






Swin Transformer
论文链接:Swin Transformer: Hierarchical Vision Transformer using Shifted Windows
官方链接:Swin-Transformer
代码补充:Swin-Replenishment(因为官方给的代码我在win下单gpu运行会报错,所以我修改了一些代码使其能够运行)
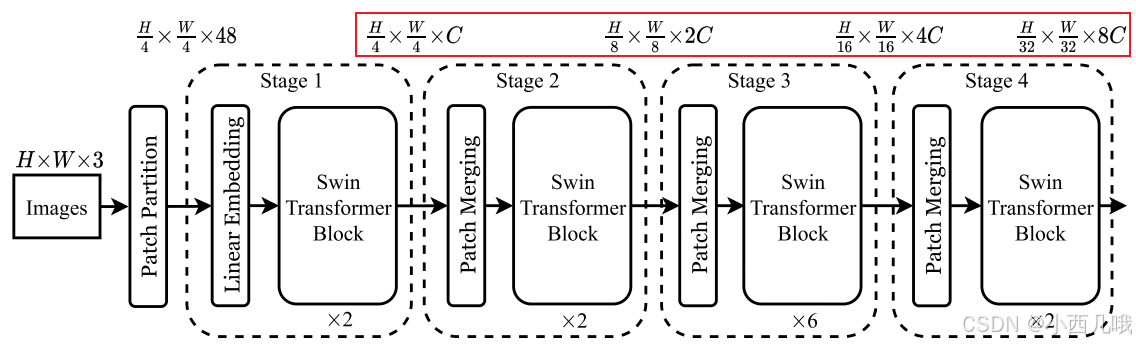
总体流程
在深度学习的视觉任务中,都会先经过backbone提取图片的特征。优秀的backbone可以事半功倍。我学习过很多模型,它们用的backbone大部分都是ResNet(经典永不过时)。近几年也演化了一些新的backbone,比如EfficientNet(之前讲过,计算量较低且效果好)、VIT(之前讲过,基于Transformer的,不过计算量很大,后续有很多优化版本),而今天介绍的是Swin Transformer (据说效果吊打)。
在VIT中,会图像分割成固定大小的 Patch然后排成一个序列,然后通过计算全局自注意力,计算量巨大,遇到高分辨率图像直接跪下。其次,VIT采用固定的patch,因此无法适应多尺度特征。
Swin Transformer灵机一动,通过分层特征提取 和窗口自注意力机制 解决这些问题。分层特征提取如下图,在初始阶段将图片划分为很小的patch,然后逐步合并patch(相邻 Patch 合并,形成更大的感受野)。这样可以逐步降低分辨率,提取高层语义信息,同时减少计算量。
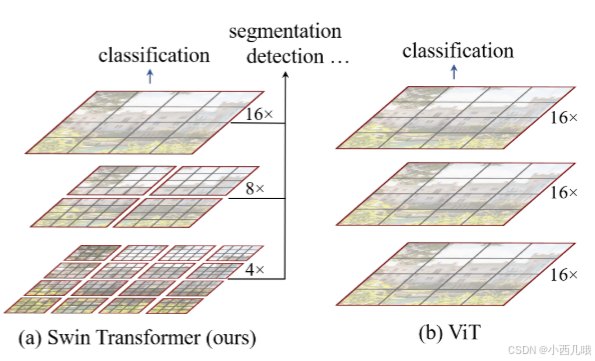
窗口自注意力机制 主要在Swin Transformer中,流程图如下,由Patch Embedding 、Swin Transformer Block 和 Patch Merging 组成。

Patch Embedding就是VIT里的核心步骤,将图片划分为固定大小的patch,然后通过一个卷积将每个 Patch 映射到固定维度的特征向量。假设输入的图像数据为(224,224,3),通过一个卷积Conv2d(3,96,kernel_size(4,4),stride=(4,4))映射到一个序列(3136,96)。(注:96 是一个经验值,3136=224÷4×224÷4,kernel_size=patch_size,确保每个 Patch 的信息被映射到一个嵌入向量中,stride=patch_size,确保不重叠分割。)
Swin Transformer Block 是Swin Transformer里的核心步骤,如下图,它由W-MSA 和SW_MSA 组成。W表示窗口、SW表示滑动窗口。
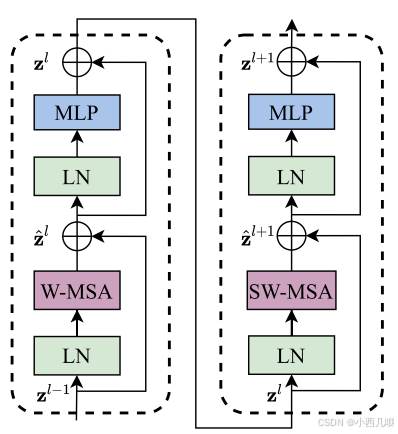
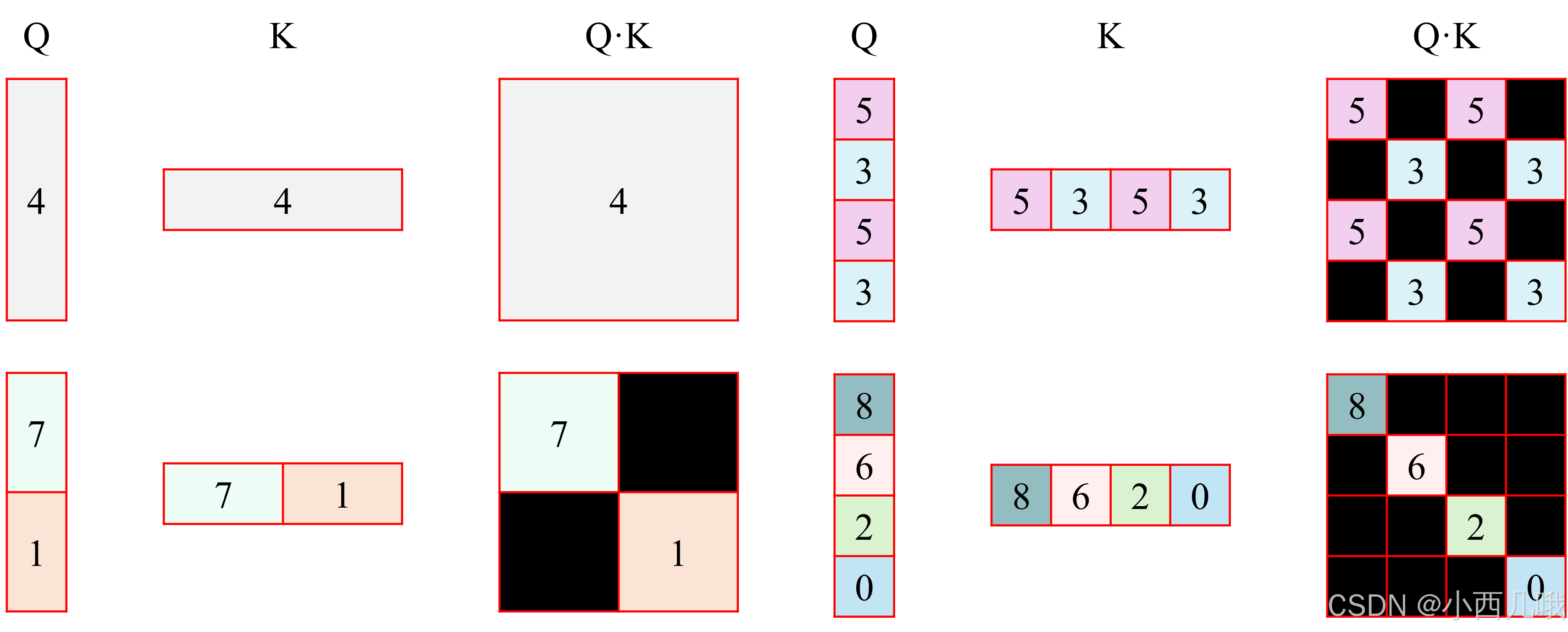
首先对输入的特征图分成窗口,比如输入特征图(56,56,96),窗口size为7,那么可以分成8×8个窗口,输出(64,7,7,96)。得到窗口后,计算每个窗口的注意力得分,那么就见到我们的老朋友qkv了。就是老规矩,先q@k,然后加上位置编码再@v,代码里详说,最终得到每个窗口的注意力得分。
