







前言
学习率调度器(Learning Rate Scheduler)是深度学习中优化的一部分,用于动态调整学习率,帮助优化器更高效地找到全局最优解。PyTorch 提供了一系列学习率调度器,可以根据训练进程调整学习率。
1. 为什么使用学习率调度器?
- 提高收敛速度:在训练早期使用较大的学习率,快速收敛。
- 避免局部最优:动态调整学习率可以帮助优化器跳出局部最优。
- 稳定训练:在训练后期逐步减小学习率,获得更精确的模型参数。
2. PyTorch 常用学习率调度器
以下是一些常见的学习率调度器:
1. StepLR:每隔固定的步数减少学习率。
2. MultiStepLR:在指定的步数上调整学习率。
3. ExponentialLR:指数衰减学习率。
4. CosineAnnealingLR:余弦退火调整学习率,适用于 warm restart。
5. ReduceLROnPlateau:当监控的指标停止改善时减少学习率。
6. LambdaLR:基于用户定义的函数调整学习率,灵活性高。
7. LinearLR:线性调整学习率。
8. ChainedScheduler:串联多个调度器依次运行。
3. 选择学习率调度器的技巧
- StepLR 和 MultiStepLR:适用于预先知道学习率调整时间点的情况。
- CosineAnnealingLR:适用于需要周期性调整学习率的任务。
- ReduceLROnPlateau:当无法确定学习率更新时机时使用。
- LinearLR:适用于学习率从初始值逐步增加的 warmup (热身) 过程。
- ExponentialLR:需要平稳指数衰减时使用。
根据具体任务选择合适的调度器,配合良好的初始学习率设置,可以显著提升模型性能和训练效率。
一、LinearLR(Pytorch 1.10.0版本开始引入)
LinearLR 是 PyTorch 的一个学习率调度器,它可以线性调整学习率,常用于训练开始时逐步增大学习率(热身阶段)。通过线性学习率调整,可以有效缓解学习率突变对模型训练的不利影响。
1.1 LinearLR 的定义
LinearLR 位于 torch.optim.lr_scheduler 模块中,使用方法如下:
torch.optim.lr_scheduler.LinearLR(optimizer, start_factor=0.3, end_factor=1.0, total_iters=5, last_epoch=-1, verbose=False)
1.2 参数说明
optimizer: 优化器实例,例如torch.optim.SGD。start_factor: 学习率起始值与初始学习率的比值(默认 0.3)。- 如果优化器初始学习率为
lr=0.01,则start_factor=0.3表示学习率从0.01 * 0.3 = 0.003开始。
- 如果优化器初始学习率为
end_factor: 学习率结束值与初始学习率的比值(默认 1.0)。- 表示学习率会逐步增大到优化器的初始学习率。
total_iters: 学习率从start_factor调整到end_factor所需的总迭代次数。- 通常等于热身阶段的迭代步数。
last_epoch: 上一次的 epoch 值,默认为-1,表示从头开始。verbose: 是否打印每次学习率调整的信息。
1.3 使用示例
以下代码展示了如何在训练时使用 LinearLR 调度器:
import torch
import torch.nn as nn
import torch.optim as optim
from torch.optim.lr_scheduler import LinearLR
# 创建模型和优化器
model = nn.Linear(10, 1)
optimizer = optim.SGD(model.parameters(), lr=0.1)
# 配置 LinearLR 调度器
warmup_epochs = 5
scheduler = LinearLR(optimizer, start_factor=0.1, end_factor=1.0, total_iters=warmup_epochs)
# 模拟训练过程
for epoch in range(10):
# 假装训练
optimizer.step()
# 更新学习率
scheduler.step()
# 打印当前学习率
current_lr = optimizer.param_groups[0]['lr']
print(f"Epoch {epoch + 1}, Learning Rate: {current_lr:.6f}")
1.4 LinearLR 输出示例
如果优化器初始学习率为 lr=0.1,总热身迭代次数为 5,则输出类似:
Epoch 1, Learning Rate: 0.010000
Epoch 2, Learning Rate: 0.032500
Epoch 3, Learning Rate: 0.055000
Epoch 4, Learning Rate: 0.077500
Epoch 5, Learning Rate: 0.100000
Epoch 6, Learning Rate: 0.100000
...
