






一、运行Uni-paint
Paper: A Unified Framework for Multimodal Image Inpainting with Pretrained Diffusion Model
github:https://github.com/ysy31415/unipaint
1.创建环境
OSError: Can't load tokenizer for 'openai/clip-vit-large-patch14'. If you were trying to load it from 'https://huggingface.co/models', make sure you don't have a local directory with the same name. Otherwise, make sure 'openai/clip-vit-large-patch14'
这是因为hugginface无法访问,所以直接下载无法下载。最靠谱的方法是在本地搭建一个环境,这个环境需要一些文件:
在主文件下创建openai,然后下载clip-vit-large-patch14文件,clip-vit-large-patch14下有该环境所需要的文件,文件可以私信我,百度网盘
然后创建一个文件夹openai将上述文件保存在当中:
2.下载与训练权重:
去hub链接上下载。
3.参考inpaint.ipynb文件进行单张图像预测
4.想要多张图像预测:
比如预测BrushBench数据集,需要重新写脚本文件,下面是我写的:
from omegaconf import OmegaConf
import torch, torch.nn.functional as F
from torchvision.utils import make_grid, save_image
from pytorch_lightning import seed_everything
from PIL import Image
from torchvision import transforms
from tqdm import tqdm
import kornia
import os, sys
sys.path.append(os.getcwd()),
sys.path.append('src/clip')
sys.path.append('src/taming-transformers')
from ldm.models.diffusion.ddim import DDIMSampler
from ldm.util import instantiate_from_config, load_model_from_config
###########################read the file##########################
import json
import cv2
import os
from PIL import Image
import torch
import numpy as np
import argparse
parser = argparse.ArgumentParser()
parser.add_argument('--brushnet_ckpt_path',
type=str,
default="/mnt/data/homes/qhyang/research/dm/preweight/brushnet/brushnet_random_mask/")
parser.add_argument('--base_model_path',
type=str,
default="/mnt/data/homes/qhyang/research/dm/preweight/stable-diffusion-v1-5")
parser.add_argument('--image_save_path',
type=str,
default="file_out")
parser.add_argument('--mapping_file',
type=str,
default="BrushBench/mapping_file.json")
parser.add_argument('--base_dir',
type=str,
default="BrushBench")
parser.add_argument('--mask_key',
type=str,
default="inpainting_mask")
parser.add_argument('--blended', action='store_true')
parser.add_argument('--paintingnet_conditioning_scale', type=float,default=1.0)
args = parser.parse_args()
num_iter = 50 # num of fine-tuning iterations
lr = 1e-5
config= "configs/stable-diffusion/v1-inference.yaml"
ckpt = "ckpt/sd-v1-4-full-ema.ckpt" # path to SD checkpoint
h = w = 512 #512
scale=8 # cfg scale
ddim_steps= 50
ddim_eta=0.0
seed_everything(42)
n_samples = 1 #4
out_path = args.image_save_path
out_uncond_path=os.path.join(out_path,'Uncond')
out_Prompt_path=os.path.join(out_path,'Prompt')
input_mask_path=os.path.join(out_path,'input_mask')
out_txt=os.path.join(out_path,'txt1.txt')
gpu_id = '0'
device = torch.device(f"cuda:{gpu_id}") if torch.cuda.is_available() else torch.device("cpu")
config = OmegaConf.load(config)
model = load_model_from_config(config, ckpt, device)
sampler = DDIMSampler(model)
params_to_be_optimized = list(model.model.parameters())
optimizer = torch.optim.Adam(params_to_be_optimized, lr=lr)
os.makedirs(out_path, exist_ok=True)
D = lambda _x: torch.clamp(model.decode_first_stage(_x), min=-1, max=1).detach() # vae decode
E = lambda _x: model.get_first_stage_encoding(model.encode_first_stage(_x)) # # vae encode
img_transforms = transforms.Compose([transforms.ToTensor(), transforms.Lambda(lambda x: x.unsqueeze(0) * 2. - 1)])
mask_transforms = transforms.Compose([transforms.ToTensor(), transforms.Lambda(lambda x: (x.unsqueeze(0) > 0).float())])
# text encode
def C(_txt, enable_emb_manager=False):
_txt = [_txt] if isinstance(_txt,str) else _txt
with torch.enable_grad() if enable_emb_manager else torch.no_grad(): # # disable grad flow unless we want textual inv
c = model.get_learned_conditioning(_txt, enable_emb_manager)
return c
# save tensor as image file
def tsave(tensor, save_path, **kwargs):
save_image(tensor, save_path, normalize=True, scale_each=True, value_range=(-1, 1), **kwargs)
def rle2mask(mask_rle, shape): # height, width
starts, lengths = [np.asarray(x, dtype=int) for x in (mask_rle[0:][::2], mask_rle[1:][::2])]
starts -= 1
ends = starts + lengths
binary_mask = np.zeros(shape[0] * shape[1], dtype=np.uint8)
for lo, hi in zip(starts, ends):
binary_mask[lo:hi] = 1
return binary_mask.reshape(shape)
device = torch.device(f"cuda:{gpu_id}") if torch.cuda.is_available() else torch.device("cpu")
with open(args.mapping_file,"r") as f:
mapping_file=json.load(f)
def read_line(file,lines):
with open(file, 'a', encoding='utf-8') as file:
file.write(lines[0] + '\n')
###########################end the file##########################
################start######################
for key, item in mapping_file.items():
print(f"generating image {key} ...")
