






树莓派4B+Qtdesigner+PyQt5+OpenCv+Python3.9---图像超分辨实验
一. 准备工作
安装树莓派系统很简单,首先准备一个读卡器和一个内存卡(运行该项目我是用的是32GB的卡),之后在树莓派官网上下载Imager(提示:这个Imager的系统版本取决于你现在使用的电脑上是什么系统),之后按照提示安装烧录就可以咯。
树莓派里自带PyQt5,位置在usr/bin/python3/dist-packages
1.OpeCV下载
(版本是4.5.4),打开终端输入以下指令
pip3 install opencv-python==4.5.4.60;#在下方下载链接中查找与自己python版本对应的opencv包
opencv包下载链接(!刚开机就装不然后面有可能装不上!)
因为要使用预训练模型去处理图片,所以要有opencv-contrib-python包,一般在下载opencv的时候会自动下载。但是!有可能下载的是最新版opencv-contrib-python(4.7)不太适用于python3.9,所以保险起见换一个稍低的版本,之后下载完opencv后通过pip list指令查看有没有下载opencv-contrib-python包,这个包的版本要和opencv-python一样,不一样的话就先卸载然后安装指定版本。
pip3 uninstall opencv-contrib-python
pip3 install opencv-contrib-python==4.5.4.60#版本号要和你下载的opencv-python的版本号一样
2.下载 QtCreator
直接在终端中下载,里面包含QtDesigner。
sudo apt-get install qt5-default
sudo apt-get install qtcreator
下载完成之后在树莓图标下的编程可找到QtDesigner。
打开QtDesigner制作界面(界面制作流程可参考该博文(点击此处)),完成后在保存的.ui文件下打开终端,运行以下命令得到.py文件(xxx替换成相应的文件名)
alias pyuic5="python3 -m PyQt5.uic.pyuic"
pyuic5 xxx.ui -o ui_ xxx.py
3.导入相关包
import qimage2ndarray#在PyQt5中处理图片需要这个函数将图片转换为numpy数组
from cv2 import dnn_superres#用于建立超分辨工程
from skimage import color
from skimage.color import rgb2ycbcr
from skimage.metrics import structural_similarity#用于计算SSIM值
用以下命令安装相关包:
pip install scikit-image
pip install qimage2ndarray
如果下载失败可以在命令后挂清华园镜像网址:
pip install xxx -i https://pypi.tuna.tsinghua.edu.cn/simple
还可以选择离线下载安装方式,在PyPi网站(点击此处)直接搜索包的名称,在左侧的Programming Language选择python3.9(选择相应的python版本),之后会自动更新页面,在新的页面找到包的version就会适配你的python版本。
注意事项:
①skimage和scikit-image本质上是一个东西,导入的时候使用前者名称,下载的时候使用后者名称。
②skimage版本过低无法导入rgb2ycbcr模块,作为参考我的skimage版本是0.20.0。
③如果出现从OpenCV中无法导入dnn_superres模块的情况,请自查opencv-contrib-python包与opencv-python包版本是否相同,是否对应python的版本。(如果opencv下载按照我的来应该是可以导入该模块的)
二. 程序编写
1.选择图片
def btn_Openimage(self):#更换函数名
fname, filetype = QFileDialog.getOpenFileNames(self, '选择图片', '',
"*.jpg, *.png, *.JPG, *.JPEG, All Files(*)")
if fname != '':
self.image = fname[0]
pix = QPixmap(self.image).scaled(self.label.width(), self.label.height()) # 用QPixmap读取图片并使图片自适应label窗口大小
self.label.setPixmap(QPixmap(pix)) # 在label显示图片
2.使用模型处理图片
(其他处理图片方式例如对图像进行三次插值,也是差不多一样的,模型获取和具体信息参考该博文(点击此处)
self.image = self.label.pixmap().toImage()#读取第一个label的图片
img = qimage2ndarray.byte_view(self.image)#处理前将图片转换numpy数组
img = cv2.cvtColor(img, cv2.COLOR_RGB2BGR)
sr = dnn_superres.DnnSuperResImpl_create() # 创建一个超分辨工程
path = "model/FSRCNN_x4.pb"#模型文件和代码不能再同级文件夹中,否则无法读取模型文件
sr.readModel(path)#读取模型
sr.setModel("fsrcnn", 4)#设置图片放大倍数
img = sr.upsample(img)#对图片上采样
img = qimage2ndarray.array2qimage(img)#转换回QImage
pix = QPixmap(img).scaled(self.label1.width(), self.label1.height()) # 用QPixmap读取图片并使图片自适应label窗口大小
self.label1.setPixmap(QPixmap(pix)) # 在label显示图片
3.计算PSNR值
self.image = self.label.pixmap().toImage()#从第一个Qlabel中提取图片
img = qimage2ndarray.byte_view(self.image)#转换图片类型以精确计算结果
