







1.背景
2024年,M Abdel-Basset等人受到冠豪猪防御行为启发,提出了冠豪猪优化算法(Crested Porcupine Optimizer, CPO)。


2.算法原理
2.1算法思想
CPO使用四种不同的保护机制:视觉、声音、气味和物理攻击。第一和第二防御策略(视觉和声音)反映了CPO的探索行为,而第三和第四防御策略(气味和物理攻击)反映了CPO的开发行为。

2.2算法过程
CPO提出一种新的方法:循环种群减少技术(CPR),以保持种群的多样性,同时加快收敛速度。这一策略模拟了并非所有CPs都激活防御机制,而只有那些受到威胁的CPs才会激活防御机制。在优化过程中,该方法从种群中取出一些CPs,以加快收敛速度,并将它们重新回到种群中,以提高多样性,避免陷入局部极小值:
N
=
N
m
i
n
+
(
N
′
−
N
m
i
n
)
×
(
1
−
(
t
%
T
m
a
x
T
T
m
a
x
T
)
)
(1)
N=N_{min}+(N^{'}-N_{min})\times\left(1-\left(\frac{t \% \frac{T_{max}}{T}}{\frac{T_{max}}{T}}\right)\right)\tag{1}
N=Nmin+(N′−Nmin)×(1−(TTmaxt%TTmax))(1)
其中,T为决定循环次数的变量,t为当前函数求值,Tmax为函数求值的最大次数,Nmin是新生成种群中最小的个体数。
探索阶段
根据CP的防御行为,当捕食者距离较远时,CP有两种防御策略,即视觉策略和声音策略。这些策略是指对不同区域进行调查,致力于全局探索:
x
i
t
+
1
→
=
x
i
t
→
+
τ
1
×
∣
2
×
τ
2
×
x
C
P
t
→
−
y
i
t
→
∣
(2)
\overrightarrow{x_i^{t+1}}=\overrightarrow{x_i^t}+\tau_1\times\left|2\times\tau_2\times\overrightarrow{x_{CP}^t}-\overrightarrow{y_i^t}\right|\tag{2}
xit+1=xit+τ1×
2×τ2×xCPt−yit
(2)
其中,xcp为最佳CP位置,yt为当前CP与随机CP之间生成的向量:
y
i
t
→
=
x
i
t
→
+
x
r
t
→
2
(3)
\overrightarrow{y_i^t} = \frac{\overrightarrow{x_i^t} + \overrightarrow{x_r^t}}{2}\tag{3}
yit=2xit+xrt(3)
CP使用声音方法制造噪音并威胁捕食者。当捕食者靠近时,CP的声音变得更大:
x
i
t
+
1
→
=
(
1
−
U
1
→
)
×
x
i
t
→
+
U
1
→
×
(
y
→
+
τ
3
×
(
x
r
1
t
→
−
x
r
2
t
→
)
)
(4)
\overrightarrow{x_i^{t+1}}=\left(1-\overrightarrow{U_1}\right)\times\overrightarrow{x_i^t}+\overrightarrow{U_1}\times\left(\overrightarrow{y}+\tau_3\times\left(\overrightarrow{x_{r1}^t}-\overrightarrow{x_{r2}^t}\right)\right)\tag{4}
xit+1=(1−U1)×xit+U1×(y+τ3×(xr1t−xr2t))(4)
开发阶段
根据CP的防御行为,当捕食者靠近时,CP有两种防御策略,即气味攻击策略和物理攻击策略。这些策略是指对有潜力的区域进行开发,致力于(局部)开发搜索。气味攻击阶段,CP会分泌一种恶臭,在周围区域传播,以防止捕食者接近它:
x
i
t
+
1
‾
=
(
1
−
U
1
→
)
×
x
i
t
→
+
U
1
→
×
(
x
r
1
′
→
+
S
i
′
×
(
x
r
2
′
→
−
x
r
3
′
→
)
−
τ
3
×
δ
→
×
γ
t
×
S
i
′
)
(5)
\begin{aligned} \overline{{x_{i}^{t+1}}} =\left(1-\overrightarrow{U_{1}}\right)\times\overrightarrow{x_{i}^{t}}+\overrightarrow{U_{1}} \times\left(\overrightarrow{x_{r_{1}}^{\prime}}+S_{i}^{\prime}\times\left(\overrightarrow{x_{r_{2}}^{\prime}}-\overrightarrow{x_{r_{3}}^{\prime}}\right)-\tau_{3}\times\overrightarrow{\delta} \times\gamma_{t}\times S_{i}^{\prime}\right) \end{aligned}\tag{5}
xit+1=(1−U1)×xit+U1×(xr1′+Si′×(xr2′−xr3′)−τ3×δ×γt×Si′)(5)
其中,δ为控制搜索方向的参数,γt为防御因子,St为气味扩散因子:
δ
→
=
{
+
1
,
i
f
r
a
n
d
→
≤
0.5
−
1
,
E
l
s
e
γ
t
=
2
×
r
a
n
d
×
(
1
−
t
t
m
a
x
)
t
t
m
a
x
S
t
i
=
exp
(
f
(
x
t
i
)
∑
k
=
1
N
f
(
x
t
k
)
+
ϵ
)
(6)
\left.\begin{aligned}&\overrightarrow{\delta}=\left\{\begin{array}{c}+1, if \overrightarrow{rand}\leq0.5\\-1, Else\end{array}\right.\\&\gamma_{t}=2 \times rand\times\left(1-\frac{t}{t_{max}}\right)^{\frac{t}{tmax}}\\&S_{t}^{i}=\exp\left(\frac{f\left(x_{t}^{i}\right)}{\sum_{k=1}^{N}f\left(x_{t}^{k}\right)+\epsilon}\right)\end{aligned}\right.\tag{6}
δ={+1,ifrand≤0.5−1,Elseγt=2×rand×(1−tmaxt)tmaxtSti=exp(∑k=1Nf(xtk)+ϵf(xti))(6)
物理攻击阶段,当捕食者离它很近时,CP会用短而厚的羽毛攻击它:
x
i
t
+
1
→
=
x
C
P
t
→
+
(
α
(
1
−
τ
4
)
+
τ
4
)
×
(
δ
×
x
C
P
t
→
−
x
i
t
→
)
−
τ
5
×
δ
×
γ
t
×
F
i
t
→
(7)
\overrightarrow{x_i^{t+1}}=\overrightarrow{x_{CP}^t}+(\alpha(1-\tau_4)+\tau_4)\times\left(\delta\times\overrightarrow{x_{CP}^t}-\overrightarrow{x_i^t}\right)-\tau_5\times\delta \times\gamma_t\times\overrightarrow{F_i^t}\tag{7}
xit+1=xCPt+(α(1−τ4)+τ4)×(δ×xCPt−xit)−τ5×δ×γt×Fit(7)
其中,α为收敛速度因子。
伪代码

