







文章目录

在优化算法的不断演进中,受自然界生物行为启发的算法逐渐崭露头角,我们之前了解过 蚁群算法、 金豺算法等,接下来介绍一种于2024年M Abdel-Basset等人提出了冠豪猪优化算法(Crested Porcupine Optimizer, CPO),参考文章《 Crested Porcupine Optimizer: A new nature-inspired metaheuristic》,我来讲解以下冠豪猪优化算法的原理及其应用
冠豪猪优化算法原理
冠豪猪从低到高的防御机制依次为视觉、听觉、气味和物理攻击,前两者对应 CPO 的探索行为,后两者对应开发行为。CPO 引入循环种群缩减技术,模拟部分冠豪猪受威胁才激活防御机制的情况,以提升收敛速度和种群多样性。

防御机制
以下四种防御机制分别对应图中的A B C D四个区域
- 视觉防御:当冠豪猪察觉到危险,它会竖起长而锋利的刺,让自己看起来体型更大,以此吓退捕食者。
- 声音防御:冠豪猪会发出各种声音,如咆哮、跺脚、磨牙等,随着捕食者靠近,声音强度会增加。
- 气味防御:若视觉和声音防御未能奏效,冠豪猪会从背部腺体分泌出恶臭的化学气味,以此驱赶捕食者。
- 物理攻击防御:这是冠豪猪最强大的防御手段,当其他策略都失败时,它会用背上短而粗的刺向后撞击攻击者。
CPO算法的数学模型与实现
初始化阶段
CPO算法在开始时,会在搜索空间内随机初始化一组个体(候选解)。每个个体的维度根据问题的要求在一定范围内随机生成,公式为:
X ⃗ i = L ⃗ + r ⃗ × ( U ⃗ − L ⃗ ) ∣ i = 1 , 2... , N \vec{X}_{i}=\vec{L}+\vec{r} \times(\vec{U}-\vec{L}) | i=1,2 ..., N Xi=L+r×(U−L)∣i=1,2...,N
其中 N N N是个体数量, X ⃗ i \vec{X}_{i} Xi是第 i i i个候选解, L ⃗ \vec{L} L和 U ⃗ \vec{U} U分别是搜索范围的下限和上限, r ⃗ \vec{r} r是在 0 0 0到 1 1 1之间随机生成的向量。
循环种群缩减技术
CPO算法引入了循环种群缩减技术(Cyclic Population Reduction,CPR),该技术模拟了只有部分冠豪猪在受到威胁时才会激活防御机制的现象。在优化过程中,通过调整种群大小来平衡探索和开发的能力。种群大小的更新公式为: N = N m i n + ( N ′ − N m i n ) × ( 1 − ( t % T m a x T T m a x T ) ) N=N_{min }+\left(N'-N_{min }\right) \times\left(1-\left(\frac{t \% \frac{T_{max }}{T}}{\frac{T_{max }}{T}}\right)\right) N=Nmin+(N′−Nmin)×(1−(TTmaxt%TTmax)) 其中, T T T是循环次数, t t t是当前迭代次数, T m a x T_{max } Tmax是最大迭代次数, N m i n N_{min } Nmin是最小种群大小, N ′ N' N′是最大种群大小。
取
T
m
a
x
=
120
T_{max }=120
Tmax=120,
N
m
i
n
=
40
N_{min }=40
Nmin=40,
N
′
=
100
N'=100
N′=100,如下图分别为
T
=
2
T=2
T=2、
T
=
3
T=3
T=3、
T
=
5
T=5
T=5的种群数量循环

