







前言:神经网络
输入值:x1, x2 = 0.5,0.3
输出值:y1, y2 =0.23, -0.07
激活函数:sigmoid
损失函数:MSE
初始权值:0.2 -0.4 0.5 0.6 0.1 -0.5 -0.3 0.8
目标:通过反向传播优化权值
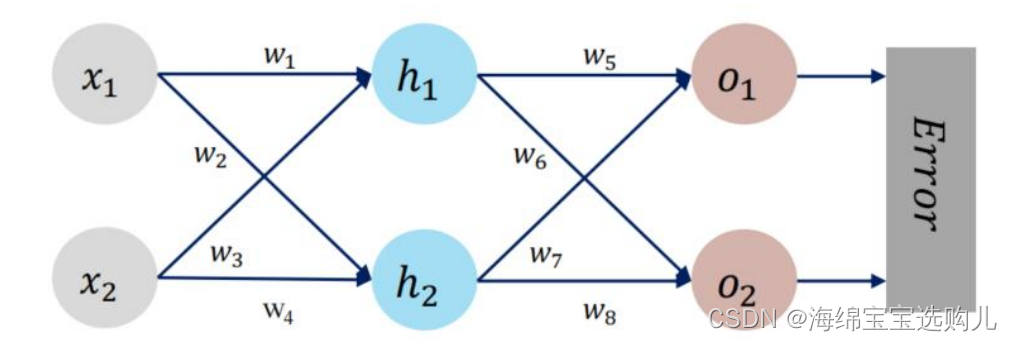
灰色是输入层x1, x2乘相应的权重,使用激活函数sigmoid激活(可以是线性的函数编程非线性的),激活后再乘相应的权值就是预测的值o1,o2了。
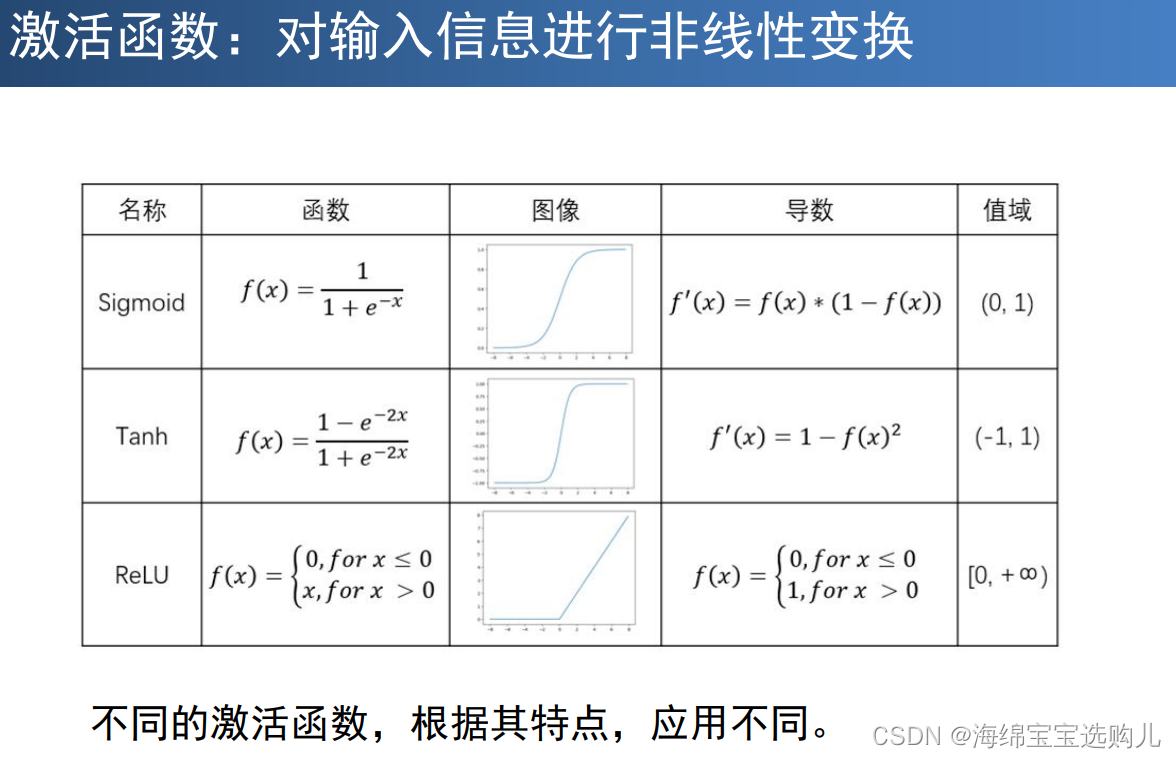
引入激活函数的原因:
数据分布绝大多数是非线性的,
一般神经网络的计算是线性的,
引入激活函数,在神经网络中引入非线性,强化网络的学习能力。
我们这里使用反向传播的原因,是为了优化权值的偏差而带来的预测的误差。
而如何看我们的偏差呢?
