







 超级会员免费看
超级会员免费看
 模型微调时先冻结底层、训练顶层是为保留预训练模型的通用特征,防止过拟合,减少计算量并保护预训练特征。底层包含迁移特征,顶层微调使模型适应特定任务,此策略能提高性能,保持训练稳定性。
模型微调时先冻结底层、训练顶层是为保留预训练模型的通用特征,防止过拟合,减少计算量并保护预训练特征。底层包含迁移特征,顶层微调使模型适应特定任务,此策略能提高性能,保持训练稳定性。
文章目录

一、模型微调先冻结底层,训练顶层的原因?
模型微调时先冻结底层,训练顶层的原因是为了保留预训练模型在大规模数据上学到的通用特征,并在特定任务上进行适应。这个做法有几个重要的考虑因素:
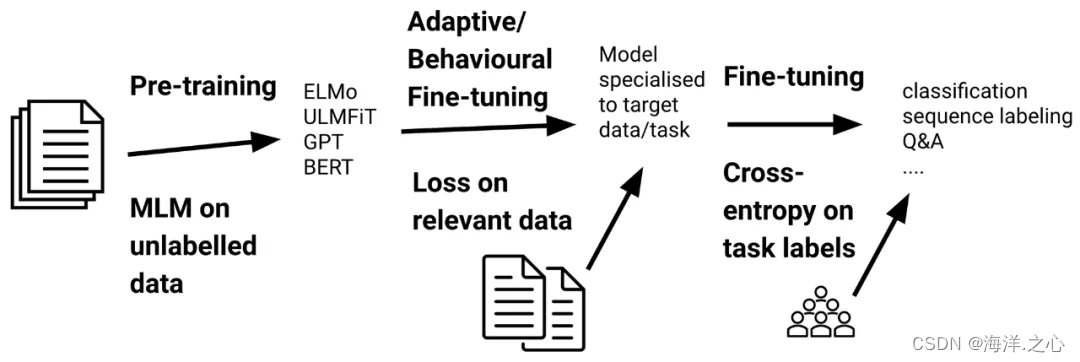
-
迁移特征: 预训练模型的底层包含了通用的特征提取器,这些特征对于许多任务都是有用的。通过冻结底层,可以将这些预训练特征迁移到目标任务中,从而为顶层提供更有信息量的输入。
-
防止过拟合: 预训练模型在大规模数据上训练,通常已经达到了相对稳定的状态。直接在小规模数据上微调整个模型,容易导致过拟合。冻结底层可以减少模型的参数,降低过拟合风险。
-
减少计算量: 预训练模型的底层参数已经收敛,微调时不需要在这些层上进行大幅度的参数更新,因此可以

 订阅专栏 解锁全文
订阅专栏 解锁全文



















 934
934

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