探索阶段
- 第一种防御策略:模拟冠豪猪竖起刺的行为,通过生成基于正态分布的随机值来决定捕食者(在算法中可理解为搜索方向)是靠近还是远离冠豪猪(当前解)。当随机值属于 [ − 1 , 1 ] [-1,1] [−1,1]时,捕食者靠近;否则,远离。 x i t + 1 → = x i t → + τ 1 × ∣ 2 × τ 2 × x C P t → − y i t → ∣ \overrightarrow{x_{i}^{t+1}}=\overrightarrow{x_{i}^{t}}+\tau_{1} \times\left|2 × \tau_{2} × \overrightarrow{x_{C P}^{t}}-\overrightarrow{y_{i}^{t}}\right| xit+1=xit+τ1× 2×τ2×xCPt−yit 其中, x C P t → \overrightarrow{x_{C P}^{t}} xCPt是当前最优解, τ 1 \tau_{1} τ1是基于正态分布的随机数, τ 2 \tau_{2} τ2是在 [ 0 , 1 ] [0, 1] [0,1]区间的随机值, y i t → \overrightarrow{y_{i}^{t}} yit是代表捕食者位置的向量,其更新公式为 y i t → = x i t ⃗ + x r t ⃗ 2 \overrightarrow{y_{i}^{t}} = \frac{\vec{x_{i}^{t}} + \vec{x_{r}^{t}}}{2} yit=2xit+xrt 其中, r r r为 [ 1 , N ] [1,N] [1,N]的随机数

- 第二种防御策略:模拟冠豪猪发出声音的行为,通过以下公式更新解的位置:
x
i
t
+
1
→
=
(
1
−
U
1
→
)
×
x
i
t
→
+
U
1
→
×
(
y
→
+
τ
3
×
(
x
r
1
r
→
−
x
r
2
t
→
)
)
\overrightarrow{x_{i}^{t+1}}=\left(1-\overrightarrow{U_{1}}\right) × \overrightarrow{x_{i}^{t}}+\overrightarrow{U_{1}} \times\left(\overrightarrow{y}+\tau_{3} \times\left(\overrightarrow{x_{r 1}^{r}}-\overrightarrow{x_{r 2}^{t}}\right)\right)
xit+1=(1−U1)×xit+U1×(y+τ3×(xr1r−xr2t)) 其中,
r
1
r1
r1和
r
2
r2
r2是在
[
1
,
N
]
[1, N]
[1,N]之间的随机整数,
τ
3
\tau_{3}
τ3是在
[
0
,
1
]
[0, 1]
[0,1]区间的随机值,
U
1
→
\overrightarrow{U_{1}}
U1是包含
0
0
0和
1
1
1的随机二进制向量,用于模拟声音对捕食者行为的不同影响。
此公式模拟了冠豪猪发出的声音对捕食者与自身距离的影响。这种影响分为三种情况:
\quad (1) 声音较弱时,捕食者继续向冠豪猪移动;
\quad (2) 声音稍大时,捕食者可能会原地不动;
\quad (3) 声音很大时,捕食者因恐惧而远离。
开发阶段
-
