







 本文介绍了注意力机制如何帮助模型区分重要和不重要的数据,通过点乘和softmax计算相似度,以及Transformer和BERT中多头注意力和位置嵌入的应用。对比了注意力机制与CNN和RNN的不同之处。
本文介绍了注意力机制如何帮助模型区分重要和不重要的数据,通过点乘和softmax计算相似度,以及Transformer和BERT中多头注意力和位置嵌入的应用。对比了注意力机制与CNN和RNN的不同之处。
原理
input&output
input: 一个向量 or 一系列向量
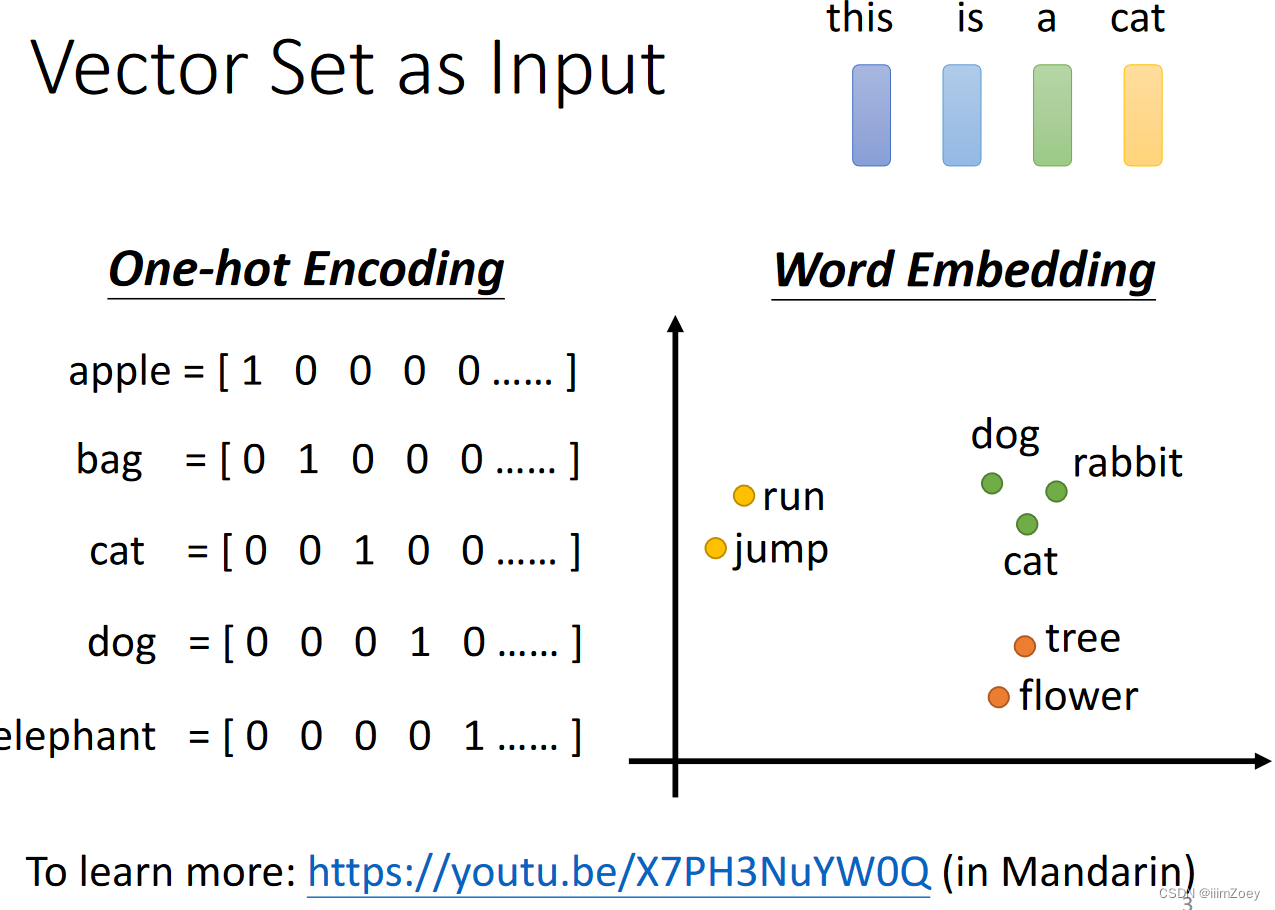
output:
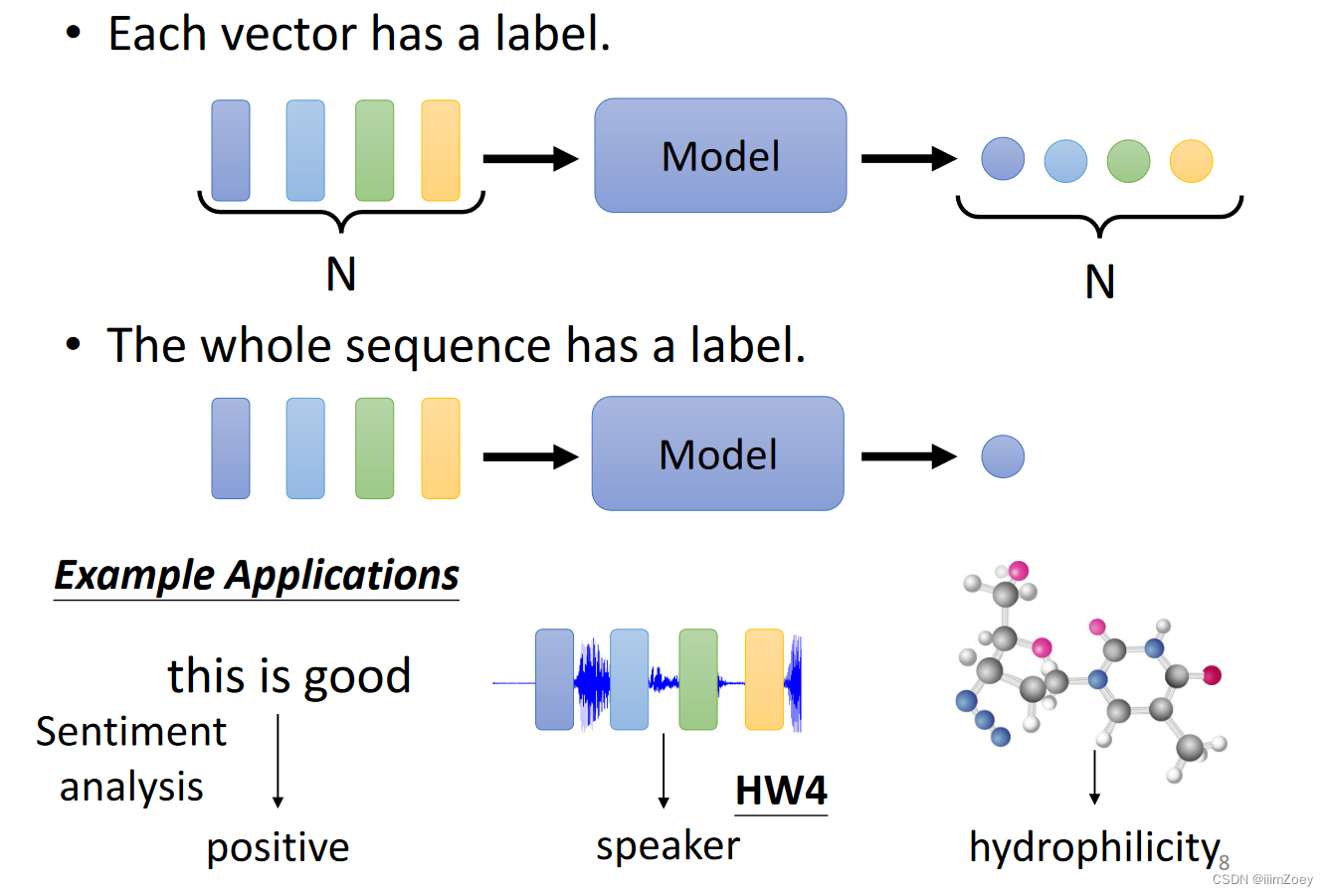
Each vector has a label.
