







一句话总结:模仿 git 实现版本控制,利用 DRL 实现客户选择,平衡分支模型的版本,解决全局模型不能充分地从掉队者那里学习知识的问题
1. 论文信息
GitFL: Uncertainty-Aware Real-Time Asynchronous Federated Learning using Version Control,IEEE Real-Time Systems Symposium (RTSS) ,ccfa
发表时间:2023.12
2. introduction
2.1.1. 背景:AIoT(人工智能物联网)场景下进行异步联邦学习
2.1.2. 解决的问题:
推理性能低、整体训练时间长
- 异构设备、数据不平衡、不稳定环境-> 模型训练速度不同-> 分支模型之间存在版本差距-> 模型陈旧->为过时的模型分配较低的权重,以减少这些模型对聚合过程的影响-> 全局模型不能充分地从掉队者那里学习知识-> 推理精度低
- 异构设备、数据不平衡、不稳定环境-> 模型训练速度不同-> 协调参与训练设备的模型版本-> 未经协调,有时需要放慢整体学习速度等待慢速设备-> 整体训练时间长
2.1.3. 贡献点:
- 基于推、拉、合并操作,建立了一个类似git的异步FL框架,既支持在各种不确定环境下对掉线设备的有效管理,也支持对其陈旧模型的版本控制
- 开发了一种新的基于强化学习(RL)的好奇心驱动探索方法,以自适应的方式支持对掉队设备的明智选择。gitFL 在AIoT设备之间实现了版本化模型的负载平衡,从而避免了由掉队器引起的性能下降
- 实验证明 gitFL 在IID和非IID场景的收敛速度和推理性能方面的有效性
3. 问题描述:
Motivation
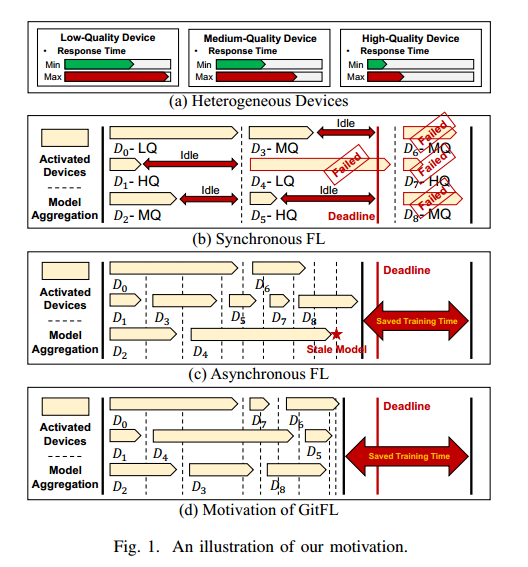
(a):按计算能力将设备分为三种不同的类型(低质量、中质量和高质量)
(b)和(c):异步FL 相较于 同步FL来说可以确保在给定的截止时间内所有设备都能参与
由于聚合陈旧的模型,异步FL存在推理精度低的问题
如图1(c)所示,在D4上进行局部训练后,云服务器需要将三个设备(即D1、D2和D4)训练的陈旧的局部模型进行汇总,而全局模型已经更新了7次。
(d):GitFL 与 异步FL 比 做设备选择:将低版本的模型分配到高性能的设备