第三种防御策略:模拟冠豪猪分泌气味进行防御的行为,通过以下公式更新解的位置: x i t + 1 → = ( 1 − U 1 → ) × x i ′ → + U 1 → × ( x 1 ′ → + S i t × ( x r 2 ′ → − x r 1 ′ → ) − τ 3 × δ → × γ t × S i t ) \overrightarrow{x_{i}^{t+1}}= \left(1-\overrightarrow{U_{1}}\right) × \overrightarrow{x_{i}'}+\overrightarrow{U_{1}} \times\left(\overrightarrow{x_{1}'}+S_{i}^{t} \times\left(\overrightarrow{x_{r_{2}}'}-\overrightarrow{x_{r_{1}}'}\right)-\tau_{3} × \overrightarrow{\delta} × \gamma_{t} × S_{i}^t\right) xit+1=(1−U1)×xi′+U1×(x1′+Sit×(xr2′−xr1′)−τ3×δ×γt×Sit)其中,涉及多个参数,如 r 3 r_{3} r3是 [ 1 , N ] [1, N] [1,N]之间的随机整数, δ → \overrightarrow{\delta} δ控制搜索方向, γ t \gamma_{t} γt是防御因子, S i t S_{i}^{t} Sit是气味扩散因子。气味扩散因子的大小决定了开发的范围,小的值使开发更靠近随机选择的解,大的值则使开发远离该解。
-
r 3 r_{3} r3是在 [ 1 , N ] [1, N] [1,N]之间的随机数,用于引入随机性,帮助算法在搜索空间中探索不同的区域。
-
δ → \overrightarrow{\delta} δ是用于控制搜索方向的参数 δ → = { + 1 , if r a n d → ≤ 0.5 − 1 , Else \overrightarrow{\delta}=\begin{cases}+1, & \text{if } \overrightarrow{rand} \leq 0.5 \\ -1, & \text{Else} \end{cases} δ={+1,−1,if rand≤0.5Else r a n d → \overrightarrow{rand} rand是一个在 0 0 0到 1 1 1之间随机生成的数值组成的向量,它决定了 δ → \overrightarrow{\delta} δ的值,进而影响搜索方向。
-
x i t → \overrightarrow{x_{i}^{t}} xit表示第 i i i个个体在迭代 t t t时的位置,是算法当前正在更新的解的位置。
-
γ t \gamma_{t} γt是防御因子 γ t = 2 × r a n d × ( 1 − t t m a x ) t t m a x \gamma_{t}=2×rand×(1 - \frac{t}{t_{max}})^{\frac{t}{t_{max}}} γt=2×rand×(1−tmaxt)tmaxt 其中 r a n d rand rand是一个在 [ 0 , 1 ] [0, 1] [0,1]区间的随机生成的向量, t t t是当前迭代次数, t m a x t_{max} tmax是最大迭代次数。 γ t \gamma_{t} γt的值会随着迭代次数的变化而变化,用于调整算法的搜索强度和方向。

