






#AI夏令营 #Datawhale #夏令营
一、赛题背景
随着全球经济的快速发展和城市化进程的加速,电力系统面临着越来越大的挑战。电力需求的准确预测对于电网的稳定运行、能源的有效管理以及可再生能源的整合至关重要。然而,电力需求受到多种因素的影响,为了提高电力需求预测的准确性和可靠性,推动智能电网和可持续能源系统的发展,本场以“电力需求预测”为赛题的数据算法挑战赛。选手需要根据历史数据构建有效的模型,能够准确的预测未来电力需求。
二、赛题任务
给定多个房屋对应电力消耗历史N天的相关序列数据等信息,预测房屋对应电力的消耗。
2.1数据说明
赛题数据由训练集和测试集组成,为了保证比赛的公平性,将每日日期进行脱敏,用1-N进行标识,即1为数据集最近一天,其中1-10为测试集数据。数据集由字段id(房屋id)、 dt(日标识)、type(房屋类型)、target(实际电力消耗)组成。
| 特征字段 | 字段描述 |
|---|---|
| id | 房屋id |
| dt | 日标识 |
| type | 房屋类型 |
| target | 实际电力消耗,预测目标 |
2.2评审规则
预测结果以 mean square error 作为评判标准,具体公式如下:
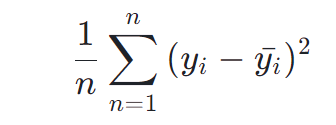
其中,![]() 是真实电力消耗,
是真实电力消耗,![]() 是预测电力消耗。
是预测电力消耗。
三、初步代码
# 1. 导入需要用到的相关库
# 导入 pandas 库,用于数据处理和分析
import pandas as pd
# 导入 numpy 库,用于科学计算和多维数组操作
import numpy as np
# 2. 读取训练集和测试集
# 使用 read_csv() 函数从文件中读取训练集数据,文件名为 'train.csv'
train = pd.read_csv('./data/data283931/train.csv')
# 使用 read_csv() 函数从文件中读取测试集数据,文件名为 'test.csv'
test = pd.read_csv('./data/data283931/test.csv')
# 3. 计算训练数据最近11-20单位时间内对应id的目标均值
target_mean = train[train['dt']<=20].groupby(['id'])['target'].mean().reset_index()
# 4. 将target_mean作为测试集结果进行合并
test = test.merge(target_mean, on=['id'], how='left')
# 5. 保存结果文件到本地
test[['id','dt','target']].to_csv('submit.csv', index=None)个人代码总结:
这段代码主要是用于数据处理、分析和保存结果到本地的过程。
- 通过导入 pandas 库和 numpy 库,将它们分别重命名为 pd 和 np。
- 使用 pd.read_csv() 方法读取训练集和测试集数据。
- 计算训练集中时间戳('dt' 列)小于等于20的数据的目标列('target')的均值,并将结果存储到变量 target_mean 中。
- 将测试集数据与目标均值结果按照'id'进行左连接合并,存储到变量 test 中。
- 从合并后的数据中选择'id'、'dt' 和 'target' 列,然后将结果保存到名为 'submit.csv' 的文件中,不包括索引。















 242
242











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









