






论文名称:BEVHeight: A Robust Framework for Vision-based Roadside 3D Object Detection
论文地址:https://arxiv.org/pdf/2303.08498.pdf
代码地址:https://github.com/ADLab-AutoDrive/BEVHeight
总结:这篇文章比较有意思的点在于其他3D检测采用的是基于深度的检测,而这篇文章是基于高度 。重点看HeightNet和2D->3Dprojector两个部分就可以了,其他地方没什么。
摘要
现有问题: 以视觉为中心的鸟瞰图检测方法在路边摄像头上的性能较差。
原因: 现有方法恢复汽车的深度。
解决问题: 不预测像素级深度而是将高度回归到地面(预测高度),在路边摄像头的3D检测任务中性能提高了。
介绍
通过深度检测车辆的缺点:
1.与具有一致相机姿势的自动驾驶汽车不同,路边通常在数据集中具有不同的相机位姿参数,这使得回归深度变得困难;
2.深度预测对外部参数的变化非常敏感,在现实世界中经常发生这种情况。(路边相机因风抖动)
想法:
无论汽车与相机中心之间的距离是多少,地面的高度一致,因此提出新的框架预测每个像素的高度而不是深度,称为BEVHeight。
具体:
首先预测每个像素的分类高度分布,将丰富的上下文特征信息投影到杂草体素空间中适当的高度区间。然后进行体素池化操作和检测头得到最终的输出检测。此外,我们提出了一种超参数可调的高度采样策略。
方法
问题定义
已知: 路边相机图像,路边相机内参和外参
目标: 检测图像当中物体的3D边界框,每个3D边界框含有7个自由度向量。(x,y,z)每个边界框的位置,(l,w,h)长方体的长宽高,混合每个实例相对于一个特定轴的偏航角。
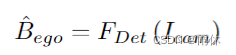
比较深度和高度
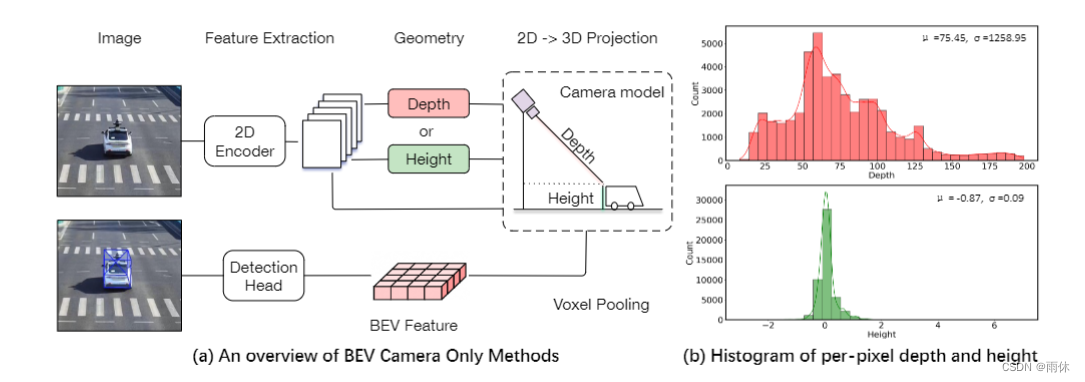
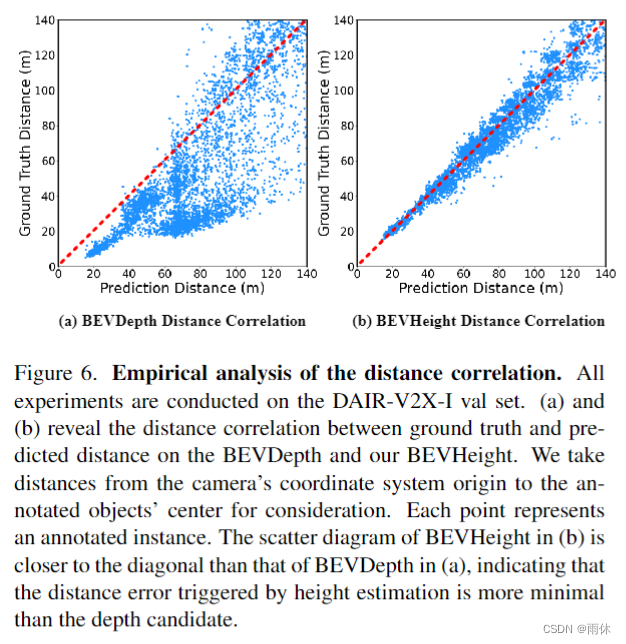
利用DAIR-V2X-I[39]数据集的LiDAR点云,我们首先将这些点投影到图像上,绘制图2 (b)中逐像素深度的直方图。我们可以观察到从 0 到 200 米的大范围。相比之下,我们将逐像素高度的直方图绘制到地面,并清楚地观察到高度分别在 -1 到 2m 之间,这对于网络更容易预测。

