






目录
摘要
CNN是一种前馈神经网络,是当图片处理的主流技术,可以处理经过放大、缩小、旋转过的图片。对于图像处理而言有以下几关键技术的应用,第一是物体定位:预测包含主要物体的图像区域,以便识别区域中的物体;第二是物体识别:针对分割好的目标进行分类;第三是目标分割:将图像目标分割出来,针对图像上的像素进行归属,例中如人类、建筑物等;第四是关键点检测:从图像中检测目标物体上某关键点的位置,例如人类面部关键点信息。对于一些机器学习的任务,输入并不是单一的,可能同时会有多个输入,而具体的输入会随着样本不同而改变,现在self-attention就能够解决这个问题,在self-attention的输出可以是多个或者单个,self-attention运作中的关键就是需要计算出注意力权重α,计算时可以进行并行计算,也能提升计算效率;self-attention可以视为是复杂版的CNN,当数据资料较少时,CNN的结果会比self-attention表现的更好,self-attention出现过拟合的风险也会更大,而当数据资料更多时self-attention则表现得比CNN更好。
Abstract
CNN is a feed-forward neural network, which is the mainstream technique when image processing, and can process images that have been zoomed in, zoomed out, and rotated. For image processing there are several key technologies applied, the first is object localization: predicting the image region containing the main objects in order to identify the objects in the region; the second is object recognition: classifying the segmented targets; the third is target segmentation: segmenting the image targets and attributing them to the pixels on the image, for example, human beings, buildings, etc.; the fourth is key point detection: detecting the location of a key point on the target object from the image, for example, human face key point information. The fourth is key point detection: detecting the location of a key point on the target