3.结果展示
使用测试框架,测试CPO性能 一键run.m
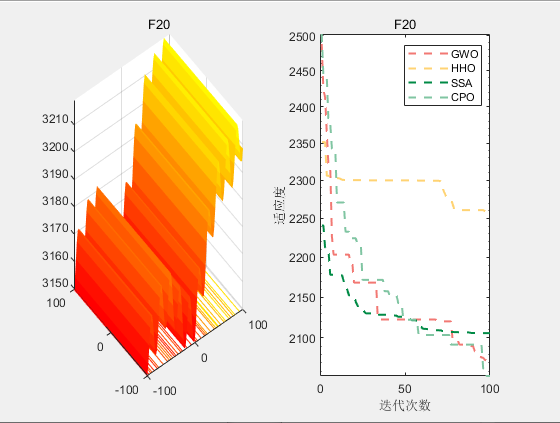
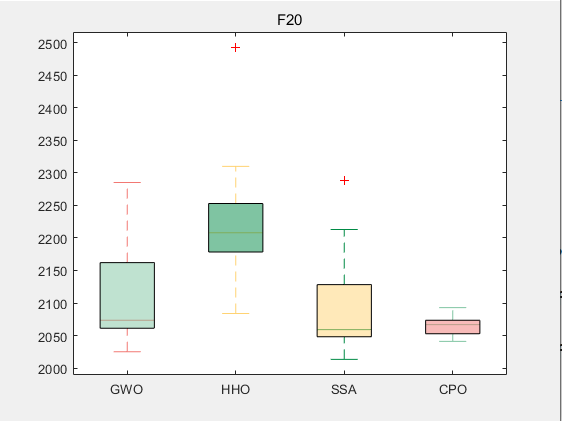
CEC2017-F20

4.参考文献
[1] Abdel-Basset M, Mohamed R, Abouhawwash M. Crested Porcupine Optimizer: A new nature-inspired metaheuristic[J]. Knowledge-Based Systems, 2024, 284: 111257.
















 1003
1003











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











