







1.神经网络:搭建小实战和Sequential的使用
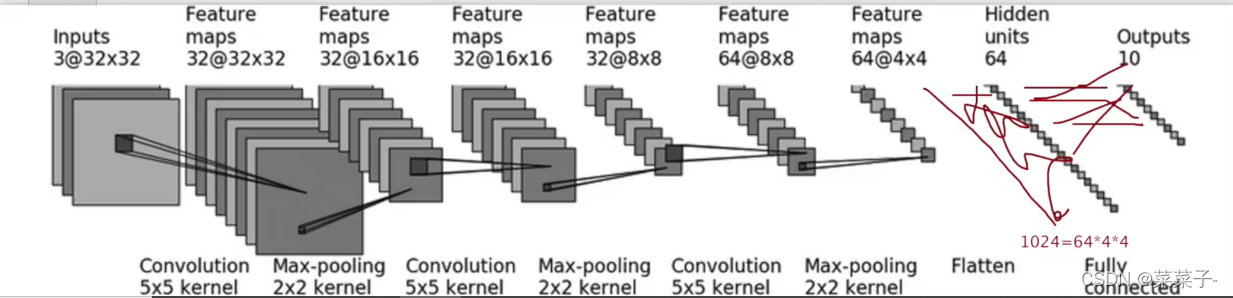
以CIFAR10 model为例

import torch
import torchvision
from tensorboardX import SummaryWriter
from torch import nn
from torch.nn import ReLU, Sigmoid, Linear, Conv2d, MaxPool2d, Flatten
from torch.utils.data import DataLoader
class test_cifar(nn.Module):
def __init__(self) -> None:
super(test_cifar, self).__init__()
self.conv1 = Conv2d(3, 32, 5, padding=2)
self.maxpool1 = MaxPool2d(2)
self.conv2 = Conv2d(32, 32, 5, padding=2)
self.maxpool2 = MaxPool2d(2)
self.conv3 = Conv2d(32, 64, 5, padding=2)
self.maxpool3 = MaxPool2d(2)
self.flatten = Flatten()
self.linear1 = Linear(1024, 64)
self.linear2 = Linear(64, 10)
def forward(self, x):
x = self.conv1(x)
x = self.maxpool1(x)
x = self.conv2(x)
x = self.maxpool2(x)
x = self.conv3(x)
x = self.maxpool3(x)
x = self.flatten(x)
x = self.linear1(x)
x = self.linear2(x)
return x
test = test_cifar()
print(test)
input = torch.ones((64, 3, 32, 32)) # 生成一个全是1的测试数据
output = test(input)
print(output.shape) # torch.Size([64, 10]) 说明网络搭建应该没问题
如果网络中间有地方错误,可以通过这部分代码进行测试
test = test_cifar()
print(test)
input = torch.ones((64, 3, 32, 32)) # 生成一个全是1的测试数据
output = test(input)
print(output.shape) # torch.Size([64, 10]) 说明网络搭建应该没问题
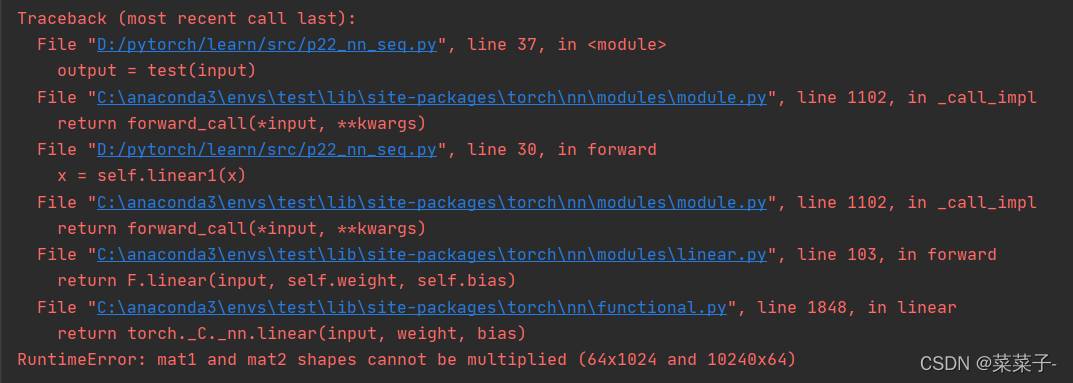
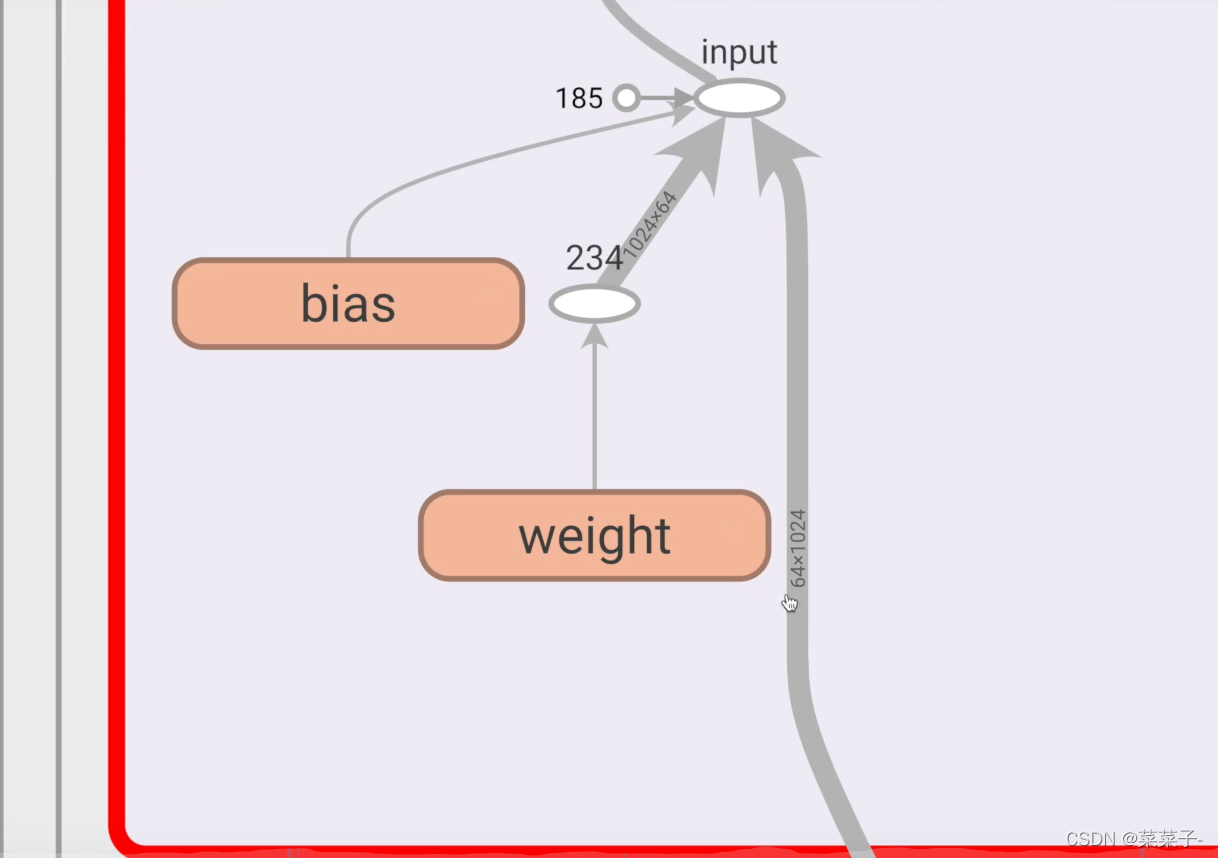
假如说,我把
self.linear1 = Linear(1024, 64)中的1024改成了10240
那么就会报错
改成Sequential代码就会变得非常简洁
import torch
import torchvision
from tensorboardX import SummaryWriter
from torch import nn