object from the image, e.g., human face key point information. For some machine learning tasks, the input is not single, there may be multiple inputs at the same time, and the specific input will change with different samples, now self-attention can solve this problem, in the output of self-attention can be multiple or single, the key in the operation of self-attention is the need to calculate The key to the operation of self-attention is to calculate the attention weight α, which can be computed in parallel to improve the computational efficiency; self-attention can be regarded as a complex version of CNN, when the data is less, the results of CNN will perform better than self-attention, and the risk of overfitting of self-attention will be greater, while when the data is more Self-attention performs better than CNN when more data are available.
CNN卷积层的计算
卷积的作用主要是进行特征提取,输入的通道数C与filter的第三个维度要相对应,h与w的大小对用在图中多大的区域中选出一个特征值。可以使用多个filter得到多个特征图的个数,将所有的特征图堆叠在一起之后就得到了更加丰富的特征。在进行卷积计算时,同一层的卷积核的大小需要一样,因为计算时是矩阵整体进行计算。
下面是具体的计算过程:
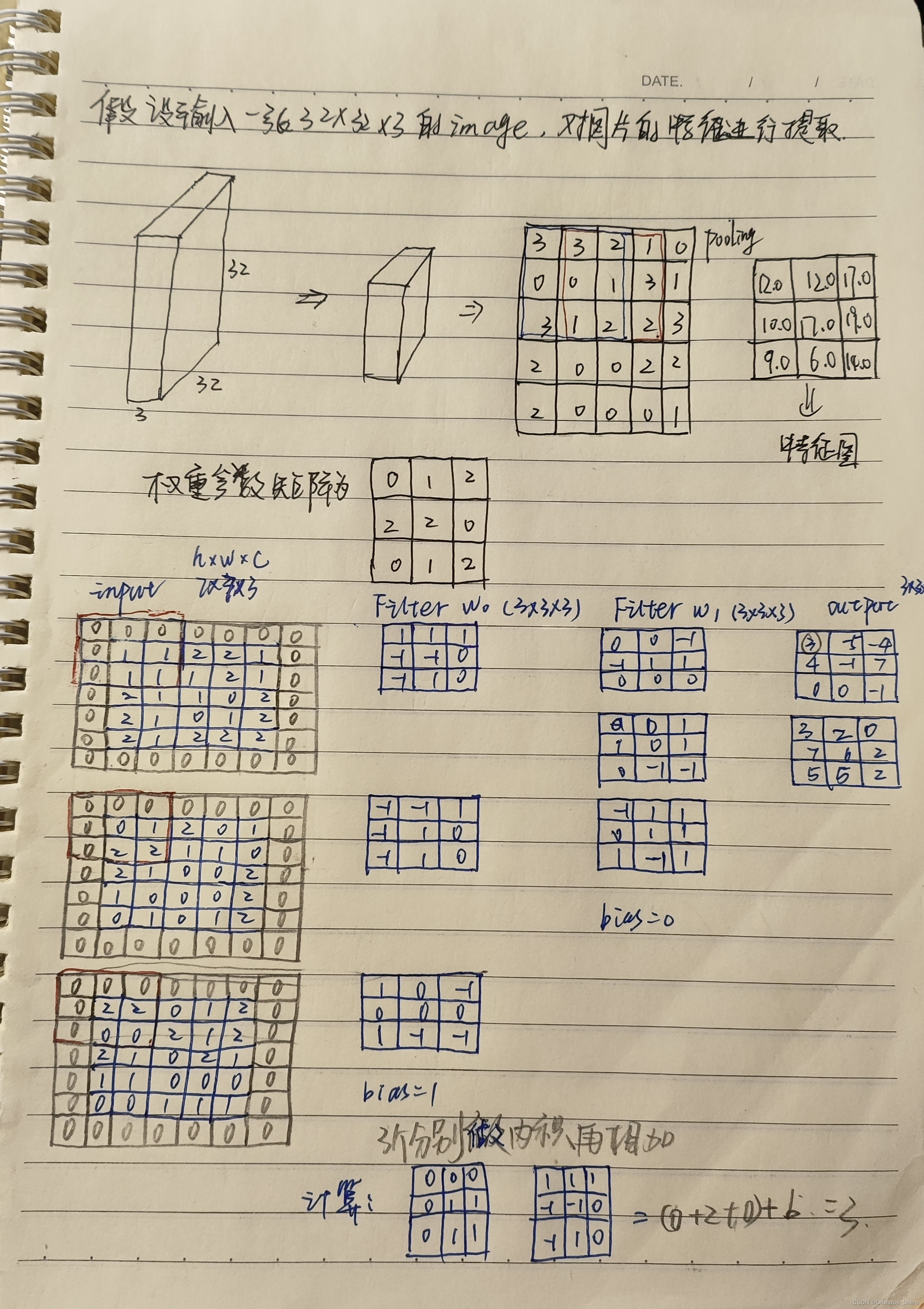
总而言之,卷积的过程就是将数据分成一个个小区域,对每一个小区域指定filter后计算内积,将内积的结果分别计算好。卷积并不是只做一次,而是提取出的特征图的基础上进一步进行特征提取,也能够进一步更精细化的对特征进行提取。
卷积层的参数
1、步长:能够滑动的窗口越多,得到的特征值就越多,特征图也越大。每次滑动的大小可以自己进行设置,一直滑动到所有区域后最终得到特征图的结果。当步长较小时,得到的特征比较丰富,但效率也比较低,当步长较大时,得到的特征图比较粗略,常用的步长为1。
2、卷积核尺寸:尺寸越小提取越精细,尺寸越小提取越粗略,一般为3*3.
