






DeepSeek-R1火遍海内外,但推理服务器频频宕机,专享版按GPU小时计费的天价成本更让中小团队望而却步。
而市面上所谓“本地部署”方案,多为参数量缩水90%的蒸馏版,背后原因是671B参数的MoE架构对显存要求极高——即便用8卡A100也难以负荷。因此,想在本地小规模硬件上跑真正的DeepSeek-R1,被认为基本不可能。
但就在近期,清华大学KVCache.AI团队联合趋境科技发布的KTransformers开源项目公布更新:
支持24G显存在本地运行DeepSeek-R1、V3的671B满血版。预处理速度最高达到286 tokens/s,推理生成速度最高能达到14 tokens/s。
其实早在DeepSeek-V2 时代,这个项目就因“专家卸载”技术而备受关注——它支持了236B的大模型在仅有24GB显存的消费级显卡上流畅运行,把显存需求砍到10分之一。
随着DeepSeek-R1的发布,社区的需求迅速激增,在GitHub盖起上百楼的issue,呼吁对其进行支持。
版本更新发布后,不少开发者也纷纷用自己的3090显卡和200GB内存进行实测,借助与Unsloth优化的组合,Q2_K_XL模型的推理速度已达到9.1 tokens/s,真正实现了千亿级模型的“家庭化”。
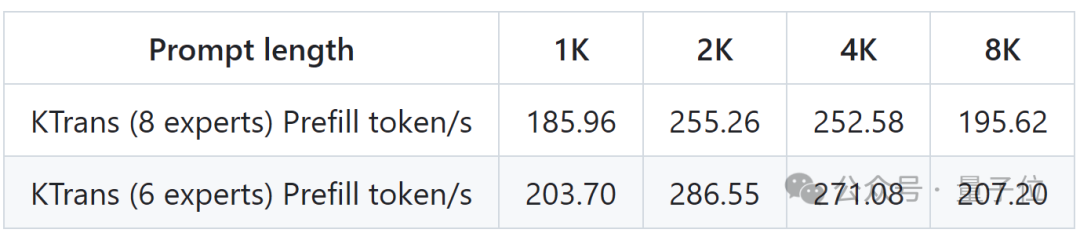
此外,KTransformers团队还公布了v0.3预览版的性能指标,将通过整合Intel AMX指令集,CPU预填充速度最高至286 tokens/s,相比llama.cpp快了近28倍。对于那些需要处理上万级Token上下文的长序列任务(比如大规模代码库分析)来说,相当于能够从“分钟级等待”瞬间迈入“秒级响应”,彻底释放CPU的算力潜能。
另外,KTransformers还提供了兼容Hugginface Transformers的API与ChatGPT式Web界面,极大降低了上手难度。同时,其基于YAML的“模板注入框架”能够灵活切换量化策略、内核替换等多种优化方式。
目前,KTransformers在localLLaMa社区持续位居热榜第一,有上百条开发者的讨论。
项目背后的技术细节,团队也给出了详细介绍。
利用MoE架构的稀疏性
DeepSeek-R1/V3均采用了MoE(混合专家)架构,这种架构的核心是将模型中的任务分配给不同的专家模块,每个专家模块专注于处理特定类型的任务。MoE结构的模型具有很强的稀疏性,在执行推理任务的时候,每次只会激活其中一部分的模型参数。
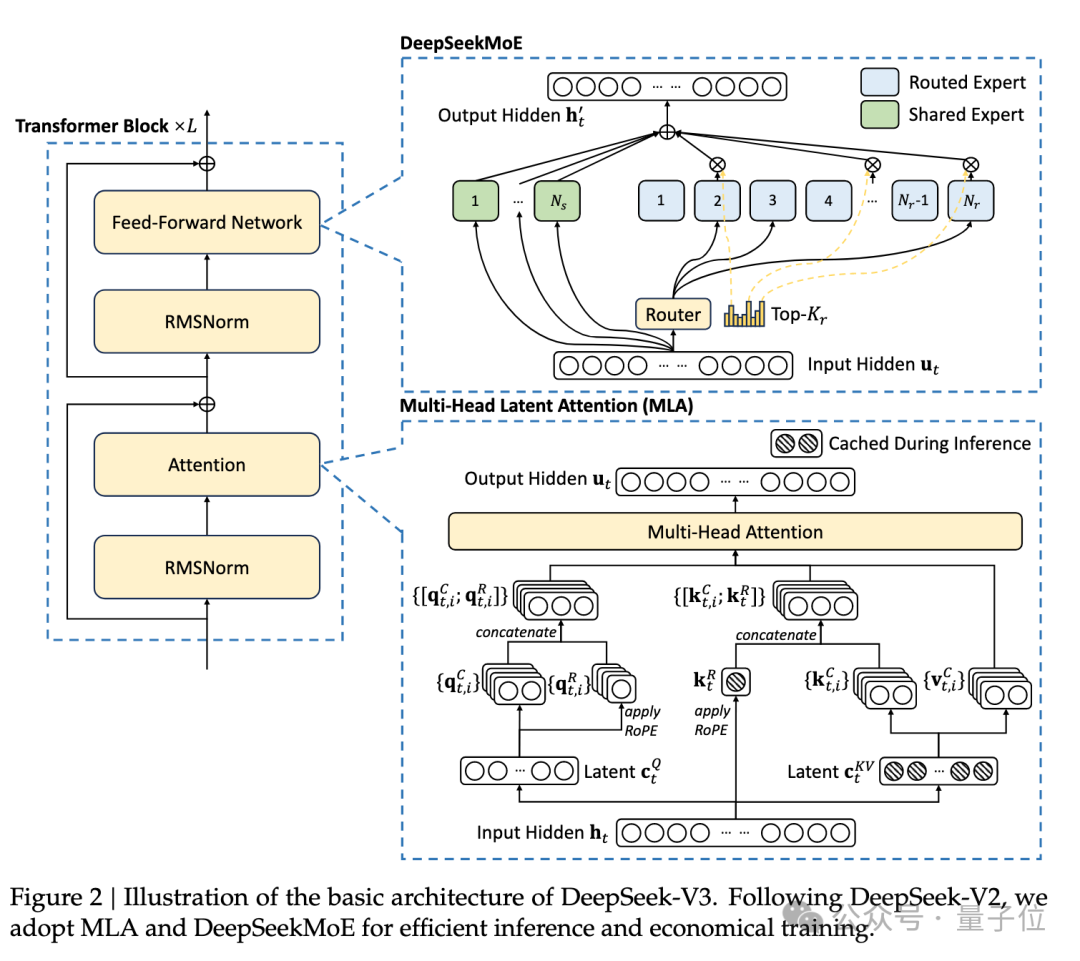
因此,MoE架构需要大量的存储空间,但是并不需要很多的计算资源。
基于此,团队采用了GPU/CPU的异构计算划分策略:仅将非Shared部分的稀疏MoE矩阵放在CPU/DRAM上并使用llamafile提供的高速算子处理,剩余稠密部分放在GPU上使用Marlin算子处理。
