







一,安装pycharm,配置好python开发环境
我的电脑已经安装好了,就没有过程了。具体详情看这篇文章。^^
PyCharm 安装教程(Windows) | 菜鸟教程 (runoob.com)
二,安装pytorch
在安装主要参考这篇文章
Pytorch安装流程
但是遇到了些问题,安装所需要的第三方包时部分包安装不了速度太慢。自己下好的包,conda install还安装不了。(暂时不太清楚原因)
于是更换了资源镜像。
更换资源镜像方法
cmd命令添加:以- - -添加【清华大学开源软件镜像站】为例
打开cmd 直接依次输入下列命令,
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free/
conda config --set show_channel_urls yes
你的目录 C:\Users<你的用户名> 下就会生成配置文件.condarc,更换为以下内容保存。
channels:
- defaults
show_channel_urls: true
channel_alias: https://mirrors.tuna.tsinghua.edu.cn/anaconda
default_channels:
- https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main
- https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free
- https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/r
- https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/pro
- https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/msys2
custom_channels:
conda-forge: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud
msys2: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud
bioconda: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud
menpo: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud
pytorch: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud
simpleitk: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud
最后在cmd中执行conda clean -i
安装所需要的第三方包。
打开 Anaconda prompt 命令窗口,激活环境,输入python,进入python开发环境中
这里true就是成功了。
Pycharm使用虚拟环境
创建一个project,然后我们点击左上角File,选中settings,点击左边齿轮图标,并选择Add

