






LapDepth深度估计模型
代码链接:LapDepth-study
论文链接:Monocular Depth Estimation Using Laplacian Pyramid-Based Depth Residuals
官方链接:LapDepth-release
看一下效果

总体流程
这里简单说一下流程,详细步骤在代码部分说。
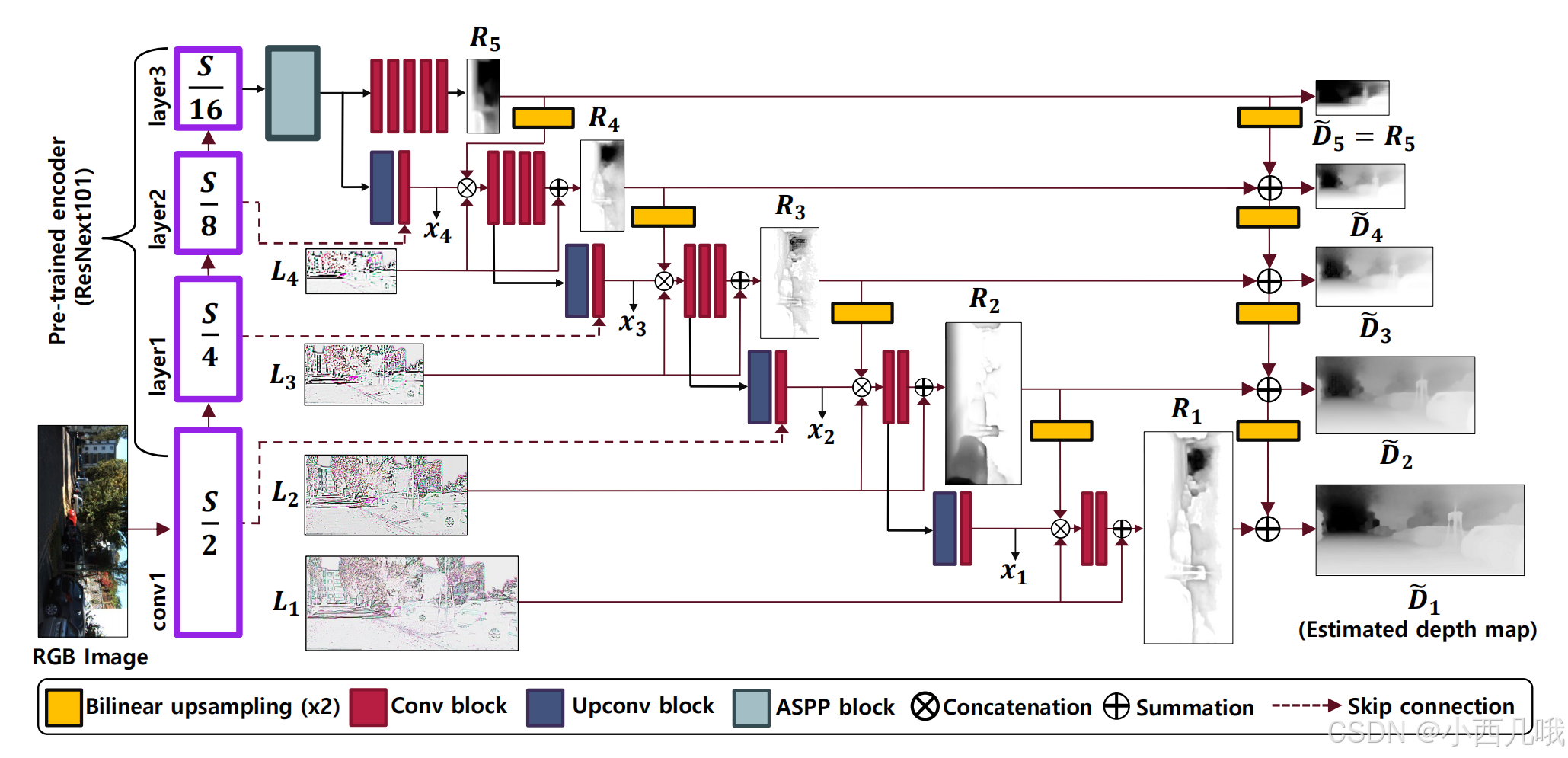
现在基本什么模型第一步都是提特征,那你用什么backbone无所谓了,大多数都是ResNet(这么多年了依旧屹立不倒)。前面四个紫色的框就是backbone提取的四层特征,大小分别是原图的1/2、1/4、1/8、1/16。
你们看L1、L2、L3、L4,看上去是不是很缭乱,那个是图像的一个轮廓,是不是很像opencv里面的cv2.findContours。它这个是怎么做的呢,先对图像进行下采样4次,然后再上采样四次,最后用每次size一样的下采样的图减去上采样的图。因为上采样下采样这不是一个可逆过程,下采样是通过计算平均值代替,上采样通过插值的方法还原回去,所以在主体部分他们还是大差不差的,但是在轮廓那边不可能计算的一模一样,这么一减不就是轮廓了嘛(大智慧)。
开始做后面特征提取时,先走最上面一层,对最小的那张特征图下手。首先,对它做一个ASPP,ASPP是空洞卷积和SPP的结合。空洞卷积应该都知道吧,也叫膨胀卷积,这个太基础了不说。SPP是干啥的呢?我们提取特征的时候希望什么,希望特征越多越好,最好再来点多样性。那如何从不同的角度去评估特征呢?我们对输入的特征图做不同尺度的pooling。比如对一张输入的特征图,我不管它size是如何,我给它pooling成一个4×4的,一个2×2的,一个1的。那如果输入是256张特征图,结果就是4×4×256、2×2×256和1×256,然后再给它们拼接在一起。SPP的优势很明显吧,输入size不需要固定(不会因为reszie而丢失信息),但能得到固定size的特征。当然,这只是正常SPP的一个思路,代码里的和这个不一样,不是直接pooling,但是思路是差不多的。
红色的就是卷积,做完ASPP后面紧接着做了5个卷积得到了R5,此时的R5就是输出的D5。但是我们最终的输出是D1,原图的大小,所以我们必须一步一步上采样融合。
先还是看左半边,首先我们对R5做了一个上采样,对之前ASPP的结果也做一个上采样(橙黄色和深蓝色虽然都是上采样,不过方法不同,我一会在代码详说)。注意后面做的这个卷积拼接了layer2的特征图,因为上采样过了嘛,这时它们的size一样大。OK,现在我们三条支路归一,将我们之前求的轮廓L4,R5的上采样和刚融合了layer2的特征图拼接在一起,做卷积。卷积完之后是我们的一个加法操作,将L4老顾客再邀请一下。不过这里有个注意的点,R4看到没,黑白的,单通道图像数据,而L4,彩色的,三通道数据。所以我们需要先将L4的RBG算个平均值代替,然后以0.1微弱的权重加入进去。OK,我们的R4大功告成。
在计算D4的时候,我们不仅需要R4的信息,看到上面那个箭头没,还需要D5的。D5做个上采样下来,然后和R4一加,OK,我们的D4也大功告成。
下面的步骤和上面的大差不差就不一一叙述了,最终呢,我们得到最终的图像D1。
特点
这篇论文里还提了很多不同寻常的点,我们来看看。
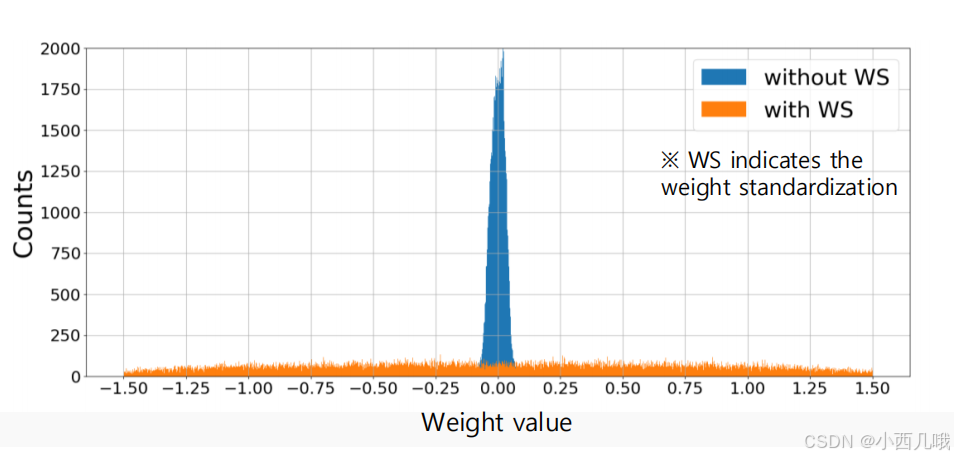
我们现在很多模型都已经默认了一种方法,就是卷积之后再BN一下,但是这篇论文不仅对数据标准化,还对权重标准化WS了一下。上图可以看到一点,没标准化的权重基本都在0附近,标准化后的就分散了很多。未标准化的权重会导致 ReLU 输出过多零值(负值就被干掉了),增加神经元“死亡”风险,而WS可以有效减少死亡神经元现象。不知道是不是我孤陋寡闻了,我没怎么见过这种操作,但是它在论文里表现的效果却出奇的好,如下图。