就是使用损失函数来计算预测值和真实值的偏差。

通过反向传播优化权值
这些误差我们可以通过反向传播来优化权值,更新wj使用下边的公式,使用梯度下降的方法。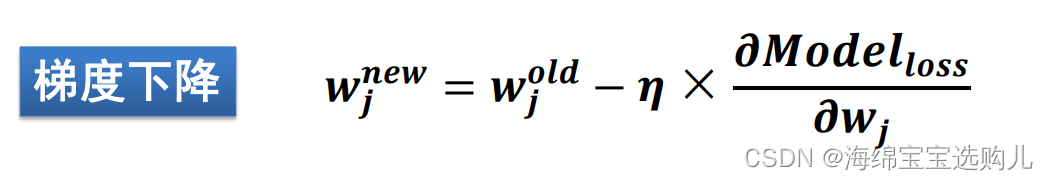
在这求过程中我们会在求梯度时会用到求偏导,这我们可以用高数的知识链式求导法则来求解。
在求W5-W8的梯度时我们,W5只影响o1。(高数知识)
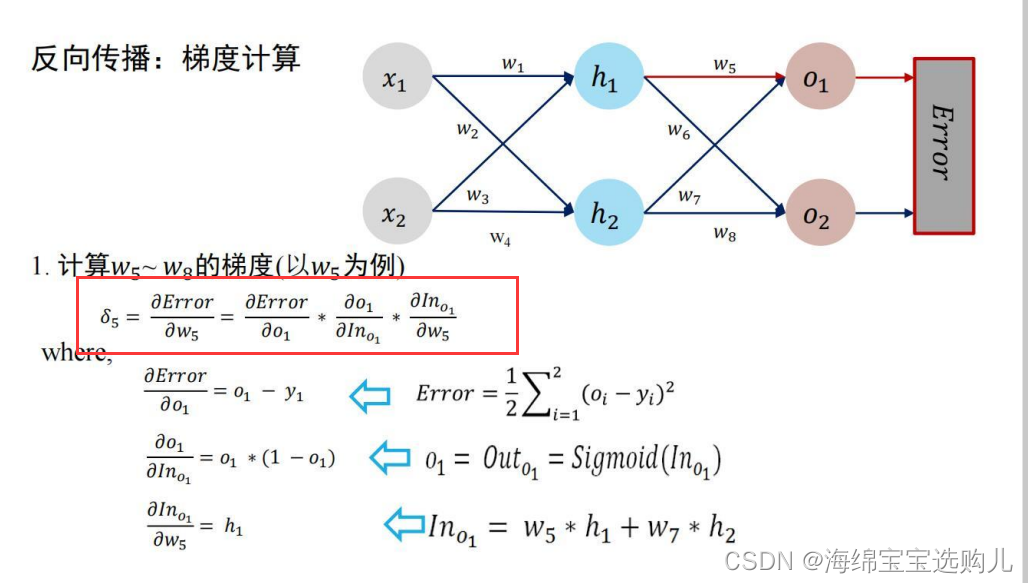
在求W1-W4的梯度时我们,W1的权值会影响o1和o2,所以求梯度要由以下方式来求。(高数知识)
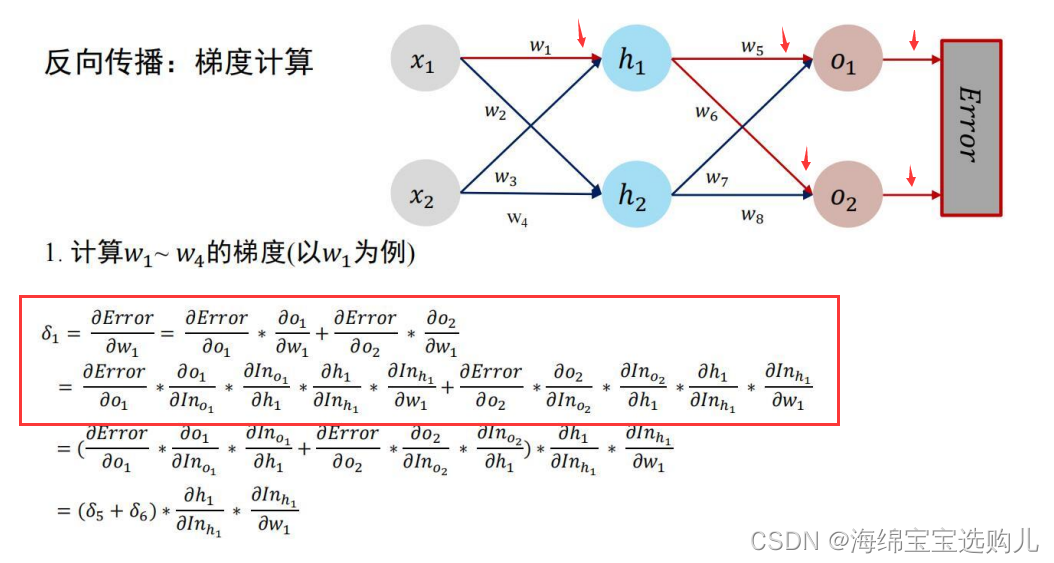
下面就是程序实现了。
程序复现
import numpy as np
def sigmoid(z):
a = 1 / (1 + np.exp(-z))
return a
def forward_propagate(x1, x2, y1, y2, w1, w2, w3, w4, w5, w6, w7, w8):
in_h1 = w1 * x1 + w3 * x2
out_h1 = sigmoid(in_h1)
in_h2 = w2 * x1 + w4 * x2
out_h2 = sigmoid(in_h2)
in_o1 = w5 * out_h1 + w7 * out_h2
out_o1 = sigmoid(in_o1)
in_o2 = w6 * out_h1 + w8 * out_h2
out_o2 = sigmoid(in_o2)
print("正向计算:o1 ,o2")
print(round(out_o1, 5), round(out_o2, 5))
error = (1 / 2) * (out_o1 - y1) ** 2 + (1 / 2) * (out_o2 - y2) ** 2
print("损失函数:均方误差")
print(round(error, 5))
return out_o1, out_o2, out_h1, out_h2
def back_propagate(out_o1, out_o2, out_h1, out_h2):
# 反向传播
d_o1 = out_o1 - y1
d_o2 = out_o2 - y2
# print(round(d_o1, 2), round(d_o2, 2))
d_w5 = d_o1 * out_o1 * (1 - out_o1) * out_h1
