rank一致。)
Train batch size:训练的批次,此值越大,耗显存越多,根据实际机器的表现来,但并非越大速度越快。拿4090举例,速度最快的时候大概是16的batch size,这个值调到20跟16总耗时差不多,但是调到20显存会耗的更多。(另外我通常用4090时此值调为8,这样可以边训练边用SD画图。速度方面大概是此值为16时的百分之八九十)
Epoch,训练轮数,通常10轮以内就够了,简单的任务几轮也就够了。我通常设为10(也试过20轮,后面基本上都过拟合了)。
Max train epoch Max train steps:没用过
Save every N epochs:几轮保存一次模型,空间充足就每一轮保存一次最好了,训练完了在SD中用XYZ脚本把每一轮的模型都拿来用一下,看看变化趋势,选效果最好的。(也可以边训练边测试),如果空间有限那就根据实际情况来。
Caption Extension:修改为txt。这里加红是因为它写的是Optional(可选)的,但实际上这个是得改的,不然数据集的描述文件就失效了。
Seed:随机种子,不填就是随机,填了就是按照某个随机种子来训练(即便使用相同随机种子,训练出的模型大概率也不会完全一样。)通常不填。
Cache latents:是否开启缓存latents,开了之后会增加一些耗时,减少显存消耗。
Cache latents to disk:是否把缓存的latents保存在电脑里,开了之后下次训练相同的数据就不用再重新缓存一遍latents,就不会增加耗时了。(会在图片-描述的数据集里每一张图片多产生一个latents缓存文件)
LR Scheduler:学习率调度器,通常就选择cosine(余弦退火),也可以尝试cosine_with_restarts,带restarts的余弦退火,不过感觉上跟cosine差不多。如果这里选constant_with_warmup,可以调节后面的一个参数LR warmup (% of total steps)来控制暖机的步数比例。
Optimizer:优化器,AdamW8bit最全能了。据说Lion比它好,但我实际用下来感觉Lion会没那么稳定,更可能出现损失越来越大的情况,所以后来还是都用AdamW8bit了。
Learning rate:学习率,1e-4(0.0001),5e-5(0.00005)比较常用。理论上来说需要根据数据情况、模型参数等进行调整,不过我一般就在0.0001附近就差不多了,这个值大的话模型就学的快,损失下降的快,但如果太大了也有可能会损失不降反增,或来回震荡。这个值小就学的慢,但是稳定。但是太小可能会陷入局部最优解走不出去。
Unet learning rate:Unet的学习率,通常就跟上面这个参数保持一致就好了。
Text Encoder learning rate:文本编码器的学习率,通常设为他俩的一半。(实际上4090训练SDXL的时候需要设置不训练文本编码器,这个值应该没啥用。)
Max resolution:可以认为是所训练的lora的分辨率,这个值为多少,lora就在多少分辨率下表现最好,一般跟底模相同,如果是SD1.5那就设成512,512,如果是SDXL就设成1024,1024,当然如果机器没那么好,或者数据集中大部分分辨率没1024这么大,设成768,768也是可以的。
Stop text encoder training (% of total steps):停止训练文本编码器的步数,一般不用管。SDXL会直接设置不训练文本编码器。
Enable buckets:是否开启buckets,以及buckets的最大最小分辨率,这个通常是要开的,它会自动的把数据裁剪成前面Max resolution所设分辨率周围的,各种形状的数据。这样的好处是可以增加训练出来模型的泛化性,如果不开,可能模型只会画正方形的,分辨率一旦设为长方形就效果不好了。开了之后训练数据里就各种形状都有了。
Minimum/Maximum bucket resolution:bucket的最大最小分辨率,通常不用修改,如果数据集里有特别特别小的图片,可以适当降低Minimum bucket resolution(但还是建议先对这样的图片进行分辨率提升再拿来训练。)
Network Rank (Dimension):网络的规模,这一项在SD1.5和SDXL里还颇为不同,对于XL来说,简单的任务32或者16,复杂一点的给64,已经是很高的配置了,很少会遇到需要给128的时候,而SD1.5中通常都是64、128、256。这个数字越大,模型的学习能力越强,最后生成的模型文件的大小也越大。如果感觉数据集里的元素太多,模型有点学不懂了,可以增加此项的值。
Network Alpha:对权重进行缩放,它的思路是神经网络的权重容易接近0,就通过这一项以一定的比例来在训练过程中对权重进行削弱,让权重看起来比较小,但实际保存的时候比较大,实际保存的时候就不容易接近0了。我通常不会用到它,它的削弱比例是Network Alpha/Network Rank,如果不想用的话就让它和Network Rank相等就行了。
SDXL Specific Parameters:训练SDXL时才会有的参数选项,分别是Cache text encoder outputs和No half VAE,前者可以降低显存消耗,后者不勾选由于某些bug会报错。建议都勾选。
3.5、高级参数
也就是Advanced选项卡打开
3.5.1、禁用文本编码器
在Additional parameters处填入--network_train_unet_only,此选项的目的是仅训练Unet而不训练text encoders这也是官方建议的做法,官方说:
强烈建议选择SDXL LoRA。因为SDXL有两个文本编码器,所以训练的结果会出乎意料。