self.image1 = self.label1.pixmap().toImage()
img1 = qimage2ndarray.byte_view(self.image1)
psnr1 = cv2.PSNR(img, img1)#OpenCV里自带的函数计算posnr值
self.label_psnr1.setText('{:.2f}'.format(psnr1))#在指定Textlabel中显示
4.计算SSIM值
self.image = self.label.pixmap().toImage()
img = qimage2ndarray.byte_view(self.image)
self.image1 = self.label1.pixmap().toImage()
img1 = qimage2ndarray.byte_view(self.image1)
if img.shape[2] == 4:
img = color.rgba2rgb(img)
# 将图像从RGBA颜色空间转换为RGB颜色空间
if img1.shape[2] == 4:
img1 = color.rgba2rgb(img1)
img = img / 255.0#对像素做归一化处理
img1 = img1 / 255.0
# 将图像像素值转换为YCbCr颜色空间
img = rgb2ycbcr(img)
img1 = rgb2ycbcr(img1)
img = img[:, :, 0]
img1 = img1[:, :, 0]
img1, img = (img1 * 255).round(), (img * 255).round()#还原像素值
ssim = structural_similarity(img, img1, win_size=11, gaussian_weights=True, multichannel=True,
data_range=1.0, K1=0.01, K2=0.03, sigma=1.5)
self.label_ssim.setText('{:.3f}'.format(ssim))
5.使用摄像头捕获图片
self.cap = cv2.VideoCapture(0)#摄像头端口号
self.width = 640
self.height = 480
self.new_width = xxx#为了适应界面的显示窗口,一般设置为与窗口相同的大小
self.new_height = xxx
# 设置摄像头分辨率
self.cap.set(cv2.CAP_PROP_FRAME_WIDTH, self.new_width)
self.cap.set(cv2.CAP_PROP_FRAME_HEIGHT, self.new_height)
def btn_Captureimage(self):
self.cap.release()
cv2.destroyAllWindows()
# 重新打开相机,以便单独拍摄图片
self.cap = cv2.VideoCapture(0)
# 获取当前相机捕获的图像
ret, frame = self.cap.read()
# 显示当前图像
frame = cv2.cvtColor(frame, cv2.COLOR_BGR2RGB)
self.image = QImage(frame, frame.shape[1], frame.shape[0], QImage.Format_RGB888)
pixmap = QPixmap.fromImage(self.image).scaled(self.label.width(), self.label.height())
self.label.setPixmap(pixmap.scaled(xxx, xxx, QtCore.Qt.KeepAspectRatio))#这里的窗口参数同样设置为与窗口相同的大小
本来是想设置捕获的图片去自适应窗口大小,但是发现摄像头拍到的图片很大只会显示图片的一部分而不是整个,所以需要手动设置图片的大小。
三. 结果图
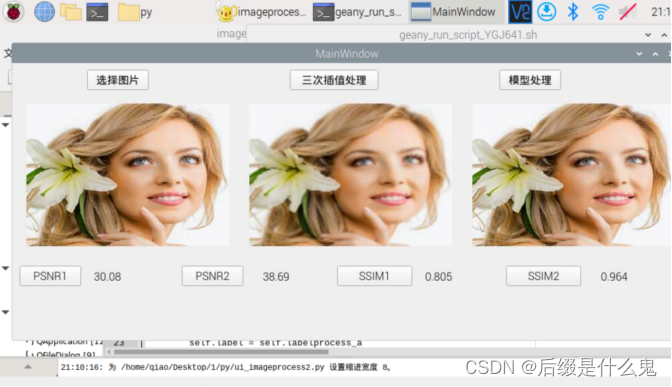
添加了三次插值处理作为对比,不知道为什么在这里使用的模型文件比FSRCNN源码处理效果还要好。
(栓q,实验老师希望不用现成的数据集的图而是用摄像头采集再处理报告都写完了)
(既然老师要求当然是尽量实现咯)
四. 错误类型
TypeError: argument 1 has unexpected type
槽函数connect调用加入lambda:定义
(后来生成一个新的ui转py文件查看代码,在connect调用那里把默认的“MainWindow”改成“self”)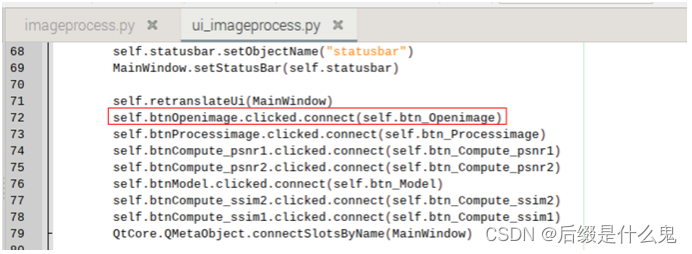
Pixmap is a null pixmap
改变图片格式的位深度(改为32)- 打开界面的时候
Could not load the Qt platform plugin提示应用程序无法在运行时加载Qt平台插件,如果按照路径删掉qt文件夹,界面就可以打开,但是无法使用dnn模块处理图片。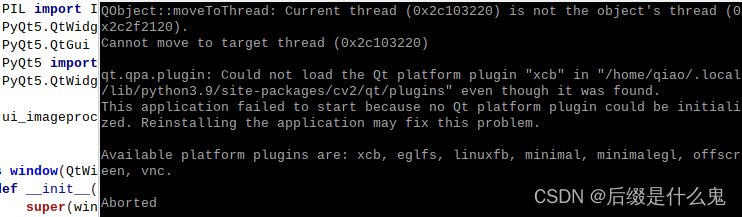
首先确保PATH环境变量正确配置,如果配置以后还是报错,那就将Qt插件目录添加到应用程序的路径,代码如下,之后重新运行程序。
import os
os.environ['QT_QPA_PLATFORM_PLUGIN_PATH'] = 'path/to/plugins'#记得换插件的路径
4.AttributeError: NoneType object has no attribute shape
该错误意味着没能读取到图片,需要检查图片路径(路径是否正确,路径下是否有图,路径中是否有中文)
5.ValueError: Input images must have the same dimensions.
计算两个图片的psnr值前需要确保两图像大小一样,如果不一样可以把其中一张图重塑为与另一张图大小一样的(一般被重塑的是尺寸较大的那张图)。
还有一些关于在树莓派上配置PyQt5、OpenCV以及Pycharm的细节可以参考这篇博文(点击此处)















 423
423











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