d_w7 = d_o1 * out_o1 * (1 - out_o1) * out_h2
# print(round(d_w5, 2), round(d_w7, 2))
d_w6 = d_o2 * out_o2 * (1 - out_o2) * out_h1
d_w8 = d_o2 * out_o2 * (1 - out_o2) * out_h2
# print(round(d_w6, 2), round(d_w8, 2))
d_w1 = (d_w5 + d_w6) * out_h1 * (1 - out_h1) * x1
d_w3 = (d_w5 + d_w6) * out_h1 * (1 - out_h1) * x2
# print(round(d_w1, 2), round(d_w3, 2))
d_w2 = (d_w7 + d_w8) * out_h2 * (1 - out_h2) * x1
d_w4 = (d_w7 + d_w8) * out_h2 * (1 - out_h2) * x2
# print(round(d_w2, 2), round(d_w4, 2))
print("反向传播:误差传给每个权值")
print(round(d_w1, 5), round(d_w2, 5), round(d_w3, 5), round(d_w4, 5), round(d_w5, 5), round(d_w6, 5),
round(d_w7, 5), round(d_w8, 5))
return d_w1, d_w2, d_w3, d_w4, d_w5, d_w6, d_w7, d_w8
def update_w(w1, w2, w3, w4, w5, w6, w7, w8):
# 步长
step = 5
w1 = w1 - step * d_w1
w2 = w2 - step * d_w2
w3 = w3 - step * d_w3
w4 = w4 - step * d_w4
w5 = w5 - step * d_w5
w6 = w6 - step * d_w6
w7 = w7 - step * d_w7
w8 = w8 - step * d_w8
return w1, w2, w3, w4, w5, w6, w7, w8
if __name__ == "__main__":