3、边缘填充:为了弥补有些特征值使用确实的情况对边缘进行填充,即在特征值的边缘加0,加0的原因是不会对输出结果产生影响。
4、卷积结果计算公式:
H
2
=
H
1
−
F
H
+
2
P
S
+
1
H_2=\frac{H_1-F_H+2P}{S}+1
H2=SH1−FH+2P+1
W
2
=
W
1
−
F
W
+
2
P
S
+
1
W_2=\frac{W_1-F_W+2P}{S}+1
W2=SW1−FW+2P+1
说明:其中H2代表输出的长度,W2代表输出的宽度,H1和W1分别是输入的长度和宽度, F H F_H FH代表filter的长度, F W F_W FW代表filter的宽度,P代表零填充的圈数,S代表步长。
self-attention
self-attention解决的问题
对于一些机器学习任务,可能面临复杂的 input,它们不止有一个向量,而且具体的向量的个数会随样本不同而改变,而self-attention解决的就是多个输入的问题。
下面是几个多输入的例子:
1、在文字处理中:每一个词都是一个向量,且句子长度不一样。表示每个单词最简单的方式就是 One-hot Encoding,但是这样表示是假设所有的词之间都没有关系,向量间没有相关信息。另一种方式是 Word Embedding,这种方式可以降维,并且含有语义信息,使得类似得词聚成一团。
