






1、残差网络基本单元
残差网络是使得深度学习的网络变得更深的奠基类的神经网络架构。从操作层面来看,不难理解,就是实现了跳跃连接(Skip Connection),在这种结构中,前一层的输出不仅会被送入下一层进行变换,还会直接与下一层(或更深的层)的输出相加。这样,前一层的输出可以直接“跳过”一到多个层,从而避免在过多的变换中丢失信息。如下图:
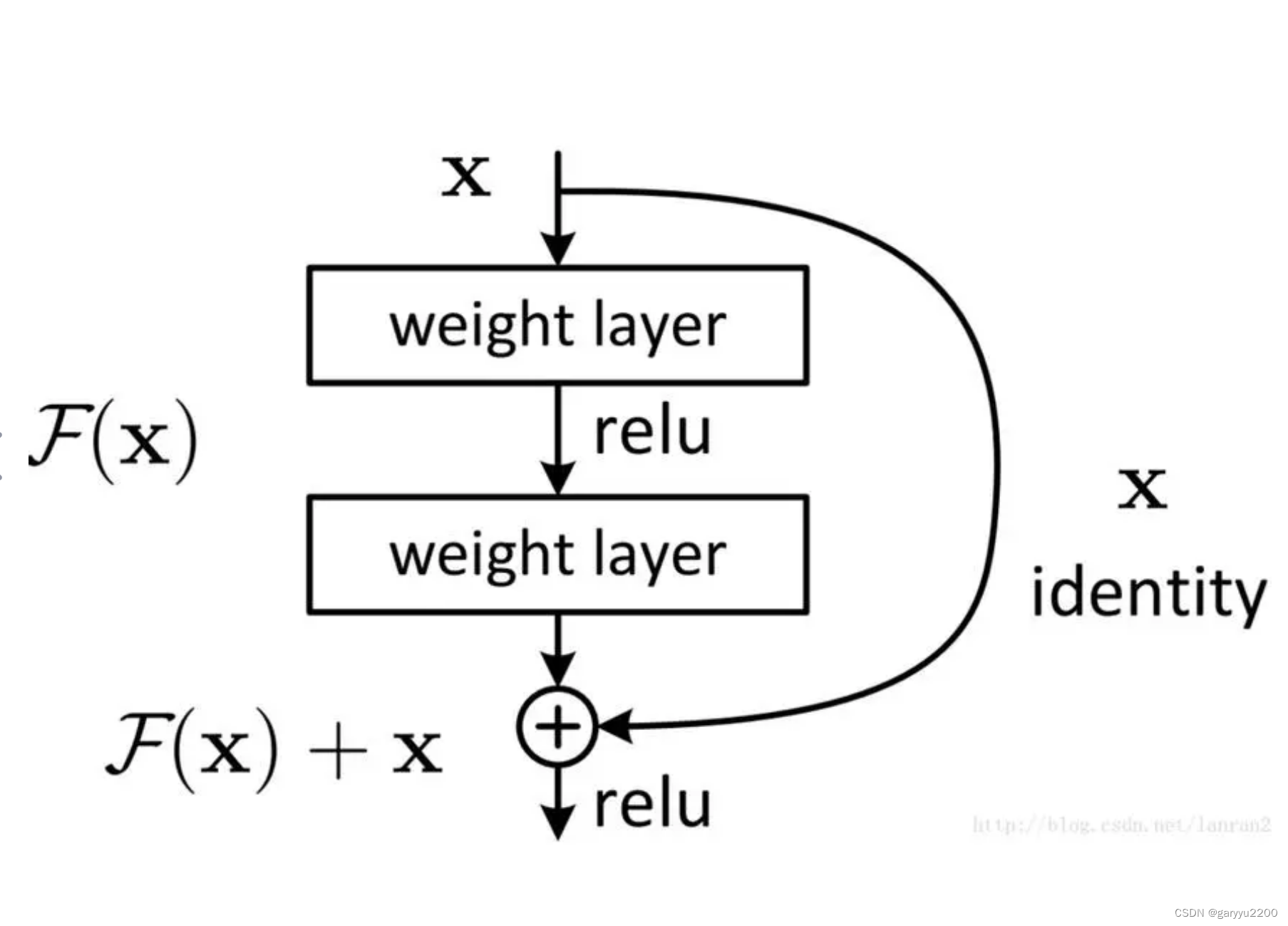
这是构成残差网络(ResNet)的基本单元。这里的 x 是输入,F(x) 是一个由两个权重层(也就是全连接层或卷积层)和一个激活函数(例如ReLU)构成的函数,F(x) + x 是添加了输入 x 后的输出,然后再通过一个激活函数,如ReLU。identity 是指恒等映射,即直接将输入传递到输出。
这个残差块的结构可以用以下的数学表达式进行描述:
z1 = WeightLayer1(x)
a1 = ReLU(z1)
z2 = WeightLayer2(a1)
F(x) = z2
这里,WeightLayer1 和 WeightLayer2 是两个权重层,可以是全连接层或者卷积层,ReLU 是激活函数,z1 和 z2 是这两个权重层的线性输出,a1 是第一个权重层的激活输出,F(x) 是残差函数的输出。
然后,这个残差块的输出是 y = ReLU(F(x) + x), 其中 F(x) + x 是恒等映射(x)和残差函数(F(x))的和,然后再通过一个ReLU激活函数。
看上图的设计很好理解,但是再看数学表达有点绕,为了解决这个问题,我们得从理解恒等映射得理解开始。开始我学习得时候,也卡在这个地方了,从恒等映射着手,慢慢理解了。
2、恒等映射
恒等映射,也被称为恒等函数或单位映射,是一种特殊的函数,它将每一个集合中的元素映射到其自身。在数学中,恒等映射通常被记作I,或者使用小写的字母i。
对于任何集合X,我们可以定义恒等映射:I: X → X,其中:
I(x) = x,
对于所有的x ∈ X。
例如,考虑有限集合X = {1, 2, 3, 4, 5}。在这个集合上的恒等映射可以被定义如下:
I(1) = 1,
I(2) = 2,
I(3) = 3,
I(4) = 4,
I(5) = 5.
