







本文提出了一个名为TIME-LLM的重编程框架,旨在将大语言模型(LLMs)重新利用于通用的时间序列预测任务,并且保持语言模型的核心结构不变。
- 代码已开源,项目地址:https://github.com/KimMeen/Time-LLM
目录
2.1 任务特定学习 (Task-specific Learning)
2.2 同模态适应 (In-modality Adaptation)
2.3 跨模态适应 (Cross-modality Adaptation)
2.4 与现有方法的差异 (Distinctions from Existing Approaches)
引言
1. 背景与动机
- 时间序列预测的重要性:时间序列预测在许多实际动态系统中具有重要作用。时间序列预测在多个现实世界动态系统中起着关键作用(Jin等,2023年),应用领域包括需求计划(Leonard,2001年)、库存优化(Li等,2022年)、能源负载预测(Liu等,2023年)以及气候建模(Schneider和Dickinson,1974年)。
- 与自然语言处理(NLP)和计算机视觉(CV)的对比:
相较于NLP和CV领域,一个大型模型通常能够处理多种任务,而时间序列预测模型往往是专门化的,不同的任务和应用需要不同的模型设计。
预训练的基础模型,尤其是大语言模型(LLMs),已经在计算机视觉(CV)和自然语言处理(NLP)领域取得了快速进展。虽然时间序列建模尚未经历类似的重大突破,但LLMs的强大能力激发了将其应用于时间序列预测的研究(Jin等,2023年)。以下是将LLMs应用于提升预测技术的几个关键需求:
-
- 泛化能力:LLMs展现了强大的少样本和零样本迁移学习能力(Brown等,2020年),这意味着它们在不需要针对每个任务从头训练的情况下,可以实现跨领域的通用预测。相比之下,当前的预测方法通常是高度专门化的,难以灵活应用。
- 数据效率:LLMs通过利用预训练的知识,可以在有限样本的情况下执行新任务。这种数据效率使得在历史数据有限的环境中也能实现有效的预测。而当前的预测方法往往需要大量的同领域数据。
- 推理能力:LLMs具备复杂的推理和模式识别能力(Mirchandani等,2023年;Wang等,2023年;Chu等,2023年)。通过利用这些能力,模型可以基于学到的高级概念做出更加精确的预测。现有的非LLM方法大多是基于统计的,缺乏推理能力。