全局模型仅用于积累分支模型获得的版本化知识
最终,所有分支模型都有相似的版本,意味着所有分支模型都有相似的权重来生成全局模型。
效果:既能充分学习到掉队者的知识,又能防止聚合陈旧模型导致的推理精度下降
受 Git 的启发,将每个上传的本地模型视为一个分支模型,并为每个分支模型分配一个版本号,以跟踪其训练次数。每个分支模型将自己的参数推入全局模型,然后根据特定的权重与全局模型合并,这样分支模型可以在保留所学知识的同时从全局模型中提取知识。
4. 解决方法
4.1. Overview
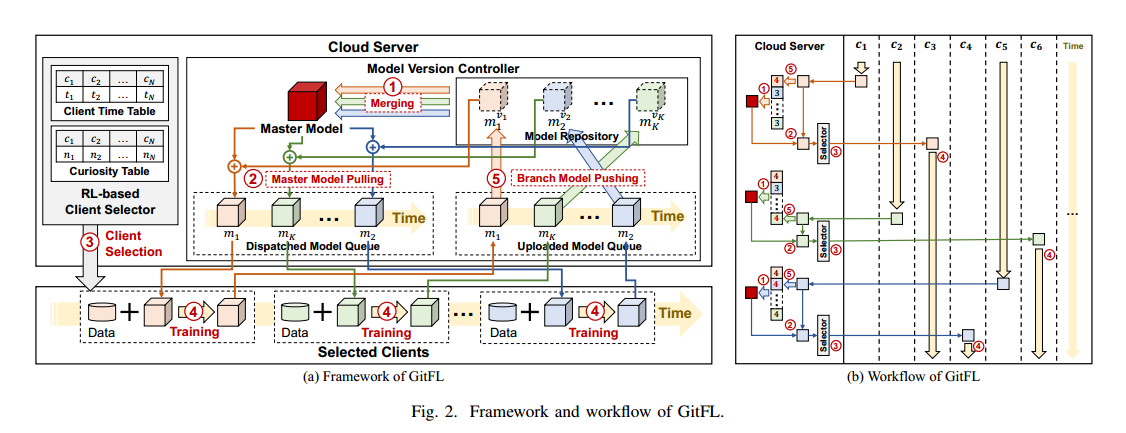
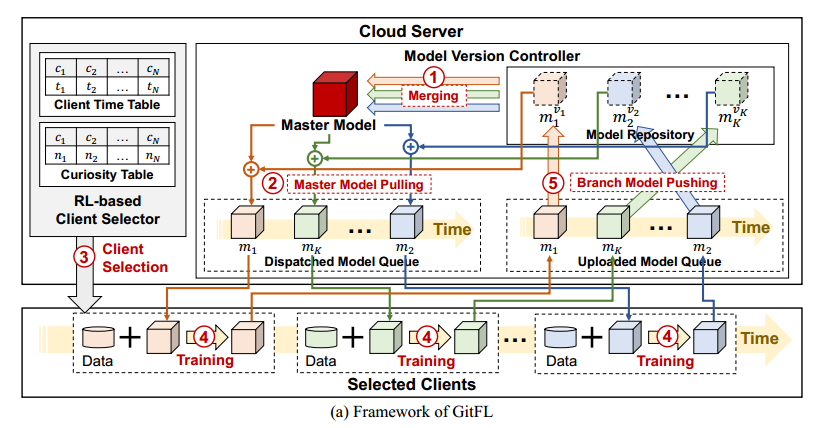
主要步骤:
- 模型合并:控制器根据每个分支模型版本计算的权重合并存储库中的所有分支模型,生成一个新的主模型。为了避免陈旧模型造成的推理退化,对低版本的分支模型赋予低权重。
- pull 模型:控制器通过合并新的主模型并将其推入已调度模型队列来更新已调度分支模型。低版本的模型被赋予较低的权重进行合并,可以使陈旧的模型从主模型中学习到更多的知识。
- 客户端选择:客户端选择器使用基于 RL 的客户端选择策略为分支模型调度选择一个客户端
- 本地训练:选定的客户端使用本地数据训练接收到的分支模型。为了保护隐私,GitFL 不需要获取客户的任何额外信息,本地训练过程与传统FL相同。
- push 模型:控制器将分支模型push到存储库中,更新分支模型的版本,并在客户端时间表和计数表中更新分支模型对应的条目
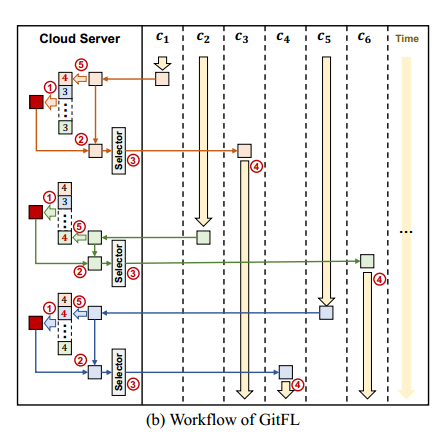
当从 c1 接收分支模型 m1时,云服务器将该模型推入存储库并将其版本更新为 4。每个分支模型在存储库中都有一个固定的存储位置。然后,云服务器合并存储库中的所有模型以生成一个新的主模型。这里m1的权重大于 m2和mK,因为它的版本高于m2和mK的版本。接下来,云服务器拉出主模型并将其与m1合并以更新一个新的m1。注意,更新后的m1不存储在存储库中。最后,客户端选择器选择客户端c3,并将更新后的m1分派给c3进行本地训练
4.2. 执行流程:

![]()