sequence has a label.
Attention(注意力机制)
你会注意什么?
大数据(什么数据都有,重要的,不重要的)
对于重要的数据,我们要使用
对于不重要的数据,我们不太想使用
但是,对于一个模型而言(CNN、LSTM),很难决定什么重要,什么不重要
由此,注意力机制诞生了(有人发现了如何去在深度学习的模型上做注意力)
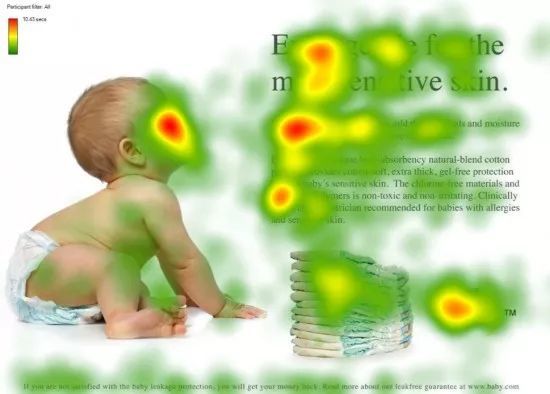
红色的是科学家们发现,如果给你一张这个图,你眼睛的重点会聚焦在红色区域
人--》看脸
文章看标题
段落看开头
后面的落款