w1, w2, w3, w4, w5, w6, w7, w8 = 0.2, -0.4, 0.5, 0.6, 0.1, -0.5, -0.3, 0.8
x1, x2 = 0.5, 0.3
y1, y2 = 0.23, -0.07
print("=====输入值:x1, x2;真实输出值:y1, y2=====")
print(x1, x2, y1, y2)
print("=====更新前的权值=====")
print(round(w1, 2), round(w2, 2), round(w3, 2), round(w4, 2), round(w5, 2), round(w6, 2), round(w7, 2),
round(w8, 2))
for i in range(1000):
print("=====第" + str(i) + "轮=====")
out_o1, out_o2, out_h1, out_h2 = forward_propagate(x1, x2, y1, y2, w1, w2, w3, w4, w5, w6, w7, w8)
d_w1, d_w2, d_w3, d_w4, d_w5, d_w6, d_w7, d_w8 = back_propagate(out_o1, out_o2, out_h1, out_h2)
w1, w2, w3, w4, w5, w6, w7, w8 = update_w(w1, w2, w3, w4, w5, w6, w7, w8)
print("更新后的权值")
print(round(w1, 2), round(w2, 2), round(w3, 2), round(w4, 2), round(w5, 2), round(w6, 2), round(w7, 2),
round(w8, 2))
这定义了sigmoid函数,正向计算函数forward_propagate,反向传播函数back_propagate(计算每个梯度loss对wi的偏导),更新权重函数update_w。
第1000轮结果,均方误差已经相当小了,可以认为模型好了。
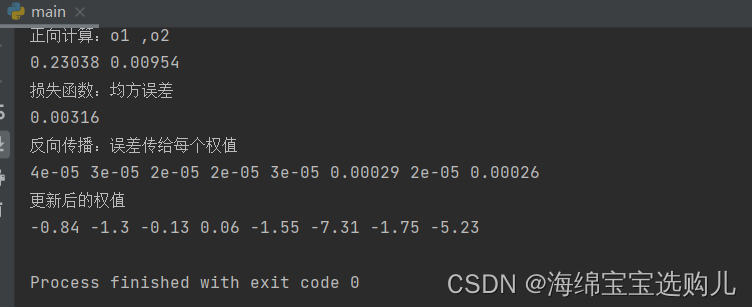















 450
450











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









