









 这篇博客介绍了使用Python3.8和PyQT5开发的GUI系统,结合深度学习框架TensorFlow,实现基于Xception和VGG_16模型的人脸表情识别。数据集包括FER2013和CK+,模型在FER2013上的准确率分别为63%和66%,在CK+上达到94%和95%。训练过程使用Tensorboard进行可视化。此外,还提供了CUDA和CuDNN的兼容性指南,以及如何使用pip安装特定版本的Python库。
这篇博客介绍了使用Python3.8和PyQT5开发的GUI系统,结合深度学习框架TensorFlow,实现基于Xception和VGG_16模型的人脸表情识别。数据集包括FER2013和CK+,模型在FER2013上的准确率分别为63%和66%,在CK+上达到94%和95%。训练过程使用Tensorboard进行可视化。此外,还提供了CUDA和CuDNN的兼容性指南,以及如何使用pip安装特定版本的Python库。
编译器 python3.8
开发平台 Pycharm
PyQT5 系统界面 (可视化开发工具designer )
模型训练基于深度学习tensorflow框架
opencv haar cascade 级联分类器 识别人脸
数据集为 fer2013和CK+ 7种表情划分
CNN架构:Xception和VGG_16
GPU加速
tip:1、配置GPU参考博文https://blog.csdn.net/qilixuening/article/details/77503631 https://blog.csdn.net/sinat_23619409/article/details/84202651等。
CUDA和CuDNN的版本一定要兼容 ,例如CUDA 11.1.1对应的CuDNN版本为 8.1.1
CUDA下载地址:https://developer.nvidia.com/cuda-toolkit-archive
官网下载地址:https://developer.nvidia.com/rdp/cudnn-download
)
2、PyQt的学习可以网上买些相关书籍学习 。Pycharm中使用PyUIC可将designer.exe设计的.ui文件转为.py
系统运行所需要的库:
Python 3.8.1
imutils 0.5.4
keras 2.7.0
numpy 1.22.2