-
τ 3 \tau_{3} τ3是一个在 [ 0 , 1 ] [0, 1] [0,1]区间内的随机值,为算法的更新过程引入更多的随机性。
-
S i t S_{i}^{t} Sit是 气味扩散因子,由公式 S t i = exp ( f ( x t i ) ∑ k = 1 N f ( x t k ) + ϵ ) S_{t}^{i}=\exp\left(\frac{f(x_{t}^{i})}{\sum_{k = 1}^{N}f(x_{t}^{k})+\epsilon}\right) Sti=exp(∑k=1Nf(xtk)+ϵf(xti)) 其中, f ( x t i ) f(x_{t}^{i}) f(xti)代表第 i i i个个体在迭代 t t t时的目标函数值, ϵ \epsilon ϵ是一个很小的值,用于避免分母为零的情况, N N N是种群大小。 S i t S_{i}^{t} Sit的值反映了个体在种群中的相对适应度,其取值范围在 0.3 0.3 0.3到 2.6 2.6 2.6之间,不同的值对应不同的气味扩散率,从而影响算法的开发行为。
-
U 1 → \overrightarrow{U_{1}} U1向量用于模拟该策略中可能出现的三种场景:当 U 1 → \overrightarrow{U_{1}} U1等于 0 0 0时,意味着冠豪猪停止气味扩散,因为捕食者因恐惧停止移动,此时捕食者与冠豪猪的距离保持不变;当 U 1 → \overrightarrow{U_{1}} U1等于 1 1 1时,表示冠豪猪会显著地释放气味,因为捕食者已经靠近;当 U 1 → \overrightarrow{U_{1}} U1是 0 0 0和 1 1 1的组合时,捕食者会与冠豪猪保持安全距离,此时不需要大量释放气味 。
-
-
第四种防御策略:模拟冠豪猪的物理攻击行为,当捕食者离得很近时,冠豪猪会用短而厚的刺攻击捕食者。在物理攻击中,两个身体强烈融合,代表一维的非弹性碰撞。通过以下公式更新解的位置: x i t + 1 → = x C P t → + ( α ( 1 − τ 4 ) + τ 4 ) × ( δ × x C P t → − x i t → ) − τ 5 × δ × γ t × F → i t \overrightarrow{x_{i}^{t+1}}=\overrightarrow{x_{C P}^{t}}+\left(\alpha\left(1-\tau_{4}\right)+\tau_{4}\right) \times\left(\delta × \overrightarrow{x_{C P}^{t}}-\overrightarrow{x_{i}^{t}}\right)-\tau_{5} × \delta × \gamma_{t} × \overrightarrow{F}_{i}^{t} xit+1=xCPt+(α(1−τ4)+τ4)×(δ×xCPt−xit)−τ5×δ×γt×Fit
其中,- x C P t → \overrightarrow{x_{CP}^{t}} xCPt是当前获得的最佳解,代表冠豪猪的位置;
- x i t → \overrightarrow{x_{i}^{t}} xit是第 i i i个个体在迭代 t t t时的位置,代表捕食者的位置;
- α \alpha α是收敛速度因子;
- τ 4 \tau_{4} τ4和 τ 5 \tau_{5} τ5是在 [ 0 , 1 ] [0, 1] [0,1]区间的随机值;
-
F
i
t
→
\overrightarrow{F_{i}^{t}}
Fit是冠豪猪对第
i
i
i个捕食者的平均作用力 ,由物理中的非弹性碰撞定律计算得出,公式为:
F i t → = τ 6 → × m i × ( v i t + 1 → − v i t → ) Δ t m i = e f ( x i t → ) ∑ k = 1 N ( x k t → ) + ϵ v i t → = x i t → v i t + 1 → = x r t → \begin{gathered} \overrightarrow{F_{i}^t}=\overrightarrow{\tau_{6}} × \frac{m_{i} \times\left(\overrightarrow{v_{i}^{t+1}}-\overrightarrow{v_{i}^{t}}\right)}{\Delta t}\\ m_{i}=e^{\frac{f\left(\overrightarrow{x_{i}^t}\right)}{\sum_{k=1}^{N}\left(\overrightarrow{x_{k}^t}\right)+\epsilon}}\\ \overrightarrow{v_{i}^{t}}=\overrightarrow{x_{i}^t}\\ \overrightarrow{v_{i}^{t+1}}=\overrightarrow{x_{r}^{t}} \end{gathered} Fit=τ6×Δtmi×(vit+1−vit)mi=e∑k=1N(xkt)+ϵf(xit)vit=xitvit+1=xrt
其中, m t i m_{t}^{i} mti是第 i i i个个体(捕食者)在迭代 t t t时的质量,它通过目标函数值 f ( ⋅ ) f(\cdot) f(⋅)来计算, ϵ \epsilon ϵ是一个很小的值,用于避免分母为零; v i t + 1 → \overrightarrow{v_{i}^{t+1}} vit+1是第 i i i个个体在下一次迭代 t + 1 t + 1 t+1时的最终速度,它是基于从当前种群中随机选择的一个解来赋值的; v i t → \overrightarrow{v_{i}^{t}} vit是第 i i i个个体在迭代 t t t时的初始速度,这里直接等于当前个体的位置 x i t → \overrightarrow{x_{i}^t} xit; Δ t \Delta t Δt是当前迭代次数; τ 6 → \overrightarrow{\tau_{6}} τ6是在 [ 0 , 1 ] [0, 1] [0,1]区间的随机值的组成的向量。
在原始公式中,平均作用力 F i t → \overrightarrow{F_{i}^{t}} Fit的计算是通过将分子除以当前迭代次数 Δ t \Delta t Δt,随着优化过程中迭代次数线性增加,该平均作用力的影响会逐渐减小。如图10所示,这种小的值对CPO算法的性能可能不利,因为它可能无法帮助算法充分探索当前最优解周围的不同区域以找到更好的解。