随着每次本地训练的完成,动态更新客户端的平均训练时间,以便在强化学习选择策略中使用,帮助选择下一个进行训练的客户端。通过这种方式,GitFL框架能够考虑到客户端的实时性能,并做出更加合理的客户端选择决策
4.3. 挑战问题怎么解决:
问题:推理性能低、整体训练时间长
- 异构设备、数据不平衡、不稳定环境-> 模型训练速度不同-> 分支模型之间存在版本差距-> 模型陈旧->为过时的模型分配较低的权重,以减少这些模型对聚合过程的影响-> 全局模型不能充分地从掉队者那里学习知识-> 推理精度低(模型版本控制)
- 异构设备、数据不平衡、不稳定环境-> 模型训练速度不同-> 协调参与训练设备的模型版本-> 未经协调,有时需要放慢整体学习速度等待慢速设备-> 整体训练时间长(DRL 客户选择进行协调,平衡分支模型版本)
4.3.1. 模型版本控制
基于推、拉、合并操作,建立一个类似git的异步FL框架,既支持在各种不确定环境下对掉线设备的有效管理,也支持对其陈旧模型的版本控制
- Model Merging
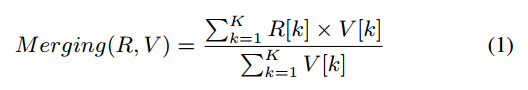
R表示模型存储库,K表示分支模型的数量,V表示版本信息列表
直接使用模型版本作为合并权值,而不是版本间的差异。在训练开始时,具有更高版本的模型应该在合并中占主导地位,因为它们更准确。此时,使用模型版本或版本差异作为权重都是合理的。然而,随着FL训练的进展,所有的模型都得到了很好的训练。此时,期望所有的模型都充分参与合并。与版本的差异相比,模型版本更有可能平等地合并模型(模型版本直接作为权重可以更直接地平衡不同模型对主模型的贡献。如果使用版本差异作为权重,可能会导致对某些模型的过度强调或忽视,特别是当版本差异较大时)
- Model Pulling:
为实现跨分支模型的知识共享,每个分支模型需要在模型调度之前拉下主模型。在每个拉取步骤中,GitFL将分支模型与主模型聚合更新分支模型,按照该分支模型的版本分配聚合权重。具有更高版本的分支模型被分配更大的权重。
一方面,具有更高版本的模型更有可能得到良好的训练,它们只需要从主模型获得较少的知识。
另一方面,主模型中包含的掉队者的知识可能会对具有更高版本的模型产生负面影响。版本较低的模型,训练不足,需要向主模型学习更多的知识。因此,在聚合中被赋予较低的权重。
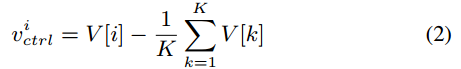