选Conda Environment,选Existing environment(因为咱们已经之前用anaconda已经创建过环境了),并勾选Make available to all projects(这个选项可以使你新开一个project的时候,也可以使用这个环境)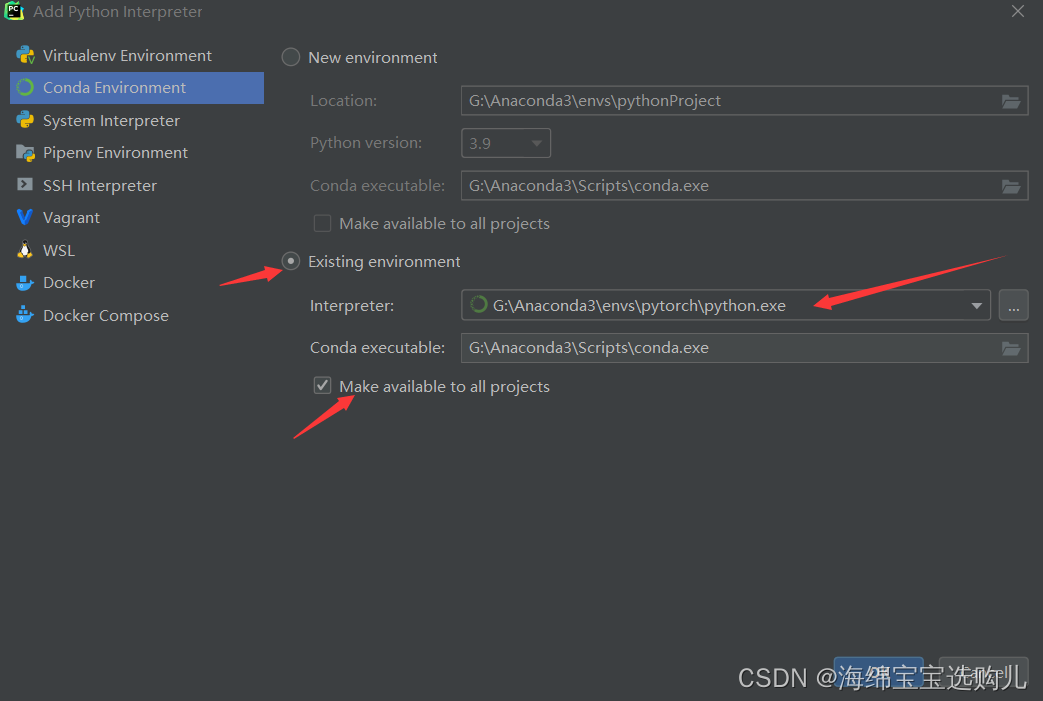
然后就ok 和Apply就好了。 我们可以在pycharm上import torch包了。
三,Pytorch实现反向传播
Pytorch 里面数据最基本的成员是 Tensor,它是用来存储数据的,它可以存标量,向量,矩阵或者高阶的 Tensor。它里面包含两个重要成员 data 和 grad。data 用来保存权重 w,grad 用来保存损失函数 Loss 对权重w的导数。
在这个实现反向传播的例子中,我们前向传播用的线性模型 y=wx 。
import torch
x_data = [1.0, 2.0, 3.0] # 输入值
y_data = [2.0, 4.0, 6.0] # 输出值
w = torch.Tensor([1.0]) # 权重初始值(设置w的初始值),在grad求导时会将这里设置的初始值带入
w.requires_grad = True # Tensor创建时默认不计算梯度,需要计算梯度设置为ture,自动记录求w的导
# y_predict = x * w
def forward(x):
return x * w
# 损失函数,return激活函数后得到的
def loss(x,y):
y_pred = forward(x)
return (y_pred - y) ** 2
# 训练过程
# 第一步:先算损失Loss
# 第二步:backward,反向传播
# 第三步:梯度下降
for epoch in range(100): #训练100次
for x, y in zip(x_data, y_data):
l = loss(x, y) # 前向传播,求Loss(损失函数),构建计算图
l.backward() # 反向传播,求出计算图中所有梯度存入w中
print("\tgrad: ", x, y, w.grad.item())
# w.grad.data:获取梯度,用data计算,不会建立计算图,每次获取叠加到grad
w.data = w.data - 0.01 * w.grad.data # 修正一次w,learningrate=0.01(类似步长
w.grad.data.zero_() # 注意:将w中记录的梯度清零,消除本次计算记录,只保留新的w,开启下一次前向传播
print("pregress:", epoch, l.item()) # item取元素精度更高,得到的是loss
print(w);
backward函数就会把loss对w的偏导/梯度求出来,直接用w.grad.data就可以得到。
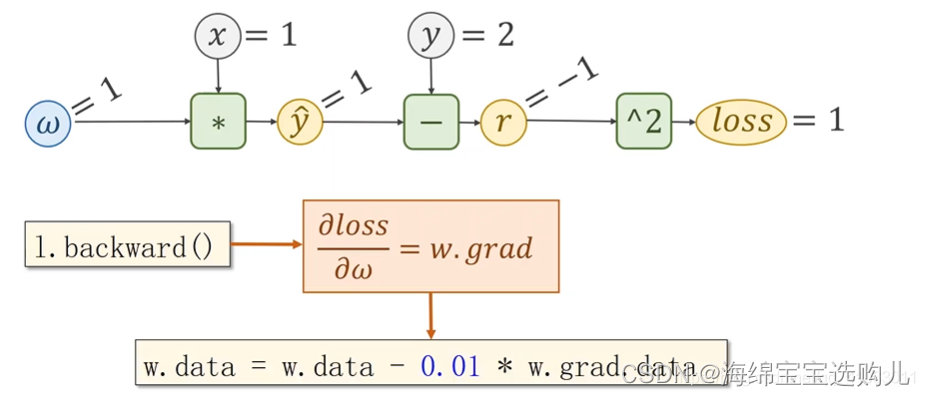
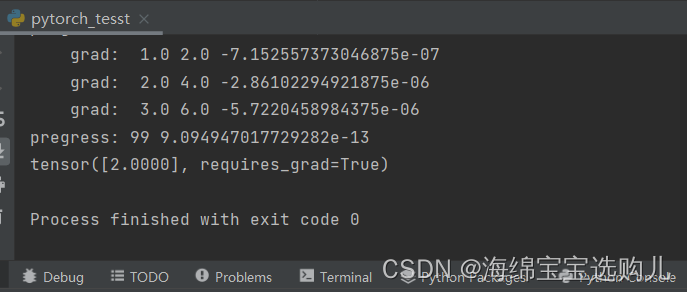
经过100轮训练之后,y已经无限接近于正确的解了,损失已经是10的-13次方非常小。w也与我们的想法一样是2。















 2697
2697











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