这些红色区域可能包含更多的信息,更重要的信息
注意力机制:我们会把我们的焦点聚焦在比较重要的事物上
怎么做注意力
我(查询对象 Q),这张图(被查询对象 V)
我看这张图,第一眼,我就会去判断哪些东西对我而言更重要,哪些对我而言又更不重要(去计算 Q 和 V 里的事物的重要度)
重要度计算,其实是不是就是相似度计算(更接近),点乘其实是求内积(不要关心为什么可以)
Q,K=k1,k2,⋯,kn
,我们一般使用点乘的方式
通过点乘的方法计算Q 和 K 里的每一个事物的相似度,就可以拿到 Q 和k1
的相似值s1,Q 和k2的相似值s2,Q 和kn的相似值 sn
做一层 softmax(s1,s2,⋯,sn)
就可以得到概率(a1,a2,⋯,an)
进而就可以找出哪个对Q 而言更重要了

我们还得进行一个汇总,当你使用 Q 查询结束了后,Q 已经失去了它的使用价值了,我们最终还是要拿到这张图片的,只不过现在的这张图片,它多了一些信息(多了于我而言更重要,更不重要的信息在这里)
V = (v1,v2,⋯,vn)
(a1,a2,⋯,an)∗+(v1,v2,⋯,vn)=(a1∗v1+a2∗v2+⋯+an∗vn)
= V'
这样的话,就得到了一个新的 V',这个新的 V' 就包含了,哪些更重要,哪些不重要的信息在里面,然后用 V' 代替 V