分支模型的版本与所有分支模型的平均版本之差

根据分支模型的版本信息平衡两者的知识,使得更新后的分支模型既能够从主模型中学习,又能够保留自己的特性
- max(10+vi_ctrl,2) 计算了分支模型 𝑚𝑖 在更新时的权重。如果 𝑣𝑖_𝑐𝑡𝑟𝑙 是正的并且足够大,那么这个权重会更大,意味着分支模型将保留更多的自身知识。即使 𝑣𝑖_𝑐𝑡𝑟𝑙 很小,权重也至少为2,避免在 𝑣𝑖_𝑐𝑡𝑟𝑙 为负时,分支模型权重过小,从主模型 𝑀 学习到的知识太多,引起梯度发散问题
M为由式(1)
生成的主模型。在模型拉取过程中,主模型的权重过大,使得分支模型的更新过于粗粒度,可能导致梯度发散问题。每个分支模型的权重设置为大于主模型的权重,分支模型能够更平滑、更细粒度地从主模型中获取知识
- Model Pushing:
当上传的队列接收到训练好的分支模型,模型版本控制器将接收到的分支模型推送到模型存储库并更新其版本信息。用新版本替换模型的旧版本,对于每个分支模型,模型存储库只保留最新版本。在GitFL中,模型存储库只存储K个模型。
4.3.2. 基于强化学习驱动的设备选择策略
为了平衡分支模型的版本,设计了一种基于分支模型版本、客户的历史训练时间和客户的选择数量来选择客户的强化学习策略。
客户端选择器倾向于为低版本的分支模型选择训练时间较快的客户端,而为高版本的分支模型选择训练时间较慢的客户端。因此,客户的选择取决于
- 目标分支模型的版本和所有分支模型的平均版本
- 所有候选客户的训练时间
为平衡客户参与训练的次数,把每个客户的选择次数作为是否选择该客户的指标之一
M =〈S, A, F, R〉
- S是状态。s =〈Bm, V, Ct, Tc〉表示GitFL的状态,Bm表示等待调度的分支模型集,V是所有分支模型的版本信息列表,Ct表示当前本地训练的客户集,Tc是记录所有客户端选择次数的表。
- A是动作。在s =〈Bm, V, Ct, Tc〉的状态下,动作a在Ct中选择一个候选客户端,然后将Bm中的分支模型分派给所选的客户端。A的选择空间是Ct中的所有客户端。
- F是转换。记录了转换 s → s '与动作 a →a'
- R是奖励函数。将选择的次数和选择的客户的培训时间结合起来作为奖励来评估选择的质量