from torch.nn import ReLU, Sigmoid, Linear, Conv2d, MaxPool2d, Flatten, Sequential
from torch.utils.data import DataLoader
class test_cifar(nn.Module):
def __init__(self) -> None:
super(test_cifar, self).__init__()
self.model1 = Sequential(
Conv2d(3, 32, 5, padding=2),
MaxPool2d(2),
Conv2d(32, 32, 5, padding=2),
MaxPool2d(2),
Conv2d(32, 64, 5, padding=2),
MaxPool2d(2),
Flatten(),
Linear(1024, 64),
Linear(64, 10)
)
def forward(self, x):
x = self.model1(x)
return x
test = test_cifar()
print(test)
input = torch.ones((64, 3, 32, 32)) # 生成一个全是1的测试数据
output = test(input)
print(output.shape) # torch.Size([64, 10]) 说明网络搭建应该没问题
用tensorboardX展示
(这里我报错!!!!!不知道为什么!!!看视频效果很牛逼,求解)
# 这个代码报错,没找到问题所在
import torch
import torchvision
from tensorboardX import SummaryWriter
from torch import nn
from torch.nn import ReLU, Sigmoid, Linear, Conv2d, MaxPool2d, Flatten, Sequential
from torch.utils.data import DataLoader
class test_cifar(nn.Module):
def __init__(self) -> None:
super(test_cifar, self).__init__()
self.model1 = Sequential(
Conv2d(3, 32, 5, padding=2),
MaxPool2d(2),
Conv2d(32, 32, 5, padding=2),
MaxPool2d(2),
Conv2d(32, 64, 5, padding=2),
MaxPool2d(2),
Flatten(),
Linear(1024, 64),
Linear(64, 10)
)
def forward(self, x):
return x
test_model = test_cifar()
print(test_model)
input = torch.ones((64, 3, 32, 32)) # 生成一个全是1的测试数据
output = test_model(input)
print(output.shape) # torch.Size([64, 10]) 说明网络搭建应该没问题
writer = SummaryWriter("../logs_seq")
writer.add_graph(test_model, input)
writer.close()
2.损失函数