为解决这一问题,作者对公式进行了更新,删除了分子,仅依赖分母,得到新公式:
F i t ⃗ = τ 6 ⃗ × m i × ( v i t + 1 ⃗ − v i t ⃗ ) \vec{F_{i}^{t}}=\vec{\tau_{6}} × m_{i} \times\left(\vec{v_{i}^{t+1}}-\vec{v_{i}^{t}}\right) Fit=τ6×mi×(vit+1−vit)
这种调整有助于在搜索空间中创建更广泛的值范围,使算法能够更全面地检查当前最优解周围的区域,加快向接近最优解的收敛速度。如图11所示,通过这种方式,算法的开发阶段能够更集中地在当前最优解附近的区域进行搜索,椭圆区域代表了搜索区域在搜索空间内的集中分布,从而提高算法找到更优解的能力。

(注:这里有一根很奇怪的点,第三阶段的气味扩散因子 S i t S_{i}^{t} Sit和第四阶段的质量 m i m_i mi,使用的公式是相同的,但是一个使用exp(·),另一个使用 e ( ⋅ ) e^{(·)} e(⋅),同时使用的目标函数也都是 f ( ⋅ ) f(·) f(⋅)的形式,没有区分,可能会产生误解)
算法流程
CPO算法在每一代中,根据随机生成的数值决定采用探索阶段还是开发阶段的策略来更新解的位置。更新后的解通过目标函数进行评估,以判断是否达到最优解或满足终止条件。整个算法流程不断迭代,直到达到最大函数评估次数或满足其他终止条件为止。文章中给出伪代码

代码
文章中作者给出了代码来源https://drive.mathworks.com/sharing/24c48ec7-bfd5-4c22-9805-42b7c394c691/
代码中使用了IEEE Congress on Evolutionary Computation (CEC )会议发布的测试函数套件(如 CEC 2014、CEC 2017、CEC 2020、CEC 2022)为优化算法的性能评估提供了标准化的工具。
main.m 主程序
- 初始化参数,设置种群数量130,最大迭代次数 T m a x = 1000000 T_{max} = 1000000 Tmax=1000000
%%
clear all
clc
CP_no=130; % Number of search agents (crested porcupines)
Tmax=1000000; % Maximum number of Function evaluations
- 设置算法独立运行30次和Fun_id 30组参数选择(需要多次独立运行以评估算法的稳定性和性能)
RUN_NO=30; %% Number of independent runs
Fun_id=[1,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16,17,18,19,20,21,22,23,24,25,26,27,28,29,30];
- 指定测试函数CEC 2017
fhd=str2func('cec17_func'); %%Default Benchmark
cec=2;
if cec==1 %% CEC-2014
fhd=str2func('cec14_func');
benchmarksType='cec14_func';
elseif cec==2 %% CEC-2017
fhd=str2func('cec17_func');
benchmarksType='cec17_func';
elseif cec==3 %% CEC-2020
fhd=str2func('cec20_func');
benchmarksType='cec20_func';
elseif cec==4 %% CEC-2022
fhd=str2func('cec22_func');
benchmarksType='cec22_func';
end
- 针对30组参数,每组运行30次(使用parfor函数多进程加速循环运行),保存Convergence_curve和fitness,并对每组参数绘制30次运行平均收敛曲线
for i=1:30 % 针对30组参数
tic;
if cec==2 && i==2
continue;
elseif cec==3 && i>10
return
elseif cec==4 && i>12
return
end
parfor j=1:RUN_NO % 每组运行30次
[lb,ub,dim]=Get_Functions_detailsCEC(Fun_id(i)); % 获取当前参数
fobj=Fun_id(i);
[Best_score,Best_pos,Convergence_curve(j,:)]=CPO(CP_no,Tmax,ub,lb,dim,fobj,fhd); % 使用CPO算法
fitness(1,j)=Best_score; % 保存适应度参数
end
time=toc;
fprintf(['benchmark \t',num2str(cec),'\t','Function_ID\t',num2str(i),'\tAverage Fitness:',num2str(mean(fitness(1,:)),20),'\tAverage Time:',num2str(time/RUN_NO,5),'\n']);
%% Drawing Convergence Curve %% 绘制收敛曲线
figure(i)
h=semilogy(mean(Convergence_curve),'-<','MarkerSize',8,'LineWidth',1.5);
h.MarkerIndices = 1000:20000:Tmax;
xlabel('Function Evaluation');
ylabel('Best Fitness obtained so-far');
axis tight
grid off
box on
legend({'CPO'});
clear Convergence_curve;
end
以第一组参数为例,展示收敛曲线结果