GitFL采用版本和好奇心驱动的策略来评估奖励。客户选择器更倾向于选择 reward 更高的客户。版本驱动策略用于平衡分支模型之间的版本差异。将较低版本的分支模型分派给高效的客户端(即,较少的训练时间),反之亦然。由于每个客户端的性能参数不可用,因此
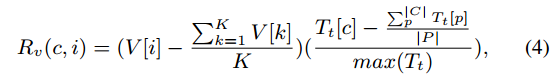
推测版本低,

为负数,且差值大,Tt[c]小,客户端高效,
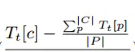
值为负数,且差值大,实现将较低版本的分支模型分派给高效的客户端,继而实现平衡分支模型之间的版本差异
分支模型 𝑖 的版本 𝑉[𝑖] 与所有分支模型平均版本的差值。这个差值反映了模型 𝑖 相对于其他模型在版本更新上的滞后或先进程度
表示客户端 𝑐 的平均训练时间与所有客户端平均训练时间的差值
max(Tt) 是所有客户端平均训练时间的最大值,用于归一化这个差值
为确保客户选择的充分性,将好奇心驱动探索作为评估奖励的策略之一,选择次数较少的客户将获得更高的好奇心奖励。GitFL使用计数表Tc记录每个客户端的选择次数,并使用基于模型的间隔估计与探索奖金(MBIE-EB)测量客户端的好奇心奖励c,如下所示:
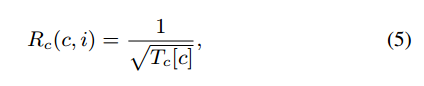
其中Tc[c]表示选择c的次数,注意Tc[c]的初始值为1。每个客户的奖励由Rv和Rc结合来衡量如下:
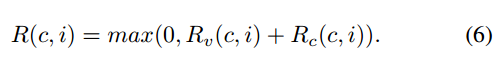
如果模型版本与平均版本差异较大,则奖励主要由版本奖励决定。如果模型版本接近平均版本,则奖励主要由好奇心奖励决定。注意,奖励的最小值是0。如果客户的奖励等于0,则该客户将不被选中。否则,根据上述奖励定义,客户端选择器选择一个客户端进行模型调度,其概率定义为:
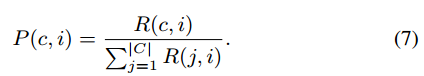
获得更高奖励的客户被选中的概率就会更高。客户选择策略是根据概率选择客户,而不是直接选择报酬最高的客户。避免偏袒具有极高或极低计算能力的个人客户,这可能导致他们垄断训练过程通过采用概率选择机制,云服务器鼓励所有客户端积极参与培训过程,防止任何一小部分客户端主导整个FL培训
5. 效果:主要关注精度和时间
5.1. 精度
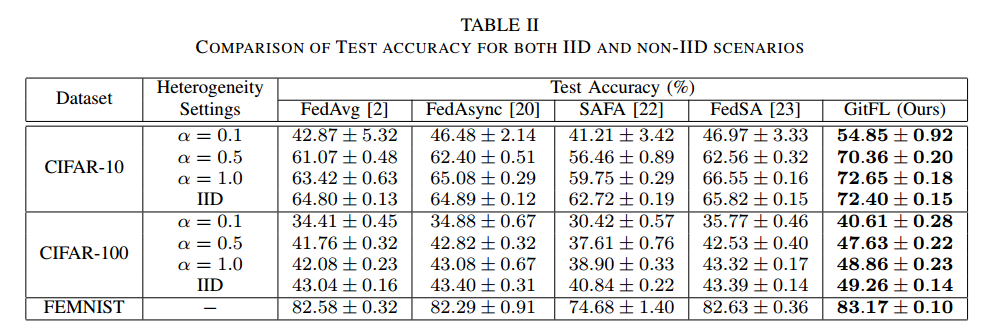
