






 Squeeze-and-Excitation Networks(简称SENet)是由Momenta的胡杰团队(WMW)提出的一种新的网络结构。该网络结构的核心思想是通过显式地建模特征通道之间的相互依赖关系,来提高网络的表示能力。SENet的提出基于一种全新的“特征重标定”策略,通过学习的方式来自动获取到每个特征通道的重要程度,然后依照这个重要程度去提升有用的特征并抑制对当前任务用处不大的特征。
Squeeze-and-Excitation Networks(简称SENet)是由Momenta的胡杰团队(WMW)提出的一种新的网络结构。该网络结构的核心思想是通过显式地建模特征通道之间的相互依赖关系,来提高网络的表示能力。SENet的提出基于一种全新的“特征重标定”策略,通过学习的方式来自动获取到每个特征通道的重要程度,然后依照这个重要程度去提升有用的特征并抑制对当前任务用处不大的特征。
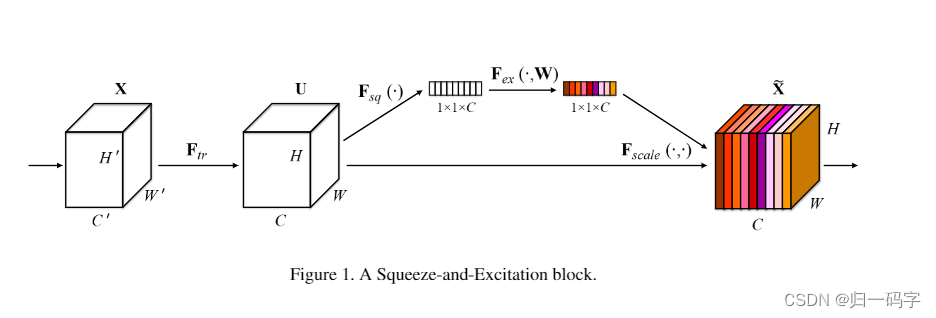
SENet的核心模块是Squeeze-and-Excitation(SE)块,这个模块包含两个主要步骤:Squeeze(挤压)和Excitation(激励)。
在Squeeze步骤中,首先对每个特征通道进行全局平均池化(Global Average Pooling),将每个二维的特征通道变成一个实数,这个实数某种程度上具有全局的感受野,并且输出的维度和输入的特征通道数相匹配。这个步骤可以看作是对特征通道的全局信息嵌入。
在Excitation步骤中,通过两个全连接层(Fully Connected Layers)和一个Sigmoid激活函数来构建一个门控机制,这个门控机制可以学习到每个特征通道的重要程度。具体来说,第一个全连接层将特征通道数降维到一个较低的维度(例如1/16),然后经过ReLU激活函数,再经过第二个全连接层将特征通道数恢复到原来的维度。最后,通过一个Sigmoid激活函数将输出值限制在0到1之间,这个值就可以作为每个特征通道的权重,即scale。
将得到的scale值乘到原来的特征通道上,就可以实现对原始特征的重标定。这种重标定的方式可以根据任务的需要来自动地增强或抑制不同的特征通道,从而使得网络能够更好地适应不同的任务。
SENet在ImageNet 2017竞赛的Image Classification任务中取得了冠军,将top-5 error降低到2.251%,比之前的最好成绩提高了约25%。此外,SENet还可以轻松地嵌入到现有的多种分类网络中,并且都能取得不错的效果。这表明SENet是一种非常有效的网络结构,可以在各种任务中提高网络的性能。
``python
import numpy as np
import torch
from torch import nn
from torch.nn import init
class SEAttention(nn.Module):
# 初始化SE模块,channel为通道数,reduction为降维比率
def __init__(self, channel=512, reduction=16):
super().__init__()
self.avg_pool = nn.AdaptiveAvgPool2d(1) # 自适应平均池化层,将特征图的空间维度压缩为1x1
self.fc = nn.Sequential( # 定义两个全连接层作为激励操作,通过降维和升维调整通道重要性
nn.Linear(channel, channel // reduction, bias=False), # 降维,减少参数数量和计算量
nn.ReLU(inplace=True), # ReLU激活函数,引入非线性
nn.Linear(channel // reduction, channel, bias=False), # 升维,恢复到原始通道数
nn.Sigmoid() # Sigmoid激活函数,输出每个通道的重要性系数
)
# 权重初始化方法
def init_weights(self):
for m in self.modules(): # 遍历模块中的所有子模块
if isinstance(m, nn.Conv2d): # 对于卷积层
init.kaiming_normal_(m.weight, mode='fan_out') # 使用Kaiming初始化方法初始化权重
if m.bias is not None:
init.constant_(m.bias, 0) # 如果有偏置项,则初始化为0
elif isinstance(m, nn.BatchNorm2d): # 对于批归一化层
init.constant_(m.weight, 1) # 权重初始化为1
init.constant_(m.bias, 0) # 偏置初始化为0
elif isinstance(m, nn.Linear): # 对于全连接层
init.normal_(m.weight, std=0.001) # 权重使用正态分布初始化
if m.bias is not None:
init.constant_(m.bias, 0) # 偏置初始化为0
# 前向传播方法
def forward(self, x):
b, c, _, _ = x.size() # 获取输入x的批量大小b和通道数c
y = self.avg_pool(x).view(b, c) # 通过自适应平均池化层后,调整形状以匹配全连接层的输入
y = self.fc(y).view(b, c, 1, 1) # 通过全连接层计算通道重要性,调整形状以匹配原始特征图的形状
return x * y.expand_as(x) # 将通道重要性系数应用到原始特征图上,进行特征重新校准
# 示例使用
if __name__ == '__main__':
input = torch.randn(50, 512, 7, 7) # 随机生成一个输入特征图
se = SEAttention(channel=512, reduction=8) # 实例化SE模块,设置降维比率为8
output = se(input) # 将输入特征图通过SE模块进行处理
print(output.shape) # 打印处理后的特征图形状,验证SE模块的作用















 20万+
20万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









