







最近一段时间看了好多论文和优秀的帖子,非常感谢各位大佬的文章,深入浅出,使我受益匪浅,借着最近完成课程作业的机会,自己也做一个简单的总结。
这里是一些参考文章:
轻松理解 VQ-VAE:首个提出 codebook 机制的生成模型
VQGAN 论文与源码解读:前Diffusion时代的高清图像生成模型
近年来,由深度学习驱动的图像生成模型迅速发展,从生成对抗网络(Generative Adversarial Networks, GAN)和变分自编码器(Variational Autoencoders, VAE)等基础模型,到后来基于Transformer的图像生成模型、扩散模型等,模型生成图像的质量和多样性都有了显著提升。然而,虽然模型能够生成视觉上合理的图像,但在精细控制生成内容方面仍有不足,图像生成模型的可控性需求愈发明显。用户们不仅期望生成高质量的图像,还希望能够灵活地控制生成图像的内容,以满足个性化、多样化的需求。为此,研究人员提出了多种可控图像生成方法,通过输入额外条件信息、生成提示引导等方式,使得生成过程可以根据用户指定的条件进行调整,从而生成符合要求的图像。这种可控性大大扩展了生成模型的应用场景。
深度学习(Deep Learning)是机器学习(Machine Learning)中的一个重要分支,深度学习通过构建多层神经网络,从数据中自动学习复杂的特征,其“深度”的含义就是指网络的层数很多。自从2012年AlexNet[1]在ImageNet大规模视觉识别竞赛中取得了优异的成绩,把深度学习模型在比赛中的正确率提升到一个前所未有的高度后,以卷积神经网络(Convolutional Neural Networks, CNN)为代表的深度学习技术迅速成为人工智能领域的核心技术之一。深度学习的关键优势在于其能够处理大规模数据,并通过多层网络结构自动提取数据中的高层次特征,这使得它在计算机视觉、自然语言处理等领域取得了巨大的成果,同时在语音识别领域取得了更优的结果。图2-1是AlexNet网络架构的示意图。
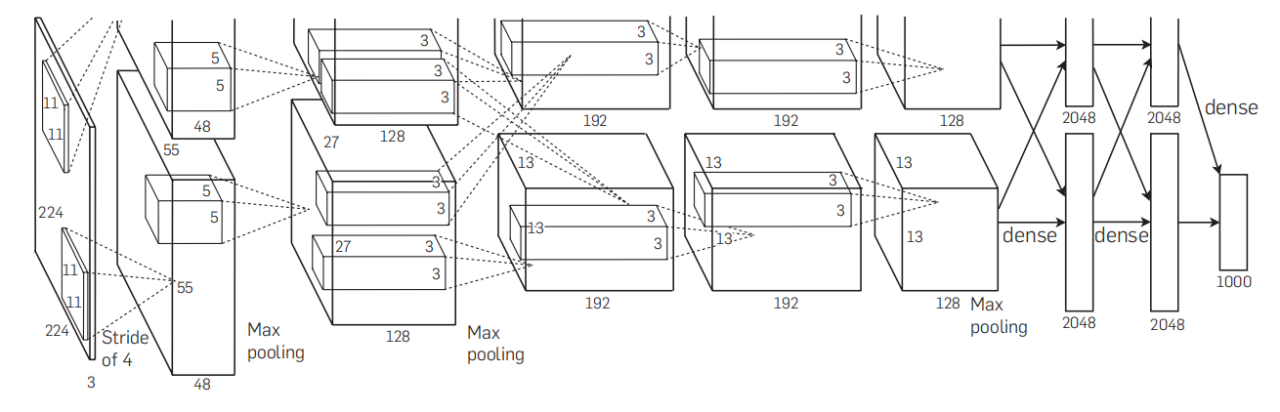
图 2-1 AlexNet网络架构的示意图[1]
Figure 2-1 Diagram of AlexNet Network Architecture[1]
1.2.1 计算机视觉
计算机视觉(Computer Vision, CV)是人工智能(Artificial Intelligence, AI)的其中一个领域,它使用机器学习和神经网络来训练计算机和系统,以便从数字图像、视频和其他视觉输入中获取有意义的信息。机器学习使用算法模型,让计算机能够自行学习视觉数据的上下文;当给模型输入足够多的数据时,由于神经网络的反向传播机制赋予了计算机的自学能力,无需人类实时编程就能使计算机逐渐准确识别图像。
深度学习在计算机视觉中的应用,特别是卷积神经网络CNN,已经成为解决图像分类、目标检测、图像分割等问题的核心技术。卷积神经网络通过模拟生物视觉系统的结构,利用卷积层、池化层和全连接层对图像进行处理,有效地提取图像的空间特征。在深度学习兴起之前,图像处理任务通常依赖于手工设计的特征提取算法。然而,深度学习的引入使得模型能够自动从原始图像中学习到丰富的特征表示,无需人工干预。深度学习技术的发展极大促进了计算机视觉领域的进步。
1.2.2 图像生成
图像生成是利用算法模型构建全新图像数据的一项重要研究方向,不仅包括图像的生成,还涵盖图像修复以及风格转换等相关任务。图像生成技术的历史可以追溯到1950年代,当时的研究者开始研究如何让计算机生成图像,随着计算机图形学和深度学习技术的发展,图像生成技术逐渐成熟,并在许多应用中得到广泛使用,如游戏、电影、设计等。如今的图像生成技术已经可以很方便地根据用户的需求和指示生成期望的图像,甚至可以对视频数据进行内容或风格的修改。
2、可控图像生成模型发展历史
本章节将回顾可控图像生成模型的主要发展历程,从生成对抗网络(GAN)到基于变分自编码器(VAE)和Transformer架构的生成模型,再到近两年来广受关注的扩散模型。本文将重点讨论这些模型的原理和优势。
生成式对抗网络GAN自Ian Goodfellow[2]等人提出后,就受到极大的重视。而随着GAN在理论与算法模型上的高速发展,它在计算机视觉、自然语言处理、人机交互等领域有着越来越深入的应用,并不断向着其它领域继续延伸。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 600
600

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









