









 本文介绍了如何使用Python的pandas库处理数据重复问题,包括使用duplicated()检查重复项,利用drop_duplicates()删除重复值,并通过实例展示了具体操作。适合初学者了解和实践数据清洗。
本文介绍了如何使用Python的pandas库处理数据重复问题,包括使用duplicated()检查重复项,利用drop_duplicates()删除重复值,并通过实例展示了具体操作。适合初学者了解和实践数据清洗。
🌠 『精品学习专栏导航帖』
- 🐳最适合入门的100个深度学习实战项目🐳
- 🐙【PyTorch深度学习项目实战100例目录】项目详解 + 数据集 + 完整源码🐙
- 🐶【机器学习入门项目10例目录】项目详解 + 数据集 + 完整源码🐶
- 🦜【机器学习项目实战10例目录】项目详解 + 数据集 + 完整源码🦜
- 🐌Java经典编程100例🐌
- 🦋Python经典编程100例🦋
- 🦄蓝桥杯历届真题题目+解析+代码+答案🦄
- 🐯【2023王道数据结构目录】课后算法设计题C、C++代码实现完整版大全🐯
✌ duplicated()和drop_duplicates()
✌ 导库
import pandas as pd
import numpy as np
✌ 创建数据集
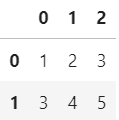
x=np.array([[1,2,3],[3,4,5],[1,2,3],[1,2,3]])
x=pd.DataFrame(x)
x

✌ duplicated()
返回每行数据是否重复
x.duplicated()

✌ 计算重复数据数目
x.duplicated().sum()
✌ drop_duplicates()
删除重复值
x=x.drop_duplicates()
x



















 2236
2236

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











