






1、为什么要做
Part 2我们提到的AB实验的方法,因为足够的随机性能很好控制观测变量之外的其他变量的影响,几乎是因果推断领域的大杀器;
但是在实际的业务中,我们总是会有很多不能做ab实验的场景,诸如:
-
医学新药的测试
-
受PR对外通传影响
这个时候,我们大概率只能全量上线策略,该场景下,全量评估的核心思想可以理解为
构造反事实对照组,即在同一个时空条件下,模拟出未全量上线策略的【预估值】
真实上线策略的【真实值】- 【预估值】 = 该策略效应
2、常见的几种方法
| 使用场景 | 方法 | 核心原理 | 局限性 | |
| 城市粒度评估 | 1、策略在部分城市全量上线; 2、存在足够多的没有上策略的对照城市 | Causal Impact | 根据对照城市和策略城市AA期时序特征的相似性,构造实验城市的反事实对照组;可以灵活加入时序特征,例如局部趋势、季节性趋势 | 1、 AA期需要足够长 4周以上; 2、评估周期不能太长,最长2-3月 3、评估周期不能太短,最好是1周以上 |
| 合成控制法(Synthetic Control) | 根据对照城市和策略城市AA期时序特征的相似性,但未考虑时序特征,适合没有时序特征的指标数据 | 增量检验基于排序秩检验,p值精度取决于城市数目,精度普遍欠缺 | ||
| 个体粒度评估 | 1、策略未经过随机分流全量上线;2、策略仅在部分城市上线 3、策略渗透率较低 4、有足够数量的可选对照组 | 倾向性得分匹配(PSM) | 拉齐高维特征,通过匹配得到“相似人群”,简单直观好理解 | 需要较多人工介入 很可能存在匹配率足够高,但AA不通过的情况,受不可测量混淆变量影响大 |
3、 PSM
【1】提出背景
在part1 ,我们已经了解到观测数据中干预的分配往往会受到个体特征的影响,即我们观测到的评估指标的差异不仅包含了干预的效果,还混杂了两组之间本身的特征差异,也就是存在混杂因素(confounding variable)。
匹配(Matching)是解决上述观测性因果推论问题常用的一类方法,它通过将实验组和对照组的个体按照可观测的特征进行匹配,为每个实验组个体寻找相似个体作为反事实对照,匹配过后的个体除是否接受处理外并无显著差异,所以就在一定程度上缓解了自选择偏误。
而在真实的业务场景下,由于混杂变量复杂繁多,匹配时往往需要考虑高维特征,且包含连续变量,这就会出现数据稀疏问题,导致直接匹配不可行,Rosenbaum and Rubin (1983)提出了倾向性得分匹配(Propensity Score Matching, PSM),它通过函数关系将对比个体相似性从多维度特征降维到一维的倾向性得分(Propensity Score)来解决上述匹配的难点问题。
【2】假设条件
-
条件独立假设(Conditional Independence Assumption, CIA): 给定一系列可观测的协变量 X ,潜在结果和干预分配相互独立。
(Unconfoundedness)
若上式成立,则潜在结果与干预分配基于 P(X)同样条件独立,即
(Unconfoundedness given PS)
-
共同支撑(Common Support):具有特征X的个体,倾向分既不能恒为0,也不能恒为1。这个假设保证了在给定X条件下(按X分层),层内均有实验组和对照组两组个体(也正因为如此才有匹配的空间)。