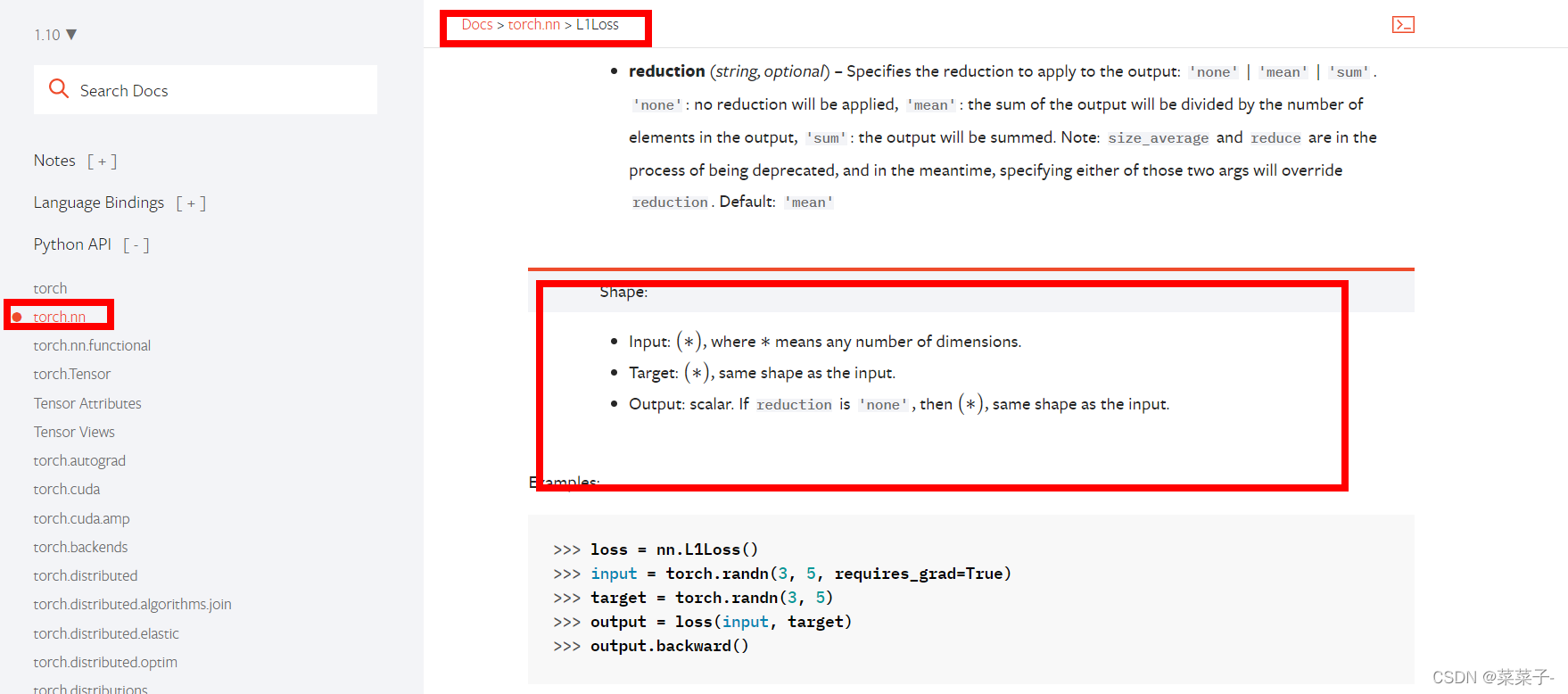
以L1loss为例
import torch
from torch.nn import L1Loss
inputs = torch.tensor([1, 2, 3], dtype=torch.float32)
targets = torch.tensor([1, 2, 5], dtype=torch.float32)
inputs = torch.reshape(inputs, (1, 1, 1, 3))
targets = torch.reshape(targets, (1, 1, 1, 3))
loss = L1Loss()
result = loss(inputs, targets) # tensor(0.6667)
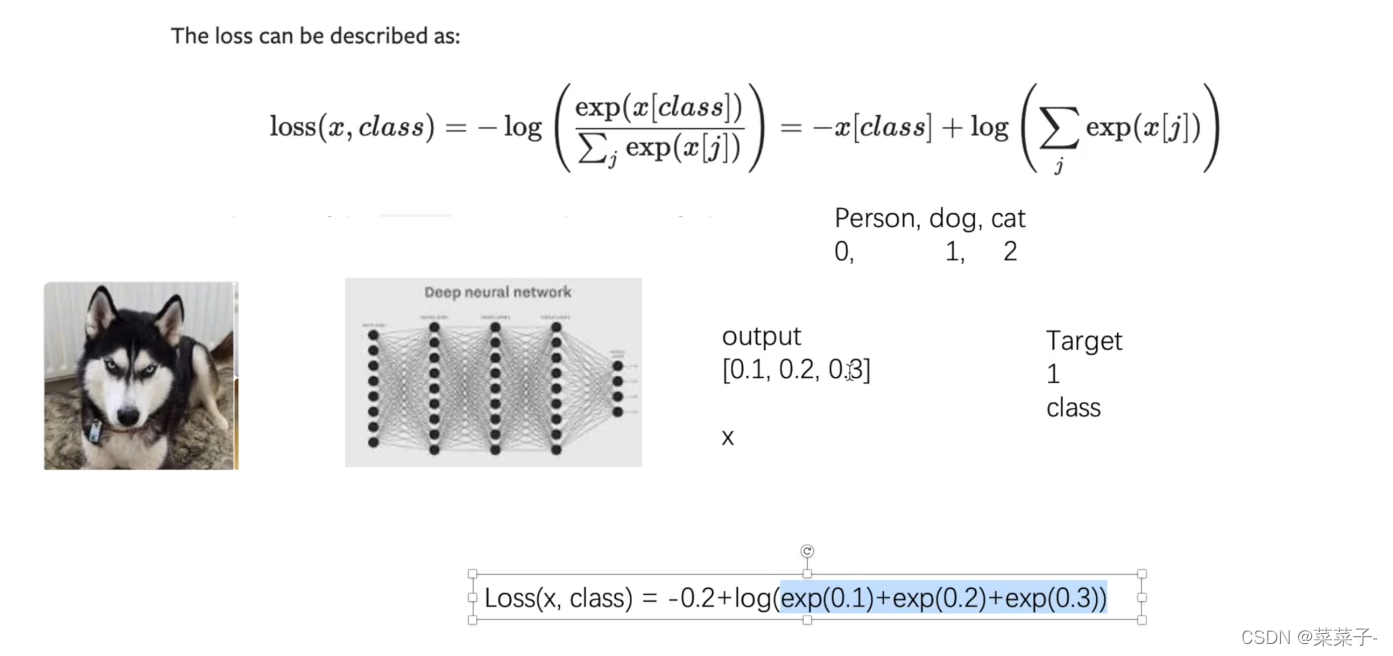
交叉熵
import torch
from torch.nn import L1Loss
from torch import nn
inputs = torch.tensor([1, 2, 3], dtype=torch.float32)
targets = torch.tensor([1, 2, 5], dtype=torch.float32)
inputs = torch.reshape(inputs, (1, 1, 1, 3))
targets = torch.reshape(targets, (1, 1, 1, 3))
# L1Loss
loss = L1Loss()
result = loss(inputs, targets) # tensor(0.6667)
# MSELoss
loss_mse = nn.MSELoss()
result_mse = loss_mse(inputs, targets) # tensor(1.3333)
# CrossEntropyLoss
x = torch.tensor([0.1, 0.2, 0.3])
y = torch.tensor([1])
x = torch.reshape(x, (1, 3))
loss_cross = nn.CrossEntropyLoss()
result_cross = loss_cross(x, y)
print(result_cross) # tensor(1.1019)
3.反向传播
利用cifar10网络进行loss和反向传播的测试
import torch
import torchvision
from tensorboardX import SummaryWriter
from torch import nn
from torch.nn import ReLU, Sigmoid, Linear, Conv2d, MaxPool2d, Flatten, Sequential
from torch.utils.data import DataLoader
class test_cifar(nn.Module):
def __init__(self) -> None:
super(test_cifar, self).__init__()
self.model1 = Sequential(
Conv2d(3, 32, 5, padding=2),
MaxPool2d(2),
Conv2d(32, 32, 5, padding=2),
MaxPool2d(2),
Conv2d(32, 64, 5, padding=2),