BEVHeight
整体架构

分为五部分:
-
图像视图编码器: 由2D骨干网络和FPN模块组成,输入:给定路边视图图像

,输出2D高维多尺度特征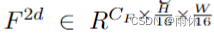
-
HeightNet: 预测高度分布bins-like
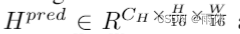
和上下文特征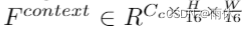
。CH代表高度箱的数量,Cc 表示上下文特征的通道。然后使用公式3生成结合图像上下文和高度分布的融合特征F f。
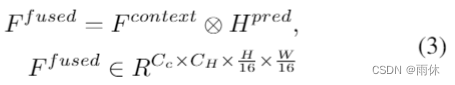
-
基于高度的2D→3D投影: 将融合后的特征推入3D楔形特征。
-
BEV特征转化: 体素池将3D楔形特征沿高度方向转换为BEV特征F。
-
编码+目标检测: 3D检测头首先用卷积层对BEV特征进行编码,然后预测由位置(x, y, z)、维度(l, w, h)和方向θ组成的3D边界框。
HeightNet
跟BEVDepth网络差不多利用Squeeze-and-Excitation层从2D图像特征F 2d生成上下文特征F上下文。 (具体操作可看源码)
- 堆叠多个残差快增加表示能力
- 使用可变形卷积预测每个像素高度(将回归任务转换为使用one-hot编码,将高度离散化为各种高度bin),且提出动态离散化。
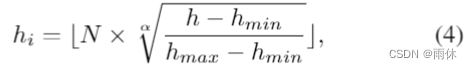 其中 h 表示地面的连续高度值,hmin 和 hmax 表示高度范围的开始和结束。N 是高度 bin 的数量,hi 表示第 i 个高度 bin 的值,H是路边摄像头的高度,α是控制高度箱浓度的炒作参数。
其中 h 表示地面的连续高度值,hmin 和 hmax 表示高度范围的开始和结束。N 是高度 bin 的数量,hi 表示第 i 个高度 bin 的值,H是路边摄像头的高度,α是控制高度箱浓度的炒作参数。
基于高度的2D-3D投影模块。
设计了一个新的2D到3D投影模块,将融合后的特征 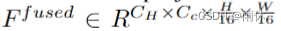 推入EGO坐标系中的楔形体特征
推入EGO坐标系中的楔形体特征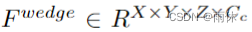
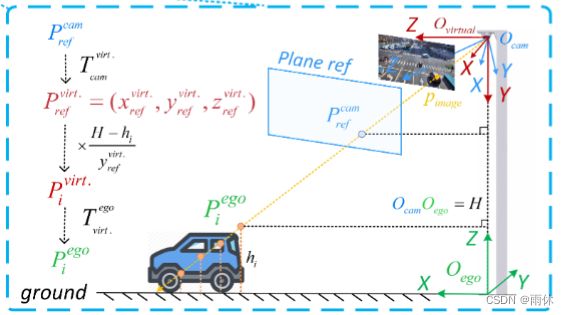
投影公式如下:

实验
数据集
采用车路协同数据集DAIR-V2X. 和 Rope3D
实验设置
2D骨干网络采用ResNet-101,输入分辨率(864,1536),所有方法都使用 AdamW optimzer [21] 训练了 150 个 epoch,其中初始学习率设置为 2e-4。在2D 空间中使用随机缩放和旋转进行数据增强。
与最先进的技术相比

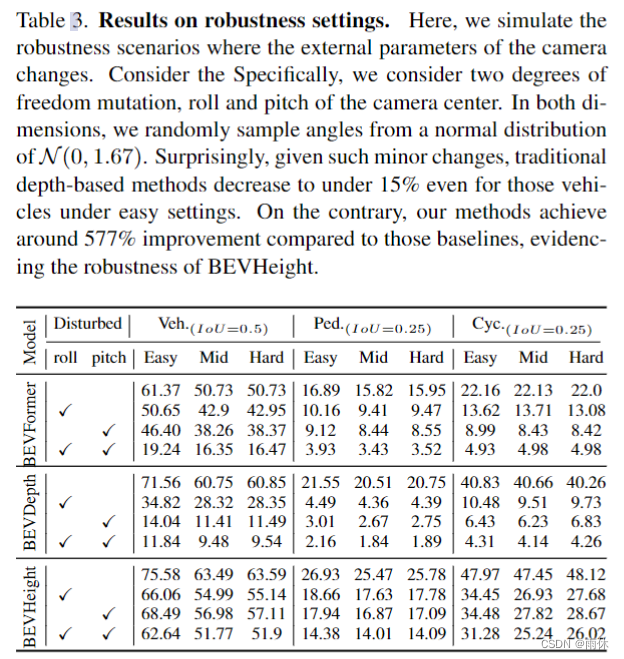

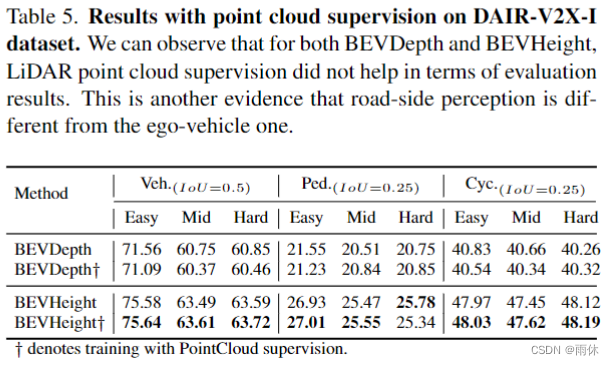















 4721
4721











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









