






Self-Adversarial Training incorporating ForgeryAttention for Image Forgery Localization
一、读后感受
这篇论文就我个人而言感觉很新颖,作者充分考虑了图像空间位置以及不同通道之间的相关性,以最大的可能提取噪声特征。最近在看有关注意力机制在图像取证方面的相关应用,这篇论文提出了一个伪造注意力机制,为一个双重注意力机制,在空间位置和通道上进行考虑,并融合两层注意后作为伪造注意力层的输出。
二、论文贡献及结论
- 提出了伪造注意,这是一种针对伪造定位的新颖注意机制,充分考虑了空间依赖和通道依赖
- 首次在取证中引入了新的训练策略SAT,解决了训练数据不足的问题,提高了模型的鲁棒性和定位性能
- 改进已有的HPF层,利用信道关系提出更细致的CW-HPF,并在此基础提出了一种新颖的从粗到细的伪造定位框架
三、简介
简介现有模型存在的问题:
- 在图像隐写分析中广泛使用的HPF层,在实际应用时只作为底层预处理层的输入
- 训练数据有限,对训练数据量的需求较大,需要大量数据来避免模型过拟合
- 现有使用注意机制关注力主要在图像的突出部分,而实际的篡改图像并不会都在图像的显著部分
给出解决办法:即论文的贡献及结论
四、模型及方法
1、模型结构简述
总体来讲,构建了一个由粗到细的网络,包括一个粗输出掩码和一个精输出掩码,包含了一种称为自对抗训练策略的两阶段训练策略来执行训练。下面为网络结构图:
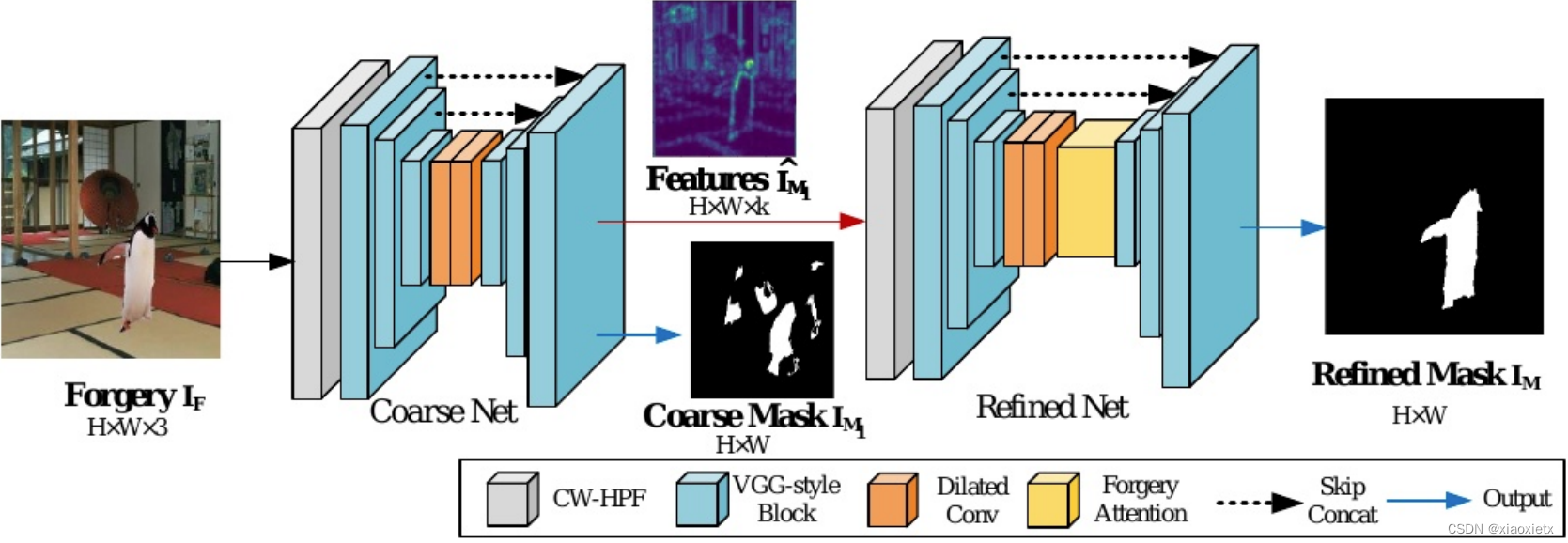
整个网络包括两个子网,即粗网和细网