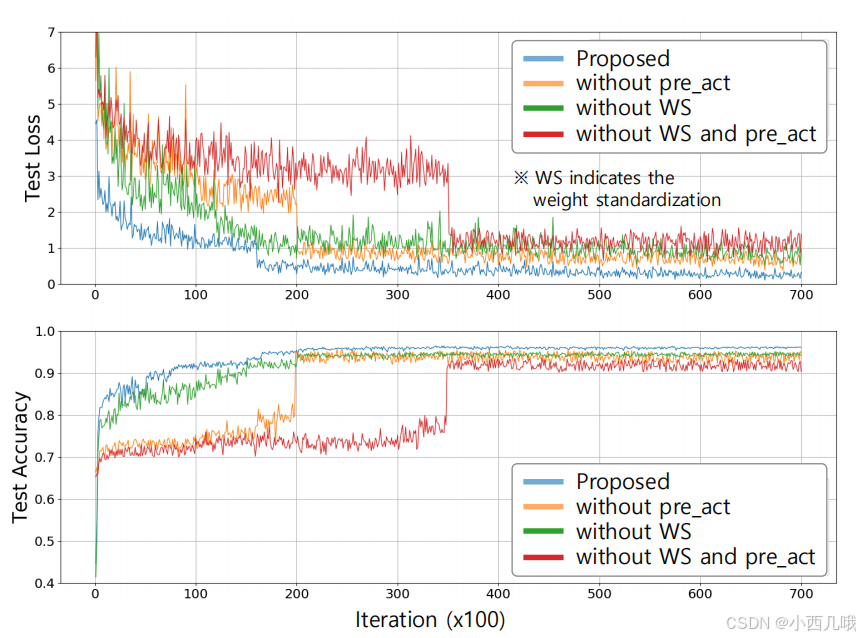
上图里面还有一个pre_act,这也是论文里一个奇怪的点。我们通常说的卷积,正常流水就是Conv->BN->Relu,但这里是BN->Relu->Conv。我的天,这也是我孤陋寡闻吗?我也没见过这种的,但是从上图看来效果还很好。最终模型用的是下图的c,中间还插了个WS。大家如果有兴趣可以试试这种方式应用到自己模型里,看看效果会不会提升。
代码
数据处理
数据的处理在datasets_list.py里。处理的非常简单,因为原图和标签直接读取路径就好了,没啥需要操作的。然后再简单的修修边,简单的数据增强。
if self.args.dataset == 'KITTI': # 将图片的边缘裁剪掉,使其能整除16
h = rgb.height
w = rgb.width
bound_left = (w - 1216) // 2
bound_right = bound_left + 1216
bound_top = h - 352
bound_bottom = bound_top + 352
elif self.args.dataset == 'NYU':
if self.train is True:
bound_left = 43
bound_right = 608
bound_top = 45
bound_bottom = 472
else:
bound_left = 0
bound_right = 640
bound_top = 0
bound_bottom = 480
if self.args.dataset == 'NYU' and (self.train is False) and (self.return_filename is False):
rgb = rgb.crop((40, 42, 616, 474))
else:
rgb = rgb.crop((bound_left, bound_top, bound_right, bound_bottom))ound_bottom = 480
用backbone对数据提取特征,每提取一次特征图片的大小就减半,最后得到原图1/16大小的特征图。那么在做之前肯定得确定数据能够整除16啊,所以我们对图片修边,使其能整除16。当然原图修边了,标签图gt也要修。
数据增强部分太简单了我就不说了,主要就是做个标准化吧,别的没啥了。
LDRN
我们跳到model.py的LDRN中。
class LDRN(nn.Module):
def __init__(self, args):
super(LDRN, self).__init__()
lv6 = args.lv6
encoder = args.encoder
if encoder == 'ResNext101':
self.encoder = deepFeatureExtractor_ResNext101(args, lv6)
elif encoder == 'VGG19':
self.encoder = deepFeatureExtractor_VGG19(args, lv6)
elif encoder == 'DenseNet161':
self.encoder = deepFeatureExtractor_DenseNet161(args, lv6)
elif encoder == 'InceptionV3':
self.encoder = deepFeatureExtractor_InceptionV3(args, lv6)