这边就已经过完了W-MSA ,但是这个过程吧,窗口自己跟自己玩,不同窗口之间的一个关系没有体现出来。
问题:不同窗口之间的 token 无法直接通信,这限制了全局信息传播
| A A A | B B B | C C C |
| A A A | B B B | C C C |
| A A A | B B B | C C C |
因此作者后面又接了一个SW-MSA ,滑动窗口。让B参与A的窗口,C参与B的窗口,A参与C的窗口。但是这也有个问题啊,A和C之间并不是一个连续的位置关系。
问题:如果直接计算自注意力,模型可能会错误地学习跨窗口不连续的位置关系。
| A A B | B B C | C C A |
| A A B | B B C | C C A |
| A A B | B B C | C C A |
SW-MSA的流程如下图,本来四块窗口的通过滑动后被划分为了九个窗口。
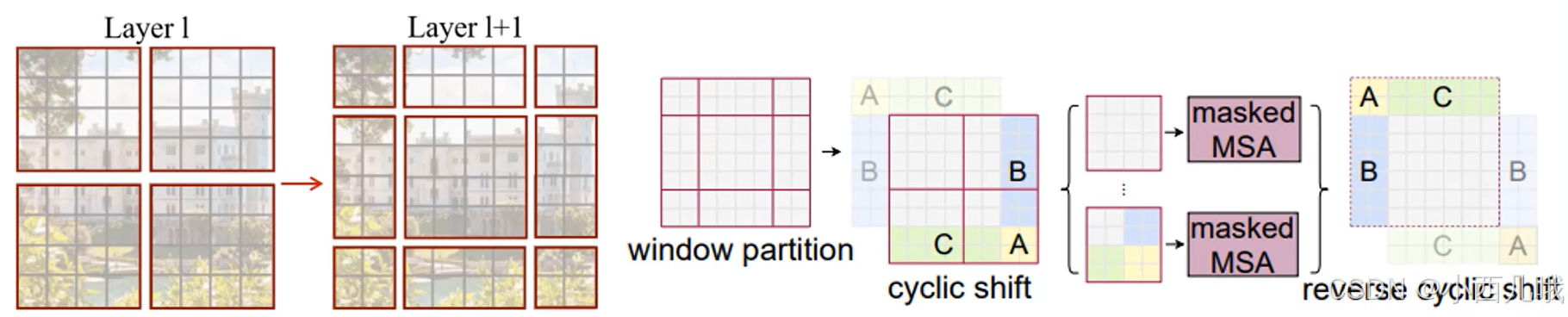
图片位移后的结果如下。
计算时仍然按4个窗口计算,但是很显然除了左上那个4,其它三个窗口都存在不连续的位置关系。怎么办?那就不计算那些不连续的数据呗,用一个mask矩阵屏蔽原始窗口间的无效连接,如下图。
OK,Swin Transformer Block 部分结束 ,接下来进行Patch Merging 。Patch Merging就是进行一个下采样,而且画个图就能理解,过程非常简单,如下图。

对H和W维度进行建个采样后拼接在一起,每次操作后H和W减一半,C多一倍,如下图红色框。
代码
官网有很多例子可以用,如下图,学习的话可以选第一个图像分类任务做一下。
代码不讲基础的部分,直接进入models/swin_transformer.py讲网络模块。配置一下参数进入debug,configs下有很多网络配置,选一个自己喜欢的。–local_rank 0表示用单gpu,不过设不设置都无所谓,因为官方代码就不支持win单GPU运行,得自己改点代码才行。–data-path是自己数据的路径。
--cfg configs/swin/swin_tiny_patch4_window7_224.yaml
--batch-size 16
--local_rank 0
--data-path imagenet
SwinTransformer
首先呢,debug到SwinTransformer的forward_features方法。
def forward_features(self, x): # (b,3,224,224)
x = self.patch_embed(x) # (b,3136,96)
if self.ape:
x = x + self.absolute_pos_embed
x = self.pos_drop(x)
for layer in self.layers:
x = layer(x)
x = self.norm(x) # B L C (b,49,768)
x = self.avgpool(x.transpose(1, 2)) # B C 1 (b,768,1)
x = torch.flatten(x, 1) # (b,768)
return x
self.patch_embed没啥好说的,就是一个卷积将图片数据分patch然后排成一排,输入(b,3,224,224)输出(b,3136,96)。(注:3136=224÷4×224÷4,通道维度3转为96)