一般 K=V,在 Transformer 里,K!=V 可不可以,可以的,但是 K 和 V 之间一定具有某种联系,这样的 QK 点乘才能指导 V 哪些重要,哪些不重要
51, 49---》 0.51,0.49
80/8,20/8 --》 0.9999999999, 0.0000000001
10 / 3 --> 0.9, 0.1
a1 和 a2 之间的差额越大,这个概率就越离谱
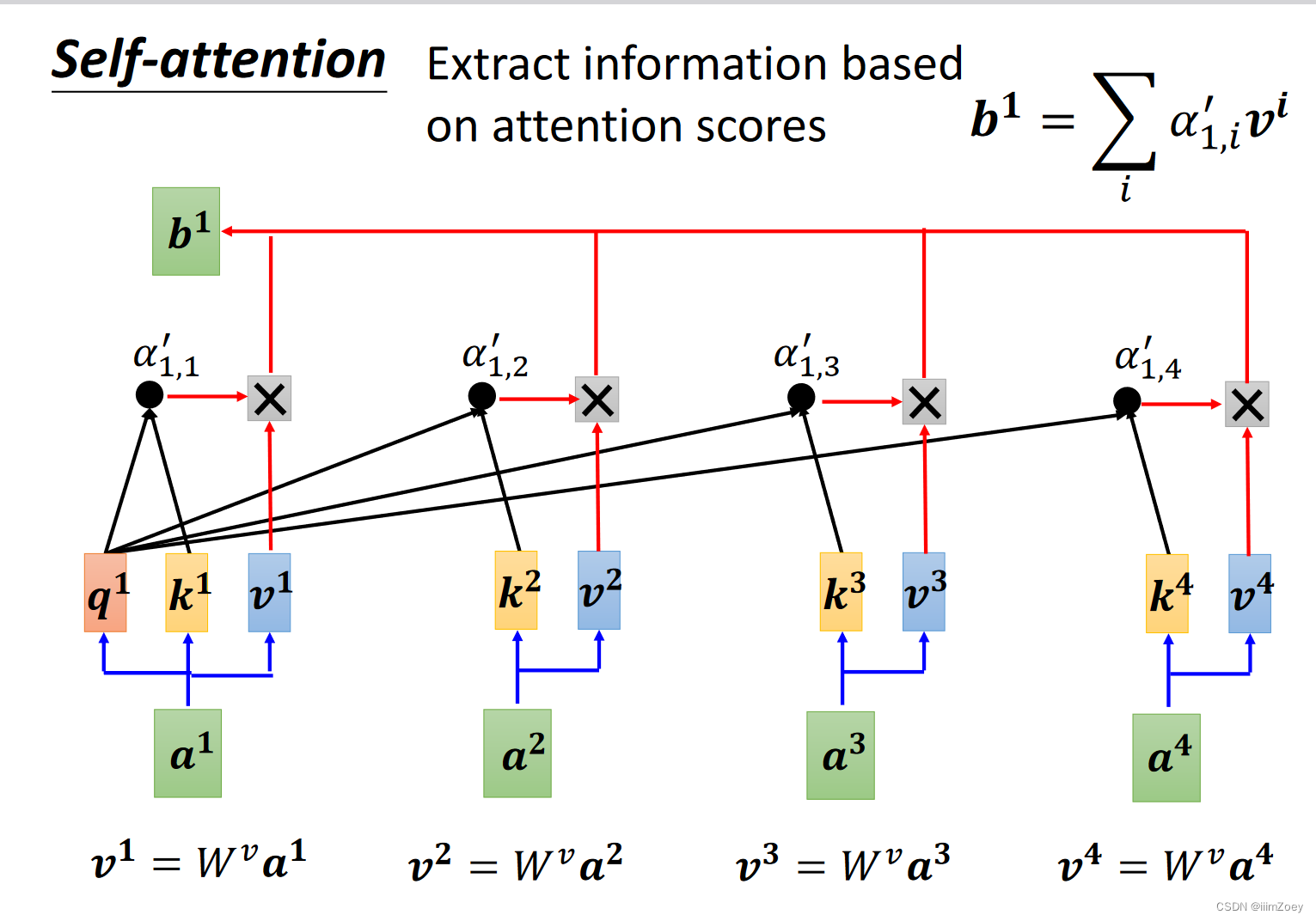
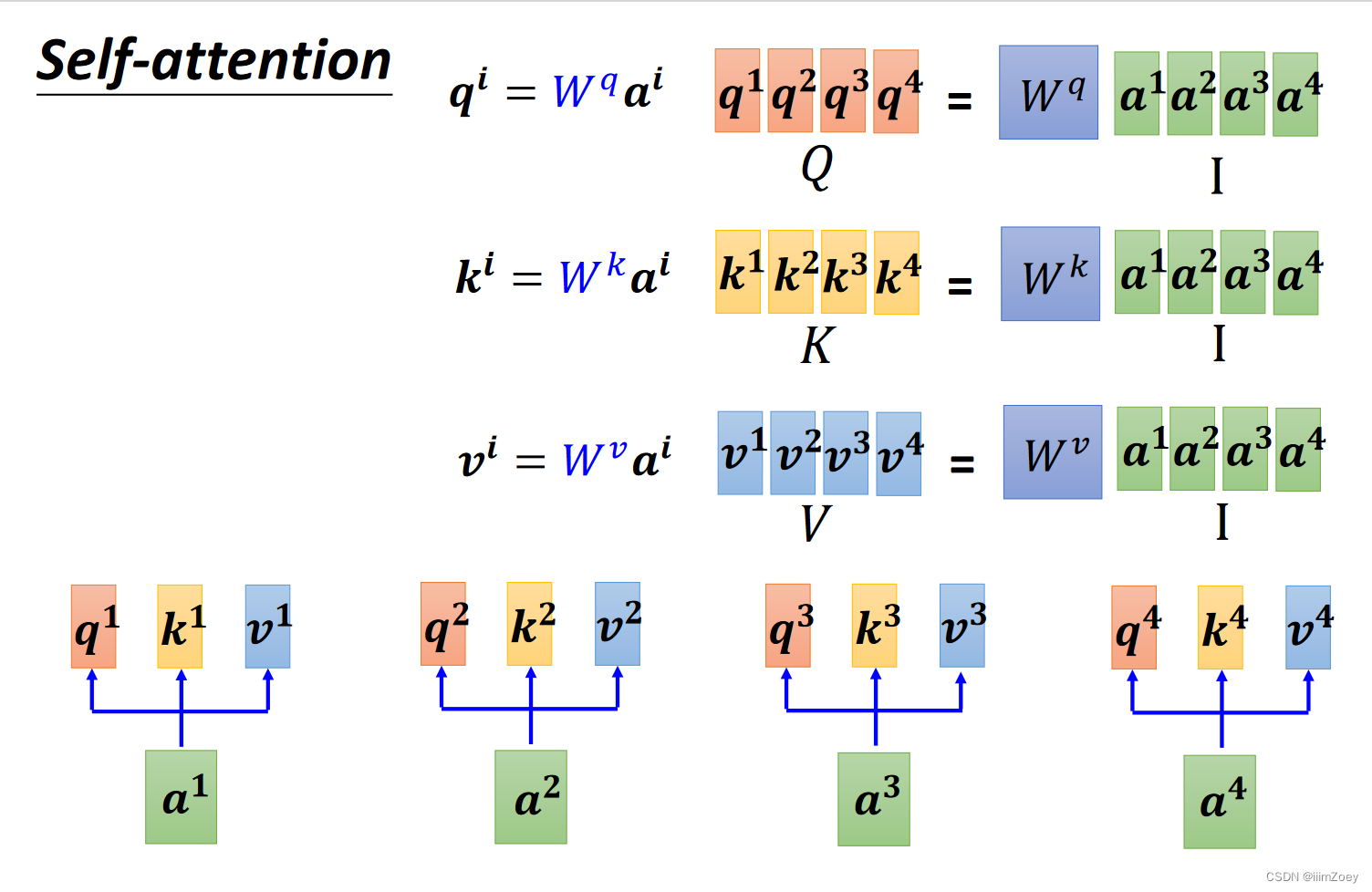