3.5.2、梯度检查点
勾选Gradient checkpointing,这一项通过在前向传播的过程中将某些中间结果临时储存,而不是一直保留,可以显著减少显存需求。它会增加耗时,但是由于显存需求降低了,可以使用更大的Batchsize,所以整体耗时是降低的。
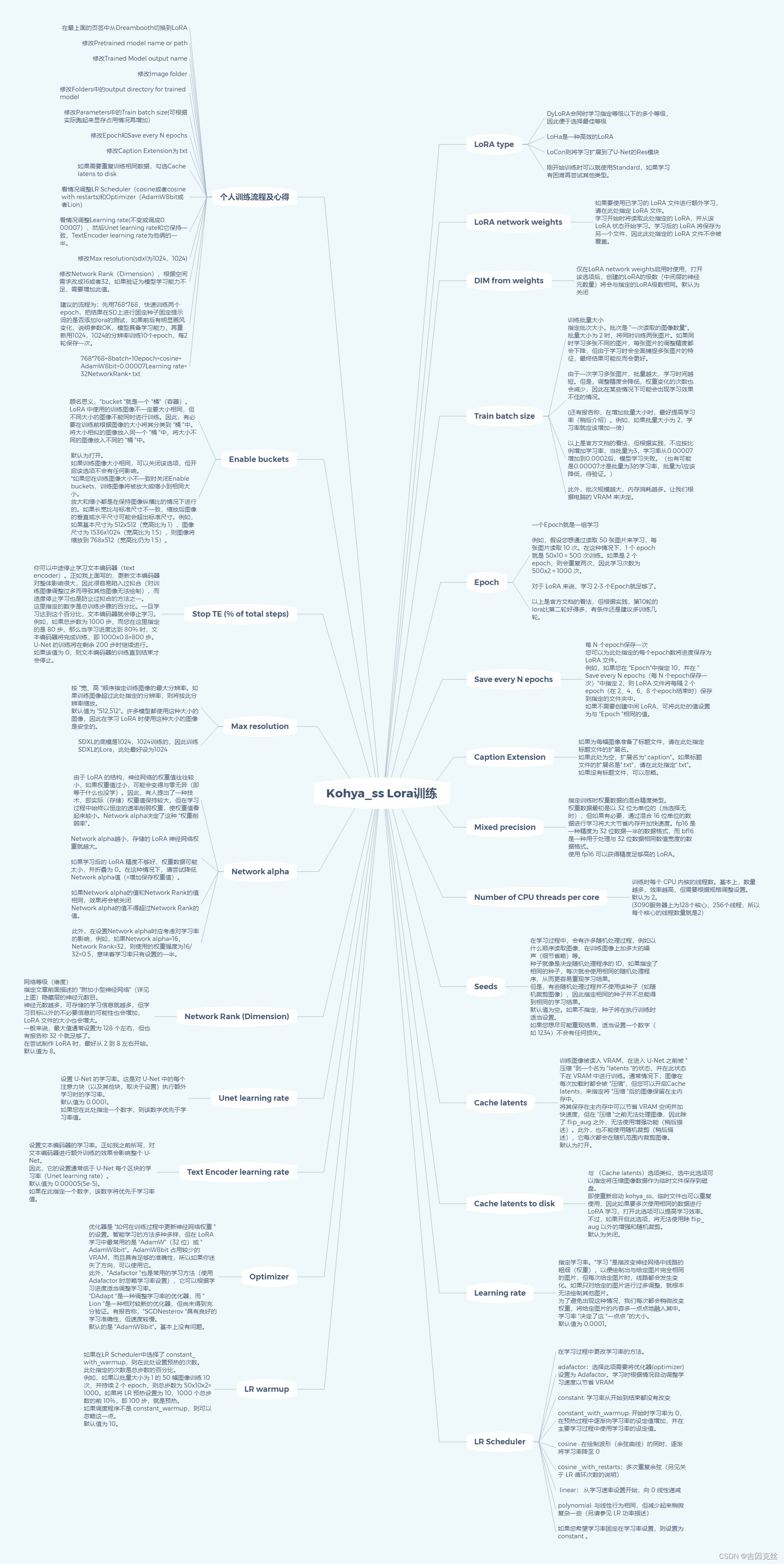
3.6、思维导图
顺便贴一张自己之前做的思维导图,其中参数的解析基本都是从官网翻译过来的。
4、一些错误
一些常见的错误在kohya_ss的终端上就能看到,如显存不足,路径为空之类的,这里列出一些不太看得出来原因的错误
4.1、load Diffusers pretrained models
在load Diffusers pretrained models: stabilityai/stable-diffusion-xl-base-1.0, variant=fp16 处卡了很久,原因是底模路径那儿填的是名字,然后电脑无法访问huggingface,建议手动下载对应底模然后换成路径的形式使用。
4.2、更改分辨率无法训练
开启过一次训练后,更改分辨率,再次训练,会无法训练,但没有报错,此时重启服务重新点击开始训练可以解决。
4.3、完成训练后无法训练
完成一次完整的训练后,相同文件名再次开始训练会无法训练,删掉之前训练的结果,或者换一个保存名可以解决。
4.4、相同参数无法训练
一切看起来都很正常,突然就怎么都运行不起来训练了,就算是相同参数。此时先停掉SD再开启训练也许可以解决。应该是内存不足(RAM不足,而非显存VRAM不足),换了台电脑之后没出现过这个问题。

















 1643
1643

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