主要是下面的for循环,将经历W-MSA和SW-MSA。我们跳入SwinTransformerBlock的forward方法中。
W-MSA
代码中if self.shift_size > 0后面接的就是SW-MSA,else接的是W-MSA。
def forward(self, x): # (b,3136,96)
H, W = self.input_resolution
B, L, C = x.shape
assert L == H * W, "input feature has wrong size"
shortcut = x
x = self.norm1(x)
x = x.view(B, H, W, C) # (b,56,56,96)
# cyclic shift
if self.shift_size > 0:
if not self.fused_window_process:
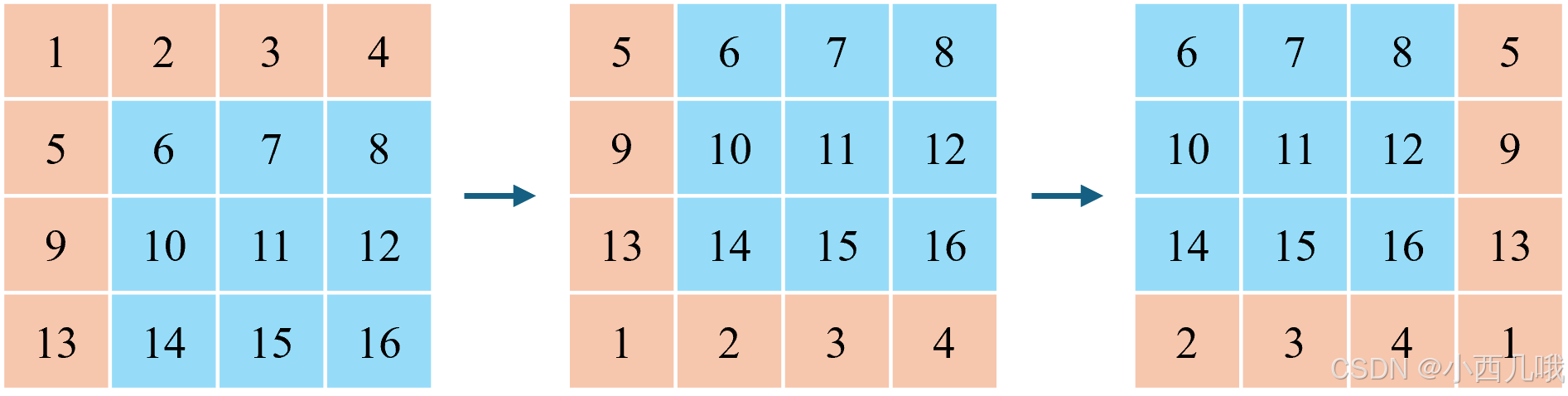
# [[ 1, 2, 3, 4], [[ 6, 7, 8, 5],
# [ 5, 6, 7, 8], ==> [10, 11, 12, 9],
# [ 9, 10, 11, 12], shift_size = 1 [14, 15, 16, 13],
# [13, 14, 15, 16]] [ 2, 3, 4, 1]]
shifted_x = torch.roll(x, shifts=(-self.shift_size, -self.shift_size), dims=(1, 2)) # 窗口滑动
# partition windows
x_windows = window_partition(shifted_x, self.window_size) # nW*B, window_size, window_size, C
else:
x_windows = WindowProcess.apply(x, B, H, W, C, -self.shift_size, self.window_size)
else:
shifted_x = x
# partition windows
x_windows = window_partition(shifted_x, self.window_size) # nW*B, w_s, w_s, C (64×b,7,7,96)
x_windows = x_windows.view(-1, self.window_size * self.window_size, C) # nW*B, w_s*w_s, C (64×b,49,96)
# W-MSA/SW-MSA
attn_windows = self.attn(x_windows, mask=self.attn_mask) # nW*B, w_s*w_s, C (64×b,49,96)
# merge windows
attn_windows = attn_windows.view(-1, self.window_size, self.window_size, C) # (64×b,7,7,96)
# reverse cyclic shift
if self.shift_size > 0:
if not self.fused_window_process:
shifted_x = window_reverse(attn_windows, self.window_size, H, W) # B H' W' C
x = torch.roll(shifted_x, shifts=(self.shift_size, self.shift_size), dims=(1, 2)) # 窗口还原
else:
x = WindowProcessReverse.apply(attn_windows, B, H, W, C, self.shift_size, self.window_size)
else:
shifted_x = window_reverse(attn_windows, self.window_size, H, W) # B H' W' C (b,56,56,96) 还原回去
x = shifted_x
x = x.view(B, H * W, C) # (b,3136,96)
x = shortcut + self.drop_path(x)
# FFN
x = x + self.drop_path(self.mlp(self.norm2(x)))
return x
输入的size为(b,3136,96),经过标准化后重新view为(b,56,56,96)。(注:56×56=3136)。第一步是W-MSA,所以先执行else后的代码,window_partition会将图像划分窗口,具体进入函数看一下。
window_partition
def window_partition(x, window_size):
B, H, W, C = x.shape
x = x.view(B, H // window_size, window_size, W // window_size, window_size, C) # (b,8,7,8,7,96)
windows = x.permute(0, 1, 3, 2, 4, 5).contiguous().view(-1, window_size, window_size, C) # (64×b,7,7,96)
return windows # 将原来56×56的窗口划分为为7×7的,然后排成一排
默认窗口size为7,现在输入的图像是56×56的,按7×7的窗口将划分8×8块窗口,最终输出(64×b,7,7,96)。
=======================================================================
回到SwinTransformerBlock的forward继续。
将刚刚划分好的窗口先重新view一下为(64×b,49,96),然后带入到self.attn计算注意力分数,我们进入attn方法中看一下怎么个事。
WindowAttention
进入WindowAttention的forward方法中。
def forward(self, x, mask=None):
B_, N, C = x.shape
qkv = self.qkv(x).reshape(B_, N, 3, self.num_heads, C // self.num_heads).permute(2, 0, 3, 1, 4) # (3,64×b,3,49,32)