elif encoder == 'MobileNetV2':
self.encoder = deepFeatureExtractor_MobileNetV2(args)
elif encoder == 'ResNet101':
self.encoder = deepFeatureExtractor_ResNet101(args, lv6)
elif 'EfficientNet' in args.encoder:
self.encoder = deepFeatureExtractor_EfficientNet(args, encoder, lv6)
if lv6 is True:
self.decoder = Lap_decoder_lv6(args, self.encoder.dimList)
else:
self.decoder = Lap_decoder_lv5(args, self.encoder.dimList)
def forward(self, x):
out_featList = self.encoder(x)
rgb_down2 = F.interpolate(x, scale_factor=0.5, mode='bilinear') # 做4次下采样
rgb_down4 = F.interpolate(rgb_down2, scale_factor=0.5, mode='bilinear') # scale_factor=0.5 变成原来的一半
rgb_down8 = F.interpolate(rgb_down4, scale_factor=0.5, mode='bilinear')
rgb_down16 = F.interpolate(rgb_down8, scale_factor=0.5, mode='bilinear')
rgb_down32 = F.interpolate(rgb_down16, scale_factor=0.5, mode='bilinear')
rgb_up16 = F.interpolate(rgb_down32, rgb_down16.shape[2:], mode='bilinear') # 做4次上采样
rgb_up8 = F.interpolate(rgb_down16, rgb_down8.shape[2:], mode='bilinear') # rgb_down8.shape[2:] 变成rgb_down8维度
rgb_up4 = F.interpolate(rgb_down8, rgb_down4.shape[2:], mode='bilinear')
rgb_up2 = F.interpolate(rgb_down4, rgb_down2.shape[2:], mode='bilinear')
rgb_up = F.interpolate(rgb_down2, x.shape[2:], mode='bilinear')
lap1 = x - rgb_up # 作差 得到轮廓信息
lap2 = rgb_down2 - rgb_up2
lap3 = rgb_down4 - rgb_up4
lap4 = rgb_down8 - rgb_up8
lap5 = rgb_down16 - rgb_up16
rgb_list = [rgb_down32, lap5, lap4, lap3, lap2, lap1]
d_res_list, depth = self.decoder(out_featList, rgb_list)
return d_res_list, depth