GitFL与所有基线相比取得了最好的性能

给定一个具体的合理时间期限,GitFL可以达到最佳的精度。即使在α = 0.1的极端非iid场景下,GitFL的学习曲线也比其他所有基线的学习曲线更稳定
5.2. 训练时间和通信开销
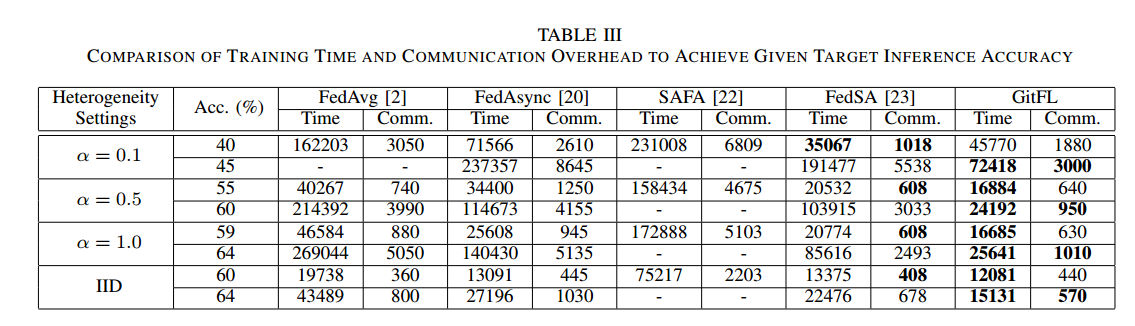
比较GitFL和所有基线之间的训练时间和通信开销
当精度目标变得更高时,GitFL比其他基线使用更少的训练时间和通信开销
5.3. 不同配置的影响
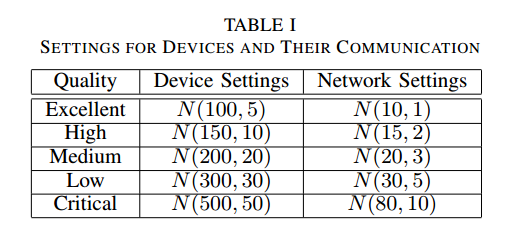
考虑不同的设备组成配置、不同的同时训练的客户端数量、不同的总客户端数量、不同类型的底层AI模型和不同的AI任务
- 不同的设备组成配置

图4给出四种设备组成配置的学习曲线,在IID分布的数据集CIFAR-10上应用了GitFL(带有ResNet18模型)。GitFL在四种设备配置(table IV)中都实现了最高的推理性能。在 non-iid 场景中也可观察到类似的学习曲线趋势。
所有FL方法在配置1下可以更快地达到最佳精度,而在配置3下则较慢。因为在配置1中,具有较强计算能力和网络通信能力的设备较多。配置2和配置4的所有异步FL方法(即FedAsync和GitFL)的收敛速度是相似的。对于同步FL方法(即FedAvg)和半异步FL方法(即FedSA和SAFA),在配置4下的收敛速度比配置1慢。因为同步FL方法的性能受到掉队者的严重限制,并且在配置4中,低性能的设备数量多于配置2。对于半异步FL方法,因为它们仍然需要等待一定数量的设备进行聚合,其性能也会受到低性能设备的影响。对于异步FL方法,其收敛性能主要受所有器件平均性能的影响。
- 不同的同时训练的客户端数量
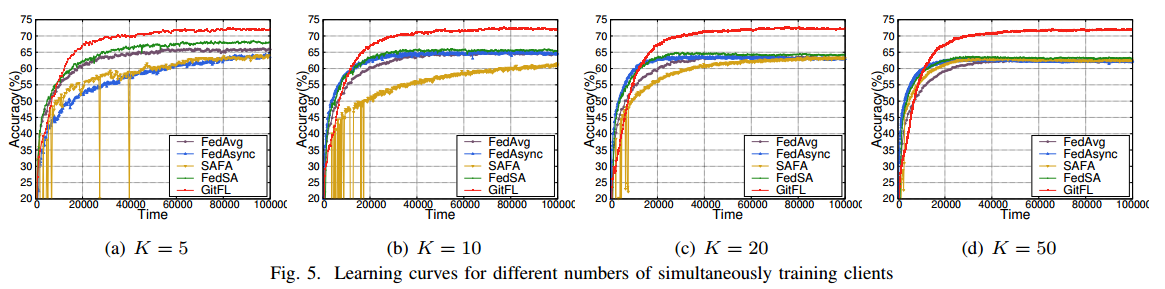
研究同时训练客户机数量对GitFL的影响,考虑四种不同的激活客户机设置(K不同),其中同时训练客户机的数量分别为5、10、20和50。图5显示了在CIFAR-10上使用ResNet-18进行IID分布的所有实验结果。
GitFL在所有设置下的精度都是最高的。
- 不同的总客户端数量(可扩展性)
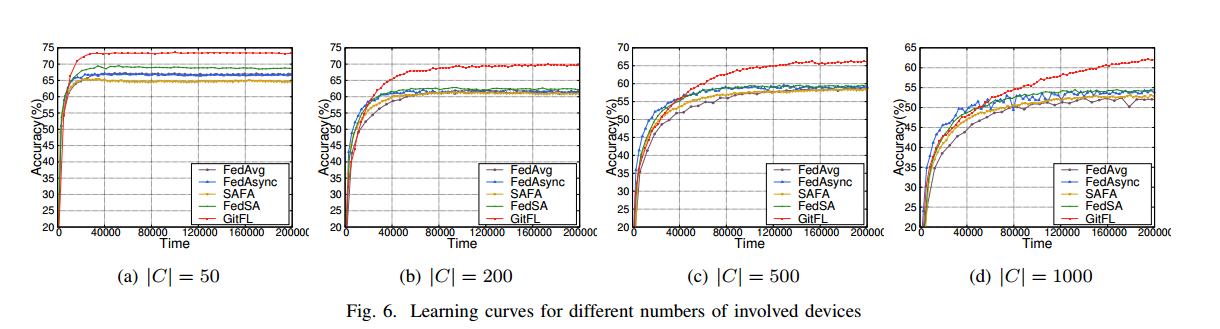