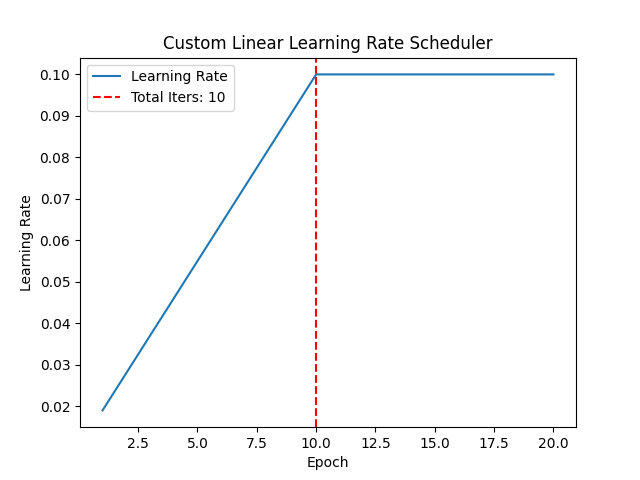
在热身阶段(前 5 个 epoch),学习率从 0.01(即 0.1 * 0.1)线性增加到 0.1。
1.5 与其他调度器配合使用
LinearLR 通常与其他调度器(如 MultiStepLR 或 CosineAnnealingLR)结合使用,用于实现更复杂的学习率调整策略。可以通过 ChainedScheduler 将多个调度器按顺序组合成一个整体调度器。在训练过程中,它会依次应用这些调度器,每个调度器负责一定的迭代范围。
1.6 LinearLR 学习率调度器产生的学习率趋势图
由于笔者的pytorch版本为1.9.1,在这个版本的pytorch中,optim.lr_scheduler 库中没有LinearLR,因此笔者自己写了一个类似的LinearLR学习率调度器,代码如下所示:
from torch.optim import Optimizer
class CustomLinearLR:
def __init__(self, optimizer: Optimizer, start_factor: float, end_factor: float, total_iters: int,
last_epoch: int = -1):
"""
自定义线性学习率调度器。
Args:
optimizer (Optimizer): PyTorch优化器。
start_factor (float): 学习率的初始比例。
end_factor (float): 学习率的最终比例。
total_iters (int): 线性调整的总迭代次数。
last_epoch (int): 上一次迭代的 epoch 索引。
"""
if total_iters <= 0:
raise ValueError("total_iters must be greater than 0.")
self.optimizer = optimizer
self.start_factor = start_factor
self.end_factor = end_factor
self.total_iters = total_iters
self.last_epoch = last_epoch
self.current_factor = start_factor
self.step()
def get_lr(self):
"""
根据当前迭代次数计算学习率比例。
"""
if self.last_epoch >= self.total_iters:
return self.end_factor
progress = self.last_epoch / self.total_iters
return self.start_factor + progress * (self.end_factor - self.start_factor)
def step(self):
"""
更新学习率。
"""
self.last_epoch += 1
self.current_factor = self.get_lr()
for param_group in self.optimizer.param_groups:
param_group['lr'] = param_group['initial_lr'] * self.current_factor
# 示例代码
if __name__ == "__main__":
import torch
import matplotlib.pyplot as plt
# 模型和优化器
model = torch.nn.Linear(10, 2)
optimizer = torch.optim.SGD([{'params': model.parameters(), 'initial_lr': 0.1}], lr=0.1)
# 自定义调度器
scheduler = CustomLinearLR(optimizer, start_factor=0.1, end_factor=1.0, total_iters=10)
# 记录学习率
lr_values = []
for epoch in range(20):
scheduler.step()
lr_values.append(optimizer.param_groups[0]['lr'])
# 绘制学习率曲线
plt.plot(range(1, 21), lr_values, label="Learning Rate")
plt.xlabel("Epoch")
plt.ylabel("Learning Rate")
plt.title("Custom Linear Learning Rate Scheduler")