image_path=item["image"]
mask=item[args.mask_key]
caption=item["caption"]
strings = [
f'image:{os.path.basename(image_path)}----Text:{caption}------mask:{os.path.basename(image_path)}'
]
read_line(out_txt,strings)
# h,w,c bgr ==> rgb
init_image = cv2.imread(os.path.join(args.base_dir,image_path))[:,:,::-1]
mask_image = rle2mask(mask,(512,512))[:,:,np.newaxis]
init_image = init_image * (1-mask_image)
init_image = Image.fromarray(init_image).convert("RGB")
mask_image=np.uint8(mask_image*255)
# mask_image = Image.fromarray(np.uint8(mask_image*255)).convert("RGB")
x = img_transforms(init_image).to(device)
# m = mask_transforms(mask).repeat(n_samples, 1, 1, 1).to(device)
m = mask_transforms(mask_image).to(device)
tsave(m, os.path.join(input_mask_path, os.path.basename(image_path)), nrow=n_samples)
x_in = x * (1 - m)
z_xm = E(x_in)
z_m = F.interpolate(m, size=(h // 8, w // 8)) # latent mask
z_m = kornia.morphology.dilation(z_m, torch.ones((3, 3), device=device)) # dilate mask a little bit
attn_mask = {}
for attn_size in [64, 32, 16, 8]: # create attention masks for multi-scale layers in unet
attn_mask[str(attn_size ** 2)] = (F.interpolate(m, (attn_size, attn_size), mode='bilinear'))[0, 0, ...]
uc = C("") # null-text emb
model.train()
pbar = tqdm(range(num_iter), desc='Fine-tune the model')
for i in pbar:
optimizer.zero_grad()
noise = torch.randn_like(z_xm)
t_emb = torch.randint(model.num_timesteps, (1,), device=device)
z_t = model.q_sample(z_xm, t_emb, noise=noise)
pred_noise = model.apply_model(z_t, t_emb, uc)
loss_noise = F.mse_loss(pred_noise * (1 - z_m), noise * (1 - z_m))
loss = loss_noise
losses_dict = {"loss": loss}
pbar.set_postfix({k: v.item() for k, v in losses_dict.items()})
loss.backward()
optimizer.step()
model.eval()