Get_Functions_detailsCEC.m 函数
函数包含了论文中表1、表2和表3中基准测试函数的全部信息和实现
lb是下界:lb=[lb_1, lb_2, ..., lb_d]ub是上界:ub=[ub_1, ub_2, ..., ub_d]dim是变量的数量(问题的维度)
function [lb,ub,dim] = Get_Functions_detailsCEC(F)
函数中包含30组参数,除第11组外,其余均一样
CPO.m 冠豪猪优化算法主体函数
该函数展示了文章中讲解的CPO算法是如何运行的
- 函数声明
function [Gb_Fit, Gb_Sol, Conv_curve] = CPO(Pop_size, Tmax, ub, lb, dim, fobj, fhd)
-
输入
Pop_size:种群大小Tmax:最大迭代次数ub:变量的上界lb:变量的下界dim:问题的维度fobj:目标函数fhd:测试函数CEC
-
输出
Gb_Fit:全局最优解的适应度值Gb_Sol:全局最优解Conv_curve:收敛曲线
- 定义输出参数的类型和大小
Gb_Fit=zeros(1,dim); % A vector to include the best-so-far solution
Gb_Sol=inf; % A Scalar variable to include the best-so-far score
Conv_curve=zeros(1,Tmax);
- 给定控制参数
N=Pop_size; %% Is the initial population size. 初始种群数目
N_min=120; %% Is the minimum population size. 最小种群数目
T=2; %% The number of cycles % 种群数量循环次数
alpha=0.2; %% The convergence rate % 收敛率
Tf=0.8; %% The percentage of the tradeoff between the third and fourth defense mechanisms 第三种和第四种防御机制之间的权衡比例
- 初始化冠豪猪的初始位置
X=initialization(Pop_size,dim,ub,lb); % Initialize the positions of crested porcupines
t=0; %% Function evaluation counter
- 针对初始位置,求解每一个冠豪猪的对cec2017的适应度,并寻找适应度最小的个体Gb_sol
for i=1:Pop_size
%% Test suites of CEC-2014, CEC-2017, CEC-2020, and CEC-2022
fitness(i)=feval(fhd, X(i,:)',fobj);
end
% 寻找最小适应Gb_Fit及其对应的个体Gb_sol
[Gb_Fit,index]=min(fitness);
Gb_Sol=X(index,:);
%% A new array to store the personal best position for each crested porcupine
Xp=X;
opt=fobj*100; %% Well-known optimal fitness 最优适应度
- 进行CPO优化求解
我会按照自己的理解将代码中变量名和文章中的公式符号尽量对应起来-
判定条件:迭代次数 t t t超出最大迭代次数 T m a x T_{max} Tmax 或者 当前最小适应Gb_Fit等于最优适应度opt,否则就循环进行CPO优化

-
代码中变量 r2 对应 第四步物理防御策略中 τ 4 \tau_4 τ4,是 [ 0 , 1 ] [0,1] [0,1]之间的随机值,各次迭代间r2值随机互不相同,但一次迭代中针对每一只个体保持r2参数相同

-
针对每一只冠豪猪个体进行CPO优化,更新位置信息,具体步骤如下
- 通过随机值 rand < rand之间比较,判断当前是 探索阶段 还是 开发阶段
-
探索阶段——依旧是通过rand < rand判断是 第一防御策略 还是 第二防御策略

