







摘要
对话是一个动态交互的过程,通常依靠上下文和常识来传递情感信息。现有的工作不是有机地和动态地将常识性知识整合到对话中,而是机械化的方法,为了探索常识知识在情感识别中的潜在价值,本文提出了一个上下文感知和情感感知的图注意机制(Sentic GAT)来嵌入常识知识,它不仅考虑了常识知识与语境信息之间的依赖关系,而且还能保持常识知识与对应词之间的情感一致性。此外,由于情感强度的帮助,进一步表示了情感一致性的程度
在Sentic GAT中,常识知识由上下文感知和情感感知的图注意机制动态表示,上下文话语的内部和相互依赖关系由基于分层多头注意的对话Transformer获得。相互依存和内部依存是指语境信息和其自身关键信息对目标话语的依存关系。
实验结果表明,上下文和情感信息能够促进常识知识的表征,上下文话语的内部和相互依赖有效地提高了感知GAT的性能。
一、介绍
依赖上下文和常识知识来传递情绪,很难被机器识别。比如下面的对话。甲:“我最喜欢狗,你呢?”。B:我最喜欢阿拉斯加雪橇犬。除非在“阿拉斯加雪橇犬”和“狗”之间建立关系,否则机器很难从对话中得出“阿拉斯加雪橇犬”是“狗”的结论
对于上下文信息:建立对话转换网络(DTN)来捕获上下文中的内部和相互依赖关系。一方面,DTN继承了transformer网络在获取长期依赖和语义提取方面的优势。另一方面,它采用分层的多头注意力(HMA T)机制对目标话语的历史信息进行实时建模,弥补了transformer网络在时间属性上相对于RNNs的不足。此外,DTN的自我注意和交叉注意机制的信息流路径比门控RNNs和CNN更短。因此,它可以更有效地对会话中的上下文信息进行建模。
对于常识知识:提出了上下文感知和情感感知的图形注意机制。它不仅能捕捉概念对语境话语的依赖性,还能保持概念与相关词之间的情感一致性。从情感强度的角度来描述情感的一致程度,特别是,CSAGA T还使DTN在捕捉长期和动态的上下文信息时能够实现隐含的情感一致性。
回忆的信息可能会根据情绪效应而发生变化。这种心理现象被称为情绪一致性效应。情绪一致性效应指导下的模型不仅会考虑常识知识与情境信息之间的依赖关系,而且会倾向于选择与情绪一致的常识知识,情感强度被用来描述这种一致性的程度。受此启发,认为在ERC,常识知识的表征也可能受到情绪的影响,这是一个动态的过程。(图1)
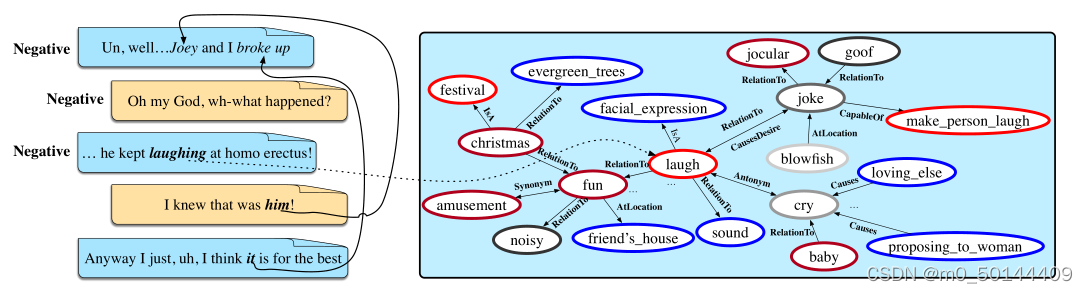
- 嗯,乔伊和我分手了。
- 哦,天哪,发生了什么事?
- …他一直嘲笑直立人!
- 我就知道是他!
