









AI预测相关目录
AI预测流程,包括ETL、算法策略、算法模型、模型评估、可视化等相关内容
最好有基础的python算法预测经验
- EEMD策略及踩坑
- VMD-CNN-LSTM时序预测
- 对双向LSTM等模型添加自注意力机制
- K折叠交叉验证
- optuna超参数优化框架
- 多任务学习-模型融合策略
- Transformer模型及Paddle实现
- 迁移学习在预测任务上的tensoflow2.0实现
- holt提取时序序列特征
- TCN时序预测及tf实现
- 注意力机制/多头注意力机制及其tensorflow实现
- 一文解析AI预测数据工程
- FITS:一个轻量级而又功能强大的时间序列分析模型
- DLinear:未来预测聚合历史信息的最简单网络
- LightGBM:更好更快地用于工业实践集成学习算法
- 面向多特征的AI预测指南
- 大模型时序预测初步调研【20240506】
- Time-LLM :超越了现有时间序列预测模型的学习器
研究背景
Time-LLM 是一个重新编程框架,旨在将大型语言模型(LLMs)重新用于通用的时间序列预测,同时保持基础语言模型的完整性。该框架通过两个关键步骤实现这一目标:首先,将输入的时间序列重新编程为文本原型表示,这种表示对LLM来说更自然;其次,通过声明性提示(例如领域专家知识和任务指令)来增强输入上下文,以指导LLM的推理。Time-LLM 证明了时间序列分析(例如预测)可以被构想为另一种“语言任务”,并且可以由现成的LLM有效地解决。此外,Time-LLM 被展示为一个强大的时间序列学习器,其性能超越了现有的、专门的预测模型。
开源地址:https://github.com/KimMeen/Time-LLM
使用
输入补丁化:首先,将输入的时间序列数据分割成一系列“补丁”(patches),这些补丁是通过在时间序列上滑动窗口来创建的,每个补丁包含了一定数量的时间步长。
重新编程层:对这些补丁进行重新编程,将它们转换成语言模型能够理解的文本原型。这涉及到使用受限的词汇来描述每个补丁,例如将时间序列的一个部分描述为“短期上涨然后稳步下降”。
使用提示前缀增强输入:为了增强语言模型的推理能力,可以添加一个提示前缀(Prompt-as-Prefix, PaP)。这个提示前缀包含了数据集的背景信息、任务说明和输入统计信息,帮助模型更好地理解上下文。
输出投影:将经过重新编程和增强的输入发送到语言模型(LLM)。模型将输出一系列的补丁嵌入,这些嵌入随后需要通过一个线性投影层来生成最终的时间序列预测。
模型训练与预测:在训练阶段,你需要对重新编程层进行训练,以便它能够学习如何将时间序列数据映射到语言任务上。在预测阶段,使用训练好的模型对新的输入时间序列进行预测。
实验与优化:在实践中,可能需要进行多次实验,调整模型参数,如补丁长度、步长、模型层数等,以及优化提示前缀的设计,来提高预测的准确性。
挑战和展望
使用 Time-LLM 进行时间序列预测时,可能会遇到以下挑战以及相应的解决方案:
挑战:数据模态对齐问题
时间序列数据和自然语言数据属于不同的模态,直接对齐存在困难。
解决方案:通过文本原型(Text Prototypes)对输入的时间序列数据进行重编程,使用自然语言来表示时间序列数据的语义信息,实现数据模态的对齐。
挑战:LLM对时间序列数据理解有限
大型语言模型(LLMs)主要是为处理自然语言设计的,对时间序列数据的理解有限。
解决方案:引入Prompt-as-Prefix(PaP)技术,在输入中添加额外的上下文和任务指令,以增强LLM对时间序列数据的推理能力。
挑战:少样本和零样本学习场景中的性能
在只有少量样本或完全没有样本的情况下进行有效预测是一个挑战。
解决方案:Time-LLM在少样本和零样本学习场景中都表现出色,能够利用其强大的模式识别和推理能力进行有效预测。
挑战:模型的泛化能力
需要确保模型在不同时间序列数据集上都能有良好的预测性能。
解决方案:Time-LLM在多个数据集和预测任务中超越了传统的时序模型,显示出良好的泛化能力。
挑战:模型效率
保持模型的高效率,尤其是在资源有限的情况下。
解决方案:Time-LLM在保持出色的模型重编程效率的同时,能够实现更高的性能。
挑战:模型训练和调整
训练Time-LLM并调整其参数以适应特定任务可能需要大量的实验和调整。
解决方案:进行多次实验,调整模型参数,如补丁长度、步长、模型层数等,以及优化提示前缀的设计来提高预测的准确性。
挑战:提示前缀的设计
设计有效的提示前缀对于激活LLM的预测能力至关重要,但也是一个挑战。
解决方案:确定构建有效提示的三个关键组件:数据集上下文、任务指令、统计描述,以充分激活LLM在时序任务上的处理能力。
挑战:长期预测的精确性
在长期预测任务中,LLM处理高精度数字时可能表现出较低的敏感性。
解决方案:通过设计合适的提示和后处理策略,提高长期预测的精确性
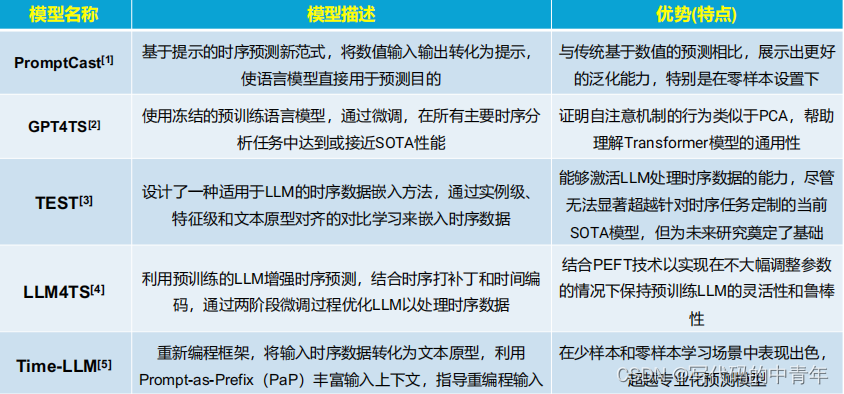
其他大模型时序预测工作
















 312
312











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