forward开头的self.encoder(x)就是一个backbone提取特征的过程,直接调用的没啥好说的,你看代码里提供了ResNext101、VGG19、DenseNet161、InceptionV3、MobileNetV2、ResNet101、EfficientNet这些,如果你想用别的backbone来提取特征也行,没有什么硬性要求。最后得到的out_featList包含了输出的四层特征图,大小分别是原图的1/2、1/4、1/8、1/16。
下面还要再准备一下图片的轮廓信息。我们通过F.interpolate()做了上采样和下采样,mode的话有很多种可以自己选。不同的就是scale_factor的方式。下采样的时候直接scale_factor=0.5,即变为原来的一半。上采样的时候,比如赋值rgb_down16.shape[2:],即上采样为rgb_down16的size。最后我们通过相同size作差得到轮廓信息rgb_list。
这都是一些准备工作,下面进入正题self.decoder(out_featList, rgb_list)部分。
Lap_decoder_lv5
我们跳到model.py的Lap_decoder_lv5的forward中。这里展示的不是全部的,先把ASPP讲完了再展示下面的。
def forward(self, x, rgb):
cat1, cat2, cat3, dense_feat = x[0], x[1], x[2], x[3] # backbone得到的四个特征图
rgb_lv6, rgb_lv5, rgb_lv4, rgb_lv3, rgb_lv2, rgb_lv1 = rgb[0], rgb[1], rgb[2], rgb[3], rgb[4], rgb[5] # 轮廓特征
dense_feat = self.ASPP(dense_feat) # Dense feature for lev 5 (B, 512, H/16, W/16)
我们先将刚刚backbone提取的特征图和轮廓图排排队,然后拿出最小的那个特征图做ASPP。
ASPP
def forward(self, x): # (B, C, h, w) 有空洞卷积的SPP
x = self.reduction1(x) # (B, C/2, h, w) 对权重标准化 然后再做个卷积
d3 = self.aspp_d3(x) # (B, C/4, h, w) BN->ReLU->WS->conv
cat1 = torch.cat([x, d3], dim=1) # (B, 3C/4, h, w)
d6 = self.aspp_d6(cat1) # (B, C/4, h, w)
cat2 = torch.cat([cat1, d6], dim=1) # (B, C, h, w)
d12 = self.aspp_d12(cat2) # (B, C/4, h, w)
cat3 = torch.cat([cat2, d12], dim=1) # (B, 5C/4, h, w)
d18 = self.aspp_d18(cat3) # (B, C/4, h, w)
out = self.reduction2(torch.cat([x, d3, d6, d12, d18], dim=1)) # (B, C/2, h, w)
return out # 512 x H/16 x W/16
你可以把它理解为ASPP的变种。self.reduction1会先对权重进行一个标准化,然后再进行卷积,将输入的size变为原来的一半。self.aspp_d3、self.aspp_d6、self.aspp_d12、self.aspp_d18通过多个不同膨胀率(3,6,12,18)的空洞卷积模块,逐层堆叠提取多尺度特征。注意这里的卷积顺序都是BN->ReLU->WS->Conv。每一层会将当前特征与前一层的特征拼接,以融合更多上下文信息。最后一层self.reduction1使用一个 3x3 卷积将拼接后的特征通道数还原为输入的一半,形成最终输出。