plt.axvline(x=10, color='red', linestyle='--', label='Total Iters: 10')
plt.legend()
plt.show()
绘制学习率变化图如下所示:
二、 ChainedScheduler (Pytorch 1.10.0版本开始引入)
- 假设你有两个调度器:
scheduler1和scheduler2。 ChainedScheduler会先运行scheduler1的调度逻辑,直到其生命周期结束;然后接着运行scheduler2的调度逻辑。
2.1 ChainedScheduler 举例
import torch
from torch.optim import SGD
from torch.optim.lr_scheduler import ChainedScheduler, LinearLR, StepLR
# 优化器
optimizer = SGD([torch.zeros(1)], lr=0.1)
# 两个调度器
linear_scheduler = LinearLR(optimizer, start_factor=0.1, total_iters=5) # 第1-5步学习率线性增加
step_scheduler = StepLR(optimizer, step_size=10, gamma=0.1) # 第6步开始,每10步学习率乘0.1
# 将两个调度器组合
scheduler = ChainedScheduler([linear_scheduler, step_scheduler])
# 模拟更新
for epoch in range(20):
optimizer.step()
scheduler.step() # 按顺序调用调度器
print(f"Epoch {epoch + 1}, LR: {optimizer.param_groups[0]['lr']:.6f}")
2.2 ChainedScheduler 运行结果说明
- 前 5 个 epoch,
LinearLR增加学习率(从0.01线性增长到0.1)。 - 第 6 个 epoch 开始,
StepLR开始生效,每 10 个 epoch 学习率减少一次。
三、StepLR 学习率调度器
StepLR 是 PyTorch 中的一个学习率调度器,它在训练过程中以预定的步长(epoch 数量)来调整学习率。具体来说,StepLR 会在每经过一定数量的 epochs(由 step_size 参数指定)后,按给定的衰减因子(由 gamma 参数指定)减少学习率。这个调度器适用于逐步减小学习率的场景,通常用于训练时期较长的模型。
3.1 StepLR 学习率调度器的定义及参数
定义:
torch.optim.lr_scheduler.StepLR(optimizer, step_size, gamma=0.1, last_epoch=-1, verbose=False)
参数:
optimizer: 必须是一个优化器对象,如torch.optim.SGD或torch.optim.Adam。StepLR会根据该优化器调整其学习率。step_size: 每step_size个 epoch 就调整一次学习率。gamma: 学习率的衰减因子。每step_size个 epoch 后,学习率会乘以gamma,通常取一个小于 1 的值来减小学习率。last_epoch: 上一个 epoch 的索引,默认值为 -1,表示从头开始。如果指定一个值,则学习率调整会从指定的 epoch 开始,通常在继续训练时使用。verbose: 如果为True,则每次学习率更新时都会打印出新的学习率。
3.2 工作原理
- 每经过
step_size个 epoch,学习率就会乘以gamma。例如,如果初始学习率为0.1,step_size设置为 30,gamma设置为0.1,那么在第 30 个 epoch 后,学习率会变为0.1 * 0.1 = 0.01,然后在第 60 个 epoch 后会再次变为0.01 * 0.1 = 0.001,依此类推。
3.3 StepLR 代码示例
import torch
import torch.optim as optim
# 假设你已经有一个模型和优化器
model = ... # 定义模型
optimizer = optim.Adam(model.parameters(), lr=0.1)
# 创建 StepLR 调度器
scheduler = optim.lr_scheduler.StepLR(optimizer, step_size=30, gamma=0.1)
# 在训练循环中使用
for epoch in range(100):