self attention
I saw a saw->n v det n,如何区分两个saw?此时要考虑全局信息,只考虑相邻neighbor,可以用fully connect(FC,Window),但是如果要考虑整个sequence,那window可以cover整个sequence,需要找到最长的sequence。此时提出self attention
I saw a saw->n v det n,分别表示a1,a2,a3,a4向量
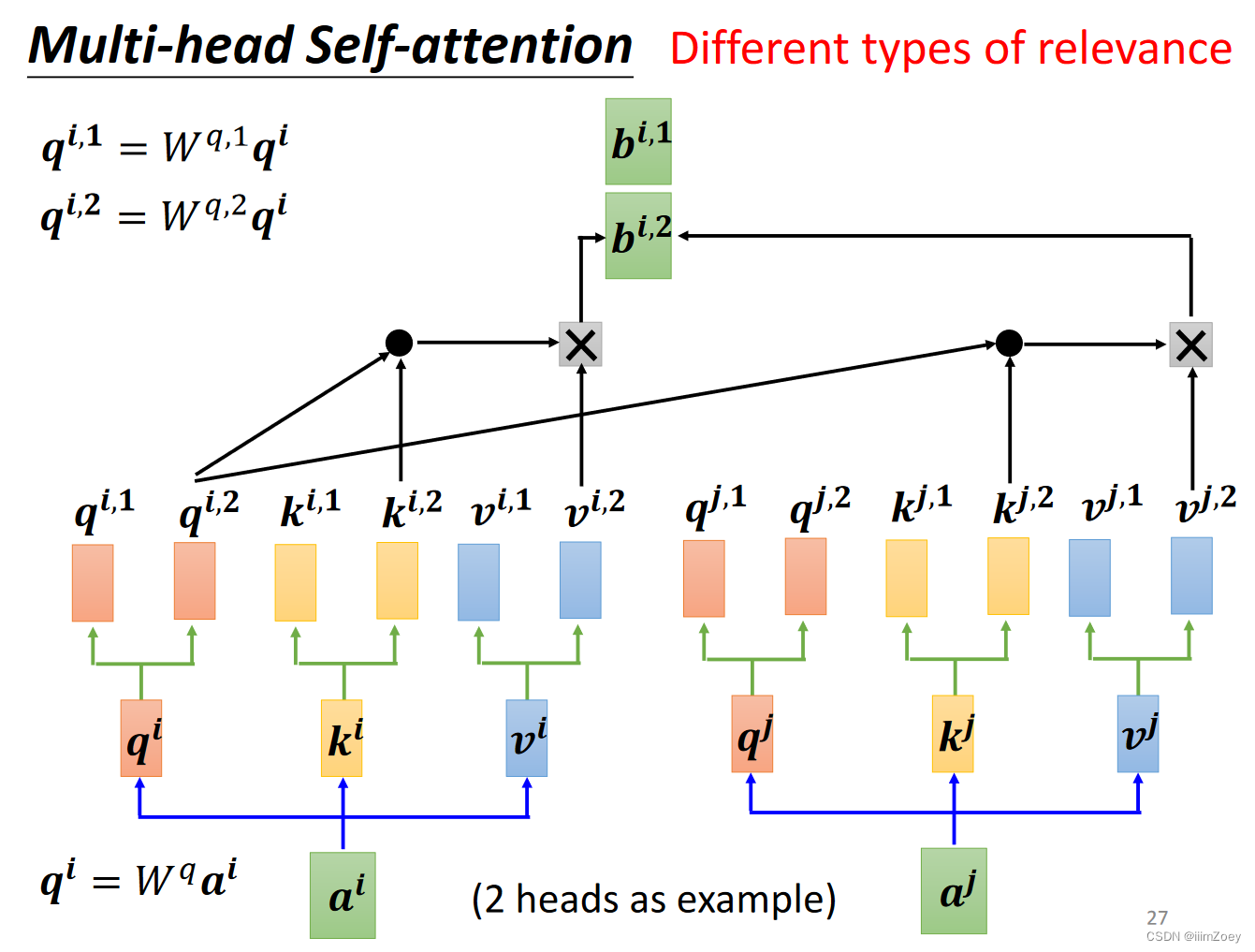