为评估GitFL的可扩展性(修改 |C| ),在CIFAR-10数据集上使用ResNet-18模型进行了四种不同设置的实验,分别为|C| = 50、200、500和1000。对于所有设置,选择10%的设备作为 IID 场景下同时进行本地训练的激活设备。图6 给出了GitFL的学习曲线以及涉及设备的四种设置下的所有基线。与所有基线相比,GitFL在所有涉及设备的设置下都能达到最佳的推理精度。
- 不同类型的底层AI模型
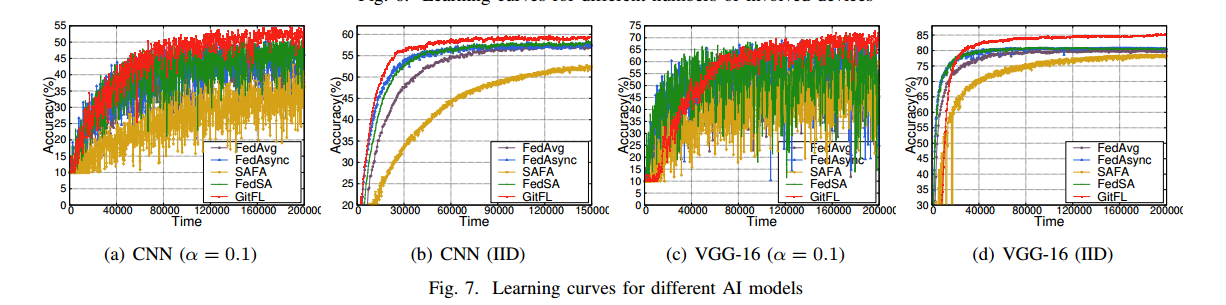
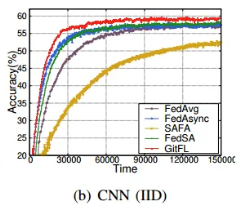
研究两种具有不同底层AI模型的GitFL变体,即CNN和VGG-16。图7显示了这两种变量对不同数据分布(即α = 0.1的非IID和IID)的影响。无论底层AI模型类型或数据分布如何,GitFL在所有情况下都达到了最高的准确率。
当使用CNN模型时,GitFL在整个训练过程中都能达到最好的准确率。在使用VGG-16模型时,GitFL在训练开始的早期不能实现最佳推理,但当所有基线都达到最佳精度时,可以实现更好的推理精度。这是因为CNN网络结构相对简单,训练时间相对较少,而VGG-16是一个连接密集的网络,需要更多的训练时间。对于基线,FedAsync和FedSA的收敛速度比fedag快,SAFA也是所有基线中表现最差的。
- 不同的AI任务
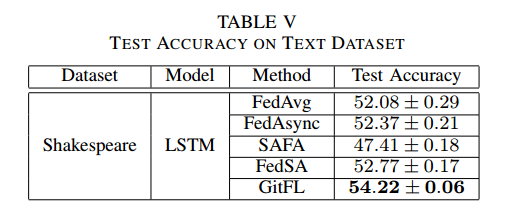
上面的实验都是针对图像进行的
另外在著名的文本数据集Shakespeare 上使用LSTM模型对所有五种FL方法进行了实验。表 V 给出所有五种FL方法的测试精度。GitFL达到了最好的推理精度。对于这四个基线,fedag、FedAsync和FedSA可以达到相似的测试精度,而SAFA表现最差。
5.4. 消融实验
证明基于rl的客户选择策略的有效性
开发三种GitFL变体:
- GitFL+R:以随机方式选择客户进行本地培训
- GitFL+C:仅根据好奇心奖励选择客户端
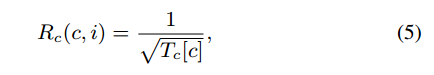
- GitFL+V:仅使用版本奖励选择客户端
- GitFL+CV: GitFL 完整版本