# 训练代码
# ...
# 更新学习率
scheduler.step()
print(f'Epoch {epoch+1}, Learning Rate: {scheduler.get_last_lr()[0]}')
3.4 适用场景
- 适合在训练过程中需要周期性降低学习率的情况。
- 常用于训练周期较长时,逐步减小学习率帮助模型更好地收敛。
3.5 StepLR学习率走势图
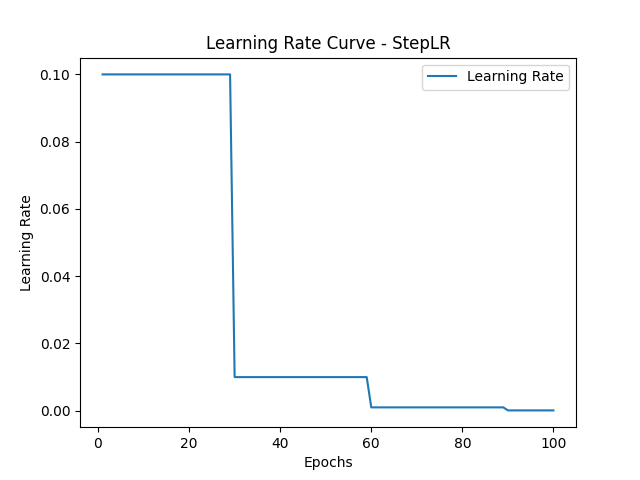
代码如下:初始学习率为0.1,step_size为30,gamma系数为0.1 ,即每经过30个epoch学习率缩小十倍,即第30个epoch时学习率变为0.01,第60个epoch时学习率变为0.001。
import torch
import torch.optim as optim
import matplotlib.pyplot as plt
# 假设有一个模型和优化器
model = torch.nn.Linear(10, 2)
optimizer = optim.SGD(model.parameters(), lr=0.1)
# 创建 StepLR 调度器
scheduler = optim.lr_scheduler.StepLR(optimizer, step_size=30, gamma=0.1)
# 用于记录学习率的列表
lr_values = []
# 训练过程
for epoch in range(100):
# 假设训练代码在此处
# 例如:模型前向传播,损失计算,反向传播等
# optimizer.zero_grad()
# loss.backward()
# optimizer.step()
# 更新学习率
scheduler.step()
# 记录当前学习率
lr_values.append(scheduler.get_last_lr()[0])
# 绘制学习率曲线
plt.plot(range(1, 101), lr_values, label="Learning Rate")
plt.xlabel('Epochs')
plt.ylabel('Learning Rate')
plt.title('Learning Rate Curve - CosineAnnealingLR')
plt.legend()
plt.show()
根据上面的代码,StepLR 学习率调度器所产生的学习率走势图如下图所示。初始学习率为0.1,在第30个epoch时,学习率缩小为原来的1/10,变为0.01;在第60个epoch时,学习率变为0.001;在第90个epoch时,学习率变为0.0001。
3.6 小结
StepLR 是一种非常基础的学习率调度器,它通过定期降低学习率来促进模型的优化,尤其在长时间训练时帮助避免学习率过大导致的训练不稳定。
四、CosineAnnealingLR
CosineAnnealingLR 是 PyTorch 中的一种学习率调度器,它通过余弦退火(Cosine Annealing)策略调整学习率。具体来说,它会在训练过程中逐渐降低学习率,并且该过程遵循余弦函数的形状,学习率先从初始值开始,然后逐渐降低,直到结束时接近零。
4.1 定义及参数解释
定义:
torch.optim.lr_scheduler.CosineAnnealingLR(optimizer, T_max, eta_min=0, last_epoch=-1, verbose=False)
参数:
optimizer: 用于更新模型参数的优化器对象(如torch.optim.SGD或torch.optim.Adam)。T_max: 余弦退火周期的最大迭代次数(epoch)。即一个周期后学习率会回到最小值(eta_min)。如果训练总 epoch 数为N,T_max可以是N,表示在整个训练过程中一次退火。eta_min: 最小学习率。学习率将在训练结束时逐渐减小到该值。默认值为 0。last_epoch: 上一个 epoch 的索引,默认值为 -1,表示从头开始。如果继续训练时可以指定为最后一个 epoch 索引。verbose: 如果为True,每次学习率更新时会打印学习率信息。
4.2 工作原理
- 学习率从初始值
lr_max逐渐减小,遵循余弦函数的曲线:在训练过程中,学习率会按照lr = eta_min + (lr_max - eta_min) * (1 + cos(pi * epoch / T_max)) / 2的公式调整。 - 训练过程中,学习率的减小速度比较平缓,最后趋近于
eta_min。
4.3 代码示例
import torch
import torch.optim as optim
# 假设有一个模型和优化器
model = torch.nn.Linear(10, 2)
optimizer = optim.SGD(model.parameters(), lr=0.1)
# 创建 CosineAnnealingLR 调度器,设置最大周期 T_max=100
scheduler = optim.lr_scheduler.CosineAnnealingLR(optimizer, T_max=100, eta_min=0)
for epoch in range(100):