- 无论如何,我只是,呃,我认为这是最好的
-
通过参照语境,我们可以发现第四个话语中的“他”和第五个话语中的“它”与第一个话语中的“乔伊”和“分手”有关。然后,利用外部知识库,丰富第三话语中“笑”的语义。特别是在外部知识库中,红色表示“正面”,蓝色表示“中性”,灰色表示“负面”。此外,颜色的深浅反映了情感的强烈程度。
二、模型
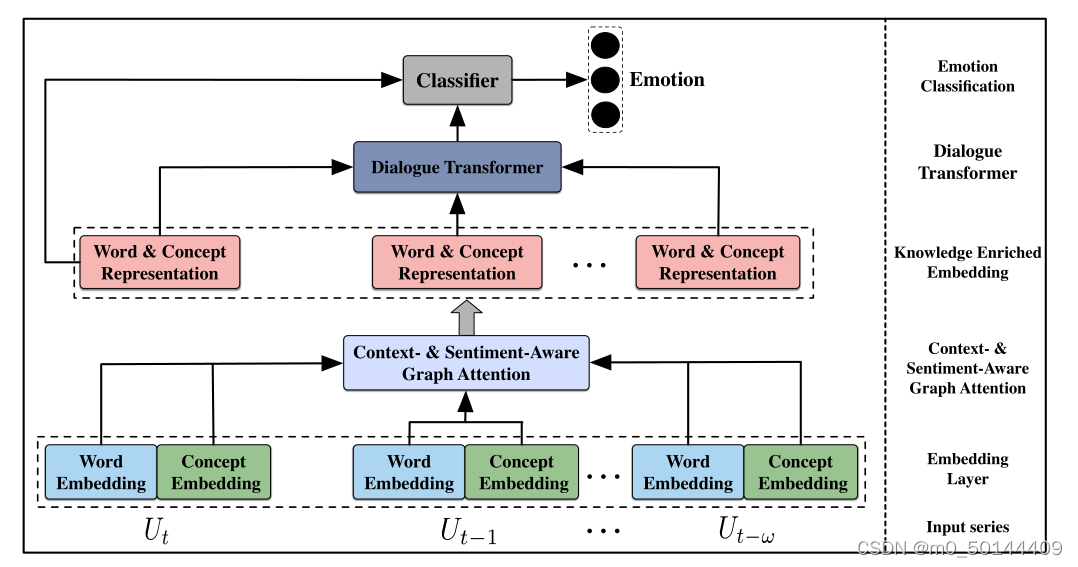
1、 Context- and Sentiment-Aware Graph ATtention (CSAGAT)
一方面,为了保持与外部知识库中的不间断单词标记和相关概念的情感一致性,另一方面,为了在概念嵌入中进一步获取相关概念与当前话语及其上下文话语之间的依赖关系,提出了一种上下文和情感感知图注意力(GSAGA T)来计算与token相对应的概念的表示
对于概念和token之间的注意力权重,考虑:
- token与概念之间的权重过于片面,无法从语义相似度的角度进行描述,而且权重对上下文信息也比较敏感。
- 受情绪一致性效应的启发,认为token和概念之间的权重部分取决于说话者当前的情绪。从情感强度的角度,进一步描述了情感的一致性,以实现注意力权重的差异。
Context-aware :上下文感知基于概念网中每个话语中的标记和相应概念之间的置信度得分,然后它完全整合上下文信息。特别地,不在ConceptNet中而在SenticNet中的概念的置信度分数被设置为1。
Sentiment-aware :情感感知基于每个话语中的符号和概念的情感,根据它们的情感强度来调整注意力权重,以表示情感一致程度的差异。
经过CSAGAT处理后,得到对应于每个话语中的标记的概念表示
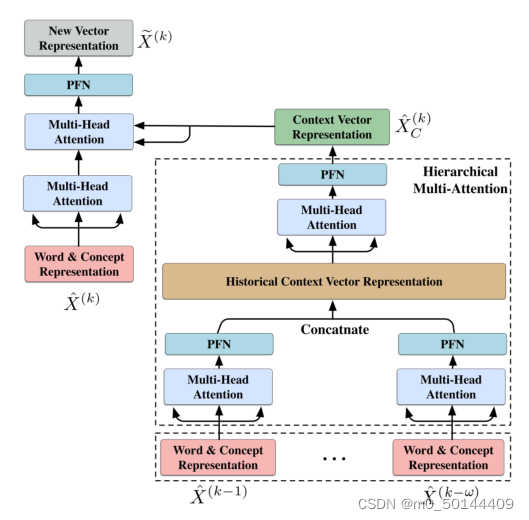
2、 Dialogue Transformer
为了获得历史对话中的上下文信息并识别关键特征。提出了对话transformer(DTN ),以进一步学习每个话语的新向量表示。DTN应用HMA T来实时模拟历史对话,用于获取重要的上下文特征
3、分类
使用全连接层来分类每个话语的最终表示
三、 实验
1、 数据集 2、实验结果
2、实验结果
在数据集上将SenticGAT及其变体的性能与基线方法进行了比较(表3)
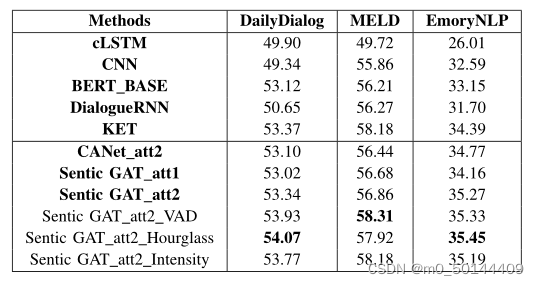
- CLSTM在短对话中表现较好(如DailyDialog),在长对话中表现最差(如MELD和EmoryNLP)。一个主要原因是,使用门控RNN来学习长期相关性可能会出现梯度消失的问题,因为梯度是通过大量话语和标记依次传播回来的。
- CNN在长对话中表现良好,这证明了仅使用基于RNN的模型来建模长对话可能是无效的
- BERT_BASE使用双向transformer模拟上下文话语。由于其强大的表示能力,BERT库在所有数据集上都取得了很好的性能。但是,参数的数量比其他基线和我们的模型要大得多,这在部署到计算能力和内存有限的GPU设备上时可能是一个缺点。
- DialogueRNN模型取得了更好的性能,这可能是由于其说话人信息用于动态建模情绪状态。