MaxPool2d(2),
Flatten(),
Linear(1024, 64),
Linear(64, 10)
)
def forward(self, x):
x = self.model1(x)
return x
dataset = torchvision.datasets.CIFAR10("../datasets", train=False, transform=torchvision.transforms.ToTensor(),
download=True)
dataloader = DataLoader(dataset, batch_size=1)
test_model = test_cifar()
loss_cross = nn.CrossEntropyLoss()
for data in dataloader:
imgs, targets = data
outputs = test_model(imgs)
# 看outputs和targets是什么样子,看需要选择什么损失函数
print(outputs) # tensor([[-0.0997, -0.1220, -0.1413, 0.0602, -0.1044, 0.1636, -0.0469, -0.1157, 0.0060, -0.1186]], grad_fn=<AddmmBackward0>)
print(targets) # tensor([3])
result_loss = loss_cross(outputs, targets) # tensor(2.3130, grad_fn=<NllLossBackward0>)
result_loss.backward()
print("ok")
打断点,进入网络中
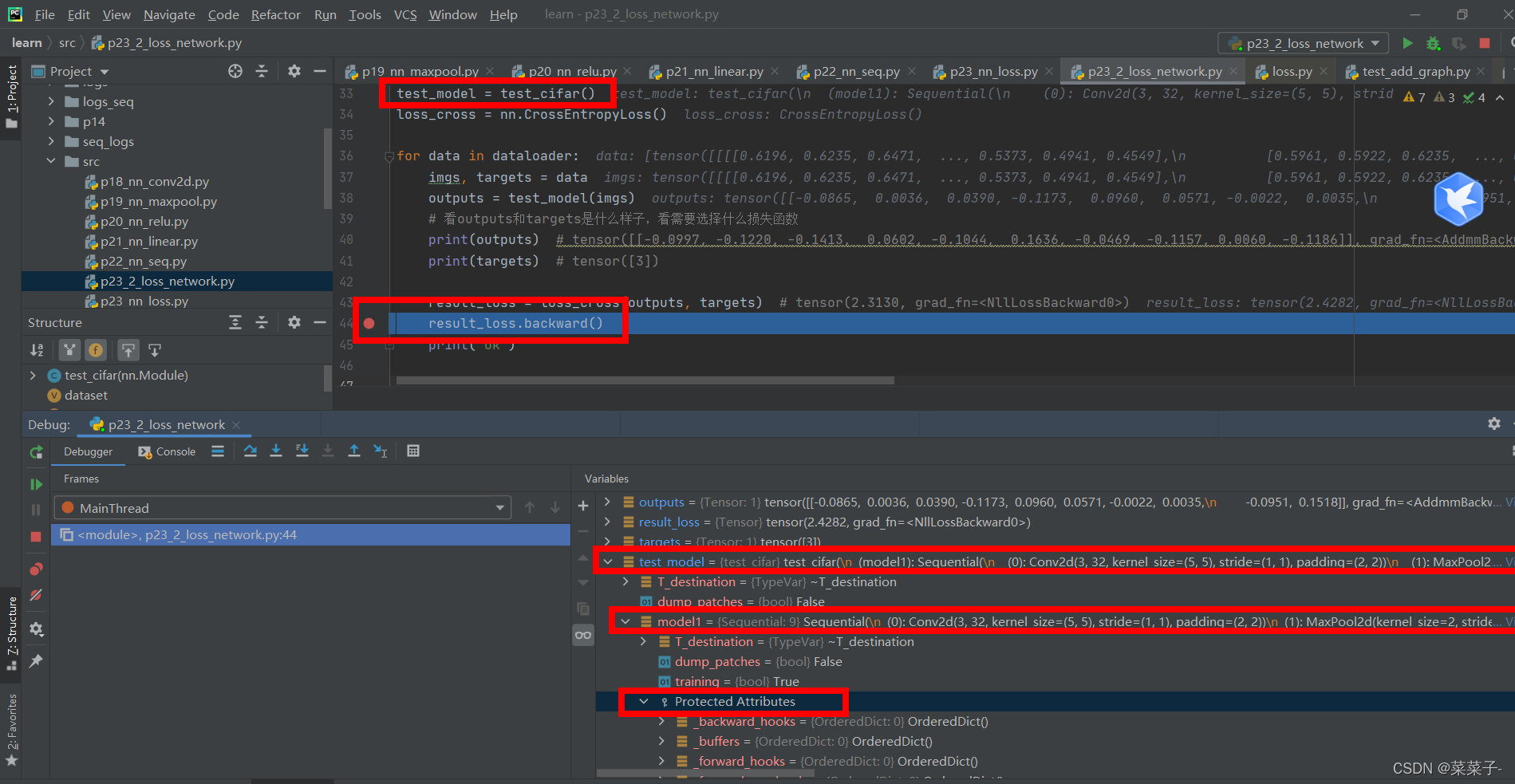
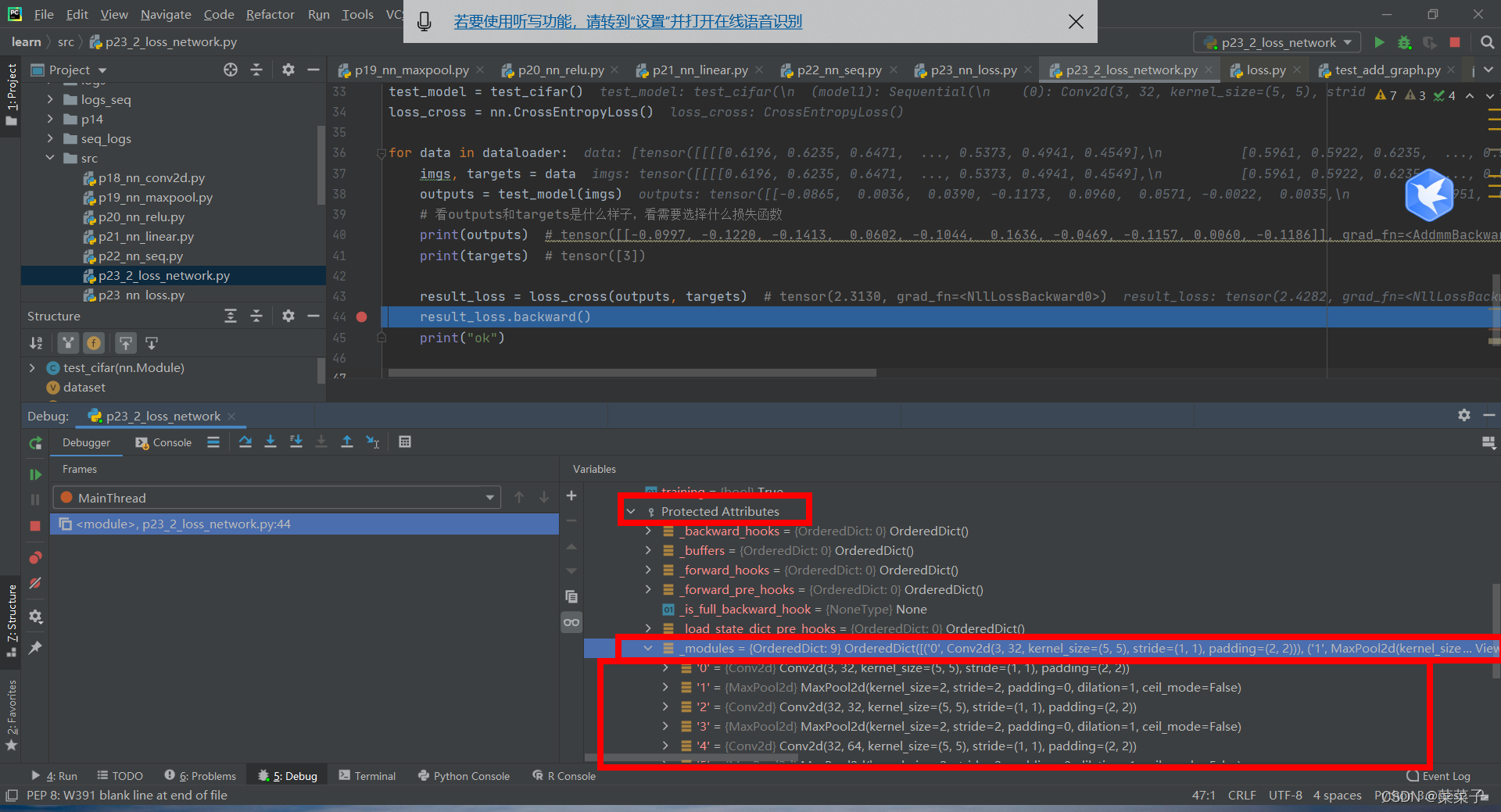
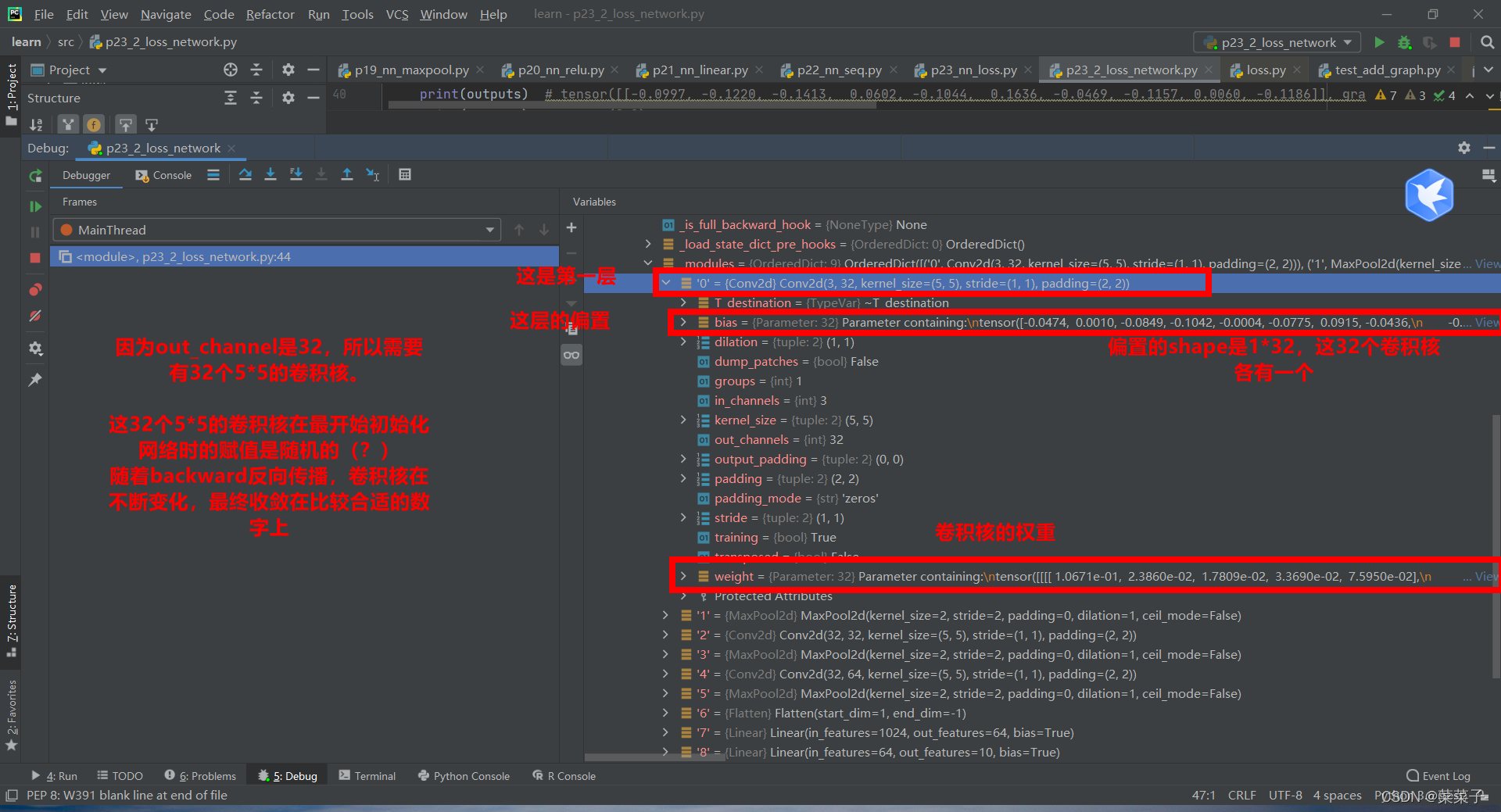
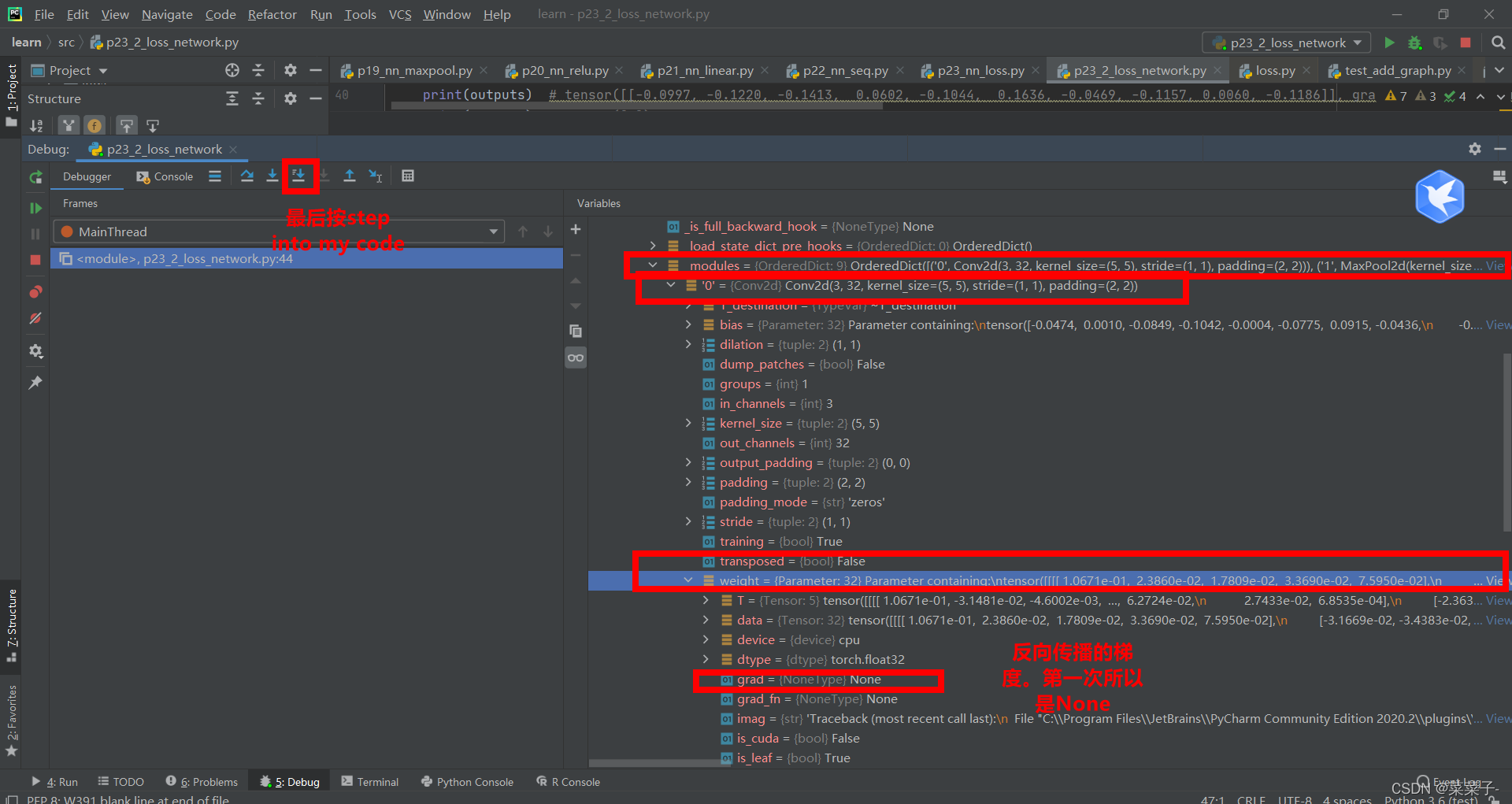
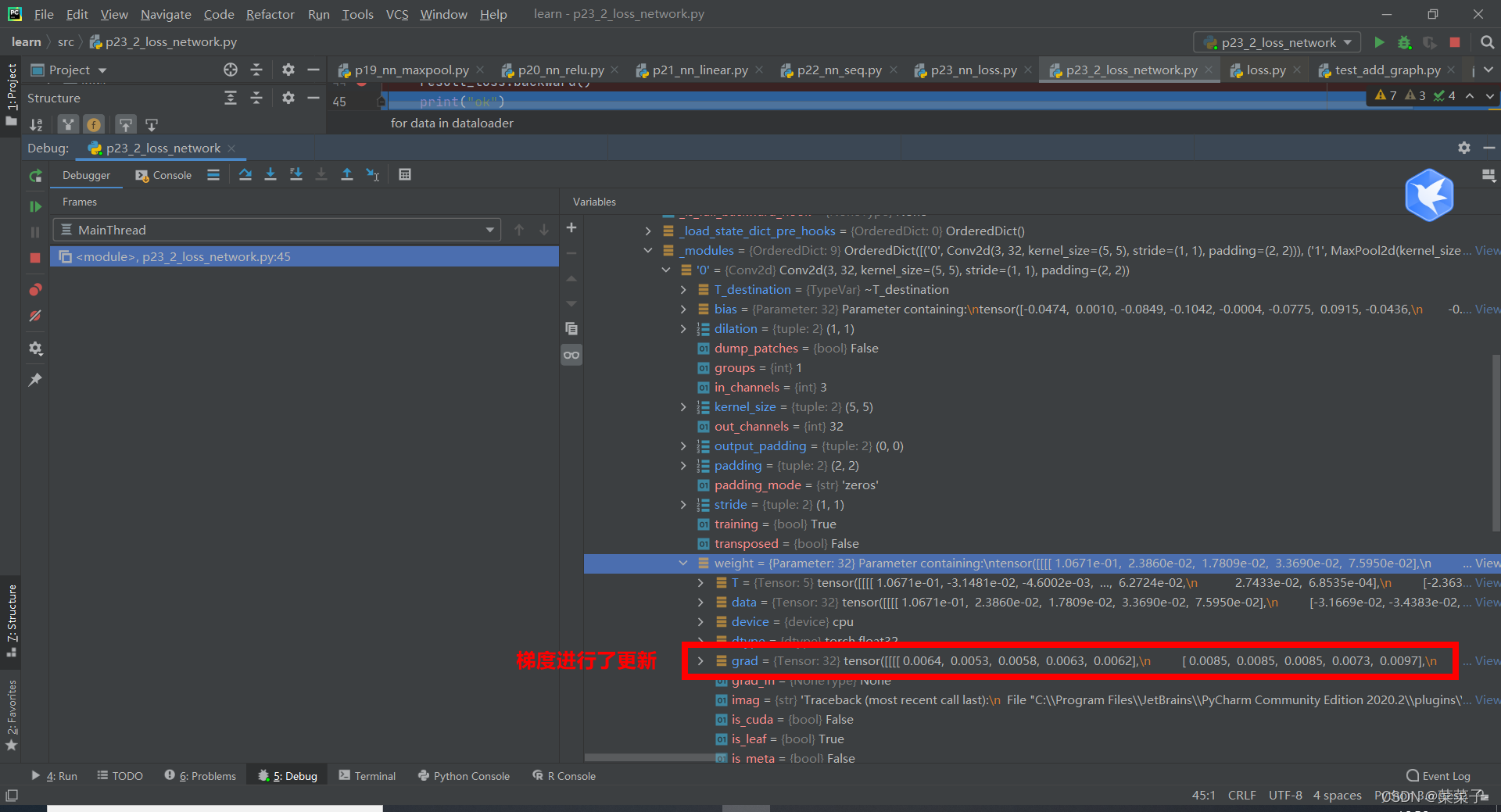
注意,如果没有result_loss.backward()这条语句的话,梯度是不会更新的。
4.优化器
优化器对梯度进行调整
import torch
import torchvision
from tensorboardX import SummaryWriter
from torch import nn
from torch.nn import ReLU, Sigmoid, Linear, Conv2d, MaxPool2d, Flatten, Sequential
from torch.utils.data import DataLoader
class test_cifar(nn.Module):
def __init__(self) -> None:
super(test_cifar, self).__init__()
self.model1 = Sequential(
Conv2d(3, 32, 5, padding=2),
MaxPool2d(2),
Conv2d(32, 32, 5, padding=2),
MaxPool2d(2),
Conv2d(32, 64, 5, padding=2),
MaxPool2d(2),
Flatten(),