在这样的情况下,同样使用4bit量化,GPU上的参数只需要24GB的显存环境,这样的消耗只需要一张4090就能满足。
此外通过这样的组合,还能够大幅度提升整个推理的性能,达到286 token/s的预填充和14 token/s的生成速度,比llama.cpp快28倍。
具体到技术实现中,团队采用了基于计算强度的offload策略、高性能的CPU和GPU算子、CUDA Graph加速的多种方式来加速推理速度。
基于计算强度的offload策略
在Attention的核心,DeepSeek引入了一种新的MLA算子,它能够充分利用显卡算力,能够很大程度提升效率。然而,MLA运算符在官方开源的v2版本中,是将MLA展开成MHA进行的计算,这个过程不仅扩大了KV cache大小,还降低了推理性能。
为了真正发挥MLA的性能,在KTransformers推理框架中,团队将矩阵直接吸收到q_proj和out_proj权重中。因此,压缩表示不需要解压缩来计算Attention。
这种调整显著减少了KV缓存大小,并增加了该运算符的算术强度,这非常显著地优化了GPU计算能力的利用率。
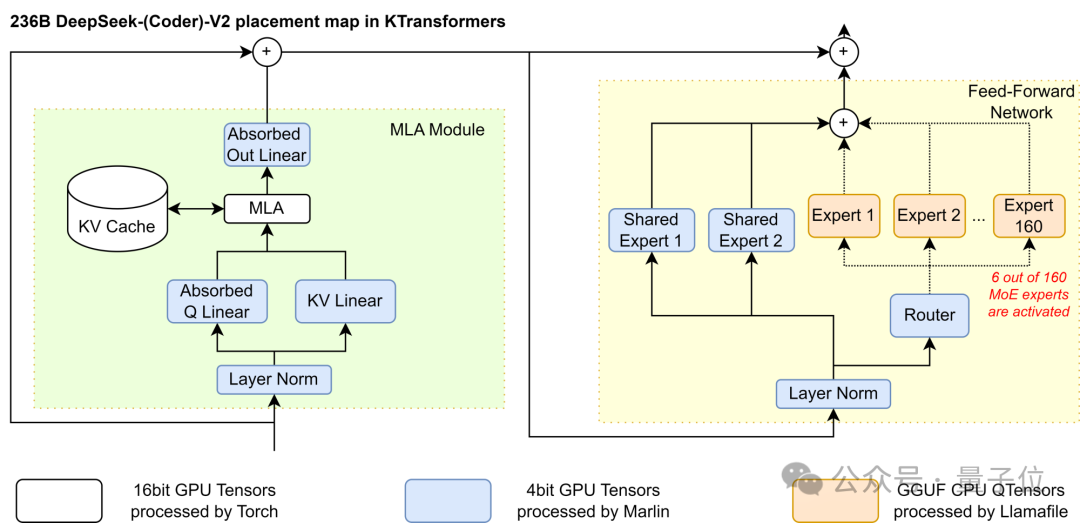
在计算中,MLA和Expert的计算强度相差数千倍。因此,团队通过计算强度来决定划分策略,优先将计算强度高的放入GPU(MLA > Shared Expert > Routed Expert),直到GPU放不下为止。
引入CPU和GPU的高性能算子
在CPU算子中,团队使用llamafile作为CPU内核,使用expert并行和其他优化,组成高性能算子框架CPUInfer。此外增加多线程、任务调度、负载均衡、NUMA感知等优化。
在GPU算子的使用上,团队引入Marlin算子作为GPU计算的内核,它能够非常高效地进行量化后的矩阵计算,和torch这些计算量化后的矩阵乘法的库相比,使用Marlin算子完成在GPU上面的计算大概可以达到3.87倍的理想加速效果。
CUDA Graph的改进和优化
为了平衡推理性能和框架本身的易用性/可扩展性,基于Python构建KTransformers框架,同时使用CUDA Graph降低Python调用开销是一个必然的选择。
KTransformers中使用CUDA Graph过程中尽可能地减少了CPU/GPU通讯造成的断点,在CUDA Graph中掺杂和CPU异构算子通讯,最终实现一次decode仅有一个完整的CUDA Graph调用的结果。
灵活高效的推理实验平台
值得关注的是,KTransformers不止是一个固定的推理框架,也不只能推理DeepSeek的模型,它可以兼容各式各样的MoE模型和算子,能够集成各种各样的算子,做各种组合的测试。