with torch.no_grad(), torch.autocast(device.type):
# uncond inpainting
tmp, _ = sampler.sample(S=ddim_steps, batch_size=n_samples, shape=[4, h // 8, w // 8],
conditioning=uc.repeat(n_samples, 1, 1),
unconditional_conditioning=uc.repeat(n_samples, 1, 1),
blend_interval=[0, 1],
x0=z_xm.repeat(n_samples, 1, 1, 1),
mask=z_m.repeat(n_samples, 1, 1, 1),
attn_mask=attn_mask,
x_T=None,
unconditional_guidance_scale=scale,
eta=ddim_eta,
verbose=False)
tsave(D(tmp), os.path.join(out_uncond_path, os.path.basename(image_path)), nrow=n_samples)
prompt = caption
with torch.no_grad(), torch.autocast(device.type):
tmp, _ = sampler.sample(S=ddim_steps, batch_size=n_samples, shape=[4, h // 8, w // 8],
conditioning=C(prompt).repeat(n_samples, 1, 1),
unconditional_conditioning=uc.repeat(n_samples, 1, 1),
blend_interval=[0, 1],
x0=z_xm.repeat(n_samples, 1, 1, 1),
mask=z_m.repeat(n_samples, 1, 1, 1),
attn_mask=attn_mask,
x_T=None,
unconditional_guidance_scale=scale,
eta=ddim_eta,
verbose=False)
tsave(D(tmp), os.path.join(out_Prompt_path, os.path.basename(image_path)), nrow=n_samples)
# tsave(D(tmp), os.path.join(out_Prompt_path, f'Text-{prompt}.jpg'), nrow=n_samples)
五、实例
a.根据github提示,输入指令去除dog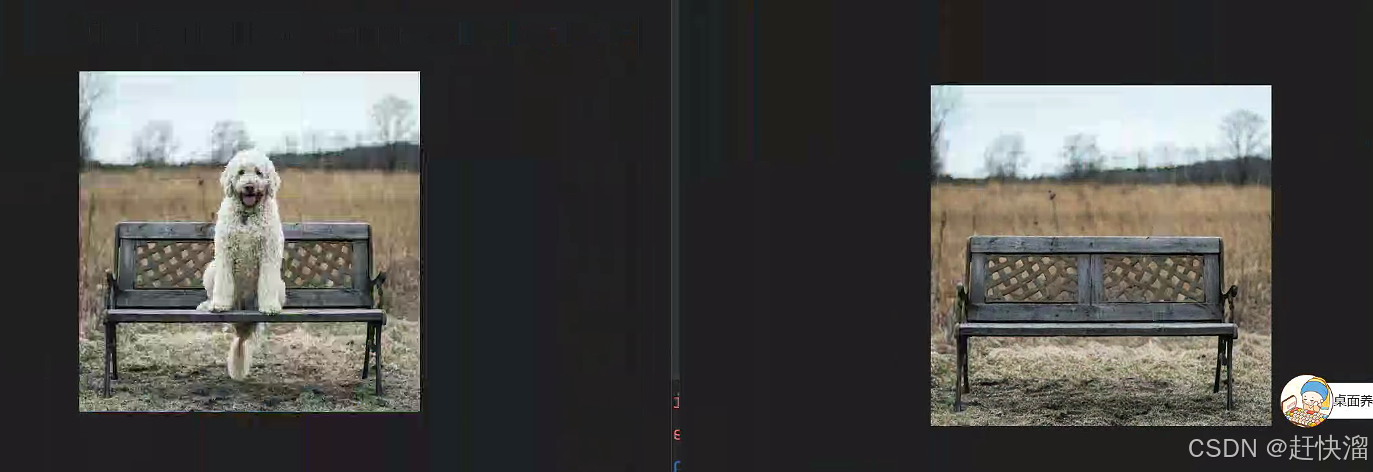
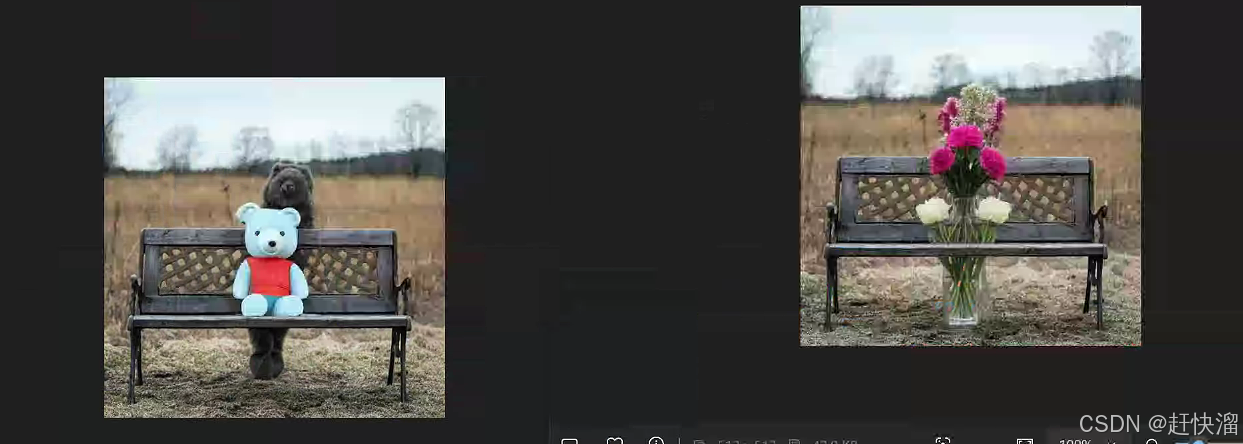
b.更换对象
二、PowerPaint_v1
2.运行PowerPaint_v1报错:
OSError: Cannot load model runwayml/stable-diffusion-inpainting: model is not cached locally and an error occurred while trying to fetch metadata from the Hub. Please check out the root cause in the stacktrace above.

OSError: D:\A_data_LMC\jie\69\PowerPaint-main\checkpoints\PowerPaint_v1 does not appear to have a file named preprocessor_config.json. Checkout 'https://huggingface.co/D:\A_data_LMC\jie\69\PowerPaint-main\checkpoints\PowerPaint_v1/main' for available files.