Linear(1024, 64),
Linear(64, 10)
)
def forward(self, x):
x = self.model1(x)
return x
dataset = torchvision.datasets.CIFAR10("../datasets", train=False, transform=torchvision.transforms.ToTensor(),
download=True)
dataloader = DataLoader(dataset, batch_size=1)
test_model = test_cifar()
loss_cross = nn.CrossEntropyLoss()
optimizer = torch.optim.SGD(test_model.parameters(), lr=0.01) # lr:学习速率
for data in dataloader:
imgs, targets = data
outputs = test_model(imgs)
result_loss = loss_cross(outputs, targets) # tensor(2.3130, grad_fn=<NllLossBackward0>)
optimizer.zero_grad() # 优化器调节梯度为0
result_loss.backward()
optimizer.step() # 对每个参数进行调优
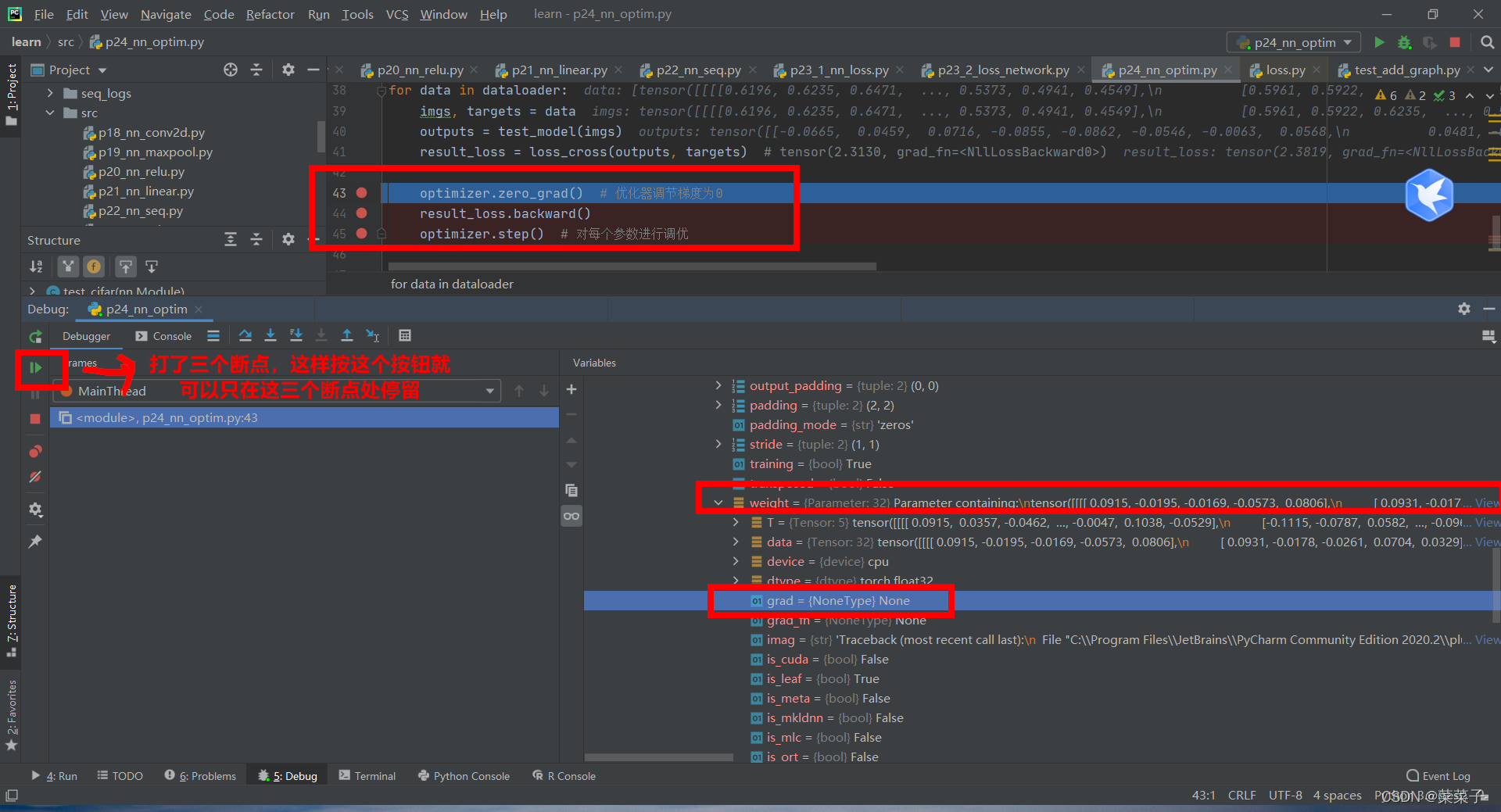
按那个绿色按钮进入下一步,即运行optimizer.zero_grad() # 优化器调节梯度为0,此时grad=None
再按一次绿色按钮,即运行result_loss.backward(),进行反向传播。此时梯度进行更新。
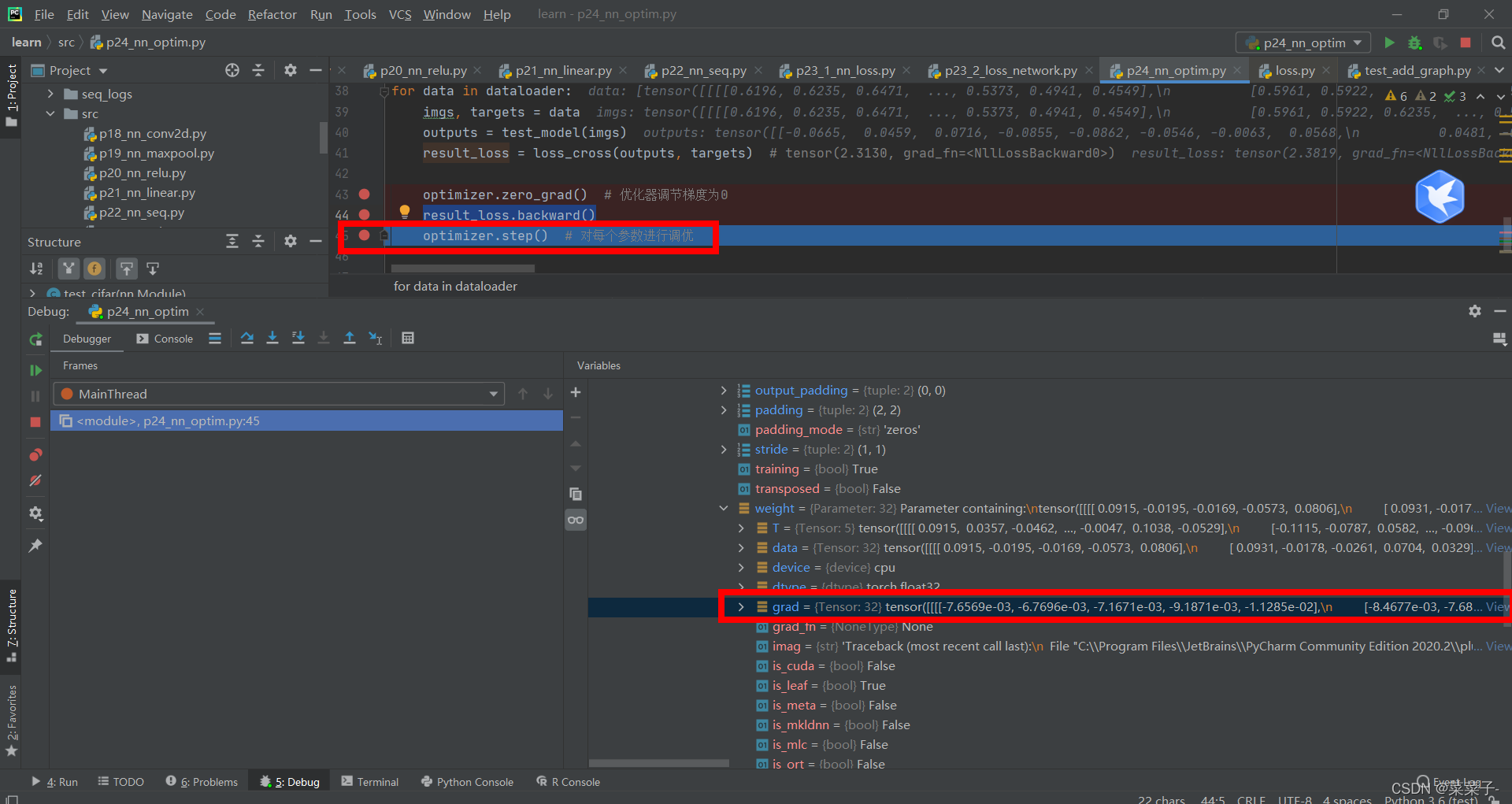
再按一次绿色按钮,此时运行optimizer.step() # 对每个参数进行调优,优化器会利用grad梯度对data进行更新。
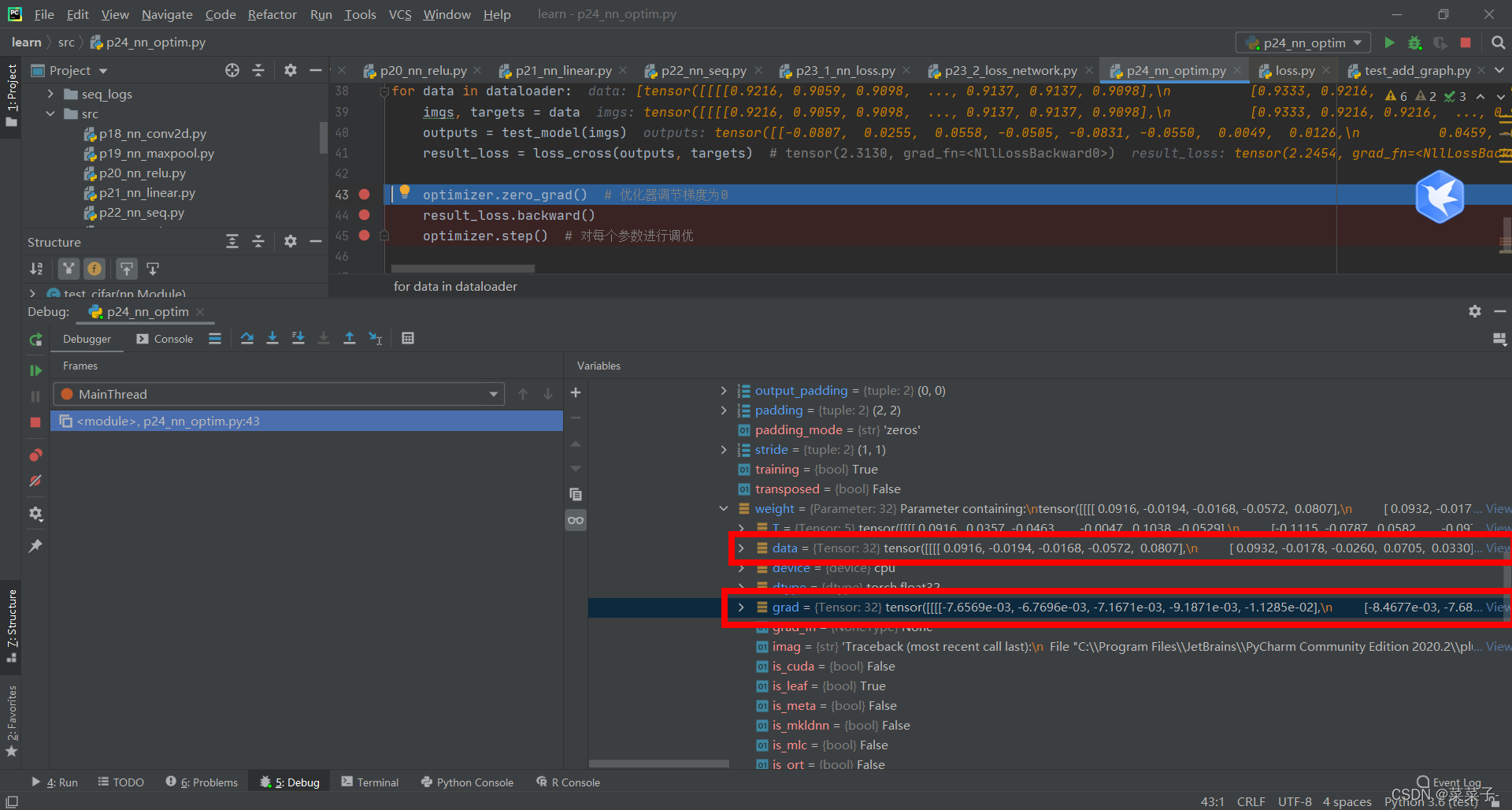
加上轮数的代码
import torch
import torchvision
from tensorboardX import SummaryWriter
from torch import nn
from torch.nn import ReLU, Sigmoid, Linear, Conv2d, MaxPool2d, Flatten, Sequential
from torch.utils.data import DataLoader
class test_cifar(nn.Module):
def __init__(self) -> None:
super(test_cifar, self).__init__()
self.model1 = Sequential(
Conv2d(3, 32, 5, padding=2),
MaxPool2d(2),
Conv2d(32, 32, 5, padding=2),
MaxPool2d(2),
Conv2d(32, 64, 5, padding=2),
MaxPool2d(2),
Flatten(),
Linear(1024, 64),
Linear(64, 10)
)
def forward(self, x):
x = self.model1(x)
