






本次使用随机森林通过十折交叉验证得到最大平均精度为99%
1.导入相应包
from sklearn.tree import DecisionTreeClassifier
from matplotlib import pyplot as plt
from sklearn.ensemble import RandomForestClassifier
from sklearn.datasets import load_wine
from sklearn.model_selection import train_test_split
from sklearn.model_selection import cross_val_score
2.准备数据集
wine = load_wine()
wine.data
wine.target
3.划分训练测试集
#划分训练测试集
Xtrain, Xtest, Ytrain, Ytest = train_test_split(wine.data, wine.target, test_size=0.3)
4.对比单个决策树和随机森林
clf = DecisionTreeClassifier(random_state=0)
rfc = RandomForestClassifier(random_state=0)
clf.fit(Xtrain, Ytrain)
rfc.fit(Xtrain, Ytrain)
score_c = clf.score(Xtest, Ytest)
score_r = rfc.score(Xtest, Ytest)
print("single Tree is {}".format(score_c), "Random forest is {}".format(score_r))
5.对比单个决策树和随机森林十折交叉验证精度
rfc = RandomForestClassifier(n_estimators=25)
rfc_s = cross_val_score(rfc, wine.data, wine.target, cv=10)
clf = DecisionTreeClassifier()
clf_s = cross_val_score(clf, wine.data, wine.target, cv=10)
plt.plot(range(1, 11), rfc_s, label='Random forest')
plt.plot(range(1, 11), clf_s, label='Decision Tree')
plt.xticks(range(1, 11))
plt.legend()
plt.show()
此段代码一种高级写法为:
#高级写法:将模型写入列表通过for遍历对比精度
label = 'Random Forest'
for model in [RandomForestClassifier(n_estimators=25), DecisionTreeClassifier()]:
score = cross_val_score(model, wine.data, wine.target, cv=10)
print("{}:".format(label)), print(score.mean())
plt.plot(range(1,11), score, label=label)
plt.legend()
label = "Decision Tree"
得到图像为:

6.对比十次单个决策树和随机森林的精度
rfc_l = []
clf_l = []
for i in range(10):
rfc = RandomForestClassifier(n_estimators=25)
rfc_s = cross_val_score(rfc, wine.data, wine.target, cv=10).mean()
rfc_l.append(rfc_s)
clf = DecisionTreeClassifier()
clf_s = cross_val_score(clf, wine.data, wine.target, cv=10).mean()
clf_l.append(clf_s)
plt.plot(range(1,11),rfc_l,label = "Random Forest")
plt.plot(range(1,11),clf_l,label = "Decision Tree")
plt.legend()
plt.show()
对比结果图为:

从结果中我们可以看出随机森林对比单个决策树分类精度整体高很多,这也说明随机森林的强大。
7.不同n_estimators随机森林学习曲线
#n_estimators学习曲线
superna = []
for i in range(50):
rfc = RandomForestClassifier(n_estimators=i+1)
rfc_s = cross_val_score(rfc, wine.data, wine.target, cv=10).mean()
superna.append(rfc_s)
print("max is {}".format(max(superna)), "index is {}".format(superna.index(max(superna))))
plt.figure(figsize=[20, 5])
plt.plot(range(1, 51), superna)
plt.show()
学习曲线图为:
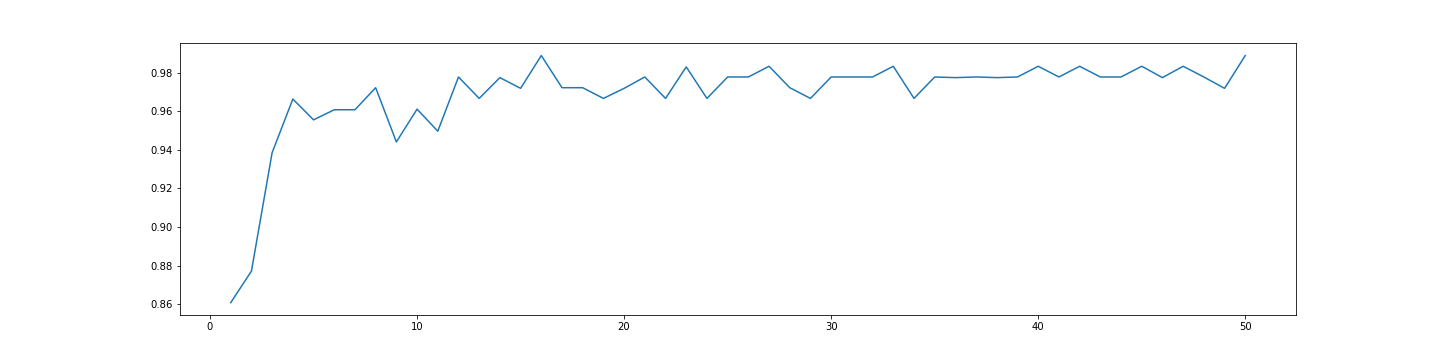
得到的最大精度以及n_estimators参数值为15,这说明随着n_estimators的不短增加,精度也会逐渐增大,但是到了一定阈值,精度就会在最大值附近波动。
max is 0.9888888888888889 index is 15
8.自主法划分训练集
#设置
rfc = RandomForestClassifier(n_estimators=25, oob_score=True)
rfc.fit(wine.data, wine.target)
rfc.oob_score_
得到的精度为:
0.9831460674157303
9.其他参数
rfc = RandomForestClassifier(n_estimators=25)
rfc.fit(Xtrain, Ytrain)
rfc.score(Xtest, Ytest)
#属性重要性
rfc.feature_importances_
#输入特征集输出叶子结点索引
rfc.apply(Xtest)
#输入特征集输出类别
rfc.predict(Xtest)
#输入特征集输出分类可能性
rfc.predict_proba(Xtest)
9.集成算法的一个重要要求
之前我们说过,在使用袋装法时要求基评估器要尽量独立。其实,袋装法还有另一个必要条件:基分类器的判断准确率至少要超过随机分类器,即时说,基分类器的判断准确率至少要超过50%,不然袋装法的精确率要比单棵决策树效果更差。
import numpy as np
import math
x = np.linspace(0, 1, 20)
y = []
for epsilon in x:
E = np.array([math.comb(25,i)*(epsilon**i)*((1-epsilon)**(25-i))
for i in range(13,26)]).sum()
y.append(E)
plt.plot(x,y,"o-",label="when estimators are different")
plt.plot(x,x,"--",color="red",label="if all estimators are same")
plt.xlabel("individual estimator's error")
plt.ylabel("RandomForest's error")
plt.legend()
plt.show()
得到的对比图如下:

所以我们需要保证每个决策树的准确率大于50%,才可以使用袋装法随机森林进行预测。














 779
779











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