q, k, v = qkv[0], qkv[1], qkv[2] # make torchscript happy (cannot use tensor as tuple)
q = q * self.scale # 缩放Q 防止点积结果过大,保持数值稳定
attn = (q @ k.transpose(-2, -1)) # k:(49,32)->(32,49) q·k->(49,49)
relative_position_bias = self.relative_position_bias_table[self.relative_position_index.view(-1)].view( # 位置编码
self.window_size[0] * self.window_size[1], self.window_size[0] * self.window_size[1], -1) # Wh*Ww,Wh*Ww,nH
relative_position_bias = relative_position_bias.permute(2, 0, 1).contiguous() # nH, Wh*Ww, Wh*Ww
attn = attn + relative_position_bias.unsqueeze(0) # (64×b,3,49,49)
if mask is not None:
nW = mask.shape[0]
attn = attn.view(B_ // nW, nW, self.num_heads, N, N) + mask.unsqueeze(1).unsqueeze(0)
attn = attn.view(-1, self.num_heads, N, N)
attn = self.softmax(attn)
else:
attn = self.softmax(attn)
attn = self.attn_drop(attn)
x = (attn @ v).transpose(1, 2).reshape(B_, N, C) # (b,3,49,49)·(b,3,49,32)->(b,3,49,32)->(b,49,3,32)->(b,49,96)
x = self.proj(x)
x = self.proj_drop(x)
return x
现在输入的维度为(64×b,49,96)。这里qkv矩阵是直接通过一个线性变换self.qkv得到,self.num_heads注意力头默认为3,得到输出(3,64×b,3,49,32)。(注:3为qkv三个矩阵,3为注意力头,49=7×7窗口大小,32=96÷3每个head特征)
然后分别通过qkv[0], qkv[1], qkv[2]取得qkv的矩阵。下面开始计算注意力分数。
self.scale是为了缩放q ,防止点积结果过大,保持数值稳定。然后与k点积,点积前将k转置一下,得到atten(64×b,3,49,49)。relative_position_bias是位置编码,这个就是套死公式,然后atten加上这个位置编码。现在还在W-MSA阶段,所以没有mask,直接对attn进行softmax。atten与v的转置点积,reshape得到(b,49,96),最后经过一个线性变换self.proj完成!