- 第一防御策略
- 首先生成捕食者位置 y 对应符号 y i t → \overrightarrow{y_i^t} yit,使用公式 y i t → = x i t ⃗ + x r t ⃗ 2 \overrightarrow{y_{i}^{t}} = \frac{\vec{x_{i}^{t}} + \vec{x_{r}^{t}}}{2} yit=2xit+xrt
- 而后更新第i个冠豪猪位置 X(i,:) 对应符号
x
i
t
→
\overrightarrow{x_i^t}
xit,使用公式
x
i
t
+
1
→
=
x
i
t
→
+
τ
1
×
∣
2
×
τ
2
×
x
C
P
t
→
−
y
i
t
→
∣
\overrightarrow{x_{i}^{t+1}}=\overrightarrow{x_{i}^{t}}+\tau_{1} \times\left|2 × \tau_{2} × \overrightarrow{x_{C P}^{t}}-\overrightarrow{y_{i}^{t}}\right|
xit+1=xit+τ1×
2×τ2×xCPt−yit
符号
τ
1
\tau_1
τ1和
τ
2
\tau_2
τ2分别使用函数randn和rand代替,符号
x
C
P
t
→
\overrightarrow{x_{C P}^{t}}
xCPt对应Gb_sol。
但是代码中的更新方式 顺序依赖性 有种弊端:就是先更新第一只冠豪猪位置,然后使用已经更新的第一冠豪猪位置来更新第二只,而不是使用原来旧的冠豪猪位置来更新
- 第二防御策略
- 同样是首先生成捕食者位置 y 对应符号 y i t → \overrightarrow{y_i^t} yit
- 而后更新第i个冠豪猪位置 X(i,:) 对应符号 x i t → \overrightarrow{x_i^t} xit,使用公式和文章中不同 x i t + 1 → = U 1 → × x i t → + ( 1 − U 1 → ) × ( y → + τ 3 × ( x r 1 r → − x r 2 t → ) ) \overrightarrow{x_{i}^{t+1}}=\overrightarrow{U_{1}} × \overrightarrow{x_{i}^{t}}+ \left(1-\overrightarrow{U_{1}}\right)\times\left(\overrightarrow{y}+\tau_{3} \times\left(\overrightarrow{x_{r 1}^{r}}-\overrightarrow{x_{r 2}^{t}}\right)\right) xit+1=U1×xit+(1−U1)×(y+τ3×(xr1r−xr2t)) 程序中将 U 1 → \overrightarrow{U_1} U1和 ( 1 − U 1 → ) (1-\overrightarrow{U_1}) (1−U1)的位置互换了, U 1 → \overrightarrow{U_1} U1本身是binary随机向量,所以互换后和原式作用基本相同,丝毫不影响程序运行,但对应文章中 U 1 → \overrightarrow{U_1} U1取值0或1的含义解释可能不同
- 第一防御策略
-
开发阶段——首先生成捕食者位置 Yt 对应符号 y i t → \overrightarrow{y_i^t} yit,而后使用文章中公式(8)生成U2对应符号 δ → \overrightarrow{\delta} δ,之后计算S同时代表第三步中 τ 3 × y i t → \tau_3\times\overrightarrow{y_i^t} τ3×yit和第四步中 τ 5 × y i t → \tau_5\times\overrightarrow{y_i^t} τ5×yit。
最后依旧是通过rand < Tf 判断是 第三防御策略 还是 第四防御策略,这里的变量Tf取值为0.8,在给定控制参数步骤中设置
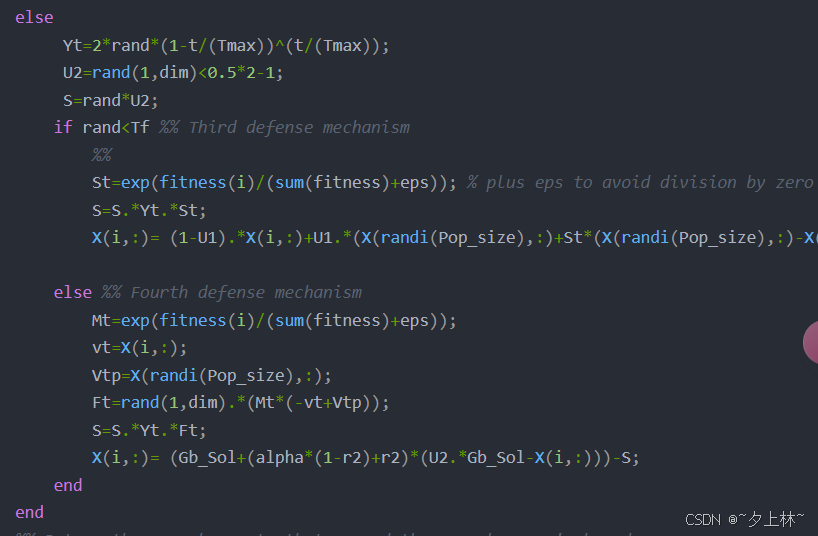
- 第三防御策略
- 计算St代表符号 S i t S_i^t Sit气味扩散因子 ,使用公式 S t i = exp ( f ( x t i ) ∑ k = 1 N f ( x t k ) + ϵ ) S_{t}^{i}=\exp\left(\frac{f(x_{t}^{i})}{\sum_{k = 1}^{N}f(x_{t}^{k})+\epsilon}\right) Sti=exp(∑k=1Nf(xtk)+ϵf(xti)) 此时的 f ( ⋅ ) f(\cdot) f(⋅)是原始设定的适应度函数fintness。
- 更新更新第i个冠豪猪位置 X(i,:) 对应符号
x
i
t
→
\overrightarrow{x_i^t}
xit,这里代码有错误,直接使用Yt来充当符号
γ
t
\gamma_t
γt,这是一个很显著的错误,在第四防御策略中也出现了这样的错误。出错位置如下