=======================================================================================================
好,我们回到Lap_decoder_lv5。
# decoder 1 - Pyramid level 5
lap_lv5 = torch.sigmoid(self.decoder1(dense_feat)) # decoder1做五个卷积 R5(B, 1, H/16, W/16)
lap_lv5_up = self.upscale(lap_lv5, scale_factor=2, mode='bilinear') # R5上采样 (B, 1, H/8, W/8)
# decoder 2 - Pyramid level 4
dec2 = self.decoder2_up1(dense_feat) # ASPP结果上采样 (B, 256, H/8, W/8)
dec2 = self.decoder2_reduc1(torch.cat([dec2, cat3], dim=1)) # 和layer2做了个拼接 (B, 252, H/8, W/8)
dec2_up = self.decoder2_1(torch.cat([dec2, lap_lv5_up, rgb_lv4], dim=1)) # 与R5上采样结果和L4做个拼接 (B, 256, H/8, W/8)
dec2 = self.decoder2_2(dec2_up)
dec2 = self.decoder2_3(dec2)
lap_lv4 = torch.tanh(
self.decoder2_4(dec2) + (0.1 * rgb_lv4.mean(dim=1, keepdim=True))) # 将L4转为1通道拼接 R4(B, 1, H/8, W/8)
# if depth range is (0,1), laplacian of image range is (-1,1)
lap_lv4_up = self.upscale(lap_lv4, scale_factor=2, mode='bilinear')
# decoder 2 - Pyramid level 3
dec3 = self.decoder2_1_up2(dec2_up)
dec3 = self.decoder2_1_reduc2(torch.cat([dec3, cat2], dim=1))
dec3_up = self.decoder2_1_1(torch.cat([dec3, lap_lv4_up, rgb_lv3], dim=1))
dec3 = self.decoder2_1_2(dec3_up)
lap_lv3 = torch.tanh(self.decoder2_1_3(dec3) + (0.1 * rgb_lv3.mean(dim=1, keepdim=True)))
# if depth range is (0,1), laplacian of image range is (-1,1)
lap_lv3_up = self.upscale(lap_lv3, scale_factor=2, mode='bilinear')
# decoder 2 - Pyramid level 2
dec4 = self.decoder2_1_1_up3(dec3_up)
dec4 = self.decoder2_1_1_reduc3(torch.cat([dec4, cat1], dim=1))
