







误差反向传播:前馈神经网络
过程推导
反向传播算法(back propagation) 主要利用损失函数来计算模型预测结果与真实结果之间的误差以优化调整模型参数,这一优化调整机制是从输出端向输入端,由后向前递进进行。
前面介绍过,损失函数梯度反方向是损失误差下降最快方向。在求取损失函数梯度时需要对各个变量求偏导,这一求取偏导过程要用到链式法则(Chain Rule)。
例题 计算反向传播的梯度
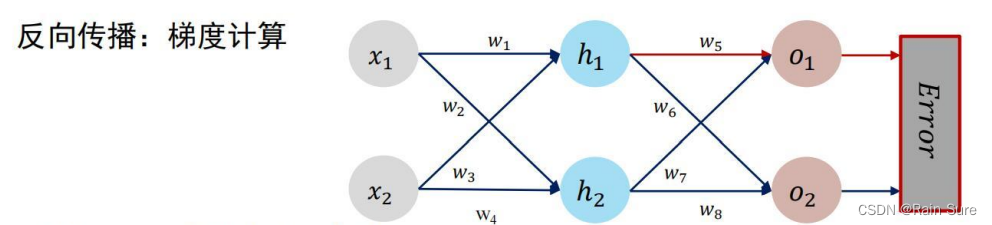
计算过程
计算 w 5 到 w 8 w_5 到 w_8 w5到w8 的梯度(以 w 5 w_5 w5为例)

计算 w 1 到 w 4 w_1 到 w_4 w1到w4的梯度(以w_1为例)
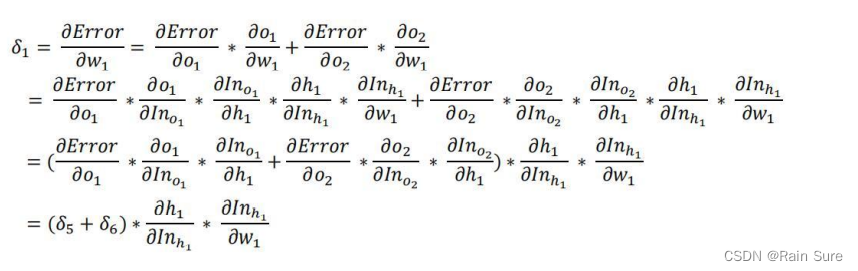
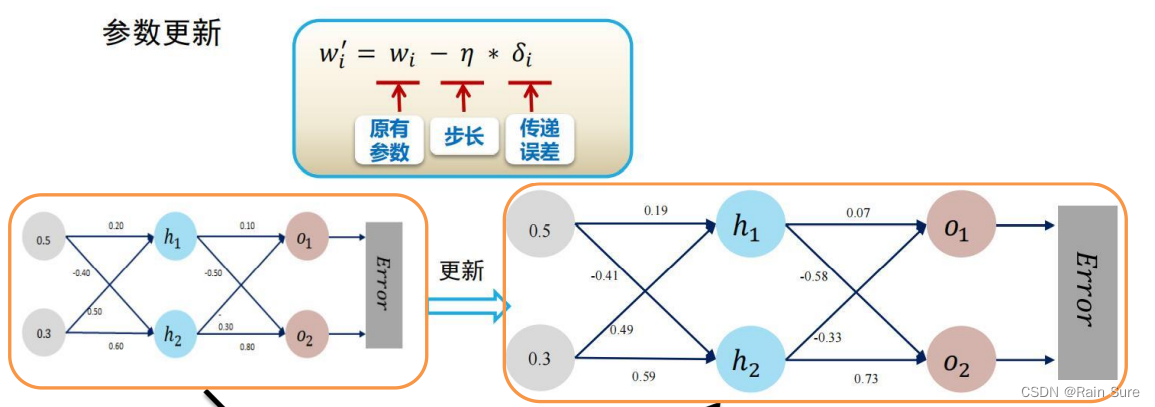
更新参数,其中 η \eta η被称为学习率
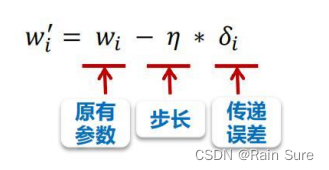
数值计算
参数初始化
前向传播
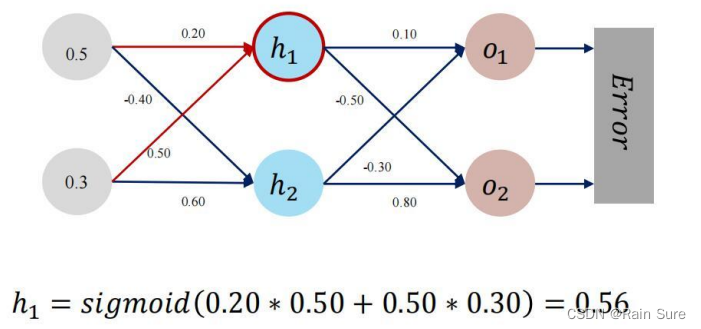
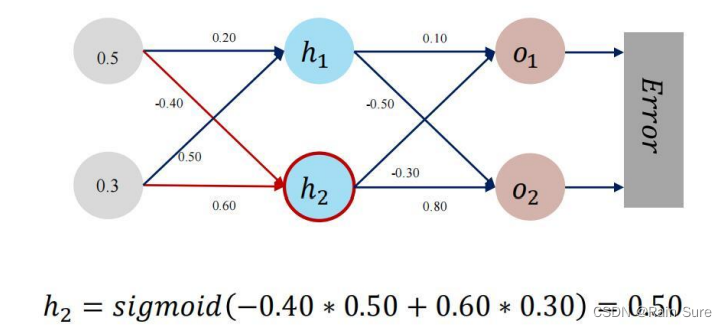
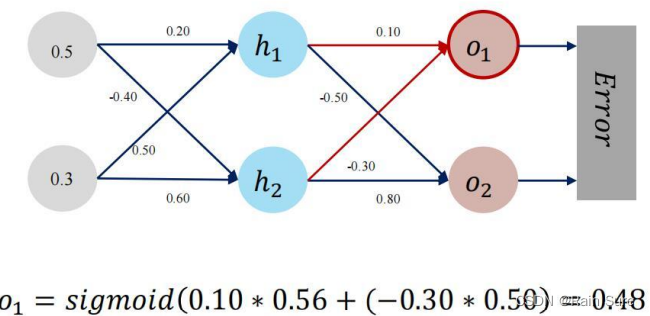
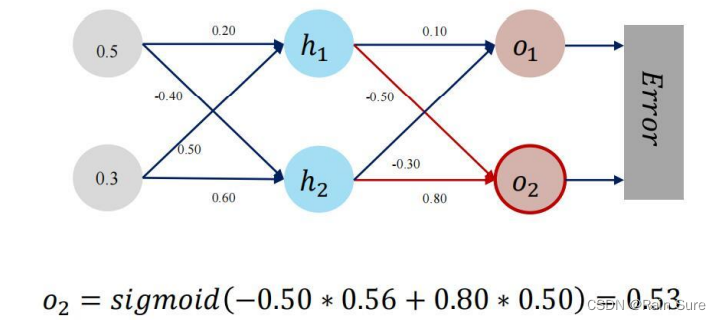
反向传播
假设学习速率(Learning Rate
η
\eta
η = 1)
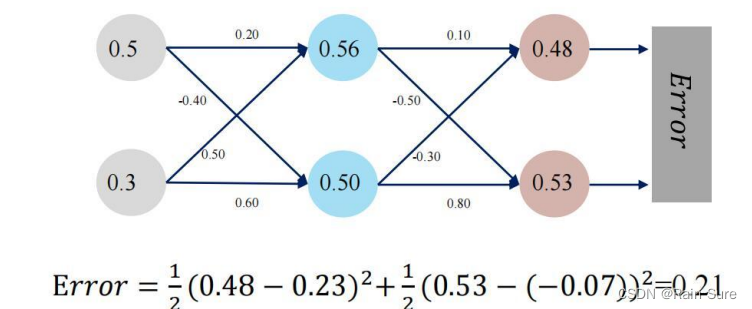
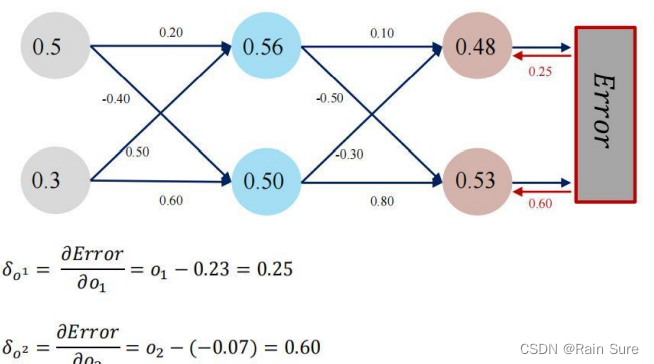
梯度计算,以
o
1
o^{1}
o1 和
o
2
o^{2}
o2为例
参数更新:
代码实现
import numpy as np
w1, w2, w3, w4, w5, w6, w7, w8 = 0.2, -0.4, 0.5, 0.6, 0.1, -0.5, -0.3, 0.8
x1, x2 = 0.5, 0.3
y1, y2 = 0.23, -0.07
print("输入值 x0, x1:", x1, x2)
print("输出值 y0, y1:", y1, y2)
def sigmoid(z):
a = 1 / (1 + np.exp(-z))
return a
def forward_propagate(x1, x2, y1, y2, w1, w2, w3, w4, w5, w6, w7, w8):
in_h1 = w1 * x1 + w3 * x2