return x
dataset = torchvision.datasets.CIFAR10("../datasets", train=False, transform=torchvision.transforms.ToTensor(),
download=True)
dataloader = DataLoader(dataset, batch_size=1)
test_model = test_cifar()
loss_cross = nn.CrossEntropyLoss()
optimizer = torch.optim.SGD(test_model.parameters(), lr=0.01) # lr:学习速率
for epoch in range(20):
running_loss = 0.0
for data in dataloader:
imgs, targets = data
outputs = test_model(imgs)
result_loss = loss_cross(outputs, targets) # tensor(2.3130, grad_fn=<NllLossBackward0>)
optimizer.zero_grad() # 优化器调节梯度为0
result_loss.backward()
optimizer.step() # 对每个参数进行调优
running_loss = result_loss + result_loss
print(running_loss)
5.现有网络模型的使用及修改
用vgg做例子
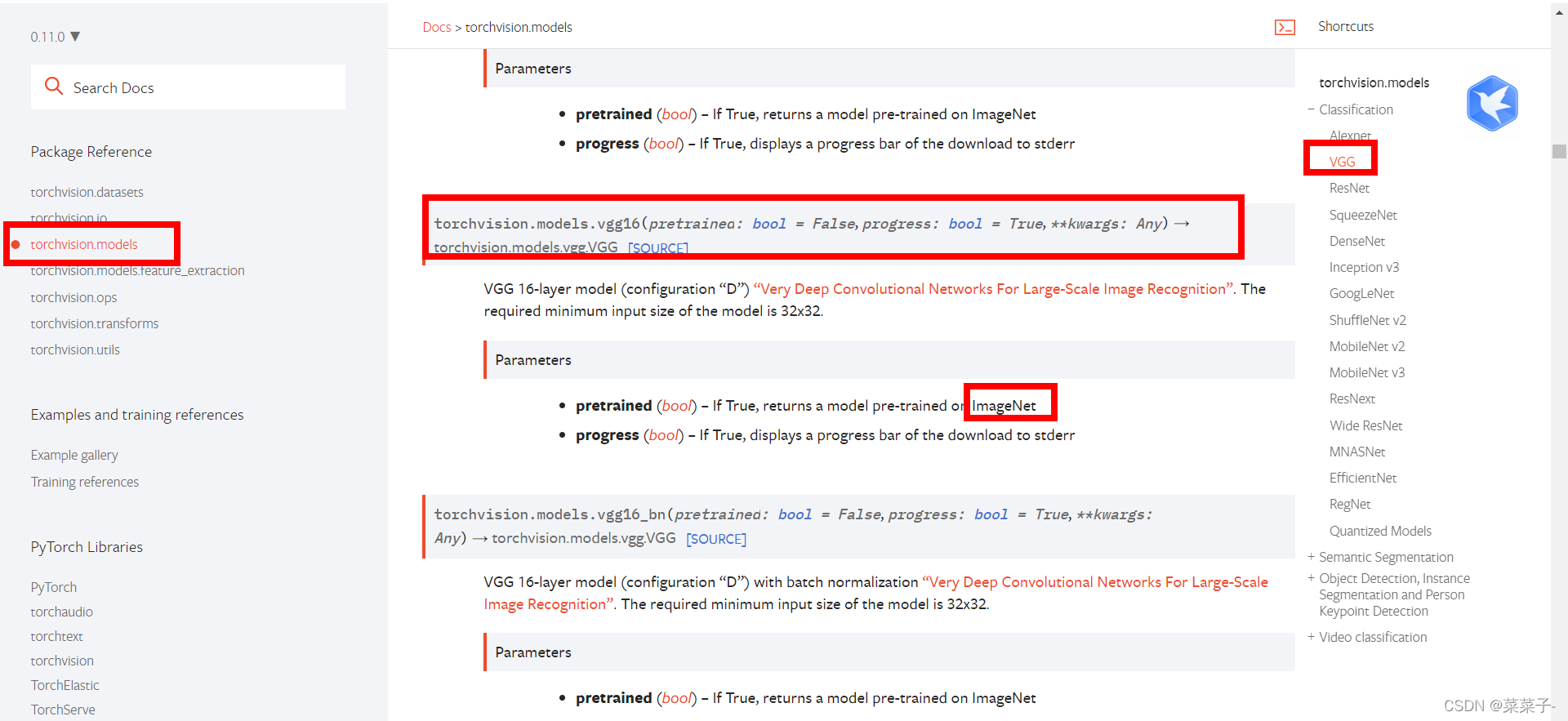
需要ImageNet数据集
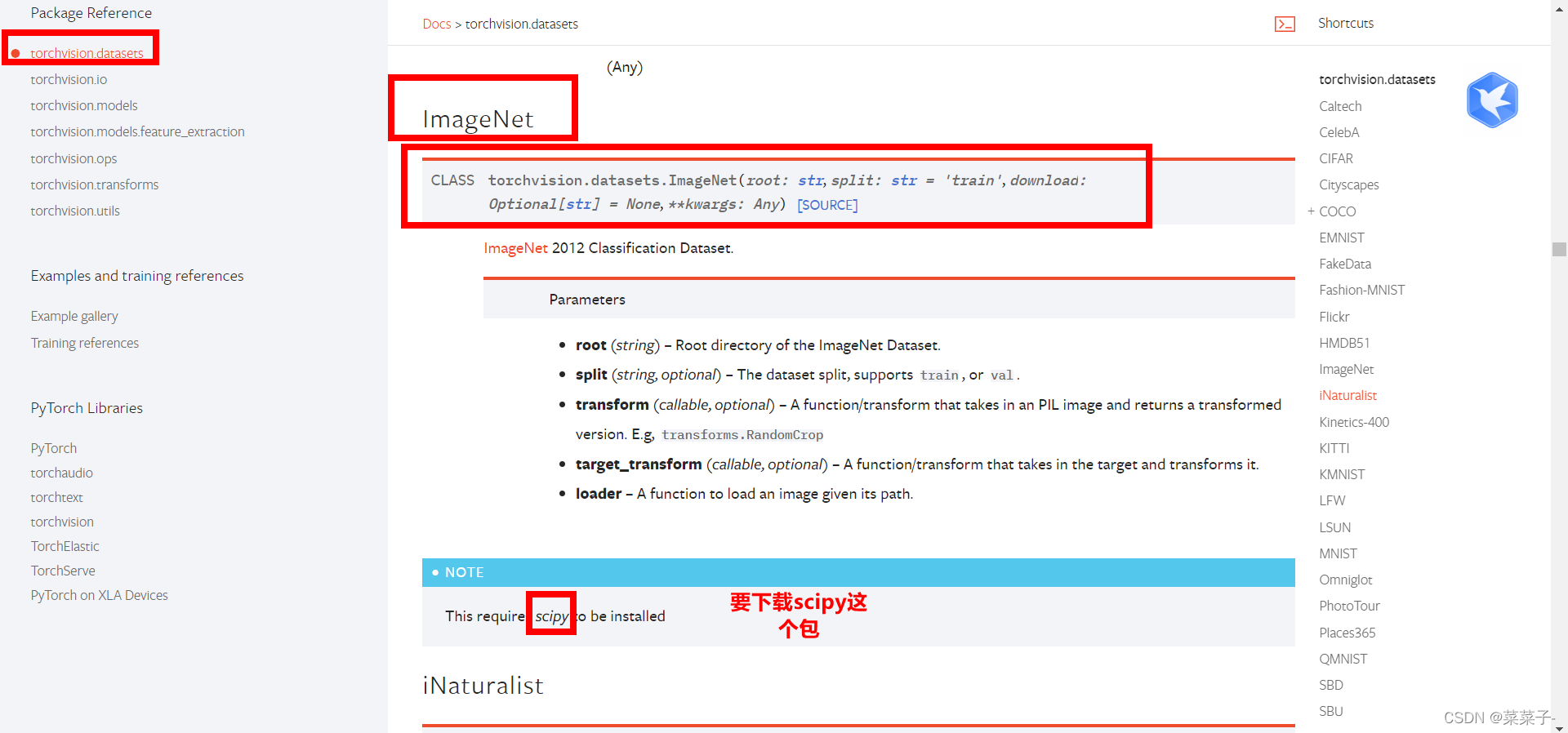
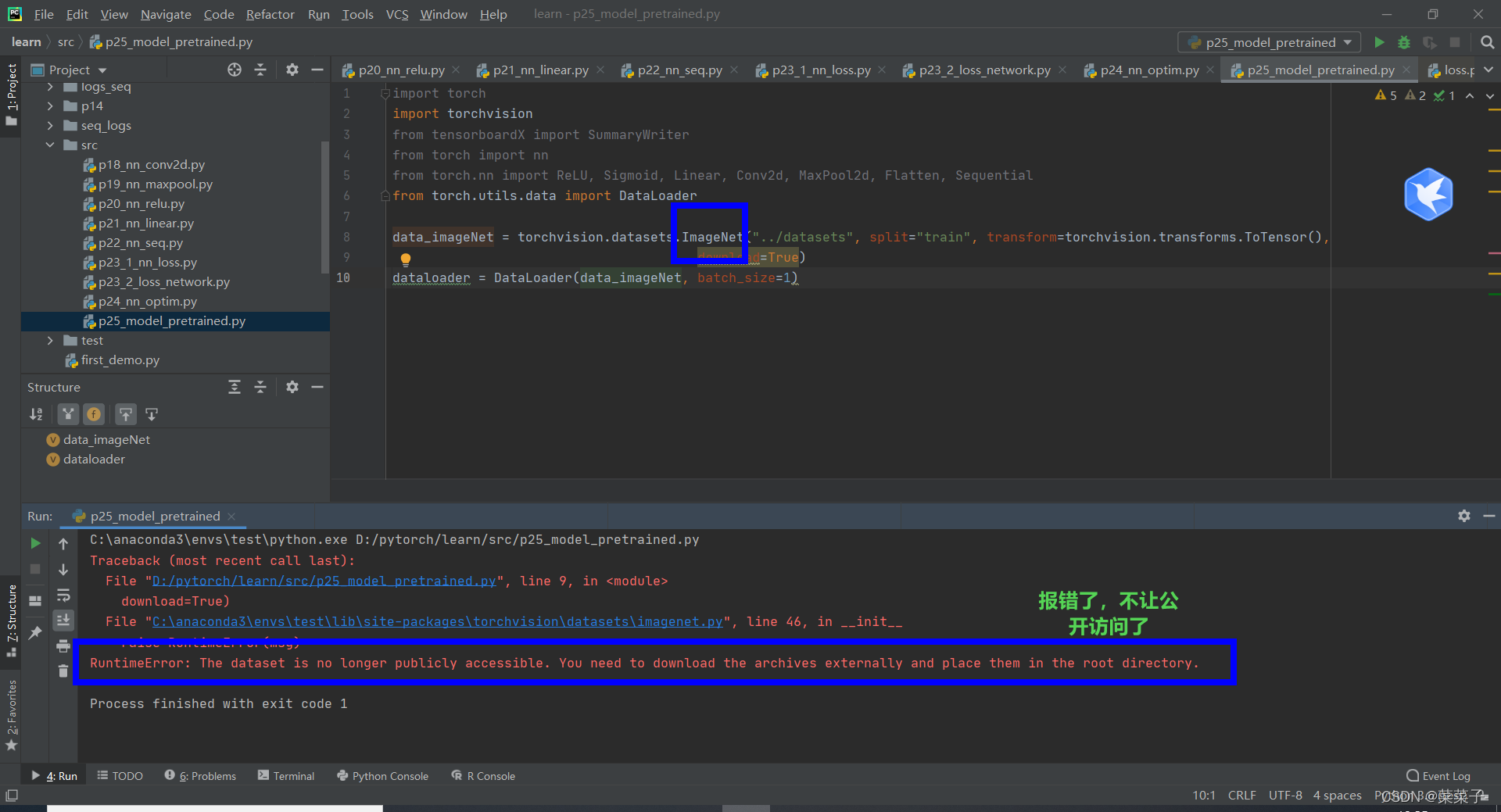
报错了。不管了
————————————————
vgg的模型 其中pretrained为是否预训练
import torchvision
vgg16_false = torchvision.models.vgg16(pretrained=False) # 网络模型,没有参数 pretrained:是否预训练
vgg16_true = torchvision.models.vgg16(pretrained=True) # 已经训练好的网络模型
print(vgg16_true)
打印出来:
VGG(
(features): Sequential(
(0): Conv2d(3, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): ReLU(inplace=True)
(2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(3): ReLU(inplace=True)
(4): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(5): Conv2d(64, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(6): ReLU(inplace=True)
(7): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(8): ReLU(inplace=True)