换句话说,恒等映射只是简单地将每一个元素映射到其自身。无论这个集合有多大,或者这个集合的元素是什么,恒等映射总是将每一个元素映射到其自身。
在实数集R上,恒等映射可以被表示为y = f(x) = x,这是一条通过原点,斜率为1的直线。在这种情况下,任何一个实数x都被映射到其自身。例如,f(0) = 0,f(1) = 1,f(2) = 2,等等。
3、深度学习中的恒等映射
在深度学习中,恒等映射(Identity Mapping)是一种常用的技巧,尤其是在设计深层神经网络的时候。这种技术被广泛应用于残差网络(ResNet)的设计中,主要用于解决深度神经网络中的梯度消失和梯度爆炸问题。
在一般的深度神经网络中,每一层的输出都是通过将前一层的输出通过一系列的变换(如卷积、激活函数等)得到的。然而,当网络的深度增加时,这种连续的变换可能会导致梯度消失或梯度爆炸的问题,从而影响模型的训练效果。
为了解决这个问题,残差网络引入了一种称为“跳远连接”(Skip Connection)或“恒等映射”的技术。在这种结构中,前一层的输出不仅会被送入下一层进行变换,还会直接与下一层(或更深的层)的输出相加。这样,前一层的输出可以直接“跳过”一到多个层,从而避免在过多的变换中丢失信息。
4、直接跳过那么被跳过的层不是白用了吗?那么增加层级又有什么意义呢?
在引入恒等映射或跳跃连接后,网络中的一部分层的输出是经过直接连接加到了最终的输出上。这并不意味着这些被跳过的层就没有起到作用,或者增加更多的层就没有意义了。
在残差网络(ResNet)中,恒等映射或跳跃连接的设计主要是为了解决深度学习模型训练过程中的梯度消失和梯度爆炸问题。当网络增加更多的层时,模型的复杂性和表示能力通常会增加。然而,这也会带来训练困难,例如梯度消失和梯度爆炸问题。通过在网络中添加恒等映射或跳跃连接,我们可以使得梯度直接通过这些连接传播,这有助于改善这些问题,使得更深层次的网络可以被有效地训练。
此外,跳跃连接实际上是在原有的网络基础上添加了额外的路径,增加了模型的多样性。每个路径可以学习并捕获到数据的不同特征和信息。这种设计使得模型有更大的能力和灵活性,可以更好地从数据中学习和提取复杂的特征。
因此,虽然跳跃连接允许部分信息直接通过网络,但是被跳过的层仍然在处理传递过来的信息,学习并提取出有价值的特征。这些特征和跳跃连接中直接传递的信息一起,共同构成了最终的输出。这种设计使得网络可以在增加更多层的同时,保持良好的训练性能。
4、跳跃连接的设计为何叫做残差网络呢?
"残差"这个词在残差网络(Residual Network,ResNet)这个概念中的使用,源于它的设计原理。在ResNet中,每个网络块(或层)被设计为学习输入数据的一个“残差函数”。
在传统的神经网络中,每一层的目标是学习一个映射函数H(x),其中x是输入数据。然而,在ResNet中,我们将这个目标稍微改变一下,使每一层去学习一个残差函数F(x) = H(x) - x,这个残差函数表示的是原始输入x与我们希望得到的输出H(x)之间的差异,或者叫做"残差"。
这样,原本的函数H(x)就被分解成了两部分:恒等映射(即x自身)和一个残差函数F(x),所以我们有H(x) = F(x) + x。这就是为什么我们说ResNet是在学习输入的“残差”的原因。
这种设计有一个主要的优点:当我们希望学习的映射H(x)接近于恒等映射时(也就是说,输入x已经非常接近我们希望的输出),残差函数F(x)可以更接近于0,这使得网络的学习任务变得更简单。
总的来说,"残差网络"这个名字来源于它的设计原理——通过学习输入数据的残差,而不是直接学习完整的映射函数,来简化网络的学习任务并提高其性能。
5、跳跃连接增加了x后,那么如何设计训练残差网络呢?