# 假设训练代码在此处
# ...
# 调用 step 更新学习率
scheduler.step()
print(f'Epoch {epoch+1}, Learning Rate: {scheduler.get_last_lr()[0]}')
4.4 学习率变化示意
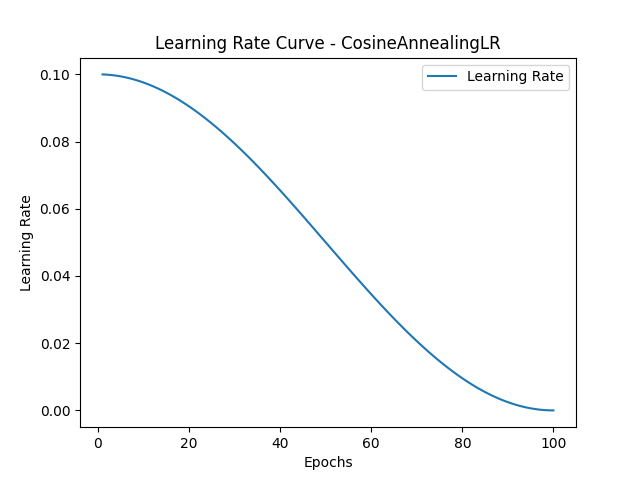
在周期内,学习率会从初始值逐渐减少,并且变化的方式是一个平滑的余弦曲线,最终接近最小学习率 eta_min。
4.5 适用场景
CosineAnnealingLR适合用于需要逐渐减小学习率并在训练过程中保持一定程度随机性的场景。- 特别适合当训练周期较长时,能够平滑地降低学习率,帮助模型收敛并避免早期过拟合。
- 这种调度方式也常见于一些高级训练策略(例如,warm restarts)中,其中学习率在多个周期内循环变化。
4.6 CosineAnnealingLR 学习率走势图
绘制余弦退火学习率变化走势图,代码如下:
在代码中,初始学习率为0.1,
import torch
import torch.optim as optim
import matplotlib.pyplot as plt
# 假设有一个模型和优化器
model = torch.nn.Linear(10, 2)
optimizer = optim.SGD(model.parameters(), lr=0.1)
# 创建 CosineAnnealingLR 调度器,设置最大周期 T_max=100
scheduler = optim.lr_scheduler.CosineAnnealingLR(optimizer, T_max=100, eta_min=0)
# 用于记录学习率的列表
lr_values = []
# 训练过程
for epoch in range(100):
# 假设训练代码在此处
# 例如:模型前向传播,损失计算,反向传播等
# optimizer.zero_grad()
# loss.backward()
# optimizer.step()
# 更新学习率
scheduler.step()
# 记录当前学习率
lr_values.append(scheduler.get_last_lr()[0])
# 绘制学习率曲线
plt.plot(range(1, 101), lr_values, label="Learning Rate")
plt.xlabel('Epochs')
plt.ylabel('Learning Rate')
plt.title('Learning Rate Curve - CosineAnnealingLR')
plt.legend()
plt.show()
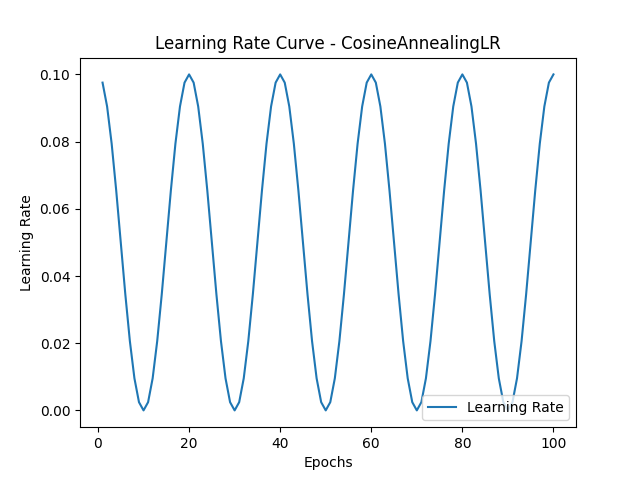
得到如下学习率变化图:(左图T_max=100,右图T_max=10)
4.7 小结
CosineAnnealingLR 是一种有效的学习率调度方法,特别适用于较长时间训练的任务,通过平滑的余弦退火降低学习率,帮助模型在后期训练中更精确地收敛。
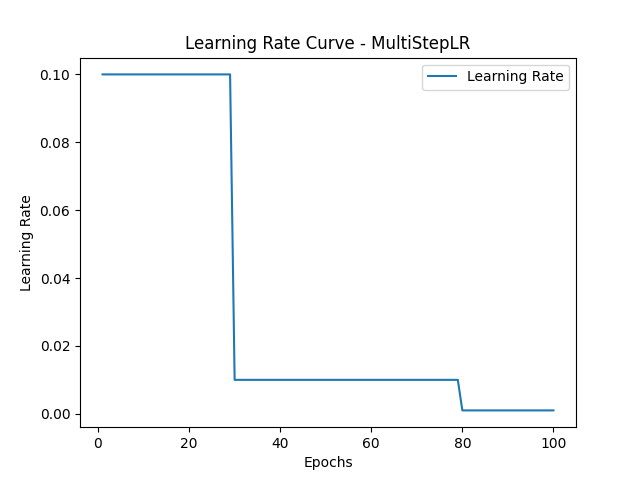
五. MultiStepLR学习率调度器
5.1 定义
MultiStepLR 是 PyTorch 中的一个学习率调度器,允许在训练期间根据指定的里程碑 (milestones) 阶段性地调整学习率。每当达到一个里程碑时,学习率会按照一个给定的衰减因子 (gamma) 缩减。
torch.optim.lr_scheduler.MultiStepLR(optimizer, milestones, gamma=0.1, last_epoch=-1, verbose=False)
5.2 参数说明