- 粗网结构(CW-HPF–>VGG–>Dilated Conv–>VGG):
-
CW-HPF:可以用于任意输入通道,可以放在框架的任意位置/分支中,总体来讲,输入为 R H × W × C R^{H×W×C} RH×W×C,输出为 R H × W × 3 C R^{H×W×3C} RH×W×3C。
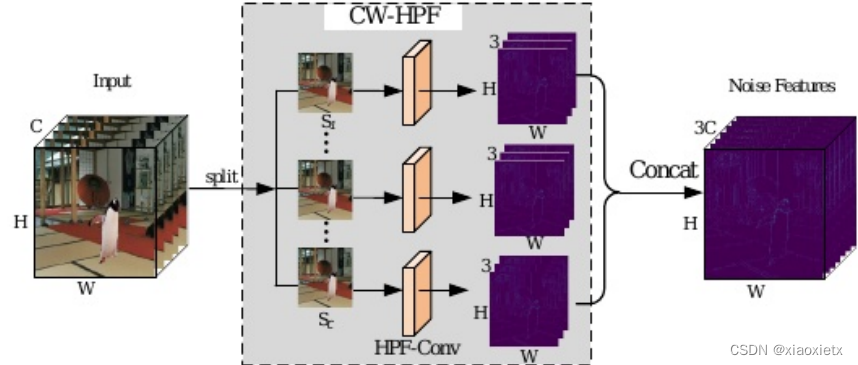
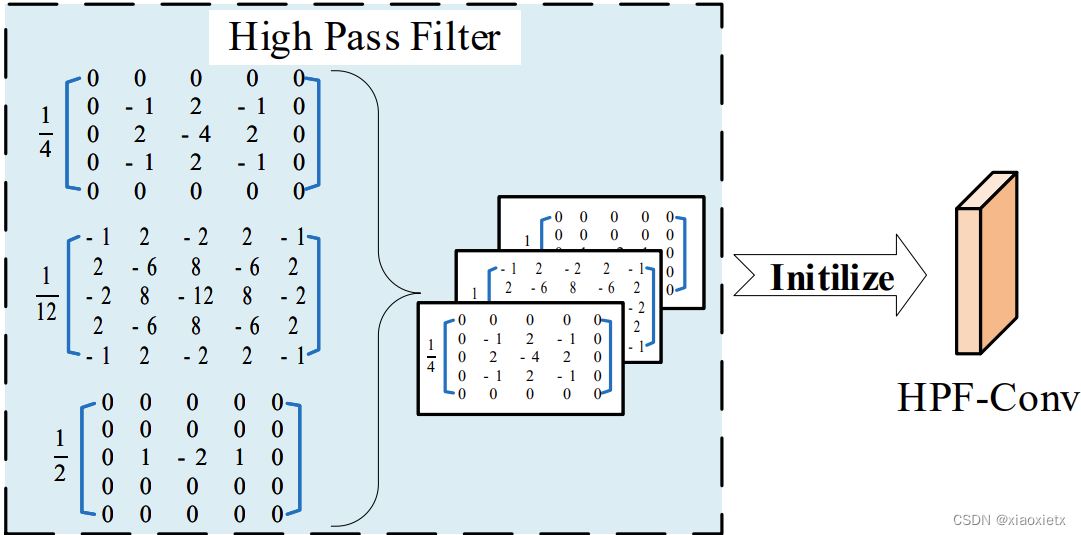
具体为将输入的特征转换为C个特征映射,在粗网里面即将图像的3个通道分别作为输入,对每个通道使用来自SRM的三个高通滤波器(5×5×3)——包括一个KB滤波器(检测水平边缘)、一个KV滤波器(检测垂直边缘)、一个一阶核,所以每个通道C输出为3C。最后将每个通道的结果连接起来作为原图的噪声特征。需要注意的是,CW-HPF不需要进行学习,三个卷积核均由手工决定。 -
-
VGG-style Block:整个VGG块包含三个或四个堆叠的卷积层,内核大小为3×3。在粗网中VGG有五个模块,其中前三个模块对噪声特征进行编码,后两个模块进行解码。最大池化层在前两层对特征进行下采样,它们的输出分别与第四第五层进行跳跃连接,第四、第五层为上采用层。
-
Dilated Conv:孔洞卷积层,在普通卷积的情况下插入来膨胀卷积核,使得其有更大的感受野。四个孔洞卷积的扩展率分别为:2、4、8、16
-
- 细网结构(CW-HPF–>VGG–>Dilated Conv–>Forgery Attention–>VGG):
- 整体与粗网结构类似,CW-HPF的输入变为了16个通道。下面重点放在伪造注意上面