dec4_up = self.decoder2_1_1_1(torch.cat([dec4, lap_lv3_up, rgb_lv2], dim=1))
lap_lv2 = torch.tanh(self.decoder2_1_1_2(dec4_up) + (0.1 * rgb_lv2.mean(dim=1, keepdim=True)))
# if depth range is (0,1), laplacian of image range is (-1,1)
lap_lv2_up = self.upscale(lap_lv2, scale_factor=2, mode='bilinear')
# decoder 2 - Pyramid level 1
dec5 = self.decoder2_1_1_1_up4(dec4_up)
dec5 = self.decoder2_1_1_1_1(torch.cat([dec5, lap_lv2_up, rgb_lv1], dim=1))
dec5 = self.decoder2_1_1_1_2(dec5)
lap_lv1 = torch.tanh(self.decoder2_1_1_1_3(dec5) + (0.1 * rgb_lv1.mean(dim=1, keepdim=True)))
# if depth range is (0,1), laplacian of image range is (-1,1)
# Laplacian restoration
lap_lv4_img = lap_lv4 + lap_lv5_up # D4 = R4 + D5上采样 (B, 1, H/8, W/8)
lap_lv3_img = lap_lv3 + self.upscale(lap_lv4_img, scale_factor=2, mode='bilinear') # D3=R3+D4上采样 (B,1,H/4,W/4)
lap_lv2_img = lap_lv2 + self.upscale(lap_lv3_img, scale_factor=2, mode='bilinear') # D2=R2+D3上采样 (B,1,H/2,W/2)
final_depth = lap_lv1 + self.upscale(lap_lv2_img, scale_factor=2, mode='bilinear') # D1=R1+D2上采样 (B,1,H,W)
final_depth = torch.sigmoid(final_depth)
return [lap_lv5 * self.max_depth, lap_lv4 * self.max_depth, lap_lv3 * self.max_depth,
lap_lv2 * self.max_depth, lap_lv1 * self.max_depth], final_depth * self.max_depth
这里的代码简直可以直接对照着那个总流程图看,一模一样。
对刚刚ASPP输出结果,上来先干五个卷积self.decoder1,最后输出的是一个图像R5,而D5就是R5,直接一石二鸟。
现在我们准备进攻D4,需要三条支路,我们一一规划。这里先用self.upscale对R5做了一个上采样,这个和之前的F.interpolate是一个东西,一条支路完成。对ASPP的结果做一个上采样,这里的上采样其实用的也是F.interpolate,但是多了几步,它的流程是BN->Relu->F.interpolate->WS->Conv。这到底是卷积里夹了个上采样,还是上采样完再做了个卷积,不管了。将之前backbone提取的特征图老二拿过来拼接一下做卷积,OK,第二条支路完成。