out_h1 = sigmoid(in_h1)
in_h2 = w2 * x1 + w4 * x2
out_h2 = sigmoid(in_h2)
in_o1 = w5 * out_h1 + w7 * out_h2
out_o1 = sigmoid(in_o1)
in_o2 = w6 * out_h1 + w8 * out_h2
out_o2 = sigmoid(in_o2)
print("正向计算,隐藏层h1 ,h2:", end="")
print(round(out_h1, 5), round(out_h2, 5))
print("正向计算,预测值o1 ,o2:", end="")
print(round(out_o1, 5), round(out_o2, 5))
error = (1 / 2) * (out_o1 - y1) ** 2 + (1 / 2) * (out_o2 - y2) ** 2
print("损失函数(均方误差):",round(error, 5))
return out_o1, out_o2, out_h1, out_h2
def back_propagate(out_o1, out_o2, out_h1, out_h2):
# 反向传播
d_o1 = out_o1 - y1
d_o2 = out_o2 - y2
d_w5 = d_o1 * out_o1 * (1 - out_o1) * out_h1
d_w7 = d_o1 * out_o1 * (1 - out_o1) * out_h2
d_w6 = d_o2 * out_o2 * (1 - out_o2) * out_h1
d_w8 = d_o2 * out_o2 * (1 - out_o2) * out_h2
d_w1 = (d_o1 * out_h1 * (1 - out_h1) * w5 + d_o2 * out_o2 * (1 - out_o2) * w6) * out_h1 * (1 - out_h1) * x1
d_w3 = (d_o1 * out_h1 * (1 - out_h1) * w5 + d_o2 * out_o2 * (1 - out_o2) * w6) * out_h1 * (1 - out_h1) * x2
d_w2 = (d_o1 * out_h1 * (1 - out_h1) * w7 + d_o2 * out_o2 * (1 - out_o2) * w8) * out_h2 * (1 - out_h2) * x1
d_w4 = (d_o1 * out_h1 * (1 - out_h1) * w7 + d_o2 * out_o2 * (1 - out_o2) * w8) * out_h2 * (1 - out_h2) * x2