- Forgery Attention:
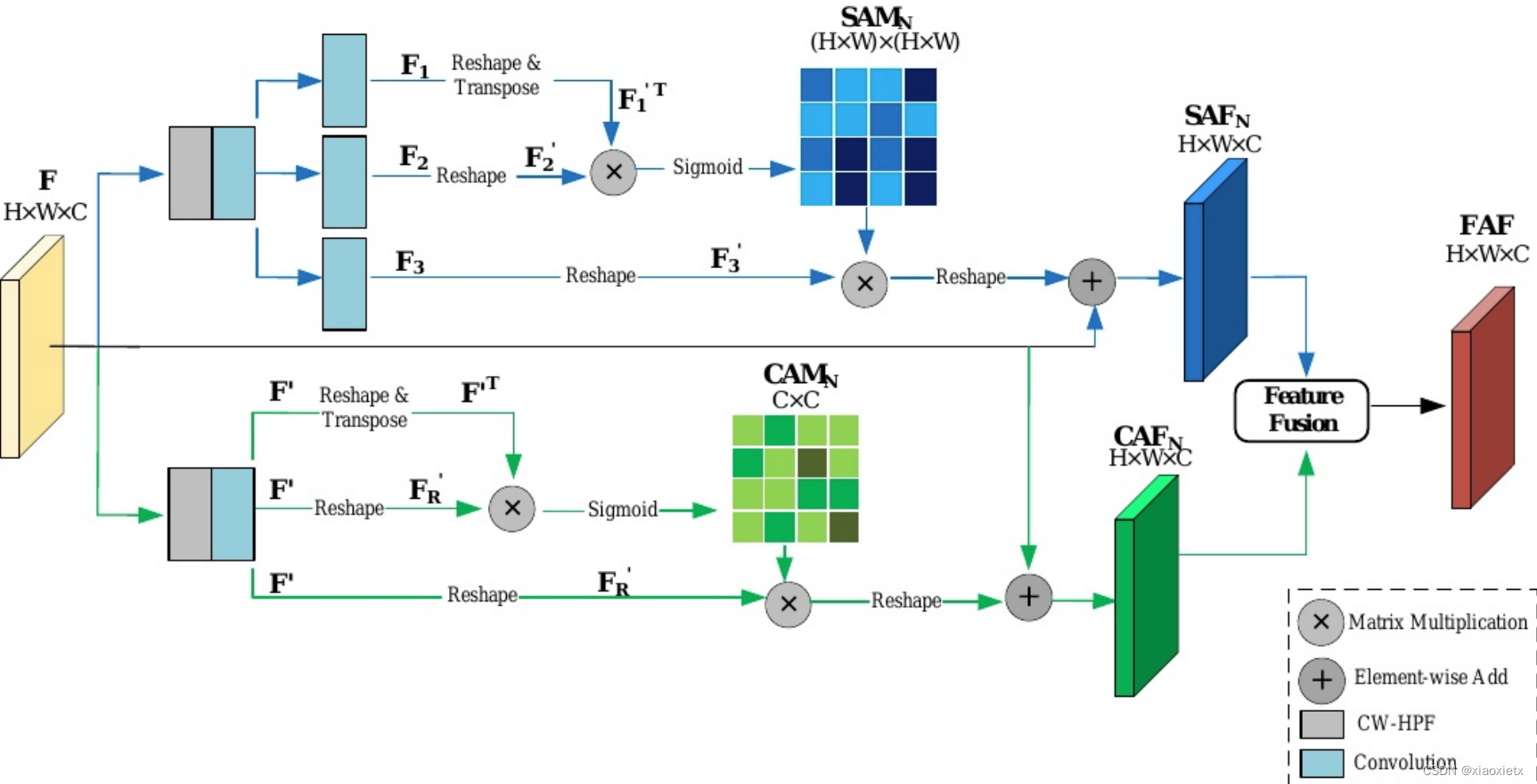
- 整体的伪造注意机制有两个部分组成,分别为空间维度与通道维度
- 空间维度可以用这个公式来概括: S A F N = γ ( s i g m o i d ( F 1 ′ T × F 2 ′ ) × F 3 ′ ) + F SAF_{N}=\gamma(sigmoid(F_{1}^{'T}×F_{2}^{'})×F_{3}^{'})+F SAFN=γ(sigmoid(F1′T×F2′)×F3′)+F,其中F为前面网络给出的特征向量,图中的F1、F2、F3为F经过三次卷积以后的结果,形状都为 R H × W × C R^{H×W×C} RH×W×C,接下来会经过一次reshape,变换为 R ( H × W ) × C R^{(H×W)×C} R(H×W)×C,经过矩阵乘法运算得到的结果 S A M N SAM_N SAMN形状为(H×W)×(H×W),最后再和 F 3 ′ F_3^{'} F3′运算,结果变换为原大小H×W×C。
- 通道维度可以用这个公式来概括: S A F N = δ ( s i g m o i d ( F ′ T × F R ′ ) × F R ) + F SAF_{N}=\delta(sigmoid(F^{'T}×F_{R}^{'})×F_{R})+F SAFN=δ(sigmoid(F′T×FR′)×FR)+F,其中F为前面网络给出的特征向量, F ′ F^{'} F′为F的卷积结果,进一步将其中一个reshape为 F R ′ F_R^{'} FR′,形状为(H×W)×C,经过与 F ′ T F^{'T} F′T进行矩阵乘法后,得到的 C A M N CAM_N CAMN形状为C×C,最后与 F R ′ F_R^{'} FR′运算,结果变换为原大小H×W×C。