- 第四防御策略
- 变量Mt代表符号 m i m_i mi
- 变量vt代表符号 v i t → \overrightarrow{v_i^t} vit
- 变量Vtp代表符号 v i t + 1 → \overrightarrow{v_i^{t+1}} vit+1
- 变量Ft代表符号 F i t → \overrightarrow{F_i^t} Fit
- 更新更新第i个冠豪猪位置 X(i,:) 对应符号 x i t → \overrightarrow{x_i^t} xit,这里代码有错误,同样也直接使用Yt来充当符号 γ t \gamma_t γt
- 第三防御策略
-
- 通过随机值 rand < rand之间比较,判断当前是 探索阶段 还是 开发阶段
-
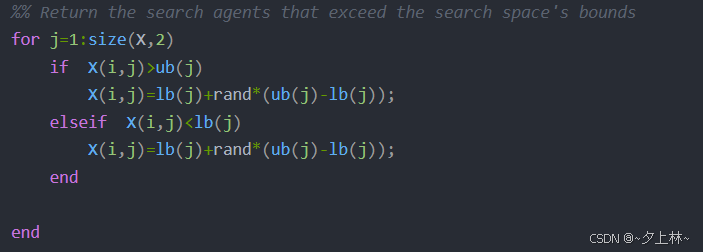
判断位置更新后是否超出范围[lb,ub],如若超出则随机生成新位置
-
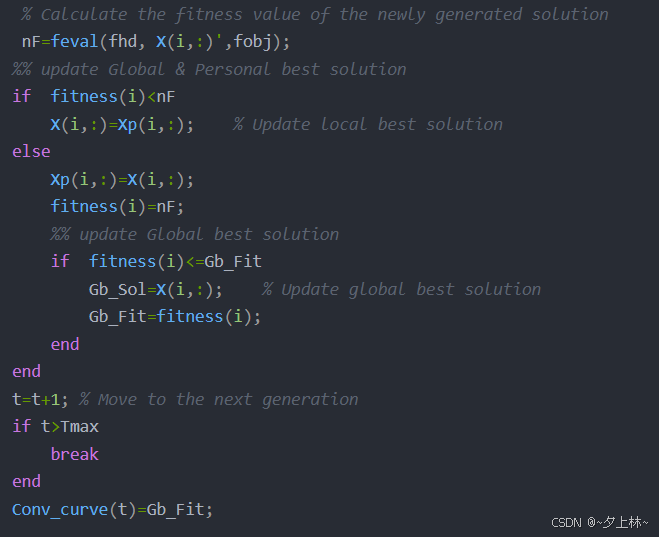
更新全局和局部最优解,并保存最小适应度fitness作为收敛曲线
-
CPO进行路径规划
绑定资源中有代码,之后有时间再来对路径规划代码详细介绍


参考资料:
[1] Mohamed Abdel-Basset, Reda Mohamed, Mohamed Abouhawwash. Crested Porcupine Optimizer: A new nature-inspired metaheuristic[J]. Knowledge-Based Systems, 2024, 284: 111257.

















 4167
4167

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