optimizer: 目标优化器,例如torch.optim.SGD或torch.optim.Adam。milestones: 一个整数列表,表示训练期间的学习率下降的时刻(epoch 数)。gamma: 学习率下降的倍数,默认值为0.1。last_epoch: 上一次更新时的 epoch 数,默认值为-1,表示从头开始。verbose: 如果为True,则在每次更新时打印学习率变化的日志。
5.3 示例代码
以下是一个使用 MultiStepLR 的完整示例,并绘制学习率随 epoch 变化的曲线:
import torch
import torch.optim as optim
import matplotlib.pyplot as plt
# 假设有一个简单模型
model = torch.nn.Linear(10, 2)
# 使用 SGD 优化器
optimizer = optim.SGD(model.parameters(), lr=0.1)
# 定义 MultiStepLR 调度器,里程碑为 [30, 80],学习率每次减小为原来的 0.1
scheduler = torch.optim.lr_scheduler.MultiStepLR(optimizer, milestones=[30, 80], gamma=0.1)
# 用于记录学习率的列表
lr_values = []
# 模拟 100 个 epoch 的训练过程
for epoch in range(100):
# 训练代码可以在这里插入
# optimizer.zero_grad()
# loss.backward()
# optimizer.step()
# 更新学习率
scheduler.step()
# 记录当前学习率
lr_values.append(scheduler.get_last_lr()[0])
# 绘制学习率曲线
plt.plot(range(1, 101), lr_values, label="Learning Rate")
plt.xlabel('Epochs')
plt.ylabel('Learning Rate')
plt.title('Learning Rate Curve - MultiStepLR')
plt.axvline(x=30, color='red', linestyle='--', label='Milestone: 30')
plt.axvline(x=80, color='blue', linestyle='--', label='Milestone: 80')
plt.legend()
plt.show()
5.4 代码解释
-
定义调度器:
- 里程碑设置为
[30, 80],表示在第 30 和第 80 个 epoch 时,学习率分别乘以gamma=0.1。
- 里程碑设置为
-
记录学习率:
- 在每个 epoch 调用
scheduler.step()更新学习率,并使用scheduler.get_last_lr()记录当前学习率。
- 在每个 epoch 调用
-
绘制曲线:
- 使用
matplotlib绘制从第 1 个 epoch 到第 100 个 epoch 的学习率变化。 - 在里程碑处(30 和 80)画虚线以标注学习率变化。
- 使用
5.5 输出结果
输出的图表中:
- 初始学习率为
0.1。 - 第 30 个 epoch 时,学习率变为
0.01(0.1 * 0.1)。 - 第 80 个 epoch 时,学习率进一步变为
0.001(0.01 * 0.1)。 - 其余 epoch,学习率保持不变。
5.6 适用场景
MultiStepLR 常用于以下情况:
- 模型训练需要在特定的 epoch 阶段减小学习率。
- 通过学习率衰减提高收敛速度和模型性能。
- 在预定义训练计划中明确标注的学习率调整步骤。

















 314
314

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