2、声音序列,也是如此,长度不一。在语音序列上,我们会把一段窗口内的语音片段(frame)变成一个向量,1秒中的语音大概有 100 个 frame。
3、图,也是一堆向量(结点和向量)
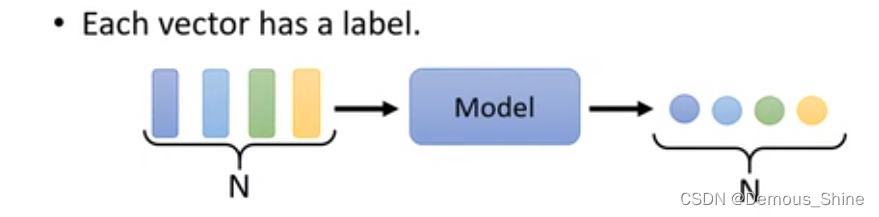
当输入一系列的向量之后,输出会有哪几种情况?其中包含输入与输出数目相同、多个输入一个输出、输出的长度不一定。
self-attention的输出
- 输入与输出一致,每一个输入向量都有一个 label。例如:当对一个英文句子中每一个单词进行词性标注,输入一个英文句子,需要输出每一个单词的词性是什么,此时有多少个英文单词输入就需要输出多少个词性。
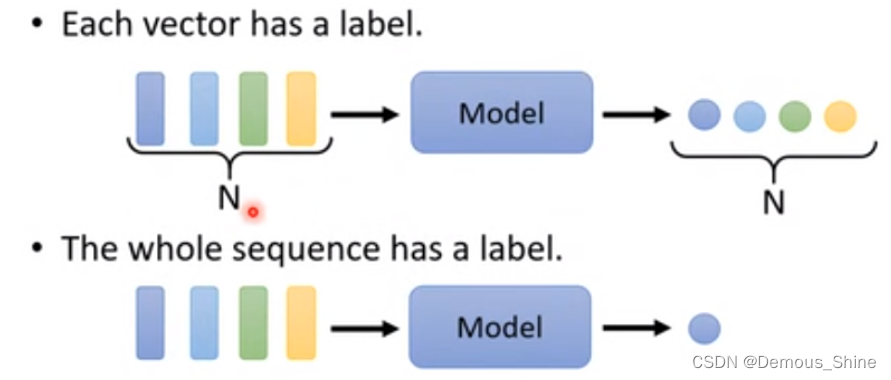
- 多个输入一个输出
分析用户的评价是正面的还是负面的,用户评价中包含许多文字,而对应输出只需要输出这些文字是正面的还是负面的,此时多个输入只有一个输出。
- 输出不一定
一系列的输入不知道输出是多少个label,需要机器自己绝对需要输出向量的数量,比如输入N个向量,机器自己输出 N ’ N^’ N’个向量。例如,机器翻译。
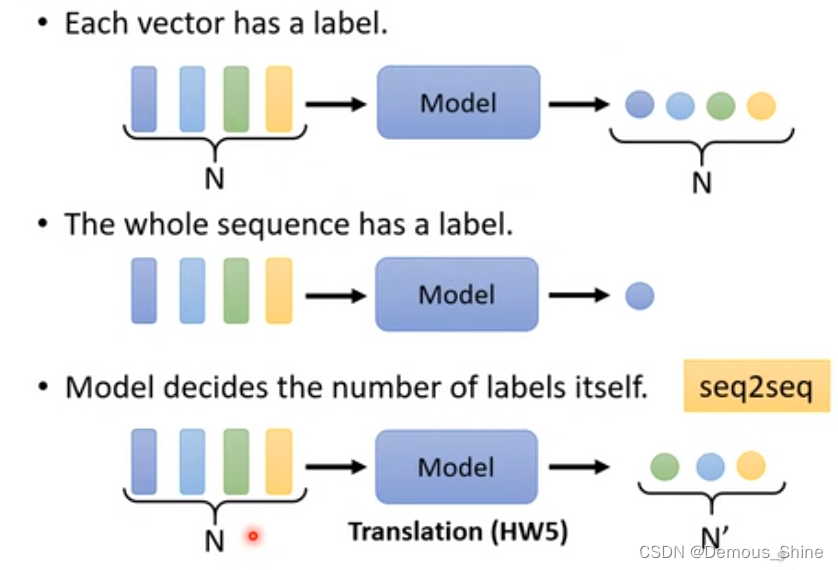
在本次学习中,主要是第一种情况的学习,输入与输出一样的情况叫sequence labeling。