去上述提示的网站:
搜索想要的内容:
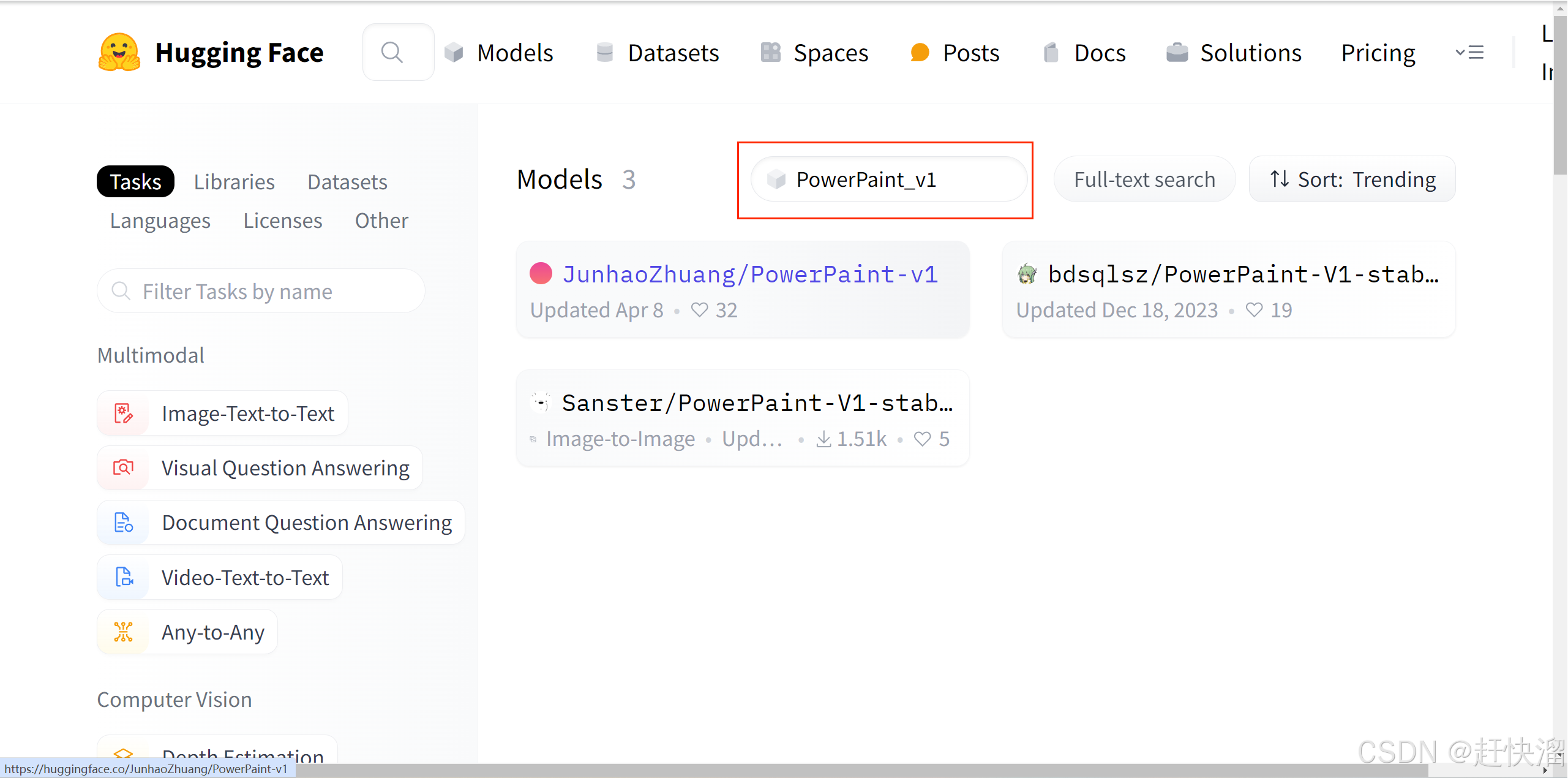
然后点击进去:
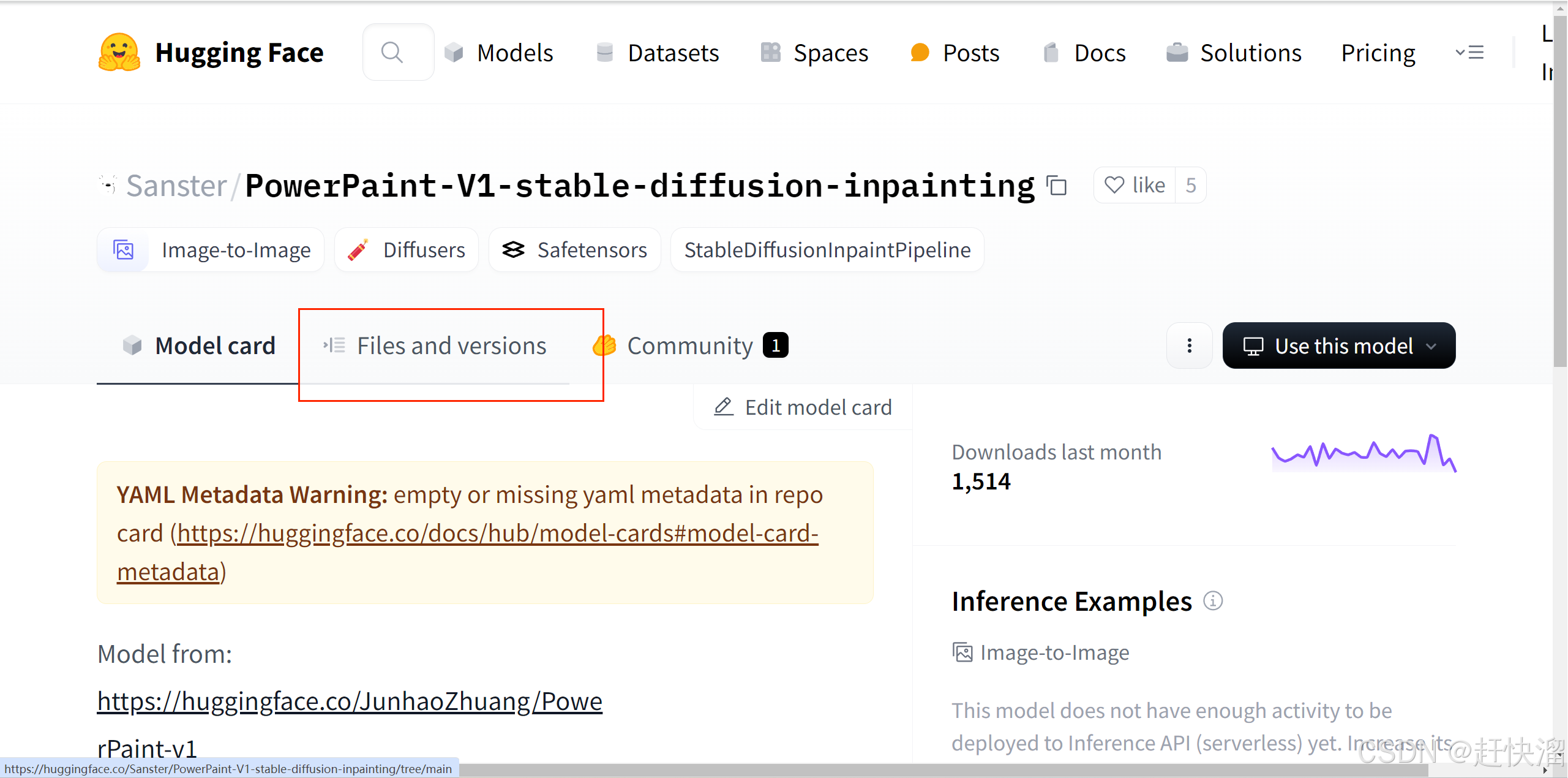
下载:
 就下载对应 文件夹下的文件。
就下载对应 文件夹下的文件。
在https://github.com/open-mmlab/PowerPaint/tree/main
下载主分支下的文件:
2.下载预训练权重:
地址:https://huggingface.co/JunhaoZhuang/PowerPaint_v2/tree/main
下载不成功或者下载太慢可以私信我,网盘发你
如果出现:

则按照提示下载->重命名->移动即可
但是如果你发现,这样操作了还是卡在这里不动(只有Running on local URL: http://0.0.0.0:7860,没有出现Running on public URL:)
可以考虑以下方法:
a.关闭杀毒软件
b.打开权限:
- 在开始菜单中搜索 “命令提示符”。
- 右键单击 “命令提示符”,然后选择 “以管理员身份运行
- cd到frpc_windows_amd64_v0.2文件夹目录(注意没有后缀名.exe)
- 运行命令:
icacls frpc_windows_amd64_v0.2 /grant Users:(RX)那么大多数情况在这里就可以得到解决。
3.修改源文件:
打开gradio文件下的tunneling.py ,添加:
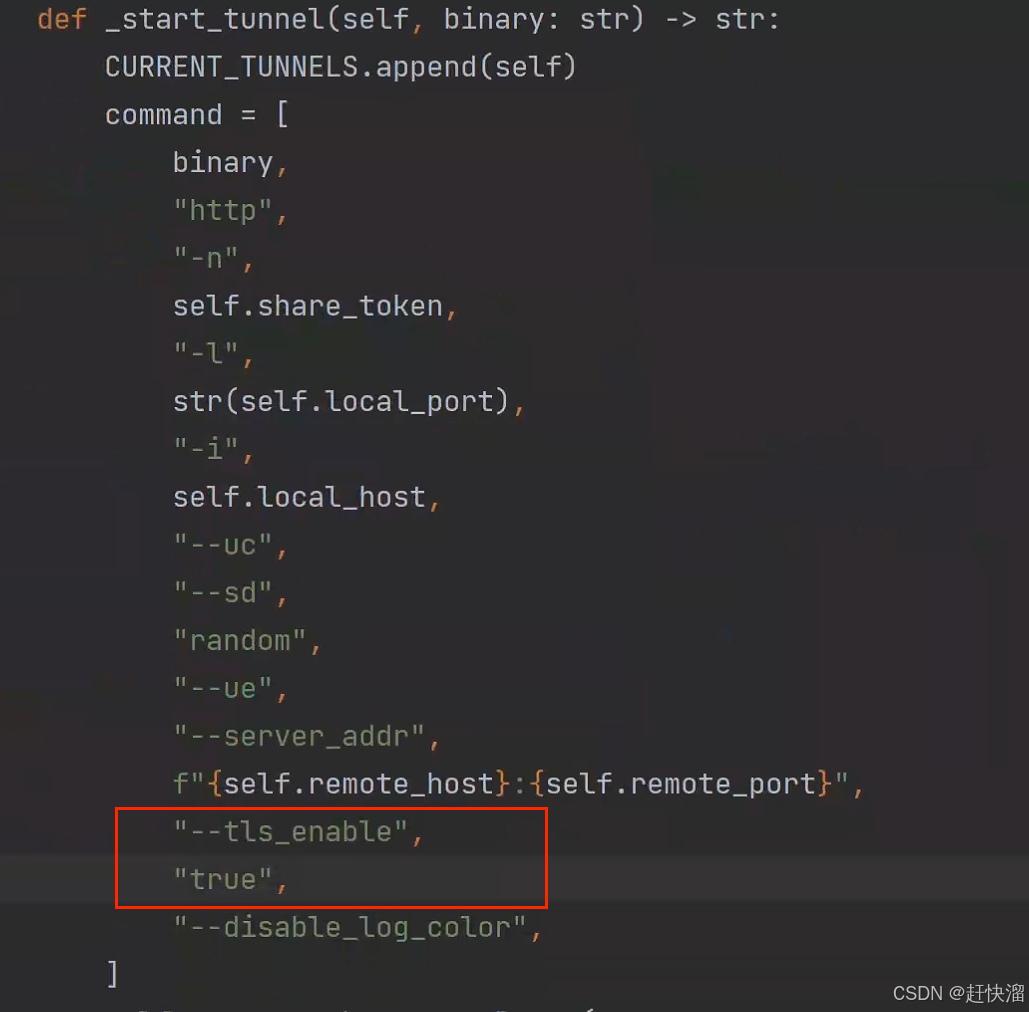
原来的文件当中是没有这两行代码的,现在加上去,即可成功获得公共链接。
三、运行PILOT
paper:PILOT: Coherent and Multi-modality Image Inpainting via Latent Space Optimization
GitHub:GitHub - Lingzhi-Pan/PILOT: Official Implement of the work "Coherent and Multi-modality Image Inpainting via Latent Space Optimization" 重点在于权重下载,我已下载到本地,然后改代码也是只是支持单张图片预测,如果要预测多张图片还需要自己写脚本文件,以下是我自己写的:
from PIL import Image
import numpy as np
import torch
import argparse
import os
from omegaconf import OmegaConf