- 多模态知识:随着LLM架构和训练技术的进步,模型在视觉、语音和文本等多个模态中积累了更多的知识(Ma等,2023年)。利用这些跨模态的知识,可以实现协同预测,整合不同的数据类型。而传统工具缺乏利用多种知识库的能力。
- 优化便捷性:LLMs只需一次大规模的训练,然后可以直接应用于预测任务,而无需从头开始学习。现有的预测模型通常需要大量的架构搜索和超参数调整(Zhou等,2023年)。
- 基础模型的发展差距:虽然预训练的基础模型在NLP和CV领域取得了显著进展,但在时间序列领域的发展受限于数据稀疏性的问题。**每项时间序列预测任务通常需要大量的领域知识和特定任务的模型设计。**这与基础语言模型(如GPT-3、GPT-4、Llama等)形成了鲜明对比,这些模型在少样本甚至零样本的情况下也能在广泛的自然语言处理(NLP)任务中表现良好。
2. 挑战与解决方案
要实现上述优点,关键在于有效对齐时间序列数据和自然语言这两种模态。然而,这是一项具有挑战性的任务,原因如下:
- LLMs基于离散的符号(token)进行操作,而时间序列数据本质上是连续的。
- LLMs的预训练过程中,并未自然包含解释时间序列模式的知识和推理能力。
在此背景下,本文提出了TIME-LLM框架,旨在通过重编程将大语言模型应用于时间序列预测任务,且在此过程中保持模型的核心结构不变。该框架的核心思想是将输入的时间序列数据重编程为更适合语言模型处理的文本原型表示,以实现模态对齐。
3. TIME-LLM框架的创新性
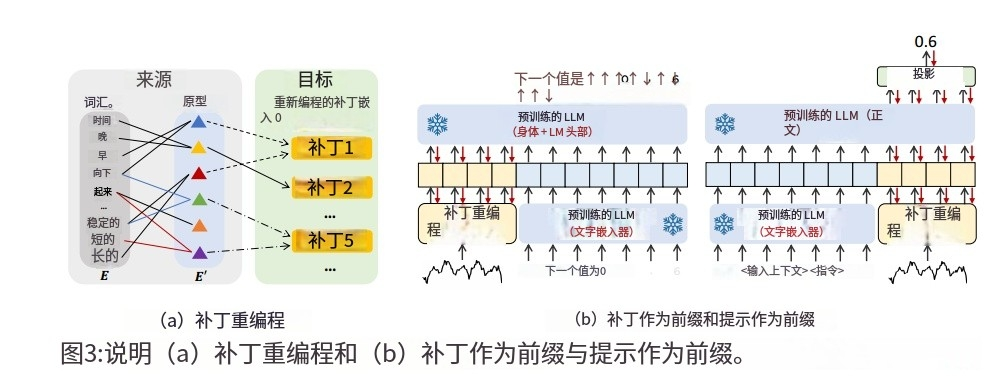
- 重编程的概念:本文首次提出了大语言模型重编程的概念,用于时间序列预测任务。在不改变预训练模型的基础上,展示了时间序列预测可以被重新定义为一种“语言任务”,从而由现成的大语言模型有效解决。
- Prompt-as-Prefix (PaP):为了增强模型对时间序列概念的推理能力,我们引入了“Prompt-as-Prefix”方法。通过为输入时间序列提供额外的上下文信息和任务指令,指导模型在自然语言模态下进行转换。该方法为模型如何对重编程后的输入应用转换提供了明确的指导,提升了模型的推理能力。
- 时间序列预测:经过大语言模型处理后的时间序列数据,输出将被投影以生成预测结果。通过这种方式,模型不仅能够理解语言,还能处理顺序数据任务,提升了模型在时间序列预测任务中的表现。
4. 实验与结果
- 优异表现:TIME-LLM在主流时间序列预测任务中展现了超越最先进预测模型的表现,尤其是在少样本和零样本场景下。TIME-LLM不仅表现优异,还保持了出色的模型重编程效率。