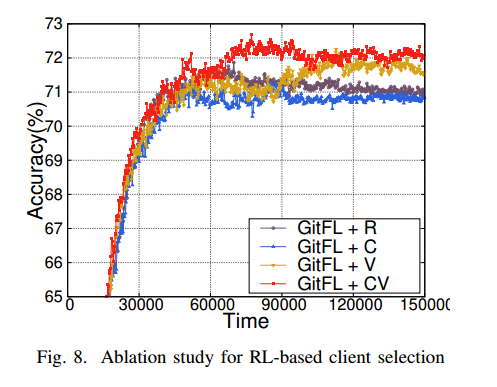
图8是基于IID分布的renet -18在CIFAR10数据集上的消融研究结果。
GitFL+CV 在四种设计中获得了最高的推理性能,
GitFL+V 优于GitFL+R,这证明了版本控制策略的有效性。
GitFL+C 对 GitFL+R 的改进可以忽略不计,如果没有模型过时信息,好奇心策略本身就不能使FL训练受益
5.5. 试验台

在图9中的真实测试平台中实现GitFL和所有四个基线
真是测试平台的配置:
- 六块带有ARM四核A72 CPU的Raspberry Pi 4B板和一个Broadcom VideoCore VI GPU;
- 五块带有四核ARM A57 CPU的Jetson Nano板,128核NVIDIA Maxwell GPU和4GB LPDDR4 RAM;
- 位于带有Intel i9 CPU的Ubuntu工作站之上的云服务器。
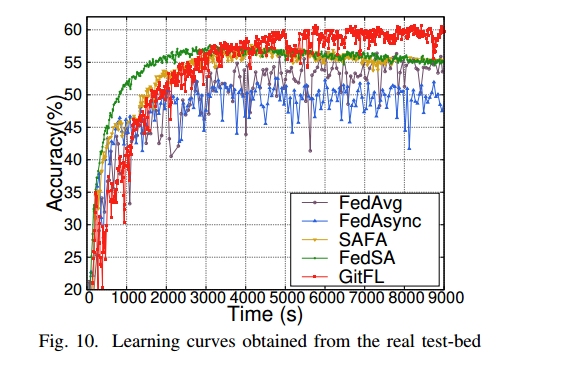
使用带有IID场景的CNN模型在CIFAR-10数据集上进行实验,假设同时有四个设备被激活用于局部训练。
图10展示了从真实测试平台上获得的所有五种FL方法的学习曲线。与所有基线相比,GitFL可以达到最好的推理精度。对于基线,FedSA和SAFA在推理精度上表现良好,而FedAsync的性能最差。与图7(b)中的对应项相比,图10中的FedAsync和fedag在实际测试台上的性能更差,尽管SAFA可以获得更好的性能。
GitFL 和 FedSA 在这两种情况下都表现良好。
6. (备选)自己的思考
- 异步FL中模型陈旧的问题:
- 模型聚合机制
- 设备选择策略
- 掉队者 和 模型陈旧属于两种问题
- 掉队者针对同步FL:由于参与的设备在计算能力、网络条件等方面存在差异,导致一部分设备(掉队者)完成本地训练和上传模型的速度远低于其他设备,导致整体训练效率降低,增加了等待时间和通信延迟
- 模型陈旧针对异步FL:在异步联邦学习中,由于模型更新不是实时进行的,某些设备可能还在使用已经过时的全局模型进行本地训练。

















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