当输入一系列的向量之后,使用全连接神经网络,即使是一系列的向量,那么只需要各个分开进行全连接,最后得到相应的输出。
但是这会产生一个问题,当输入一个英文句子时,需要分辨每一个单词的词性,会遇到一个句子中两个单词一样的情况,那么这个时候就会出现一样的输出,但实际上两个输出是不一样的。
method 1:考虑一个固定长度的 window,在判断词性的时候,不仅只看当前词,还看固定 window 内的其他词,也就是这个词的上下文背景信息。
当输出不只是需要考虑一个window就可以完成,当需要考虑一整个输入时才能得到输出时,也许会想到可以扩大window的范围到整个输入,但是模型中sequence的长度是不一致的,每次的sequence都不一样,当从所有的sequence中找到最大的sequence,将其作为最大的window,但这个 时候,开一个很大的window会使得神经网络的参数很多,并且也有可能会出现过拟合的现象。
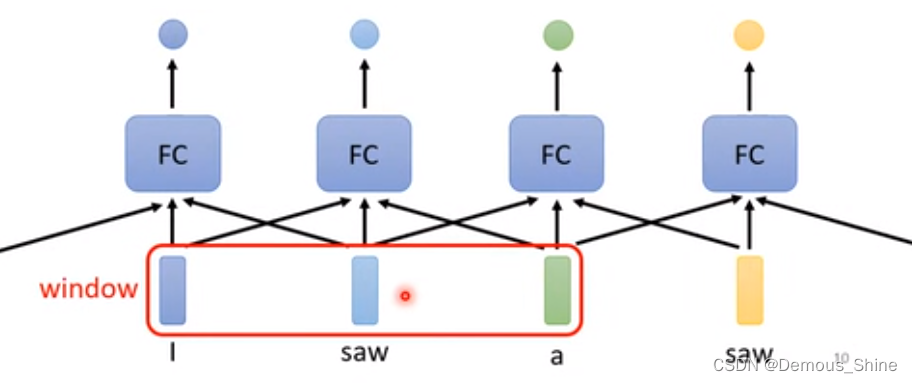
method 2:Self-attention(自注意力机制)
Self-attention,会将所有的输入都进行考虑,再考虑一整个sequence之后根据有几个输入向量,再输出有几个向量,再将得到的向量输入到神经网络中,这时输入的向量就是考虑了一整个向量之后的输入。