- KET在所有基准中表现最佳。它应用上下文感知的情感图注意机制来动态利用外部常识知识。然而,KET缺乏有效的选择机制来处理大量的常识知识。换句话说,无论说话者当前的情绪或情感是什么,将常识性知识嵌入目标话语中的同一个词没有区别,这是不恰当的。
-
CANet在长对话(如MELD和EmoryNLP)上表现良好,证明了我们的对话transformer和上下文感知图注意机制的有效性
-
SenticGAT及其变体在大多数测试数据集(不同的训练规模、上下文长度和领域)上都优于其他基线。可能的解释是KET使用NRC_VAD中的效价和唤醒值来衡量概念的情感强度,并丰富了概念和token之间的关系
-
Sentic GAT_att2_VAD、Sentic GAT_att2_Hourglass和Sentic GAT_att2_Intensity在使用其他情感模型和情感极性来测量概念的情感强度后,表现出比KET模型更好的性能。
3、模型分析
CAGAT分析:在概念嵌入中,引入CAGAT来获取相关概念与当前话语及其语境话语之间的依赖关系。通过改变上下文窗口的长度ω,图中示出了具有不同上下文长度的模型的准确度和F1分数。 显然,将更多的上下文信息集成到模型中可以提高模型在长会话和短会话数据集中的性能。但是当F1值达到某个阈值时,模型的性能开始下降。长度越长,训练成本(时间和内存消耗)越高。(图4)
 SAGAT分析:受情绪一致性的启发,提出了SAGAT。模拟人类的记忆选择机制来选择潜在的概念,以保持概念与对应token之间的情感一致性。 根据表3,可以看到通过用情感强度进一步描述情感一致性的程度,模型的性能得到提升。通过改变图4所示的预设阈值来显示模型的准确性和F1分数,模型的精度和F1值随着阈值的变化而波动。为了更好地理解SAGAT及其情感强度对注意力权重的影响,使用图1中的“laugh”作为token来可视化表征和相关概念之间的权重(图5)
SAGAT分析:受情绪一致性的启发,提出了SAGAT。模拟人类的记忆选择机制来选择潜在的概念,以保持概念与对应token之间的情感一致性。 根据表3,可以看到通过用情感强度进一步描述情感一致性的程度,模型的性能得到提升。通过改变图4所示的预设阈值来显示模型的准确性和F1分数,模型的精度和F1值随着阈值的变化而波动。为了更好地理解SAGAT及其情感强度对注意力权重的影响,使用图1中的“laugh”作为token来可视化表征和相关概念之间的权重(图5)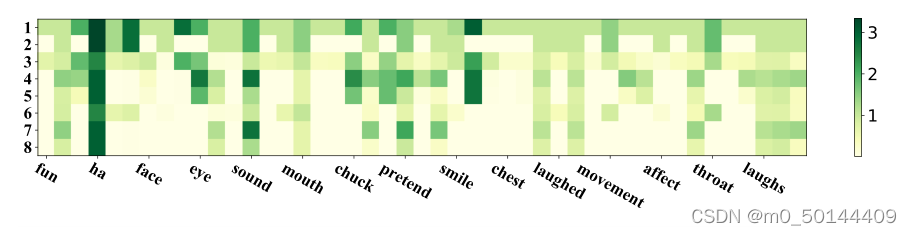
四、 结论
- 提出了一个上下文和情感感知的网络来进行文本会话中的情感识别。我们的模型采用了一种上下文感知和情感感知的图注意机制来动态地链接与外部知识库中的上下文话语和目标token的情感一致的相关知识实体
- 未来:将尝试通过在词级、话语级和上下文级的情绪或情感来选择潜在的概念(常识知识)。此外,将尝试使用图卷积网络(GCN)来捕获发言者之间的依赖关系,以进一步提高模型的性能,因为发言者级别的依赖关系在多方对话中起着重要作用

















 292
292

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