第三条支路,老早就搁着等着我们了,就是之前的轮廓图L4。桃园结义了属实,三兄弟相聚直接合体然后做个卷积。下面的两步都是卷积,OK,出现变体,看看怎么个事。我们看到第四次做完卷积的时候加上0.1 * rgb_lv4.mean(dim=1, keepdim=True),这不就是我之前说的,老顾客L4做了个平均变为单通道,然后以微弱的0.1权重加入(果然改变自己去迎合别人的结果就是没啥地位)。那么R4大功告成,R4都有了,D4还远吗?和之前那个上采样的R5一加,OK,D4大功告成。
下面的步骤和上面的差不多,你们可以再一步一步debug看看,巩固巩固,我就不多说了。
LOSS
转到utils.py的scale_invariant_loss中。
def scale_invariant_loss(valid_out, valid_gt):
logdiff = torch.log(valid_out) - torch.log(valid_gt)
scale_inv_loss = torch.sqrt((logdiff ** 2).mean() - 0.85 * (logdiff.mean() ** 2)) * 10.0
return scale_inv_loss
这里可以看到loss的计算非常简单,两行代码。但是理解起来有点难度,后面基本所有的深度估计模型都用的这个方式计算loss的,出自Depth Map Prediction from a Single Image using a Multi-Scale Deep Network,我们来看看它究竟有什么魅力。
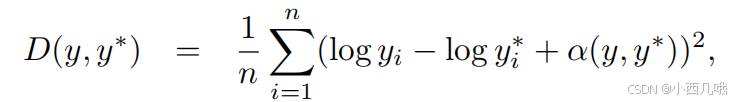
y∗是目标值。前面的公式很好理解,就是正常的预测值与目标值的差异,后面的α(y,y∗ )是啥意思呢?
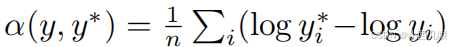
重新带入回公式。
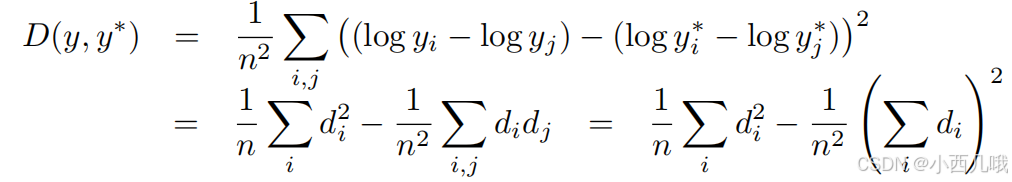
我根据自己的理解解释一下哈。
如果所有的预测值与目标值基本一样,只有一个预测值脱离群体,与目标值相差很多,那还不得惩罚死它。但如果所有的预测值都比目标值低了一点,或者都高了一点,好了,法不责众。
公式里的yi和yj表示两个点,它们两个点的预测值的差异最好和目标值的差异差不多,都预测大一点或者都预测小一点就给抵消掉了。但是如果一个预测的大了点,一个预测小了点,那就完蛋喽。你看公式里的di和dj分别表示预测值的差异和目标值的差异,负负得正,正正得正,减去这个正数loss就小了点。但是如果你一正一负,减去这个负数,你的loss就变大了。
在深度估计这个模型里,要么你都预测深了,要么你都预测浅了,但是你不能预测一深一浅,过多的不连续预测会导致深度图看起来不自然。
demo
demo.py里面只需要将model_dir改为自己.pkl所在的位置就行。对了,如果你是分布式的话代码里面有些地方需要改,我有注释。如果你有两个GPU,就将gpu_num改为“0,1”,以此类推。
=======================================================================================================
前两天出了个小车祸,也就我年轻耐摔了,给我撞飞了但好在人没事。本人守法公民,对方全责,但是对方态度也太恶劣了,给我气的不想撤案,纠葛了两天,最后还是跟我道歉了。最严重的就是,导致我两天没咋学习,更新慢了点。

















 1872
1872

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