- 多模态基础模型的未来:TIME-LLM通过利用大语言模型的推理能力,展示了大语言模型在语言和顺序数据任务中都具备卓越表现的潜力,指引了未来多模态基础模型的发展方向。
5. 研究贡献总结
- 引入了LLM重编程的创新概念:我们首次提出了将大语言模型重编程用于时间序列预测任务的概念,且在此过程中保持了模型的核心结构不变。展示了预测任务可以被重新定义为“语言任务”。
- TIME-LLM框架的设计:提出了TIME-LLM框架,通过将输入的时间序列重编程为文本原型表示,使其更适合语言模型的处理。同时,通过“Prompt-as-Prefix”策略为模型提供明确的任务指令,引导模型推理和处理时间序列数据。
- 卓越的性能:TIME-LLM在多个主流预测任务中展现了领先的性能,尤其是在少样本和零样本学习场景下。此外,TIME-LLM能够在保持高效重编程的前提下,持续超越现有的专用预测模型。
- 未来扩展:本文的重编程框架为大模型在超越其原有预训练能力的基础上,赋予了新的能力,为未来研究指明了新的方向,尤其是多模态基础模型在语言和顺序数据任务上的应用潜力。
2. 相关工作 (Related Work)
2.1 任务特定学习 (Task-specific Learning)
大多数时间序列预测模型是为特定任务和领域(例如交通预测)量身定制的,并通过端到端的小规模数据训练来实现目标。这类模型专注于某一领域,难以推广到其他任务或领域。
2.2 同模态适应 (In-modality Adaptation)
在计算机视觉(CV)和自然语言处理(NLP)领域,预训练模型的效果已被充分证明,这些模型可以通过微调适应不同的下游任务,而无需从头开始进行高昂的训练(Devlin等,2018;Brown等,2020;Touvron等,2023)。受这些成功经验的启发,最近的研究开始开发时间序列预训练模型(TSPTMs)。这些研究的首要步骤是通过监督学习(Fawaz等,2018)或自监督学习(Zhang等,2022b;Deldari等,2022;Zhang等,2023)对时间序列进行预训练,帮助模型学习表示多种输入的时间序列。预训练完成后,模型可以在相似的领域内进行微调,以学习如何执行特定任务(Tang等,2022),例如图1(b)所示。然而,TSPTMs的应用仍受到数据稀疏性的限制,规模相对较小。
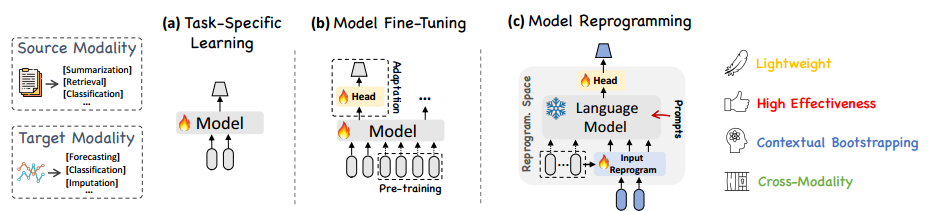