Self-attention不只是只能使用一次,可以多次进行使用,将第一次经过Self-attention之后得到的向量放入到神经网络中,得到一次输出,再将输出放入到Self-attention中,再一次进行分配,再次放进神经网络中,进行多次的交互使用。
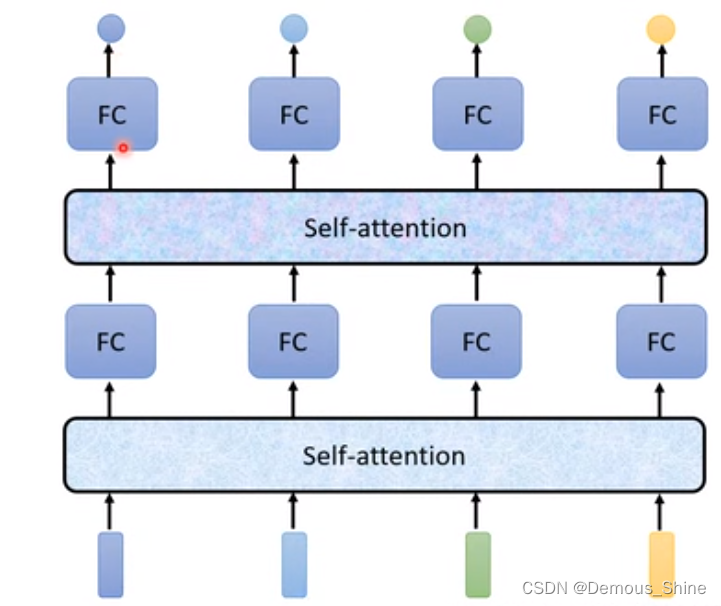
Self-attention的运作
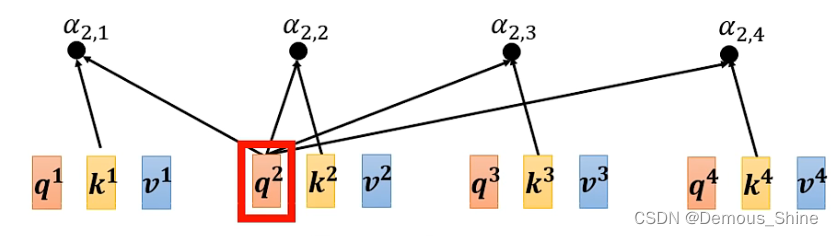
Self-attention的输入有可能是一系列的输入或者一个隐藏层。那么如何通过Self-attention产生神经网络的向量:例如产生b1,第一个步骤是根据a1,找出跟a1相关的向量,找出那些向量是与其有关的,每一个向量与其相关连的程度用
α
\alpha
α来表示。
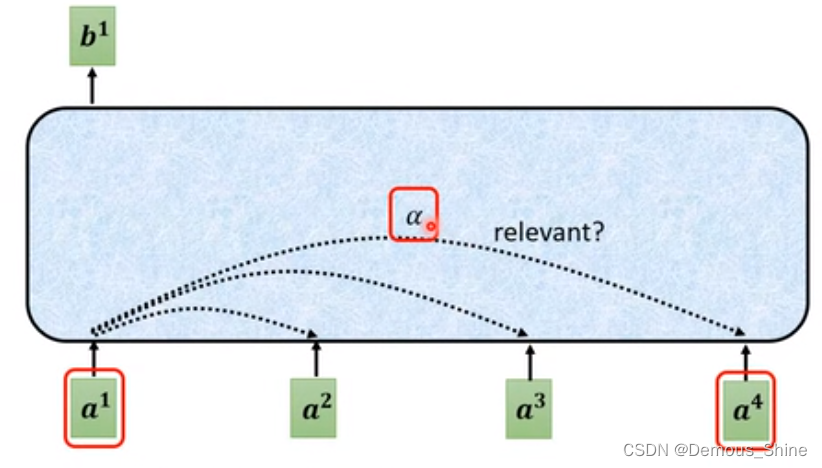
计算 attention 的模组算出
α
\alpha
α(关联度大小),有很多方法,比如 Dot-product 方法和 Additive 方法。
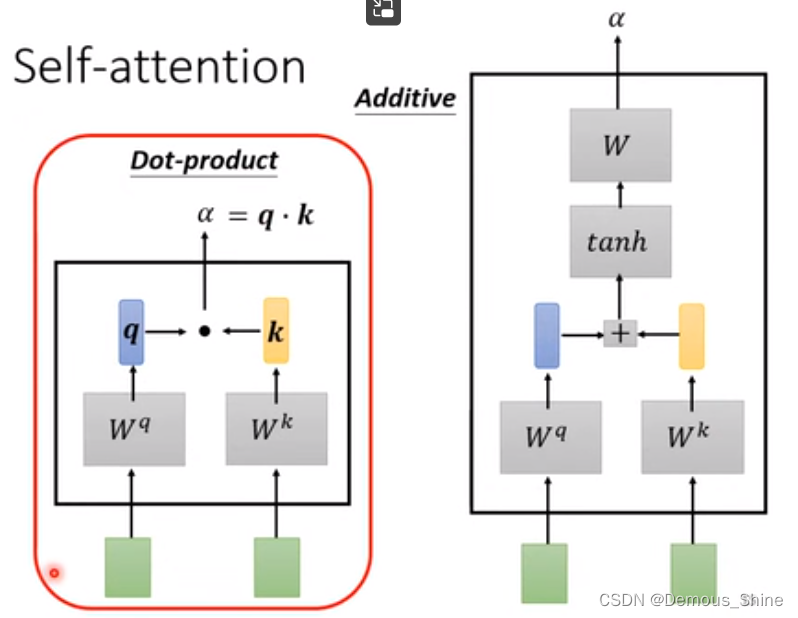
注意力权重 α 的计算
对于当前的输入向量,我们称之为 query,它对应有
W
q
W^q
Wq这个权重矩阵,query 的值为权重矩阵乘以输入向量,也就是
q
i
=
W
q
∗
a
i
q^i=W^q*a^i
qi=Wq∗ai。