======================================================================
回到SwinTransformerBlock的forward继续。
将刚刚得到的重新view一下为(64×b,7,7,96)。window_reverse是将图像数据的size还原回原来的样子(64×b,7,7,96)->(b,56,56,96)。得到的结果view成(b,3136,96),最后做点线性变换做残差得到最终结果。
SW-MSA
W-MSA部分算是结束了,紧接着进入SW-MSA模块,重复的地方就不说了。还是在SwinTransformerBlock的forward方法中,这次将执行if self.shift_size > 0后的代码。
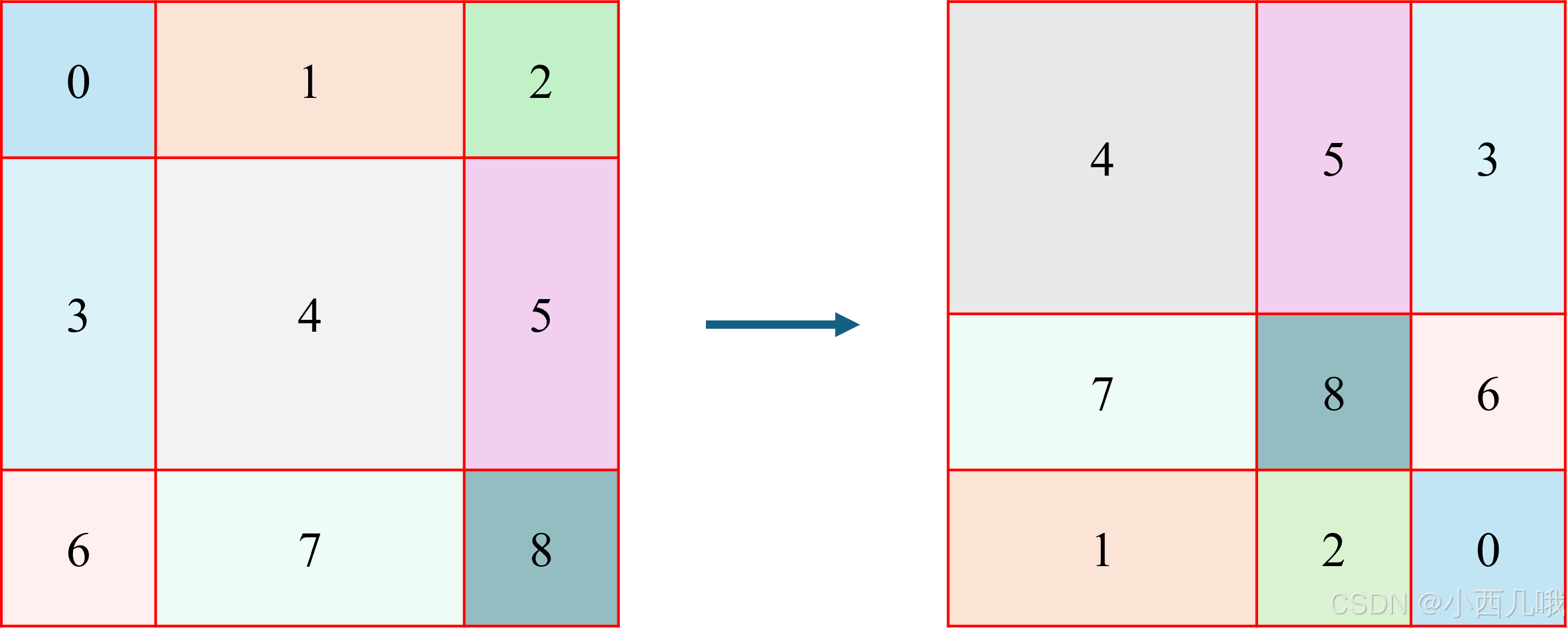
shift_size默认值为3,torch.roll就是用来窗口滑动的。我画了个图来理解它,加入shift_size为1的情况,它的效果如下图。
接下来不一样的点在计算注意力机制模块,WindowAttention的forward方法中。
if mask is not None:
nW = mask.shape[0]
attn = attn.view(B_ // nW, nW, self.num_heads, N, N) + mask.unsqueeze(1).unsqueeze(0)
attn = attn.view(-1, self.num_heads, N, N)
attn = self.softmax(attn)
这里的attn还加了一个mask矩阵,mask矩阵是怎么来的呢。
H, W = self.input_resolution
img_mask = torch.zeros((1, H, W, 1)) # 1 H W 1
h_slices = (slice(0, -self.window_size),
slice(-self.window_size, -self.shift_size),
slice(-self.shift_size, None))
w_slices = (slice(0, -self.window_size),
slice(-self.window_size, -self.shift_size),
slice(-self.shift_size, None))
cnt = 0
for h in h_slices:
for w in w_slices:
img_mask[:, h, w, :] = cnt
cnt += 1
mask_windows = window_partition(img_mask, self.window_size) # nW, window_size, window_size, 1
mask_windows = mask_windows.view(-1, self.window_size * self.window_size)
attn_mask = mask_windows.unsqueeze(1) - mask_windows.unsqueeze(2)
