







KGQA与KGE
关于KGQA以及知识图谱嵌入的简单介绍可以看之前的两篇博客:
这篇论文就是结合知识图谱嵌入(KGE)来进行多跳知识问答
EmbedKGQA
MetaQA数据
实验数据集是MetaQA数据集,该数据集是基于电影知识图谱的电影问答。下载链接
提供的KG
我们需要提供的KG,因为我们要预先训练KG中每一个实体的embedding。KG如下:

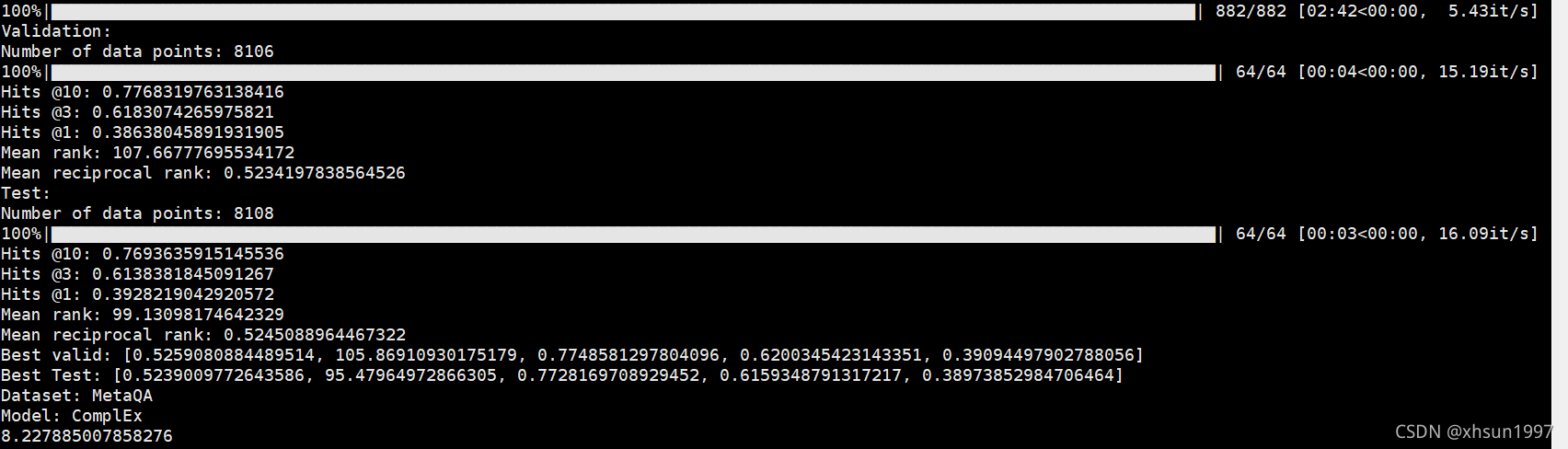
比如,用ComplEx这个KGE模型训练MetaQA知识图谱得到的结果:
提供的QA数据

提供的QA数据就是由(q,a) pairs组成的数据集,每一个(q,a)对中,问题q包含一个实体,由中括号标出。
每一个答案a就是KG中的一个实体。
模型流程
流程图如下:
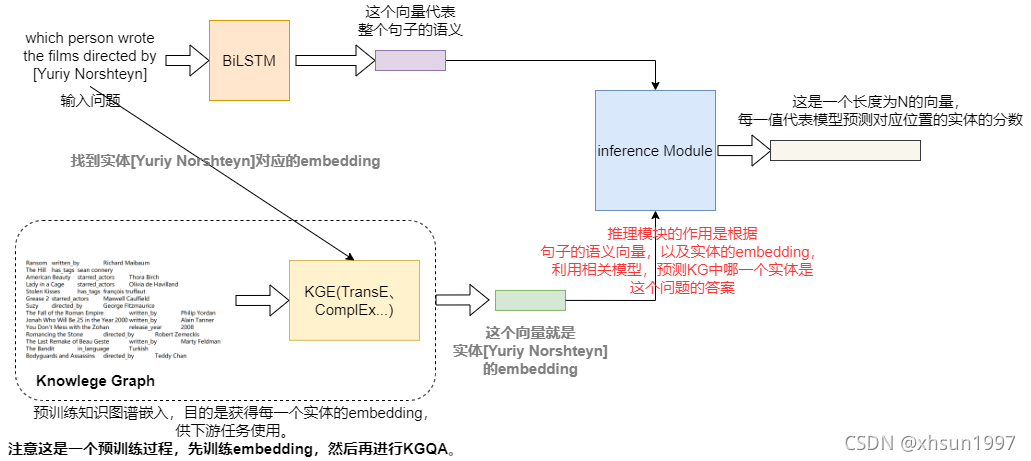
模型流程:
- 首先利用相关的KGE模型预训练,获得每一个实体的embedding,记为entity_embed_matrix
- 对于QA数据集中的每一个样本,取出question中的实体名词,从entity_embed_matrix中找到这个实体名词对应的embedding,记为head_embed
- 将question中的实体名词用统一字符NE替代,然后将question输入到BiLSTM中,取前向的最后一个时刻与反向的第一个时刻的hidden state的结合作为整个句子语义的embedding,记为question_embed
- 然后将head_embed与question_embed输入到ComplEx模型中(目的是推理),得到一个长度为N的向量,记为predict,这个N代表所有实体的数量,比如实验提供的KG数据集中数量是43234
- predict中每一个数值代表模型预测对应实体的分数,比如predict中第二个数字是0.0045,那么代表模型预测当前question对应的答案是KG中第二个实体的分数是0.0045
测试指标可以用准确率衡量,也就是模型预测的predict中,分数最高的那个位置对应的实体是否是真正的answer。

















 2136
2136

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