而 query 外的其他的输入向量,则被被成为 key,其对应有
W
k
W^k
Wk, 这个权重向量,key 的值为权重矩阵乘以输入,也就是
k
i
=
W
k
∗
a
i
k^i=W^k*a^i
ki=Wk∗ai。
如何衡量关联度呢?可以采用点积(Dot-product)的方式,比如说 query1 和 key2 的关联度,就为二者的点积:
α
1
,
2
=
q
1
∗
k
2
\alpha_{1,2}=q^1 * k^2
α1,2=q1∗k2,类似推荐系统里的用户向量乘以物品向量得到二者的相关度。
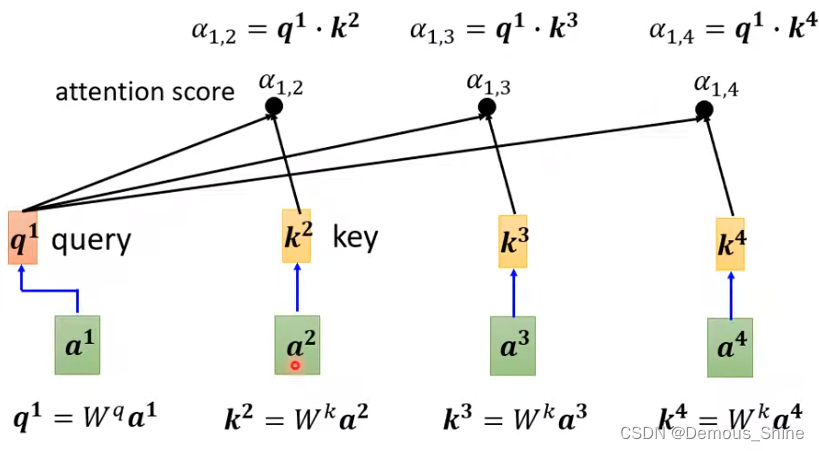
这个过程要重复进行,在实际中,每个向量向量和自己、和其他向量都要做一次。
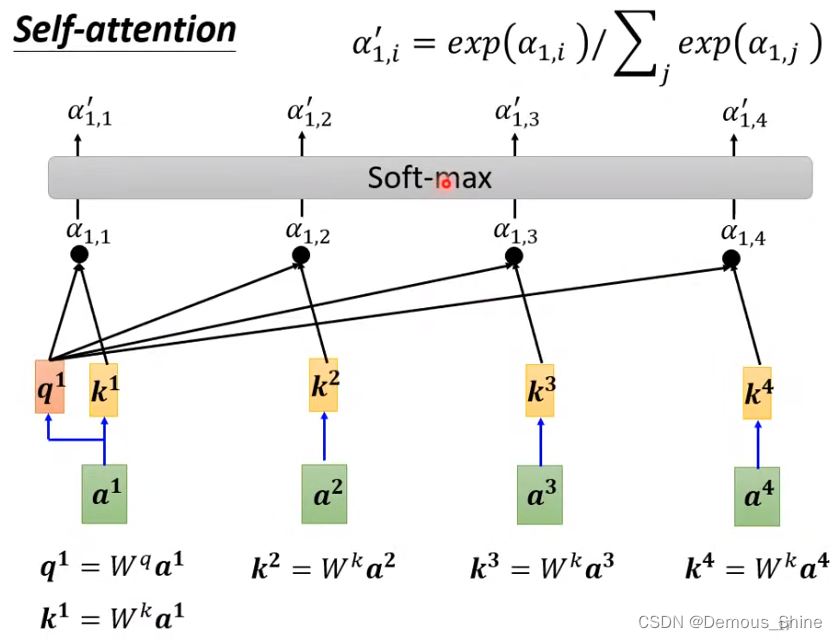
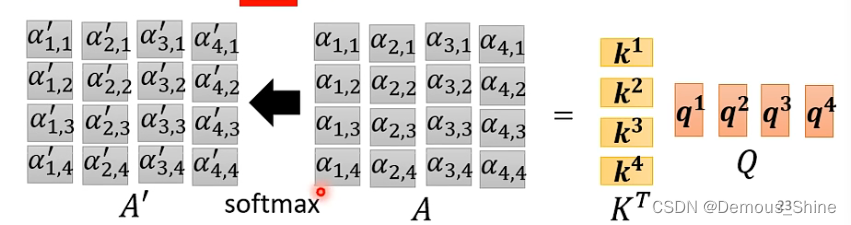
得出所有的
α
i
,
j
\alpha_{i,j}
αi,j之后,这些数需要通过激活函数比如 Soft-max 函数,输出激活后的α’,也就是我们需要的注意力权重。这里的激活函数使用的是 Soft-max,目的是做 Normalization。激活函数也可以使用其他的函数,比如ReLU。
最后根据 α’ ,也就是激活后的 attention score,来抽取信息。