此外还同时提供了Windows、Linux的平台的支持,方便运行。
当大模型不断往上卷,KTransformers用异构计算打开一条新的推理路径。基于此,科研工作者无需巨额预算也能够探索模型本质。
如何使用KTransformers?
使用KTransformers非常简单,以下是基本步骤:
-
安装依赖
pip install ktransformers -
加载模型
from transformers import AutoModelForCausalLM import torch with torch.device("meta"): model = AutoModelForCausalLM.from_config(config, trust_remote_code=True) -
优化和加载模型
from ktransformers import optimize_and_load_gguf optimize_and_load_gguf(model, optimize_rule_path, gguf_path, config) -
生成文本
generated = prefill_and_generate(model, tokenizer, input_tensor.cuda(), max_new_tokens=1000)
性能对比:KTransformers vs llama.cpp
| 指标 | llama.cpp(双节点,64核) | KTransformers(双节点,64核) | 提升倍数 |
|---|---|---|---|
| Prefill Speed | 10.31 tokens/s | 286.55 tokens/s | 27.79× |
| Decode Speed | 4.51 tokens/s | 13.69 tokens/s | 3.03× |
从上表可以看出,KTransformers在性能上远超llama.cpp,尤其是在Prefill阶段,速度提升了27.79倍!
KTransformers的适用场景
-
本地开发和测试
如果您希望在本地快速开发和测试大模型,KTransformers是一个理想的选择。 -
资源受限的环境
对于硬件资源有限的开发者,KTransformers可以通过优化和量化,让模型在有限的资源下运行得更好。 -
高性能推理需求
如果您需要在本地实现高性能的模型推理,KTransformers的多GPU和异构计算支持能够满足您的需求。
GitHub 地址:https://github.com/kvcache-ai/ktransformers


















 205
205

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