from diffusers import (
ControlNetModel,
DDIMScheduler,
T2IAdapter,
)
from pipeline.pipeline_pilot import PilotPipeline
from models.attn_processor import revise_pilot_unet_attention_forward
import os
import torch.nn.functional as F
from utils.generate_spatial_map import img2cond
from utils.image_processor import preprocess_image, tensor2PIL, mask4image
from utils.visualize import t2i_visualize, spatial_visualize, ipa_visualize, ipa_spatial_visualize
import json
import argparse
import cv2
parser = argparse.ArgumentParser()
parser.add_argument(
"--config_file", type=str, default="configs/t2i_step50.yaml"
)
args = parser.parse_args()
config = OmegaConf.load(args.config_file)
if not os.path.exists(config.output_path):
os.makedirs(config.output_path)
# prompt_list = [config.prompt]
device = "cuda"
controlnet = None
adapter = None
model_list = ["base"]
if config.fp16:
weight_format = torch.float16
else:
weight_format = torch.float32
###############################start#####################
parser = argparse.ArgumentParser()
parser.add_argument('--brushnet_ckpt_path',
type=str,
default="/mnt/data/homes/qhyang/research/dm/preweight/brushnet/brushnet_random_mask/")
parser.add_argument('--base_model_path',
type=str,
default="/mnt/data/homes/qhyang/research/dm/preweight/stable-diffusion-v1-5")
parser.add_argument('--image_save_path',
type=str,
default="file_out")
parser.add_argument('--mapping_file',
type=str,
default="BrushBench/mapping_file.json")
parser.add_argument('--base_dir',
type=str,
default="BrushBench")
parser.add_argument('--mask_key',
type=str,
default="inpainting_mask")
parser.add_argument('--blended', action='store_true')
parser.add_argument('--paintingnet_conditioning_scale', type=float,default=1.0)
args = parser.parse_args()
def read_line(file,lines):
with open(file, 'a', encoding='utf-8') as file:
file.write(lines[0] + '\n')
def rle2mask(mask_rle, shape): # height, width
starts, lengths = [np.asarray(x, dtype=int) for x in (mask_rle[0:][::2], mask_rle[1:][::2])]
starts -= 1
ends = starts + lengths
binary_mask = np.zeros(shape[0] * shape[1], dtype=np.uint8)
for lo, hi in zip(starts, ends):
binary_mask[lo:hi] = 1
return binary_mask.reshape(shape)
with open(args.mapping_file,"r") as f:
mapping_file=json.load(f)
for key, item in mapping_file.items():
print(f"generating image {key} ...")