(9): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(10): Conv2d(128, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(11): ReLU(inplace=True)
(12): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(13): ReLU(inplace=True)
(14): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(15): ReLU(inplace=True)
(16): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(17): Conv2d(256, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(18): ReLU(inplace=True)
(19): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(20): ReLU(inplace=True)
(21): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(22): ReLU(inplace=True)
(23): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(24): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(25): ReLU(inplace=True)
(26): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(27): ReLU(inplace=True)
(28): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(29): ReLU(inplace=True)
(30): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
)
(avgpool): AdaptiveAvgPool2d(output_size=(7, 7))
(classifier): Sequential(
(0): Linear(in_features=25088, out_features=4096, bias=True)
(1): ReLU(inplace=True)
(2): Dropout(p=0.5, inplace=False)
(3): Linear(in_features=4096, out_features=4096, bias=True)
(4): ReLU(inplace=True)
(5): Dropout(p=0.5, inplace=False)
(6): Linear(in_features=4096, out_features=1000, bias=True)
)
)
从最后一个线性层可以看出来,输出 out_features=1000,分类1000种。我们想让vgg能够分类10个,在cifar10上用。
在后面加一层
import torchvision
from torch import nn
vgg16_false = torchvision.models.vgg16(pretrained=False) # 网络模型,没有参数 pretrained:是否预训练
vgg16_true = torchvision.models.vgg16(pretrained=True) # 已经训练好的网络模型
print(vgg16_true)
vgg16_true.add_module("add_linear", nn.Linear(1000, 10))
print(vgg16_true)
输出:
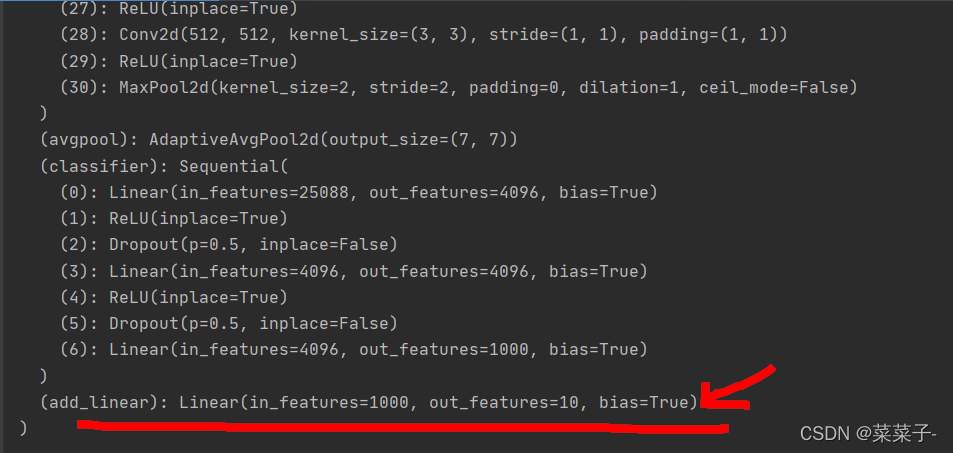
如果在classifier后面加一层的话,语句是:
vgg16_true.classifier.add_module("7 add_linear", nn.Linear(1000, 10))
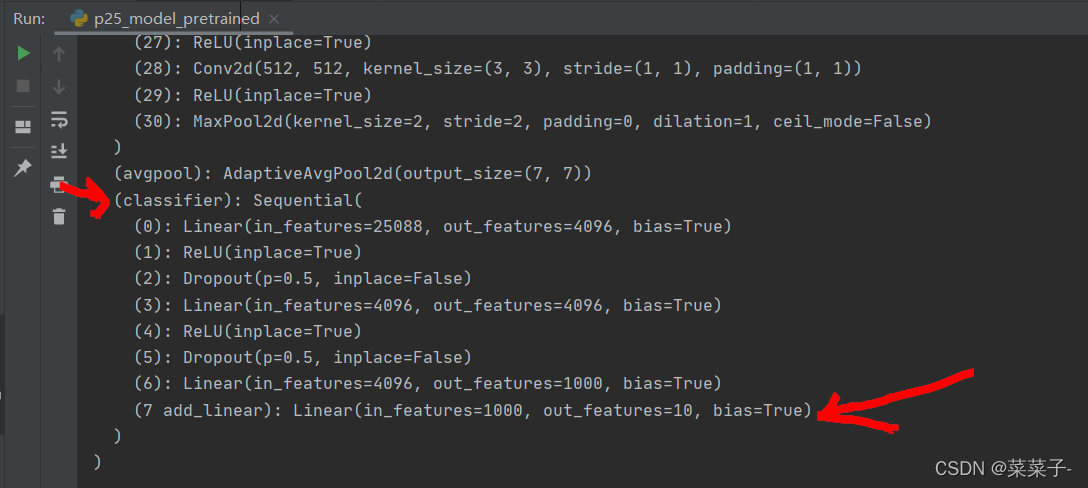
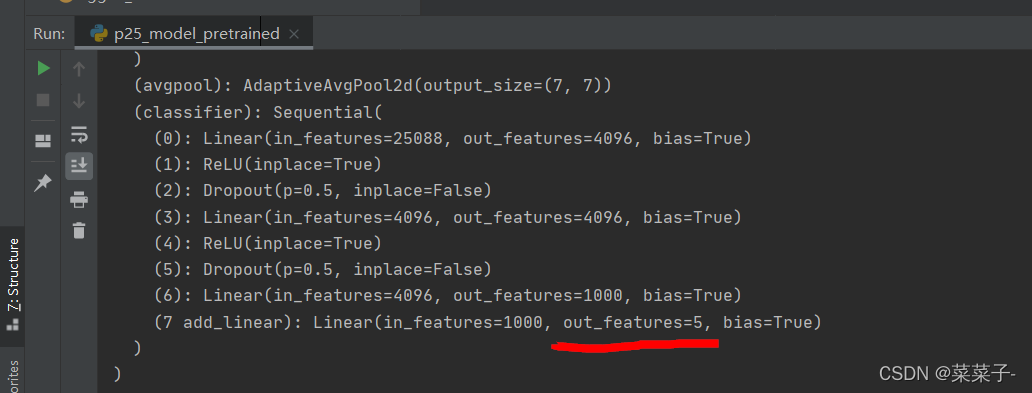
如果想对某一层修改,例如把7 add_linear修改为输出5
vgg16_true.classifier[7] = nn.Linear(1000, 5) # 7是下标,下标从0开始
则输出
6.模型的保存和加载
模型的保存
方法1:保存模型的结构和参数
方法2:把vgg16中的状态保存成字典形式
把两种方法在下面的代码中进行展示
import torchvision
from torch import nn
import torch
vgg16 = torchvision.models.vgg16(pretrained=False)
# 保存方式1 模型结构+模型参数
torch.save(vgg16, "vgg16_method1.pth") # 保存模型的结构和参数
# 保存方式2 模型参数(官方推荐) 比较小
torch.save(vgg16.state_dict(), "vgg16_method2.pth") # 把vgg16中的状态保存成字典形式
生成文件,保存模型的结构和参数
模型的加载
两种方式对应不同的加载方式
import torchvision
from torch import nn
import torch
# 保存方式1——>>加载
model1 = torch.load("vgg16_method1.pth")
print(model1)
# 保存方式2——>>加载
vgg16 = torchvision.models.vgg16(pretrained=False)
vgg16.load_state_dict(torch.load("vgg16_method2.pth"))
print(vgg16)
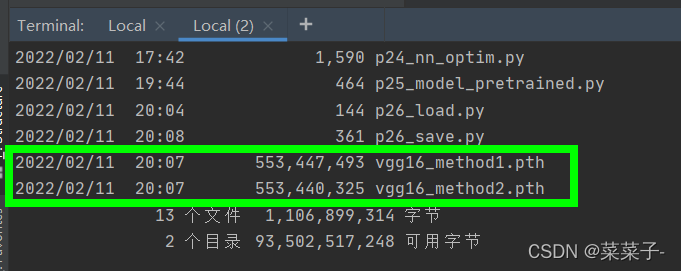
在pycharm中:在pth所在的文件夹右键点击open in Terminal
再在Terminal中输入dir,可以查看该文件夹下所有文件的信息
陷阱:
保存时:
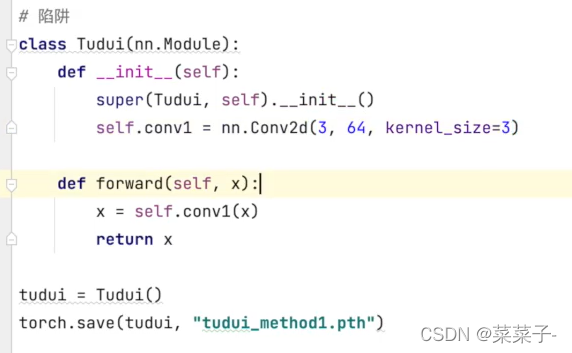
加载时,直接加载会报错:
要把网络结构定义一下才能正常运行
也可以直接从py文件里import过来

















 2676
2676











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