在进行匹配时,为了提高匹配质量,通常仅保留倾向得分重叠部分的个体,这样做会损失样本量。若共同取值范围太小,则会导致偏差。
【3】适用场景
1、受限于种种条件,不能做ab,全量上线策略,策略覆盖人群和未覆盖人群有一定量级,有丰富的的个体粒度数据,有丰富的特征用以匹配,从而找到相似用户;
2、AB实验策略渗透率低,即入组用户中仅有小部分被策略实际影响,评估整体效果往往不显著。
【4】核心流程
1、拟合倾向分模型
选择匹配用的协变量,从理论上来说,所有对影响干预分配和结果的变量应该被包括,被干预项影响的变量应该排除(变量需要在干预项前计算)
基于选定的协变量集,通过“probit”或“logit”模型来计算个体进入处理组的概率(倾向值),或者说预测用户被干预的概率,其实就是一个常见的二分类问题,常见的机器学习模型都可以在这里使用。 通常在实际应用中我们会选取尽量多的特征,同时也会用到一些机器学习中常规的特征筛选方法。
倾向值匹配就是一种用个体接受处理的倾向性(propensity)的差值作为距离来对样本进行匹配的方法
2.进行匹配
完成倾向分模型及预测后,每个样本会得到一个propensity score,此时便可以进行匹配步骤了:为每个被干预的样本匹配一个(或多个)虚拟的对照样本。
匹配的基础思路很简单,即找到一个距离最近的样本,实具体方法按照渐进的顺序阐述如下:
·最邻近匹配(nearest neighbor matching)
将控制组中与处理组倾向得分差异最小的个体进行匹配。虽然处理组所有个体都能匹配成功,但是不放弃任一处理组个体可能影响匹配质量,降低处理效应的精确度。
·半径匹配(radius matching)
提前设定卡尺,按照半径范围寻找控制个体进行匹配,卡尺越小匹配严格程度越高。
·核匹配(kernel matching)
将处理组样本与由控制组所有样本计算出的一个估计效果进行配对,其中估计效果由处理组个体得分值与控制组所有样本得分值加权平均获得,而权数则由核函数计算得出。
· 分层区间匹配Stratification and Interval Matching
分层匹配可以看作radius matching的一种相似版本,即将倾向得分分成多个区间,在每个区间内进行匹配。需要注意的是,分层的依据除了propensity score,也可以用一些我们认为重要的特征(如性别、地区),在相同特征的用户间进行匹配。
3、 匹配质量检验
【1】AA指标的显著性检验
匹配后的实验组和对照组足够“相似”,那么被干预前这两组在核心指标上应无显著差异。这样的检验通常基于t检验,核心指标一般选取干预前的评估指标,如评估指标为30天GMV,那么检验指标一般为干预前30天的GMV。
需要注意的是,当样本量较大时,t检验可以检测出细微的差异,非常容易显著,这时建议参考下面介绍的平衡性检验判断匹配质量。
【2】倾向分重叠情况
方法1: 可视化倾向分分布,如果两组分布几乎重叠,则匹配较为成功;
方法2: 通过KS检验判断两组倾向分分布是否无显著差异
【3】协变量的平衡性检验
对于连续型协变量,通过标准均值差(Standardized Mean Difference, SMD / Standardized Bias, SB) 我们可以衡量协变量在实验组和对照组分布的差异大小 (Stuart, 2010),不同于t检验,它不受样本量的影响。其计算可以简单地理解为两组均值的差/合并标准差,具体计算公式如下:
通常会认为d < 0.05是比较好的;
对于分类型协变量,可以采用卡方独立性检验判断匹配后变量分布是否相同,是否与分组无关。
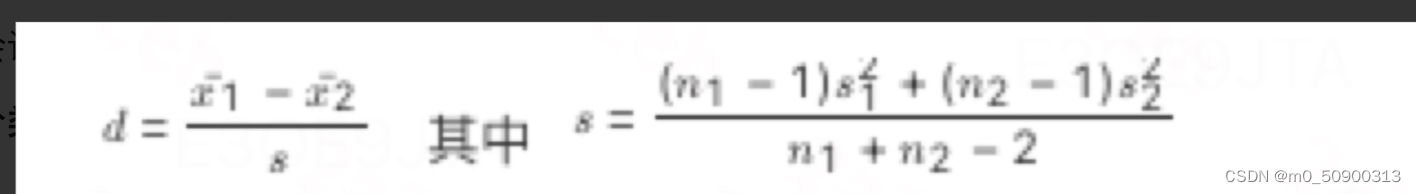
特别地: 关于模型调参数与修正
要实现较高的匹配质量还是比较难的,不断调参很多时候是必要的,具体来说可以做的事情类似:
-
通过因果机制推断,增加或删减匹配特征
-
更换倾向分模型,或调整倾向分模型参数
-
缩小匹配半径,以牺牲匹配率为代价换来更高的匹配精度
-
进行分组匹配,或调整分组维度
4、Causal Impact
背景
前序的PSM方法通过解决自选择偏差,能够帮助我们评估人均完单、人均gmv等诸如等ATE口径的指标, 但在全量上线的场景下,如果想评估比率指标,这时候psm 就不能很好解决这一问题, 在反事实框架下发展起来的观测性因果推断为上述全量评估问题提供了解法,2015年Google提出了Causal Impact方法。
优点:
-
对比双重差分法(Difference-in Difference,DID)基于静态回归模型,Causal Impact本身就是时间序列的预测,解决了DID且策略效果不随时间变化等在真实业务场景中很难满足的假设问题;
-
对比经典的合成控制法(Synthetic Control)也是合成虚拟对照组,但是Causal Impact允许更灵活地加入时序特征信息,且基于贝叶斯框架可以将关于模型参数的先验知识作为数据来源之一,从而得到更准确的反事实时序估计。
原理简述
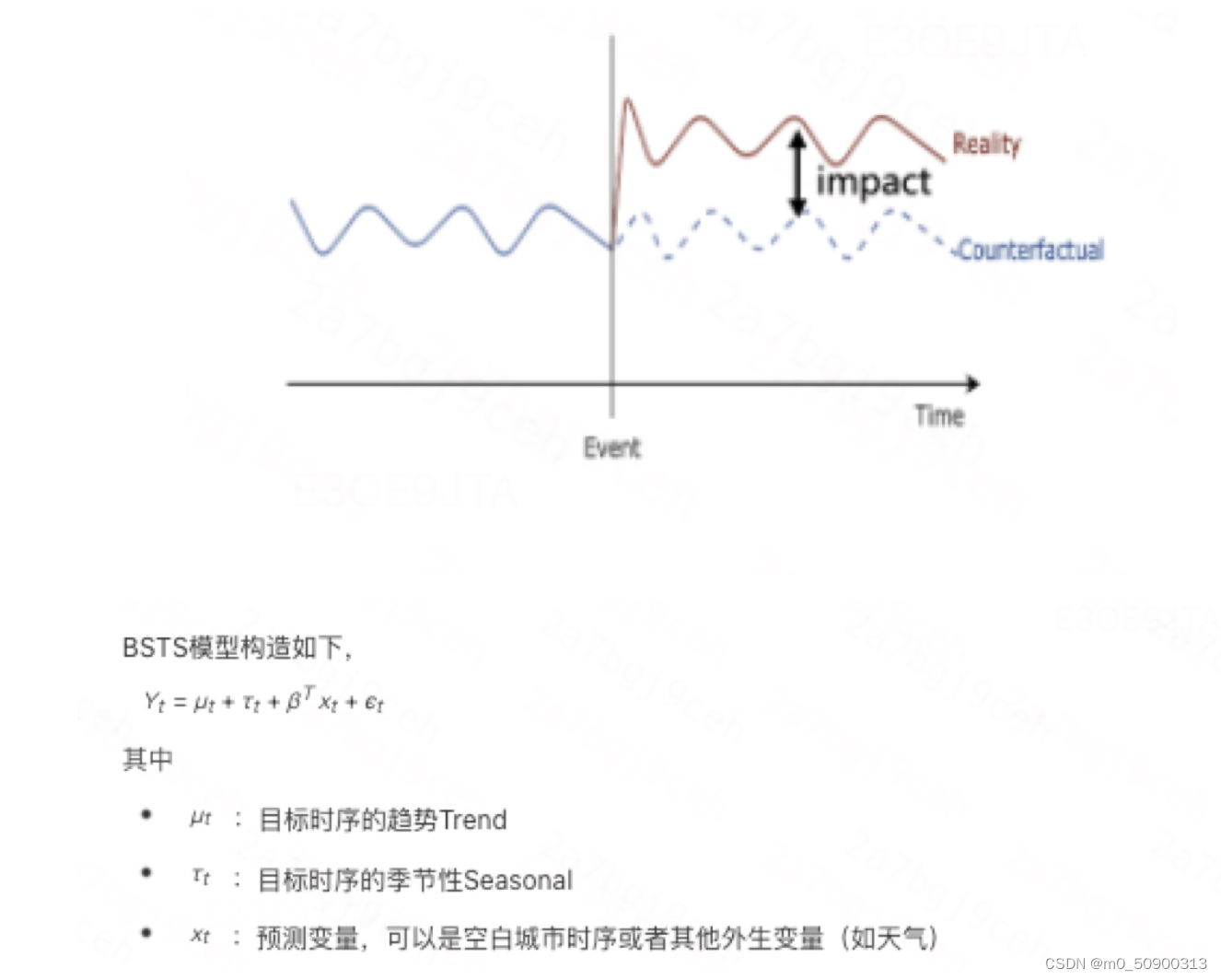
为了评估一段时期内某个城市(策略城市)全量上线的策略效果,Causal Impact基于贝叶斯结构时间序列模型(Bayesian Structural Time Series,BSTS),使用干预前策略城市的时序数据以及和策略城市时序高度相关的变量,合成策略城市的反事实时序基线,也就是说,如果不被策略干预,策略城市的时序会如何发展;然后通过比较反事实时序基线与策略城市时序间的差异估计策略效果。
假设条件:
-
策略城市时序自身存在的时序特征(如长期趋势Trend、季节性Seasonal)不受策略的影响。
-
control 不受treatment影响。 一般我们认为,A市上线策略并不会对未上线策略的B市造成任何干扰,因此会将未上线策略的空白城市时序作为预测变量来源之一
-
协变量(covariates)对treatment 时间序列在实验上线前后的影响稳定。
局限性
-
微小提升检测不灵敏:由于模型误差的存在,当预期提升较小时,很难检测出来。
-
评估周期不宜过长:随着预测期的延长,模型估计值的置信域会变宽,且时序间关系变化的可能性变大,基于拟合期数据得到的预测期反事实时序基线可能会有偏差。
-
难以得到”干净的“策略效果:时序变化往往影响因素众多且几乎不可能考虑周全(难以一一枚举或技术上难以都剔除掉),导致评估出的策略效果包含其他因素影响。
相关系列更多知识:关注gzh 《大佬等我呀》
实操:
r处理代码CausalImpact















 3044
3044

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