image_path=item["image"]
mask=item[args.mask_key]
caption=item["caption"]
prompt_list = [caption]
strings = [
f'image:{os.path.basename(image_path)}----Text:{caption}------mask:{os.path.basename(image_path)}'
]
read_line('out_txt.txt', strings)
# h,w,c bgr ==> rgb
init_image = cv2.imread(os.path.join(args.base_dir, image_path))[:, :, ::-1]
# mask_image = rle2mask(mask, (512, 512))[:, :, np.newaxis]
ask_image = rle2mask(mask, (512, 512))#[:, :, np.newaxis]
ask_image=1-ask_image
# init_image = init_image * (1 - mask_image)
init_image = Image.fromarray(init_image).convert("RGB")
# l=np.uint8(mask_image).transpose(1,2,0)
mask_image = Image.fromarray(np.uint8(ask_image*255))
# generator = torch.Generator(device).manual_seed(1234)
# save_path= os.path.join(args.image_save_path,image_path)
# masked_image_save_path=save_path.replace(".jpg","_masked.jpg")
###########################
image = init_image
image = image.resize((config.W, config.H), Image.NEAREST)
mask_image = mask_image.resize((config.W, config.H), Image.NEAREST)
if mask_image.mode != "RGB":
mask_image = mask_image.convert("RGB")
for x in range(config.W):
for y in range(config.H):
r, g, b = mask_image.getpixel((x, y))
if (r, g, b) != (0, 0, 0) and (r, g, b) != (255, 255, 255):
mask_image.putpixel((x, y), (0, 0, 0))
################################### loading models and additional controls #############################
# load controlnet
if "controlnet_id" in config:
print("load controlnet")
model_list.append("controlnet")
controlnet = ControlNetModel.from_pretrained(
f"{config.model_path}/{config.controlnet_id}", torch_dtype=weight_format
).to(device)
# load t2i adapter
if "t2iadapter_id" in config:
print("load t2i adapter")
model_list.append("t2iadapter")
adapter = T2IAdapter.from_pretrained(
f"{config.model_path}/{config.t2iadapter_id}", torch_dtype=weight_format
).to(device)
# process spatial controls
cond_image = None
if ("controlnet" in model_list) or ("t2iadapter" in model_list):
print("process spatial controls")
spatial_id = config.controlnet_id if "controlnet_id" in config else config.t2iadapter_id
cond_image = Image.open(config.cond_image).convert("RGB")
cond_image = cond_image.resize((config.W, config.H), Image.NEAREST)
cond_image = img2cond(spatial_id, cond_image, config.model_path)
image_convert = img2cond(spatial_id, image, config.model_path)
image_convert = mask4image(
-preprocess_image(image_convert), preprocess_image(mask_image)
)
cond_image = mask4image(
-preprocess_image(cond_image), -preprocess_image(mask_image)
)
cond_image = (image_convert + 1) / 2 + (cond_image + 1) / 2
cond_image = 2 * cond_image - 1
cond_image = tensor2PIL(-cond_image)
# load base model
print("load base model")
if config.fp16:
pipe = PilotPipeline.from_pretrained(
f"{config.model_path}/{config.model_id}",
controlnet=controlnet,
adapter=adapter,
torch_dtype=torch.float16,
variant="fp16",
requires_safety_checker=False,
).to(device)
else:
pipe = PilotPipeline.from_pretrained(
f"{config.model_path}/{config.model_id}",
controlnet=controlnet,
adapter=adapter,
torch_dtype=torch.float16,
requires_safety_checker=False,
).to(device)
if "t2iadapter" in model_list:
if "t2iadapter_scale" in config:
pipe.set_t2i_adapter_scale([config.t2iadapter_scale])
else:
pipe.set_t2i_adapter_scale(1)
if "controlnet" in model_list:
if "controlnet_scale" in config:
pipe.set_controlnet_scale([config.controlnet_scale])
else:
pipe.set_controlnet_scale(1)
# load lora
if "lora_id" in config:
print("load lora")
for i in range(len(config.lora_id)):
lora_id = config.lora_id[i]
lora_scale = config.lora_scale[i]
pipe.load_lora_weights(
f"{config.model_path}/{lora_id}",
weight_name="model.safetensors",
torch_dtype=torch.float16,
adapter_name=lora_id,
)
print(f"lora id: {lora_id}*{lora_scale}")
pipe.set_adapters(config.lora_id, adapter_weights=config.lora_scale)
# load ip adapter
ip_image = None
if "ipa_id" in config:
print("load ip adapter")
model_list.append("ipa")
pipe.load_ip_adapter(
f"{config.model_path}/ip_adapter",
subfolder="v1-5",
weight_name="ip-adapter_sd15_light.bin",
)
revise_pilot_unet_attention_forward(pipe.unet)
ip_image = Image.open(config.ip_image)
ip_image = ip_image.resize((config.W, config.H), Image.NEAREST)
if "ip_scale" not in config:
config.ip_scale = 0.8
pipe.set_ip_adapter_scale(config.ip_scale)
pipe.scheduler = DDIMScheduler.from_config(pipe.scheduler.config)
generator = torch.Generator(device="cuda").manual_seed(config.seed)
pipe.to("cuda", weight_format)
#################################### run examples and save results ##########################
image_list = pipe(
prompt=prompt_list,
num_inference_steps=config.step,
height=config.H,
width=config.W,
guidance_scale=config.cfg,
num_images_per_prompt=config.num,
image=image,
mask=mask_image,
generator=generator,
lr_f=config.lr_f,
momentum=config.momentum,
lr=config.lr,
lr_warmup=config.lr_warmup,
coef=config.coef,
coef_f=config.coef_f,
op_interval=config.op_interval,
cond_image=cond_image,
num_gradient_ops=config.num_gradient_ops,
gamma=config.gamma,
return_dict=True,
ip_adapter_image=ip_image,
model_list=model_list
)
if "ipa" in model_list and "controlnet" in model_list:
new_image_list = ipa_spatial_visualize(image=image, mask_image=mask_image, ip_image=ip_image,
cond_image=cond_image, result_list=image_list)
elif "controlnet" in model_list or "t2iadapter" in model_list:
new_image_list = spatial_visualize(image=image, mask_image=mask_image, cond_image=cond_image,
result_list=image_list)
elif "ipa" in model_list:
new_image_list = ipa_visualize(image=image, mask_image=mask_image, ip_image=ip_image, result_list=image_list)
else:
image_list[0].save(os.path.join('file_out/prompt',os.path.basename(image_path)))
mask_image.save(os.path.join('file_out/mask', os.path.basename(image_path)))
new_image_list = t2i_visualize(image=image, mask_image=mask_image, result_list=image_list)
file_path = (
f"{config.output_path}/seed{config.seed}_step{config.step}.png"
)
for new_image in new_image_list:
if os.path.exists(file_path):
base, ext = os.path.splitext(file_path)
j = 0
while True:
j += 1
file_path = f"{base}_{j}{ext}"
if not os.path.exists(file_path):
break
new_image.save(file_path)
print(f"image save in {file_path}")
以上环境可以使用同一个环境:
conda create -n pilot python==3.9
conda activate pilot
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu118
pip install -r requirements.txt这里的
requirements.txt就是PILOT的环境。
当时还出现一个错误:
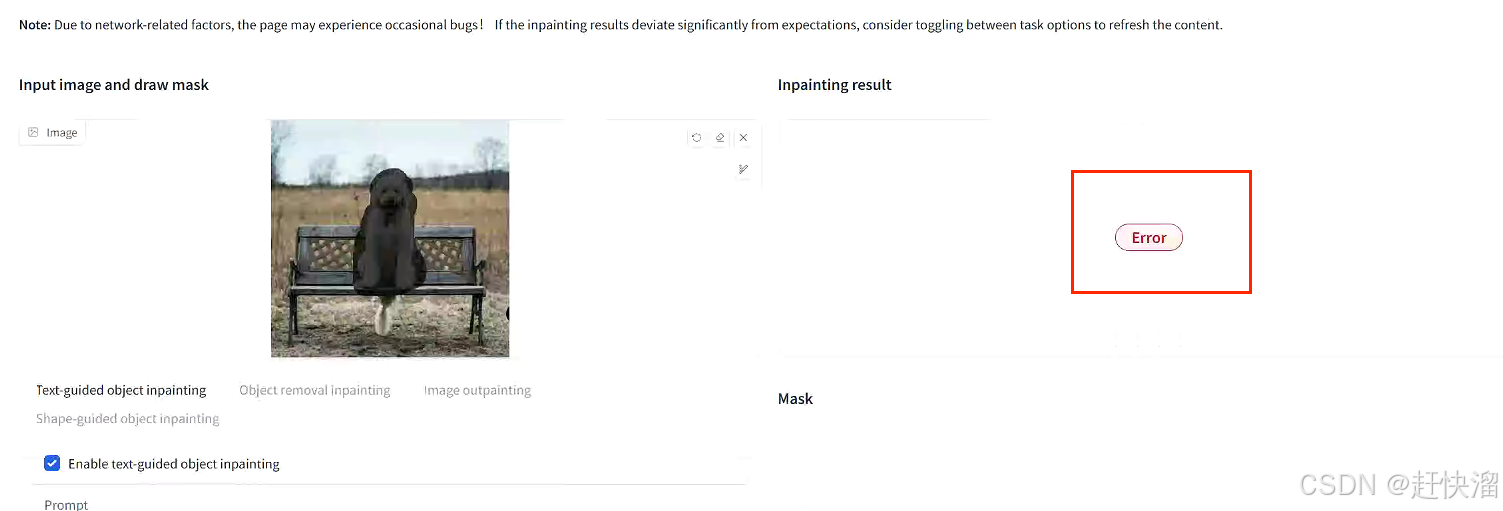
四、说明:
以上内容是本人在使用上述模型的时候所遇到的问题,有可能书写的有错误,欢迎一起交流


















 1367
1367

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