multi-head attention
分别乘两个矩阵,变成两部分,此时变成两个head(cnn里面的多channel)
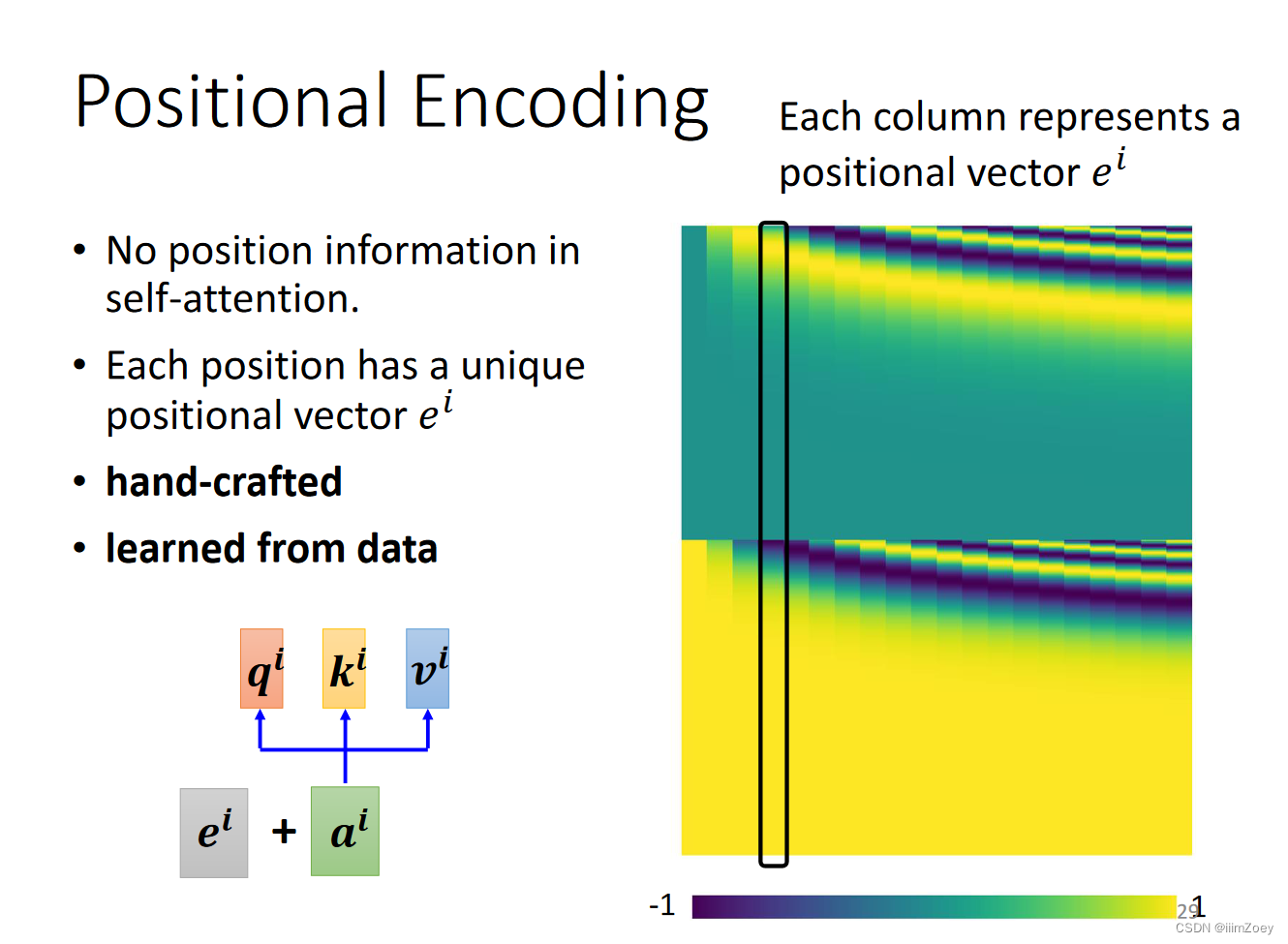
position embedding
四个位置操作一模一样
应用
广义的transformer其实就是self attention,Bert
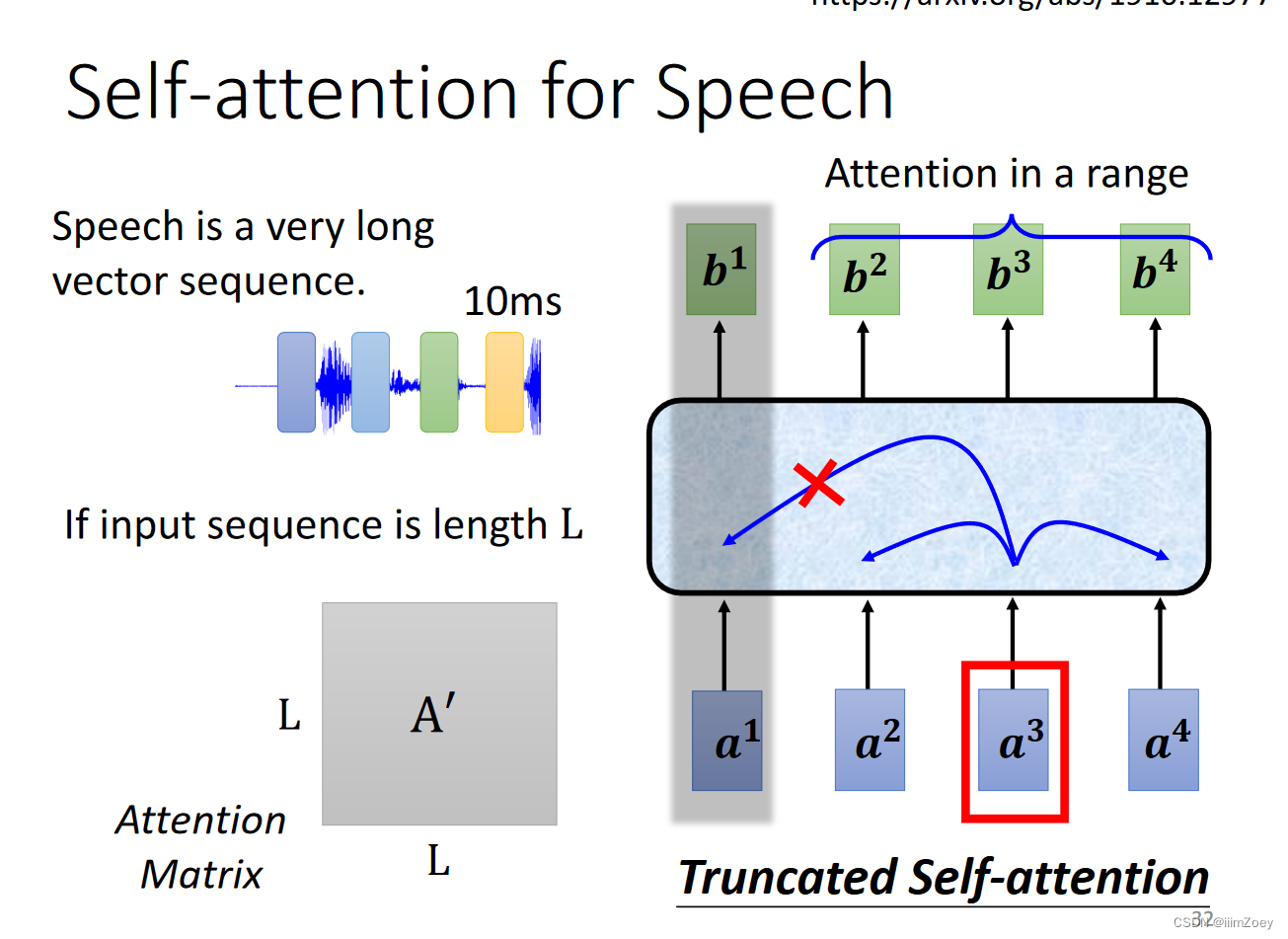
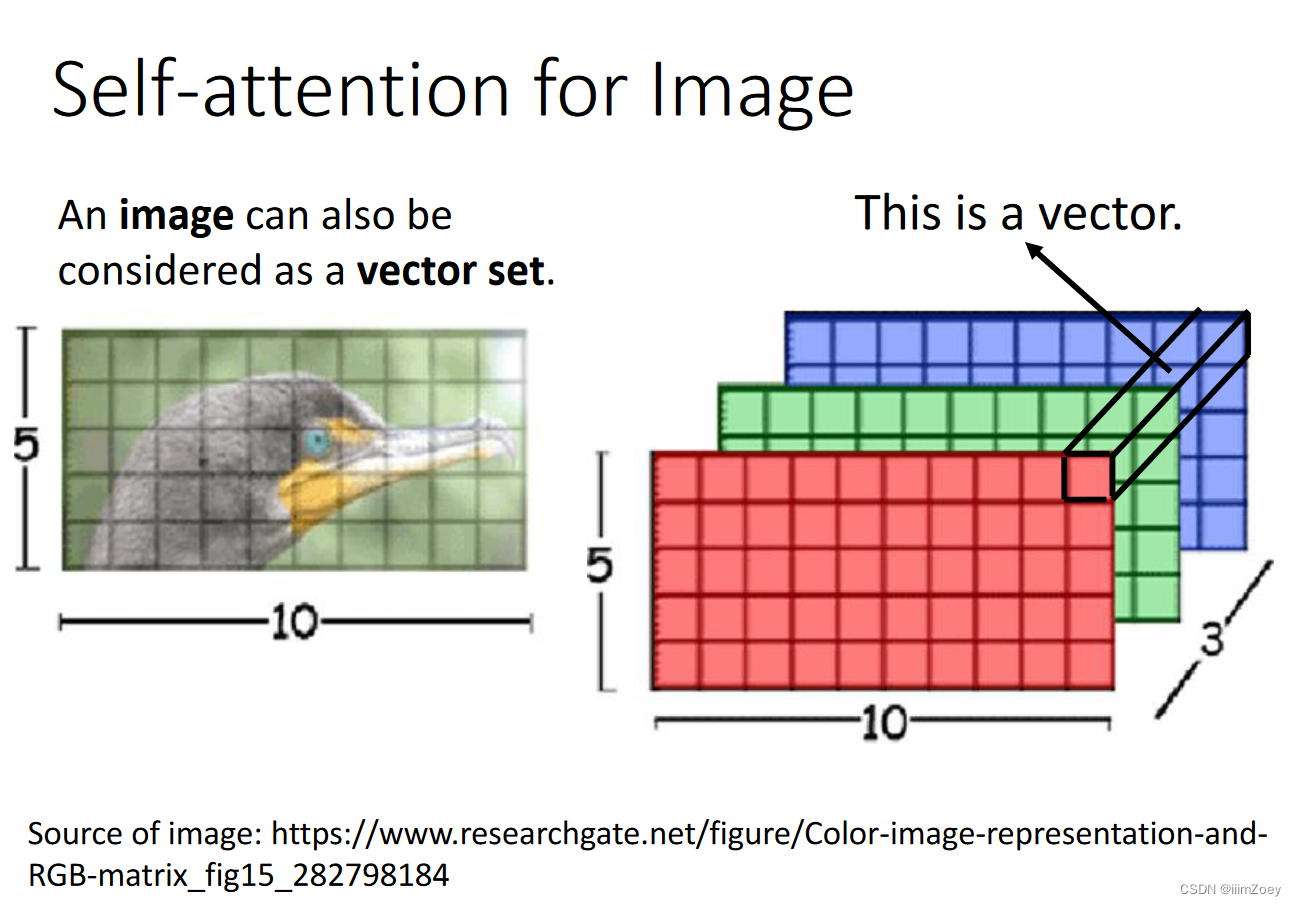
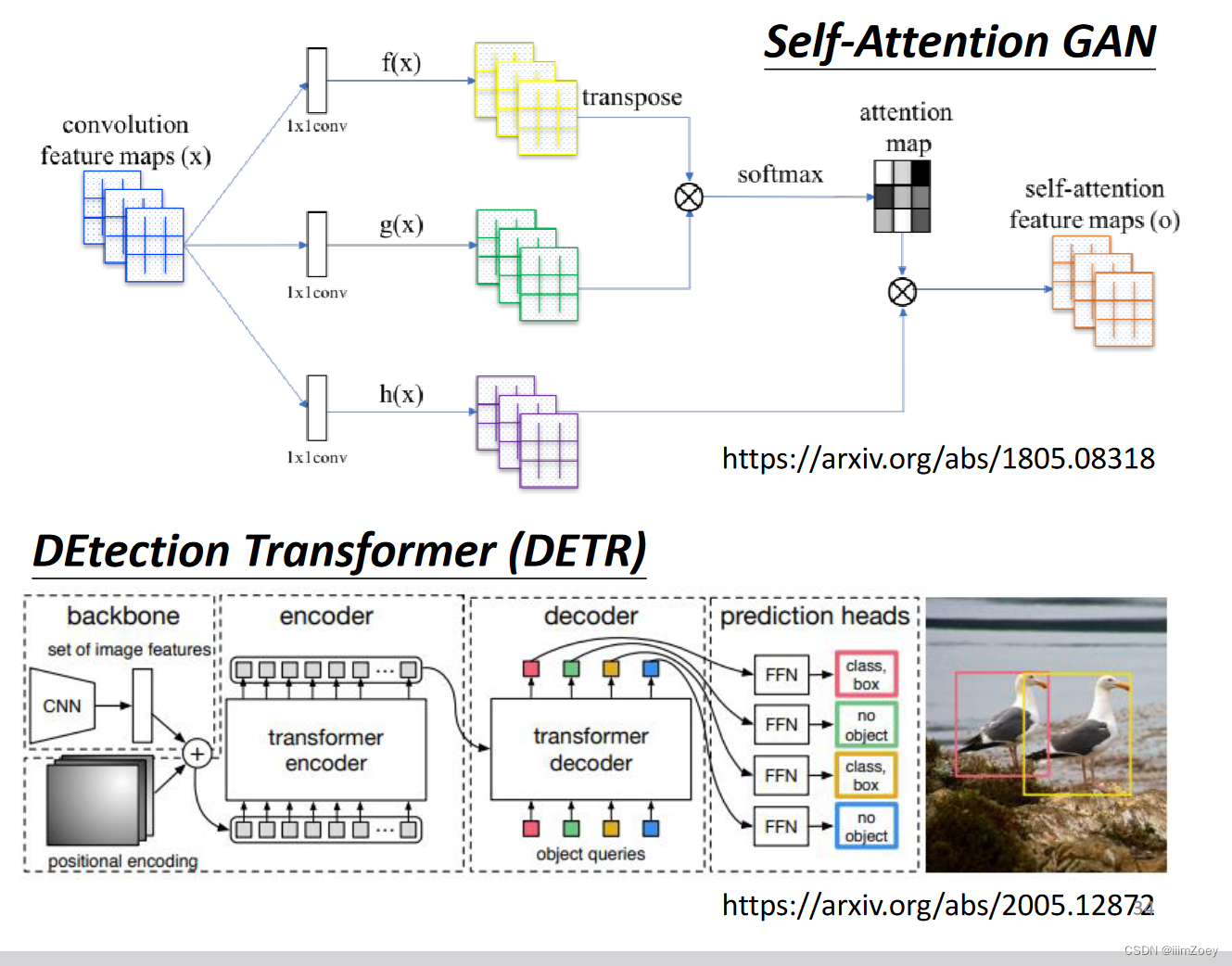