- 两个维度所要学习的参数为变换的矩阵以及 γ 、 δ \gamma、\delta γ、δ,两个参数初始化为0,通过反向传播进行更新。
2、自对抗训练
用以解决训练数据不足的问题,根据模型学习的梯度生成对抗样本进行训练学习。SAT不仅在训练过程增强了模型的鲁棒性,且动态提供训练数据提高了模型的性能。
作者在文中将其概述为两个训练阶段: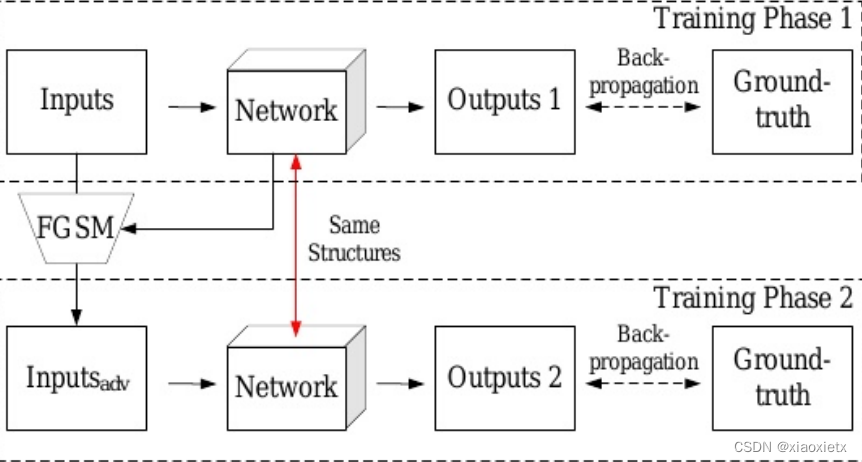
- 其中第一个阶段和传统训练过程一样,使用伪造图像 I F I_F IF以及对应的ground-truth-mask y g t y_{gt} ygt进行训练
- 第二个阶段,首先使用快速梯度符号法(FGSM)生成对抗图像
I
a
d
v
I_{adv}
Iadv,以该图像以及模型训练更新的最新梯度为依据生成第二阶段的输入,将其与对应的mask进行训练后更新权重信息。
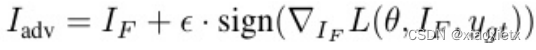
五、实验
实验内容大致是与其他网络进行比较,显示模型的优秀性能。作者也进行了消融实验,进一步研究各个模块在网络中的作用,具体实验细节不在此赘述,参考原文。















 411
411











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