pandas 1.0.5
pip 22.0.3
PyQt5 5.15.4
scikit-learn 1.0.2
tensorboard 2.7.0
tensorflow-gpu 2.7.0
opencv-python 4.5.5.62
matplotlib 3.5.1
tip:如何使用pip安装特定版本的python第三方包https://blog.csdn.net/colourful_sky/article/details/80182082
数据集
FER2013
FER2013数据集是由Kaggle提供的csv文件,其中每一行包含该图片的表情分类标签,像素信息以及数据及分类用途。整个数据集其中涵盖了28709张进行训练的图像,3589张验证的图像与3589张进行测试的图像。 这些图片划分为7个表情标签,分别是(anger,disgust,fear,happiness,sadness,surprise和neutral)。
CK+
CK+数据集在Cohn-Kanade 数据集基础上进行了扩展,并在2010年发布,该数据集包含123个对象和593个图像序列。CK+数据集来源于123个采集对象,主要来自西方国家,划分了7种表情,包括惊讶,轻蔑,生气,害怕,高兴,厌恶和悲伤。共计327个被标记的人脸表情序列,在每个序列中研究者们记录了受试者从正常表情即中性表情,逐渐转变到某种所要求的表情的过程,并将每个序列的最后一张图像作为所要求表情的数据图片。这个数据集是目前人脸表情识别研究中比较流行的一个数据集。

tip:FER2013数据集存储的是一个个像素点,CK+中存储的是一张张图片,且都是48*48的分辨率。
模型
VGG_16
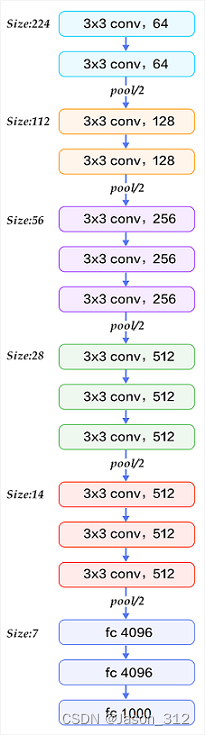
VGGNet是由Simonyan等人提出的深度卷积神经网络,是由Google Deep Mind团队和牛津大学合作完成的。VGGNet模型证明了通过增加网络深度可以有效地增强模型性能。“VGGNet的卷积核采用小而多的形式,使用了三个3×3的卷积核,而不是一个大的卷积核;这样做的好处是既增大了网络的深度,也没有加大运算量”。下图为VGGNet系列的网络结构示意图。根据卷积层层数和卷积核大小,VGG系列共有6种配置,分别为A、A_LRN、B、C、D和E。其中D和E是最被广泛使用的,也就是VGGNet16和VGGNet19。
Xception