attn_mask = attn_mask.masked_fill(attn_mask != 0, float(-100.0)).masked_fill(attn_mask == 0, float(0.0))
先创建一个全零的掩码张量img_mask,shape为 (1, H, W, 1),用来存储窗口索引。h_slices和w_slices是用来划分区域的切片(其实我没看懂,只是大概知道是干啥的)。cnt为不同的窗口区域编号,然后按刚刚的切片填充不同的索引值,用来区分不同区域。这样,相同窗口的像素会有相同的cnt值,不同窗口的像素值不同。将img_mask按7×7进行窗口划分为mask_windows,展平,计算像素间的差值矩阵,相同窗口内的元素差值为 0,不同窗口之间的差值不为 0。不同窗口的填充-100,相同的填充0。
因此atten加上mask矩阵,对于连续窗口的token不做变化,而对于不连续窗口的token加上-100,经过softmax近似忽略。
做完这些之后要进入下采样了。
PatchMerging
跳到PatchMerging的forward方法中看看怎么个事。
def forward(self, x):
H, W = self.input_resolution
B, L, C = x.shape
assert L == H * W, "input feature has wrong size"
assert H % 2 == 0 and W % 2 == 0, f"x size ({H}*{W}) are not even."
x = x.view(B, H, W, C)
x0 = x[:, 0::2, 0::2, :] # B H/2 W/2 C
x1 = x[:, 1::2, 0::2, :] # B H/2 W/2 C
x2 = x[:, 0::2, 1::2, :] # B H/2 W/2 C
x3 = x[:, 1::2, 1::2, :] # B H/2 W/2 C
x = torch.cat([x0, x1, x2, x3], -1) # B H/2 W/2 4*C
x = x.view(B, -1, 4 * C) # B H/2*W/2 4*C
x = self.norm(x)
x = self.reduction(x)
return x
代码简洁明了,非常清晰。按H和W每隔一个像素点取值,然后拼接在一起。标准化后再经过一个线性变换,结束!输出(b,784,192)。(注:784=56÷2×56÷2,即H和W都减半。C一开始叠了4倍,后面经过self.reduction减半了,所以192=96×4÷2)
======================================================================
后面再重复几次,每次HW减半,C两倍,over!

















 21万+
21万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