在残差网络(Residual Network,ResNet)中,我们并不是直接训练网络来学习H(x) - x,而是让网络学习一个新的函数F(x),然后通过添加输入x(即恒等映射)来得到H(x)。这样,我们实际上是在训练网络学习F(x) = H(x) - x,同时确保了H(x) = F(x) + x。
具体来说,我们可以设计一个网络块或层,其目标是学习F(x),然后在输出时将输入x添加回去。这就是所谓的"残差块"或"残差连接"。
例如,一个简单的残差块可以由两个卷积层组成,就像这样:
def residual_block(x, num_filters):
Fx = Conv2D(num_filters, kernel_size=(3,3), padding='same')(x)
Fx = Activation('relu')(Fx)
Fx = Conv2D(num_filters, kernel_size=(3,3), padding='same')(Fx)
out = Add()([x, Fx]) # 在这里,我们将输入x添加回去,得到H(x) = F(x) + x
out = Activation('relu')(out)
return out在这个例子中,网络块首先将输入x通过两个卷积层,得到F(x)。然后,我们将输入x添加回去,得到H(x) = F(x) + x。这就是一个基本的残差块的设计。
通过这种方式,我们实际上是在训练网络学习F(x),同时通过添加x来得到H(x)。这种设计使得当所需的映射H(x)接近于恒等映射(即,当x已经非常接近我们想要的输出时)时,网络可以更容易地学习这个映射,因为这时F(x)可以更接近于0。
6、以一个狗的图片学习为例,如果输入x是狗的像素表达,h(x)和f(x)又是什么呢?
在深度学习和神经网络中,x,H(x)和F(x)都是在高维空间中的向量,而不是单一的值。如果我们以图片识别为例,处理的是一个狗的图片,那么:
- x:x 是输入向量,也就是狗的图片。图像通常表示为像素强度的数组,可以被视为高维空间中的一个点或向量。例如,一个 100x100 的灰度图像可以被视为 10,000 维空间中的一个点。
- H(x):H(x) 是我们的目标输出,也就是我们希望网络预测的结果。在分类任务中,H(x) 可能是一个表示不同类别的概率分布的向量。例如,如果我们的任务是识别图片中的动物种类,H(x) 可能是一个向量,其中每个元素代表了对应动物种类的概率。如果图片中的狗是一个拉布拉多,那么 H(x) 的“拉布拉多”元素将会是最大的。
- F(x):F(x) 是残差函数,表示我们需要让网络学习的“差异”或“改变”。在残差网络中,我们试图让网络学习的不是直接从 x 映射到 H(x) 的函数,而是从 x 映射到 H(x) - x 的函数。这个 F(x) 表示了输入 x 需要经过多少改变才能得到我们的目标输出 H(x)。
在这个例子中,F(x) 可以理解为网络需要学习的特征或者模式,如狗的形状、颜色、纹理等,这些特征可以帮助网络从原始的像素数据中识别出拉布拉多。通过学习这些特征(也就是学习 F(x)),网络可以在原始的输入 x(也就是原始的像素数据)上添加这些特征,从而得到我们的目标输出 H(x)(也就是正确的类别概率分布)。
总的来说,残差网络的设计使得网络能够更好地学习复杂的映射关系,特别是当网络的深度增加时,它能够更好地解决梯度消失和梯度爆炸的问题,从而提高模型的性能。
7、在狗的识别学习过程中,残差学习的意义在哪里呢?
残差学习在狗的识别过程中的意义在于它可以帮助深度神经网络更好地学习和识别出复杂的图像模式。
如果我们没有使用残差学习,网络需要直接学习输入 `x` 到目标输出 `H(x)` 的映射关系。这可能非常困难,尤其是对于复杂的任务,比如识别一个狗的品种,这需要理解复杂的视觉模式,如狗的形状、颜色、纹理等。
然而,当我们引入残差学习,网络不再需要直接学习复杂的 `H(x)` 函数,而是学习残差函数 `F(x)`,这个函数表示从输入 `x` 到目标输出 `H(x)` 所需的"改变"或"差异"。在这种情况下,网络可以更加专注于学习这些改变或者差异,也就是需要添加到输入 `x` 上的特征或者模式,从而得到我们的目标输出 `H(x)`。这种学习方式可以使得网络更容易地学习复杂的映射关系。
此外,残差学习的另一个重要优点是它可以帮助解决深度神经网络的梯度消失和梯度爆炸问题。当网络的深度增加时,这两个问题可能会导致网络的性能下降。而通过引入残差连接,我们可以使得梯度直接流过网络的一部分,从而避免了这些问题。
所以,在狗的识别过程中,残差学习可以使得网络更好地学习和识别复杂的视觉模式,同时也可以使得网络在深度增加时仍能保持良好的性能。


















 4095
4095

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