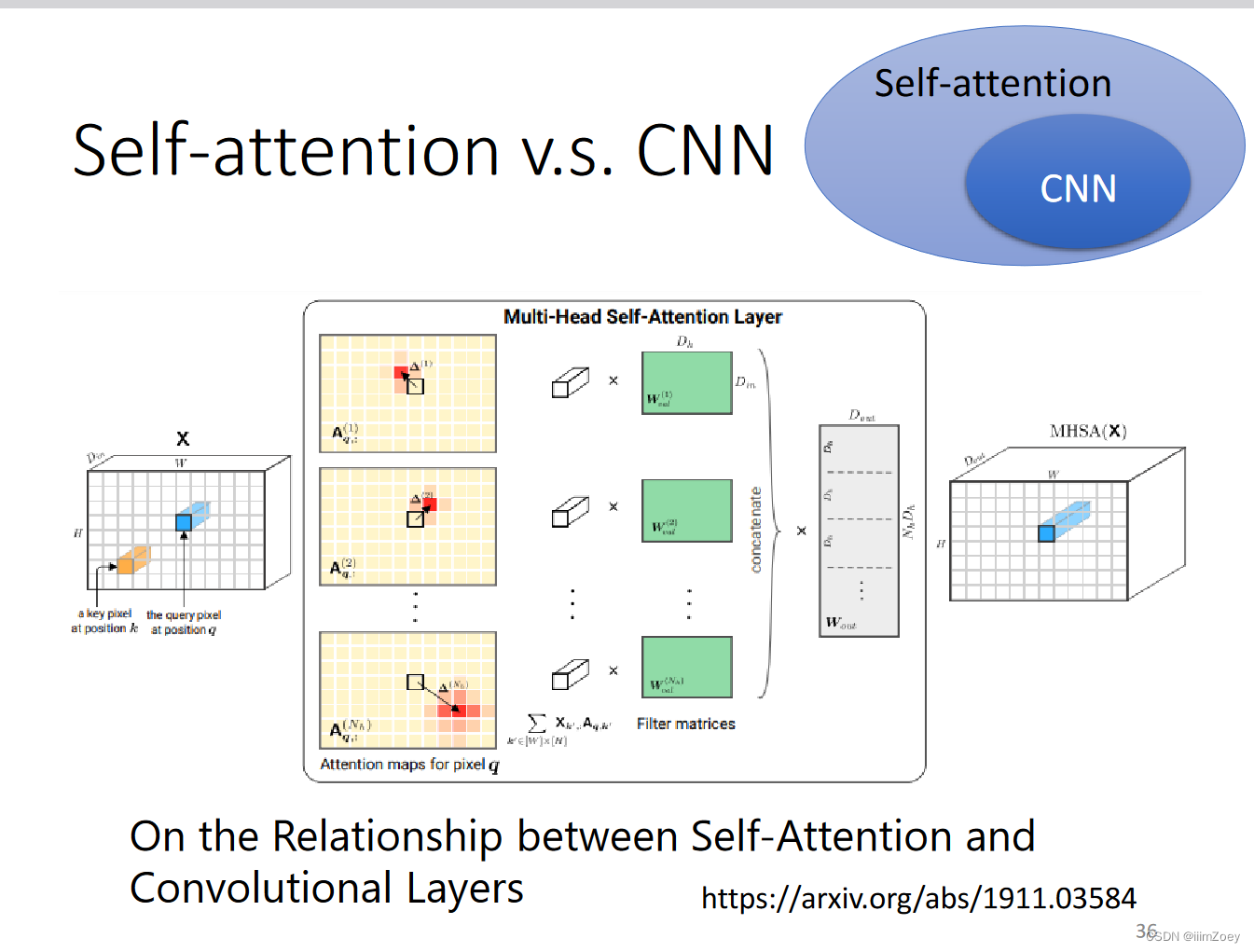
attention vs cnn
attention vs rnn

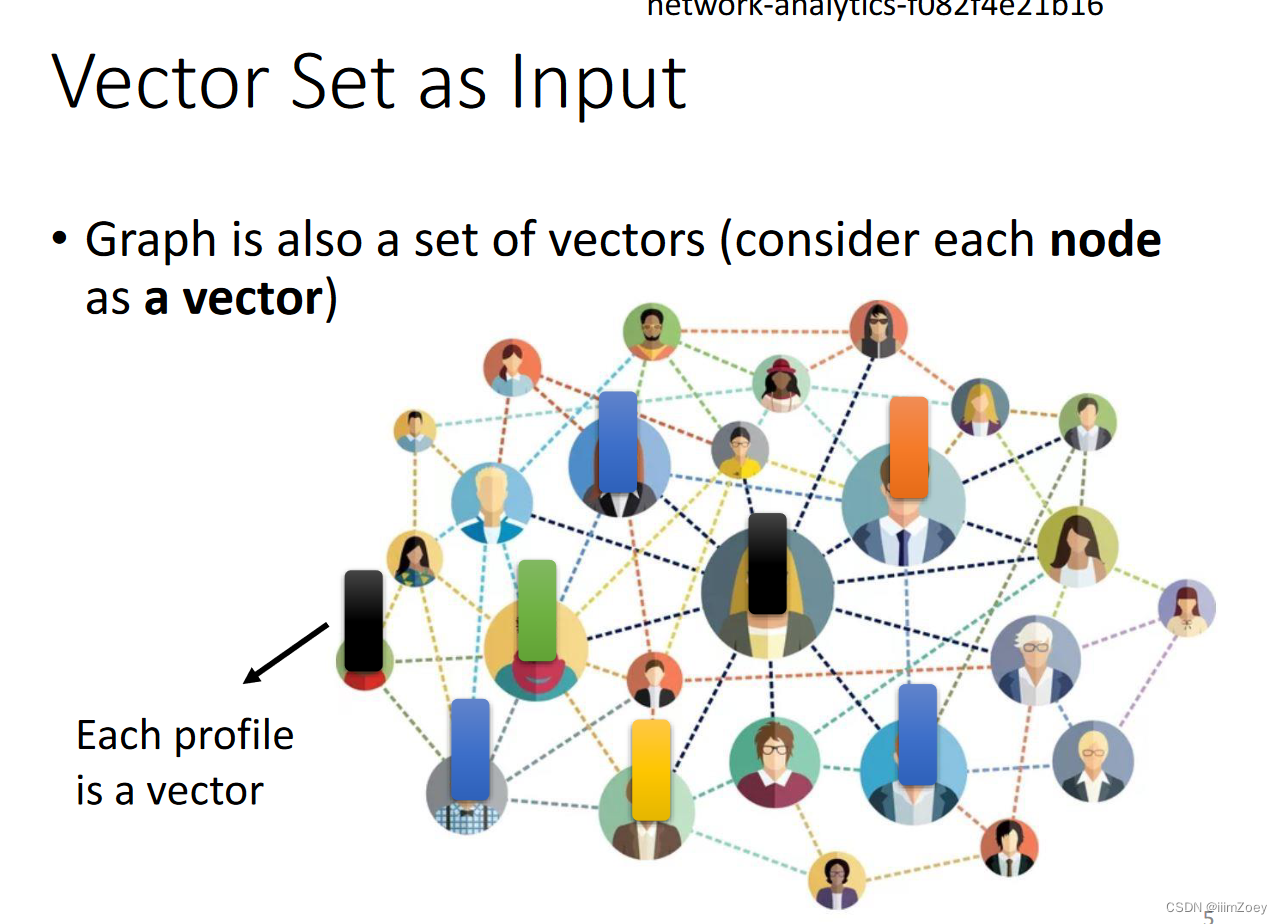
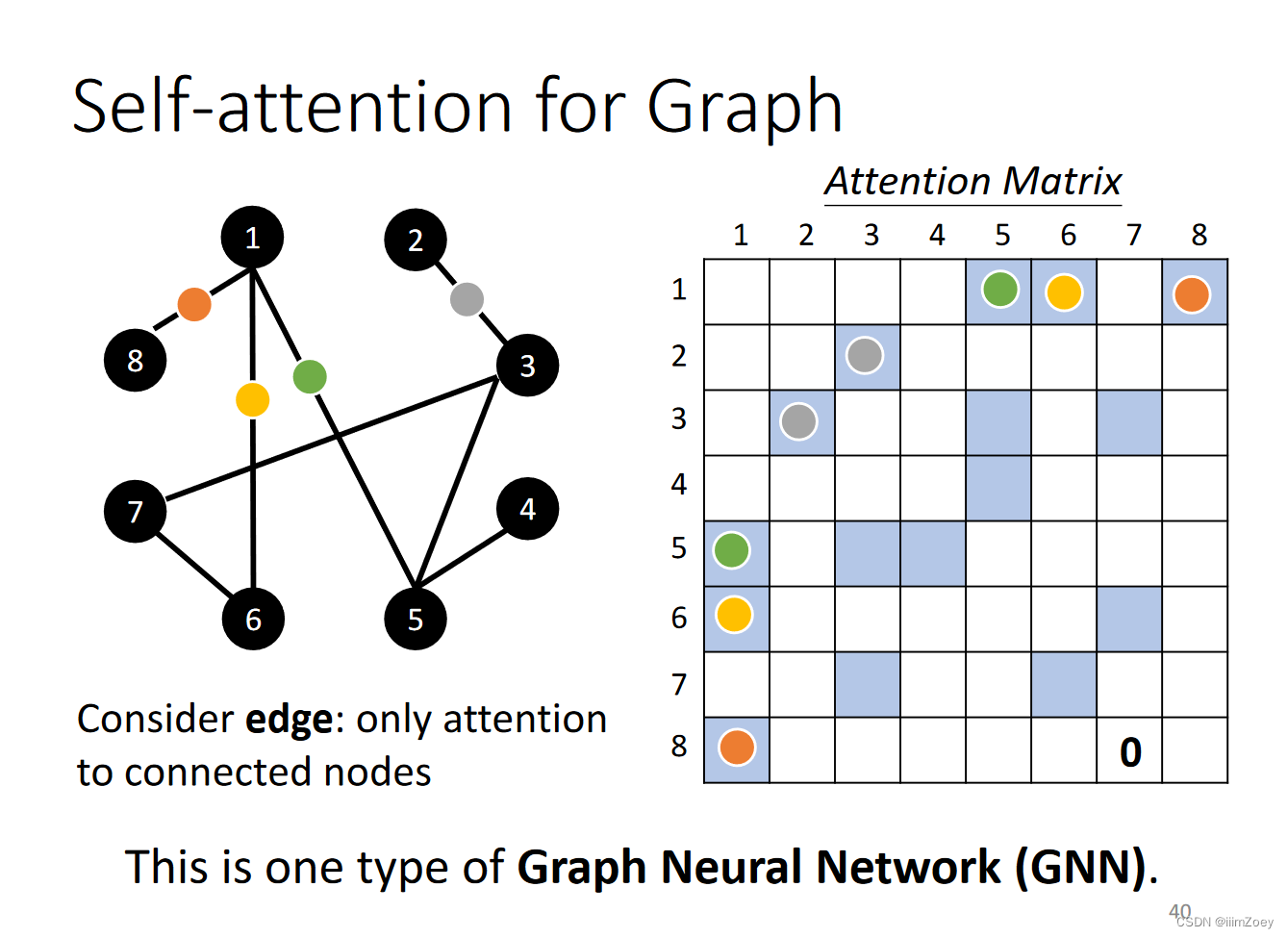
attention for graph















 1023
1023

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









