






DeepLab v3plus 模型解读(附源码+论文)
代码链接:https://github.com/xiaoxijio/DeeplabV3plus-VOC2012-Image-segmentation
论文链接:https://arxiv.org/abs/1802.02611
刚开始囫囵吞枣的看论文的时候,我以为模型结构就是下面这个图里的。但是看到代码里面大段的ResNet模块就很懵逼,这玩意放模型哪的。
一步一步看代码才了解到,先使用 ResNet 提取特征,再通过 DeepLabV3plus 的扩展模块处理这些特征。所以下图这个模型结构里还有个ResNet。
可以看到模型在原有的基础上增加了ASPP,那我们来分析一下模型的流程吧。
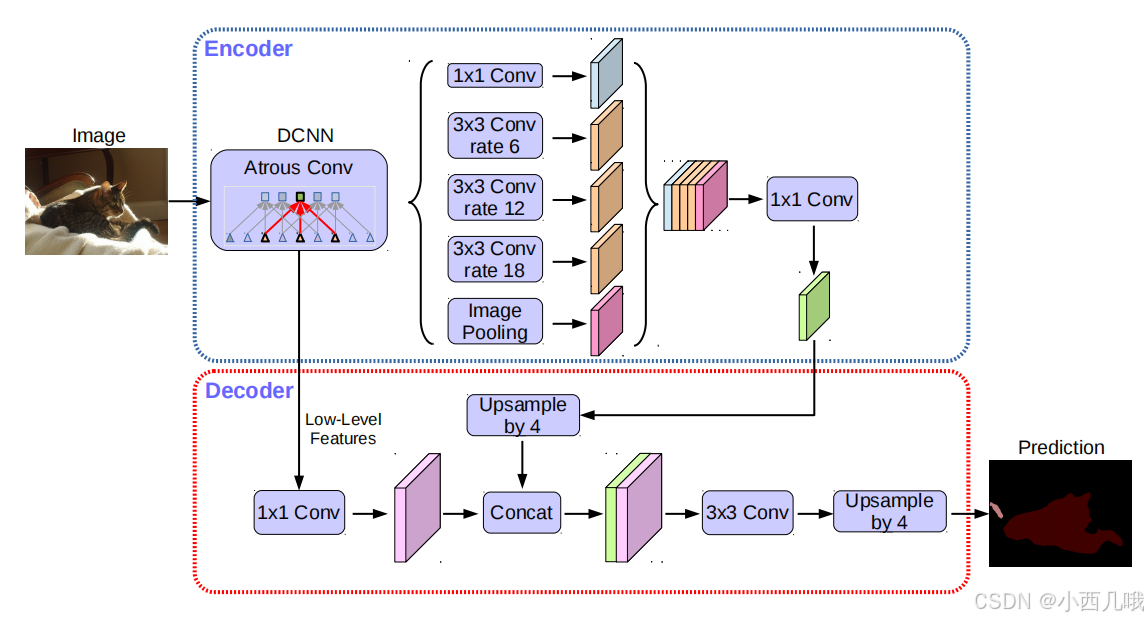
1. ResNet 主干网络
数据首先被输入到 ResNet 网络,主要用于提取底层到高层的特征。
ResNet 作为骨干网络(Backbone):
- 它将输入图像通过多个卷积和残差模块(Residual Blocks)提取特征。
- 一般会用到 ResNet 的前几个阶段(例如
ResNet50的 C1-C4 阶段),输出一个高维的特征图。 - 通常去掉 ResNet 的全连接层和最后的分类部分,只保留特征提取的卷积层。
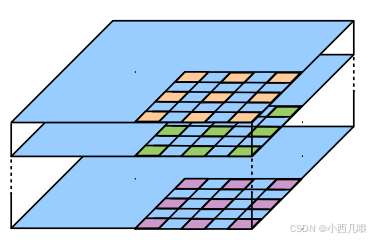
ResNet中也应用了空洞卷积。空洞卷积应该知道吧,就是在原始的卷积上隔几个空(空洞率)
if output_stride == 8:
replace_stride_with_dilation = [False, True, True]
aspp_dilate = [12, 24, 36]
else:
replace_stride_with_dilation = [False, False, True]
aspp_dilate = [6, 12, 18]
output_stride下采样比例
- 较大的
output_stride(如 16)会增加感受野,但可能导致分辨率不足。适合大物体分割 - 较小的
output_stride(如 8)提高了分辨率,但可能需要增加空洞卷积的膨胀率来保持足够的感受野。适合小物体分割
self.layer1 = self._make_layer(block, 64, layers[0])
self.layer2 = self._make_layer(block, 128, layers[1], stride=2, dilate=replace_stride_with_dilation[0])
self.layer3 = self._make_layer(block, 256, layers[2], stride=2, dilate=replace_stride_with_dilation[1])
self.layer4 = self._make_layer(block, 512, layers[3], stride=2, dilate=replace_stride_with_dilation[2])
replace_stride_with_dilation 决定 ResNet 中哪些层使用空洞卷积替代下采样。它会将卷积的 步幅(stride)= 2 替换为 步幅=1 并使用空洞卷积,从而在保持特征图分辨率的同时,扩大感受野。