print("w的梯度:",round(d_w1, 2), round(d_w2, 2), round(d_w3, 2), round(d_w4, 2), round(d_w5, 2), round(d_w6, 2),
round(d_w7, 2), round(d_w8, 2))
return d_w1, d_w2, d_w3, d_w4, d_w5, d_w6, d_w7, d_w8
def update_w(w1, w2, w3, w4, w5, w6, w7, w8):
# 步长
step = 1
w1 = w1 - step * d_w1
w2 = w2 - step * d_w2
w3 = w3 - step * d_w3
w4 = w4 - step * d_w4
w5 = w5 - step * d_w5
w6 = w6 - step * d_w6
w7 = w7 - step * d_w7
w8 = w8 - step * d_w8
return w1, w2, w3, w4, w5, w6, w7, w8
if __name__ == "__main__":
print("权值w0-w7:",round(w1, 2), round(w2, 2), round(w3, 2), round(w4, 2), round(w5, 2), round(w6, 2), round(w7, 2),
round(w8, 2))
for i in range(1):
print("=====第" + str(i+1) + "轮=====")
out_o1, out_o2, out_h1, out_h2 = forward_propagate(x1, x2, y1, y2, w1, w2, w3, w4, w5, w6, w7, w8)
d_w1, d_w2, d_w3, d_w4, d_w5, d_w6, d_w7, d_w8 = back_propagate(out_o1, out_o2, out_h1, out_h2)
w1, w2, w3, w4, w5, w6, w7, w8 = update_w(w1, w2, w3, w4, w5, w6, w7, w8)
print("更新后的权值w:",round(w1, 2), round(w2, 2), round(w3, 2), round(w4, 2), round(w5, 2), round(w6, 2), round(w7, 2),
round(w8, 2))
运行结果

















 605
605











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











