







前沿: electra训练模型,可以说是训练框架和预训练任务的一个改良吧。
首先整体框架是这样的。
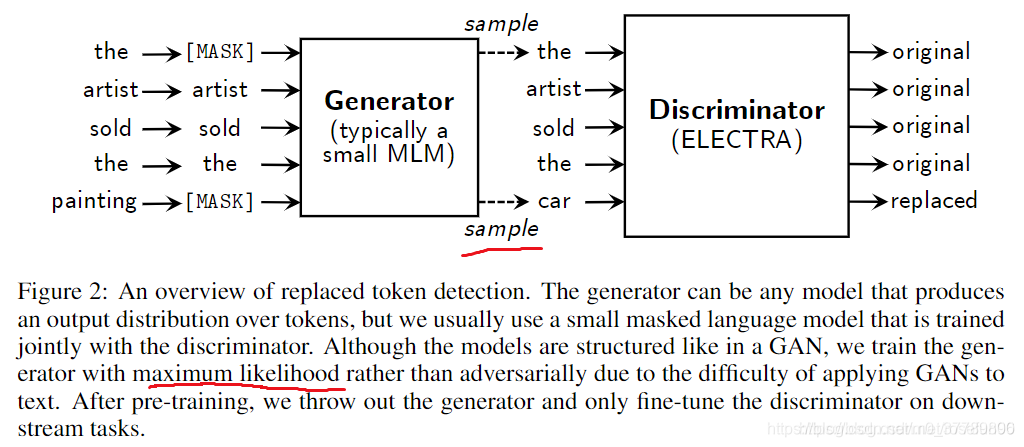
-
原先MLM是通过对[mask]位置直接进行预测,然后给出损失,也就是交叉熵的计算。
-
然而electra不是,生成器会首先对[mask]位置的部分进行预测,也就是一个MLM任务(可以理解为是对简单的位置先进行预测,然后将难的部分交给了判别器),然后对预测结果,进行判别器预测。
-
此时判别器预测值只有2类,也就是是否是原文中出现过,成功将原先MLM任务转化成为了两个任务,而且。这里面判别器计算需要考虑所有的单词,然而原先的MLM任务实际考虑的只有那15%的单词。甚至还不一定有。。。
-
并且需要注意electra的生成器和判别器的梯度并不会由一个模型传给另一个模型,而是考虑进行多任务联合训练的方式进行。

















 3355
3355

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