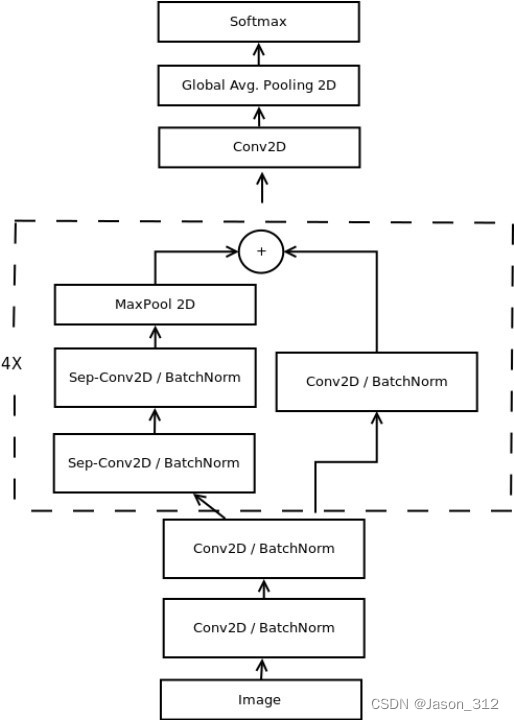
Xception是Google继Inception后提出的对Inception v3的另一种改进,主要是采用深度可分离卷积(Depthwise separable convolution)来替换原来Inception v3中的卷积操作[30]。在GooleLeNet中,采用了全局均值池化(Global Average Pooling)来作为网络的最后一层,其优点在于降低了上一层参数的具体数量。全局平均池化主要是对所有元素取平均值。平均操作迫使网络从输入图像中提取全局特征。Xception的卷积神经网络架构充分利用了残差模块和深度可分离卷积的组合使用。深度可分离卷积通过在一个卷积层内分离特征提取和组合过程进一步减少了参数的数量。
关于该模型可参考论文:Xception: Deep Learning with Depthwise Separable Convolutions,论文Real-time Convolutional Neural Networks for Emotion and Gender Classification等。
基于Fer2013数据集,VGG_16网络模型识别准确率在63%,Xception 网络模型是66%;
基于CK+数据集,VGG_16网络模型识别准确率在94%,Xception网络模型是95%。
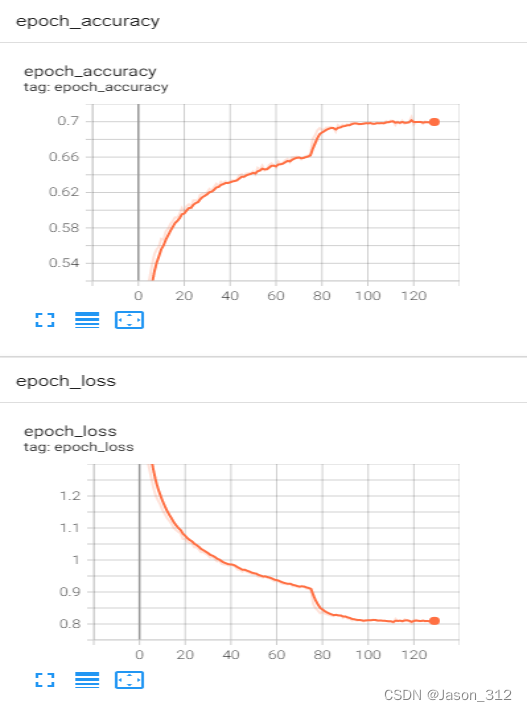
模型训练数据可视化(tensorboard。它的主要用途在于在训练过程中以可视化的方法监控模型内部发生的一切。把训练中的损失函数、测试集准确率可视化。如下图所示。)
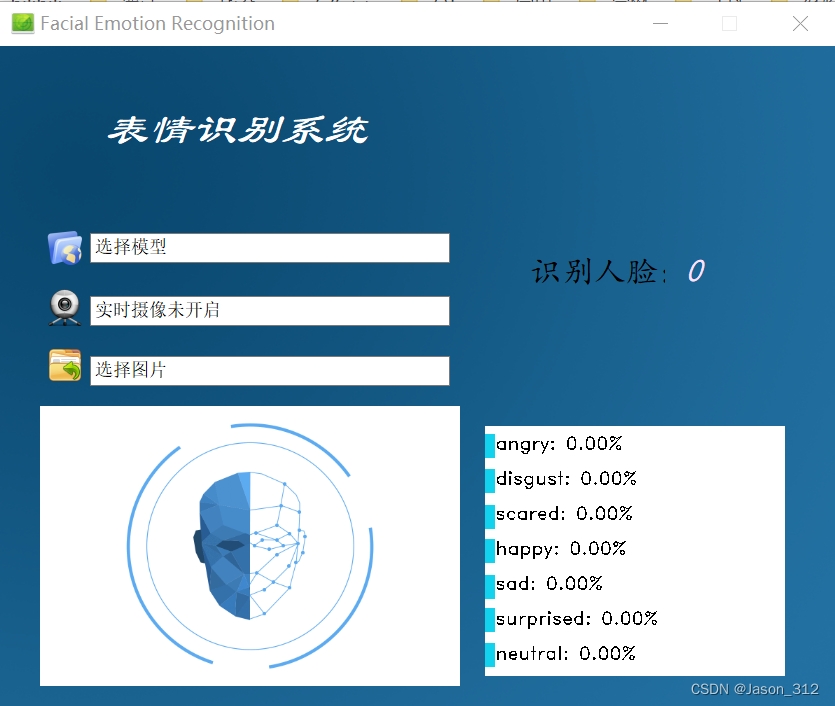
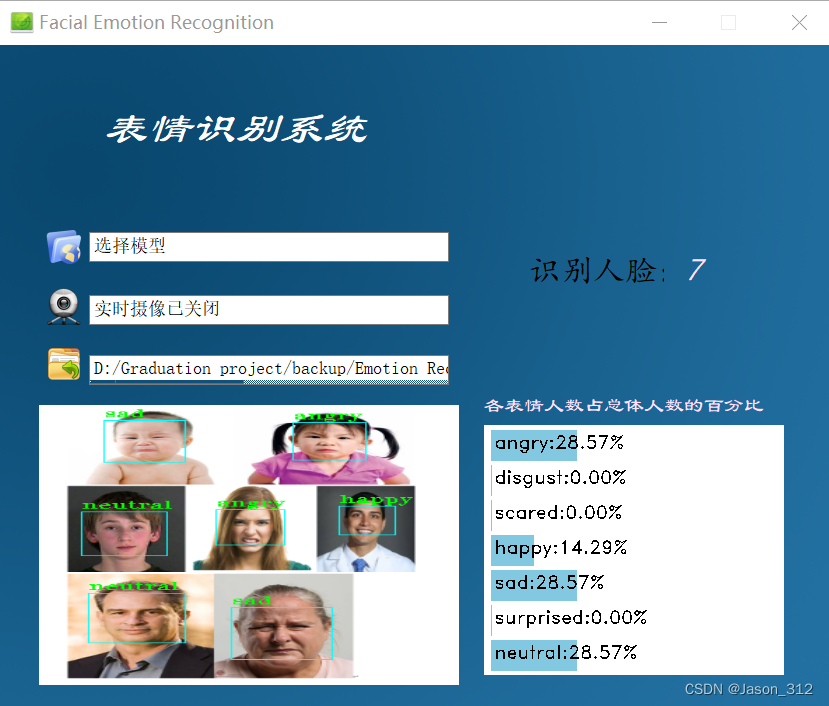
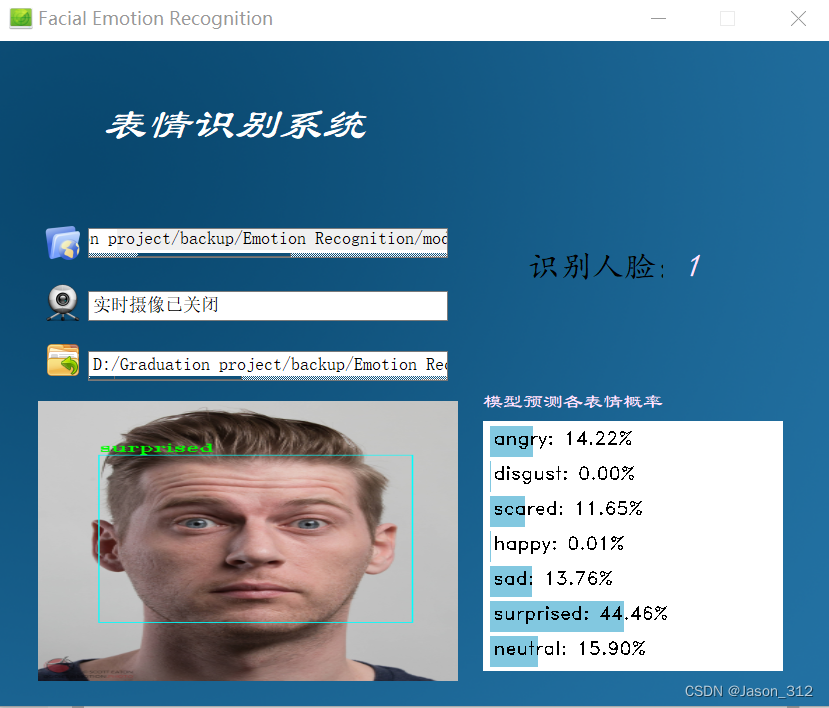
系统测试
主界面运行Mainwindow.py。
实时摄像也是可以的,大家可以获取源码后自行测试。(源码获取在文末)
下载链接
如果你对本系统感兴趣,获取全部源码。可点以下链接。

















 2926
2926

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