2.DeepLabV3+ 的ASPP模块
从图中可以看到有两条分支,一个是往下的一个是往右的,先分析右边的ASPP模块。
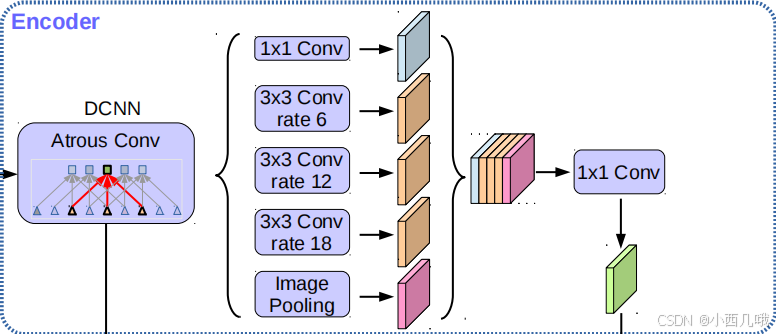
这个流程其实很简单,就是对输入分别执行了五层操作
-
第一层:简单的1*1卷积+BN+relu
-
第二层到第四层:3*3的空洞率(rate)分别为[6,12,18]的空洞卷积(当然根据上面说的,如果你的
output_stride为8,rate就是[12, 24, 36])。使用空洞的时候,padding的值和rate一样哦,为了确保输出特征图大小固定。 -
第五层:池化+1*1卷积+BN+relu
然后将五层输出拼接在一起,然后1*1卷积+BN+relu+丢弃层
网络结构就这么简单
3.DeepLabV3+ 的解码器(Decoder)
这里讲的就是往下的支线
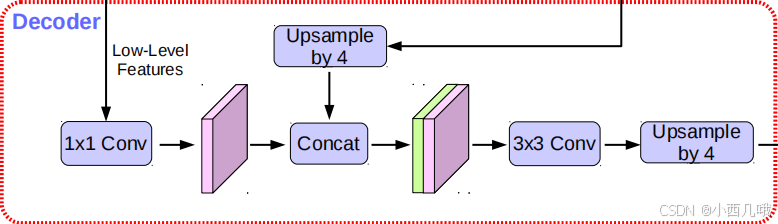
low_level先简单的1*1卷积+BN+relu,然后跟刚刚ASPP模块的输出拼接一下。不过ASPP都卷了好几层肯定比这个刚来的low_level的size小,所以对它做个上采样再跟low_level拼接。
拼接完再来个卷积+BN+relu+卷积,最后上采样到原来图大小输出。
总体架构流程图
- 输入图像 → ResNet 主干网络(加空洞卷积) → 提取特征
- ResNet 输出 → ASPP 模块 → 多尺度上下文信息提取
- ASPP 输出 + ResNet 较浅层特征 → Decoder 解码器 → 恢复分辨率
- 输出最终的分割结果
我自己用的mobilenet跑的,ResNet跑太慢了,懒得等,大家自己玩的话可以用ResNet
还有一点提醒哦,现在pytorch是提供deeplabv3_resnet50这些模型的,可以直接调用,所以提供的代码主要以学习为主 。
看一下效果 ,我mobilenet跑了有三个小时吧,实在不想等了所以提前终止了,效果可能还没跑的特别好,大家自己跑可以用ResNet50或者101,跑个三年五载看看
从左到右分别是 原图–>覆盖图–>预测图–>真实图。感觉细节图刻画的一般,大图还好,可能我用的mobilenet+训练时间短导致的。

大家模型训练好后,测试的时候记得改几个参数。打开仅测试,ckpt写自己训练好的模型位置。
parser.add_argument("--test_only", action='store_true', default=True)
parser.add_argument("--ckpt", default='checkpoints/best_deeplabv3_mobilenet_voc_os16.pth', type=str,
help="restore from checkpoint")
代码链接:https://github.com/xiaoxijio/DeeplabV3plus-VOC2012-Image-segmentation
论文链接:https://arxiv.org/abs/1802.02611

















 7092
7092

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