2.3 跨模态适应 (Cross-modality Adaptation)
基于同模态适应的研究,最近的工作进一步探索了将自然语言处理和计算机视觉中强大的预训练基础模型的知识迁移到时间序列建模中的方法,如多模态微调(Yin等,2023)和模型重编程(Chen,2022)。这些方法旨在利用跨模态的知识提升时间序列预测性能。
例如,Voice2Series(Yang等,2021)将语音识别中的声学模型(AM)适应于时间序列分类任务,通过将时间序列编辑成适合声学模型的格式进行处理。最近,Chang等(2023) 提出了 LLM4TS,这是一个用于时间序列预测的LLM模型。该模型设计了一个两阶段的微调过程,首先对时间序列进行监督预训练,然后针对具体任务进行微调。而Zhou等(2023a) 则提出利用预训练语言模型的方式,在不修改其自注意力机制和前馈层的情况下,通过微调进行时间序列分析任务,并展现了与当前最先进模型相媲美的性能。
2.4 与现有方法的差异 (Distinctions from Existing Approaches)
与上述方法不同,本文提出的TIME-LLM框架既不直接编辑输入的时间序列数据,也不微调预训练的大语言模型(LLM)。如图1(c)所示,TIME-LLM框架通过重编程将时间序列数据转换为适合LLM处理的输入格式,并结合提示(prompt)以激发LLM在时间序列任务中的潜力,从而无需修改LLM的骨干模型,实现有效的时间序列预测。
总结来说,TIME-LLM与现有的时间序列建模方法相比,采用了一种创新的重编程策略,通过模态转换和提示机制使大语言模型能够适应时间序列预测任务,避免了复杂的模型微调过程。
3.方法论
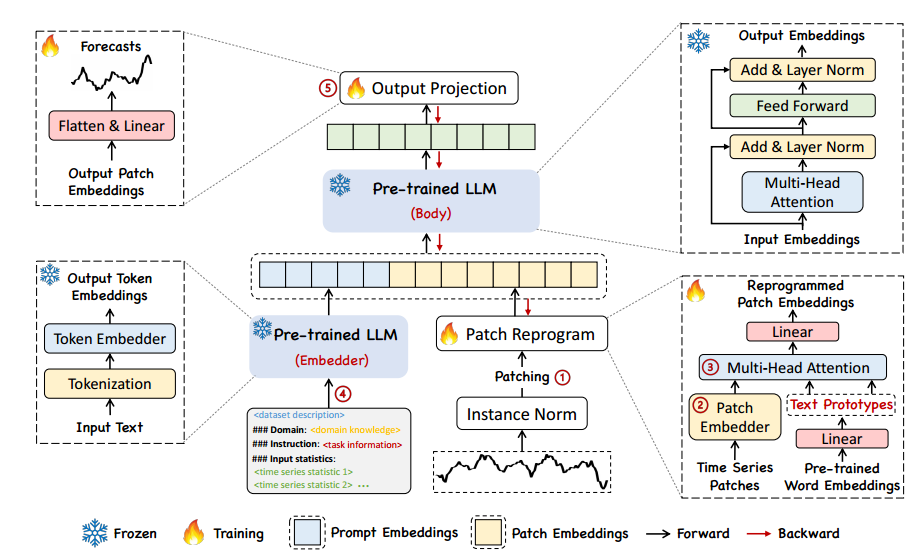
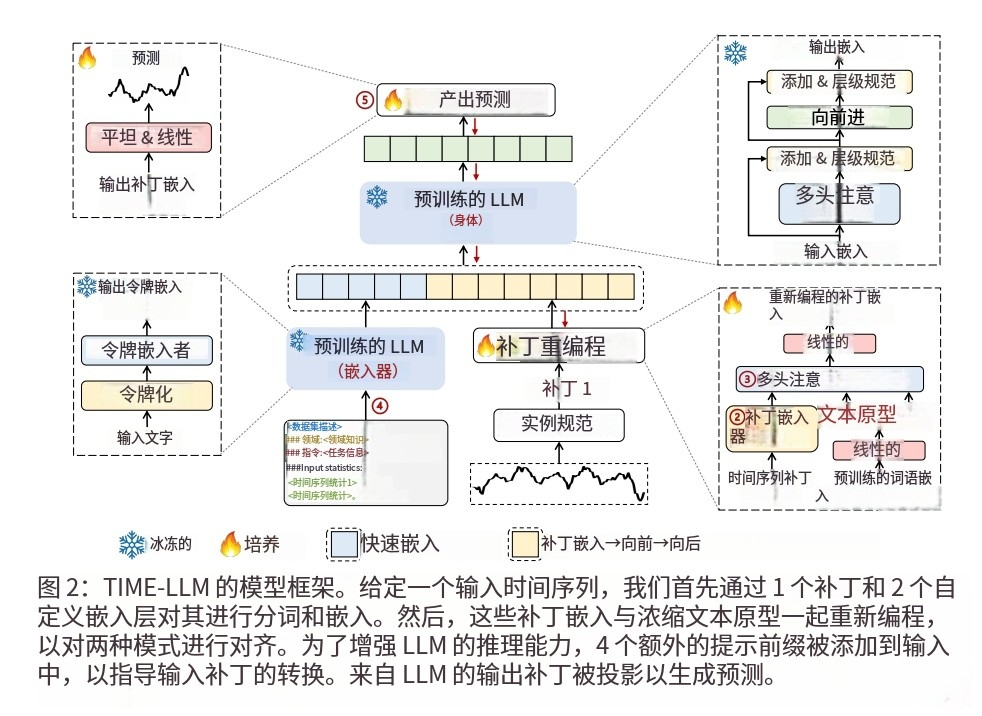
图2:TIME-LLM的模型框架。给定一个输入时间序列,我们首先通过1补丁和2自定义嵌入层对其进行标记和嵌入。3然后用压缩文本原型重新编程这些补丁嵌入,以对齐两种模式。为了增强LLM的推理能力,在输入中增加了4个额外的提示前缀来指导输入补丁的转换。5 .对LLM的输出patch进行投影生成预测。
























 1493
1493

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