引入另一个组件,
v
i
v^i
vi,它的计算方式也和 query 或 key 的计算很相似,它也有属于自己的权重矩阵
W
v
W^v
Wv,所以计算方式为:
v
i
=
W
v
∗
a
i
v^i=W^v*a^i
vi=Wv∗ai,最终的 b1 是加全求和计算公式为:
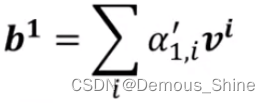
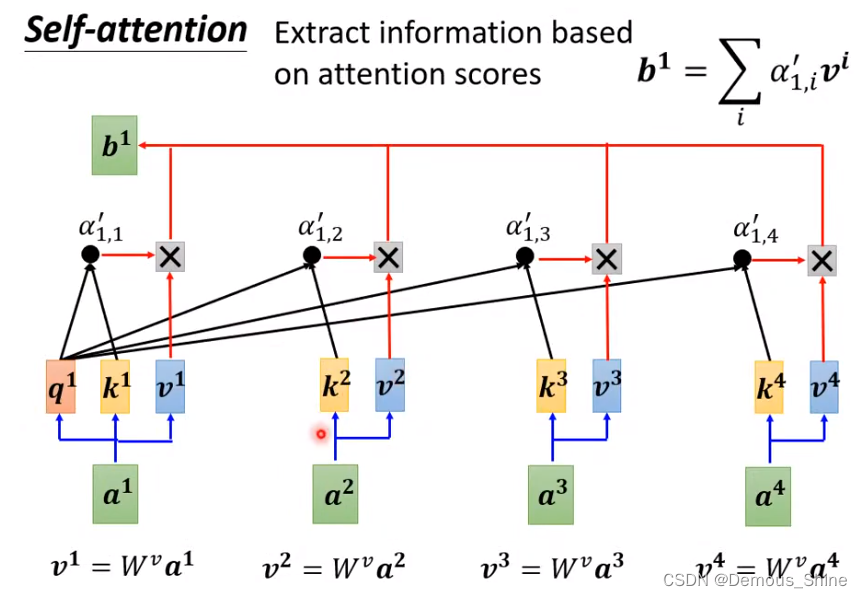
谁和当前词的关系越大,其信息就越会被抽出来。每一个输入向量都有其对应的 q,k,v 向量。
并行计算
计算attention score实际上是可以一起进行计算的,只需要将所有输入向量拼起来形成一个新的矩阵,再将其乘以
W
q
W^q
Wq,得到的新矩阵的每一列就就可以得到qi,ki与vi的计算方式与qi的计算方式相同,用
W
k
W^k
Wk和
W
v
W^v
Wv均分别乘以输入向量,就分别可以得到ki和vi。
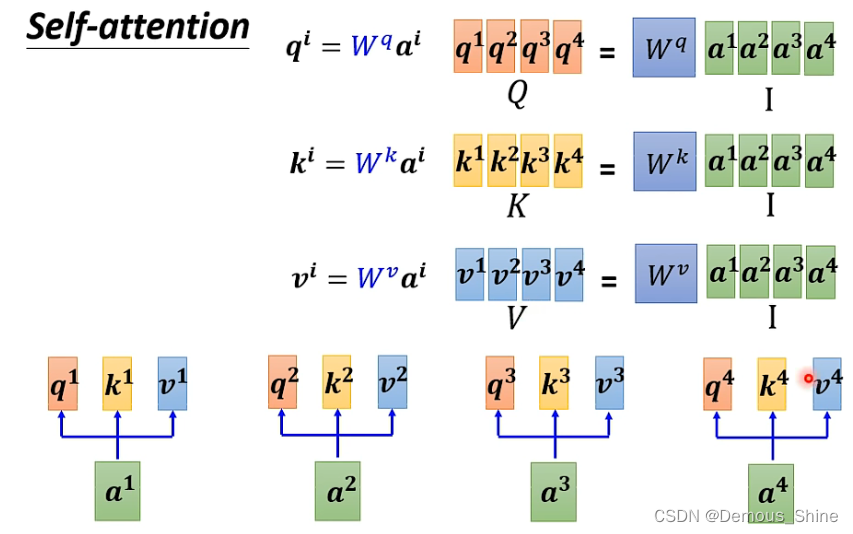
注意力分数的计算如果从矩阵操作来看,
α
1
,
1
\alpha_{1,1}
α1,1等于K1的转置乘以q1,其他的计算方式也是如此,这四个步骤的操作可以视为矩阵与向量的相乘,可以看做将k1-4拼起来,当做一个矩阵,乘以q1,就得到第一个向量与其他向量的attention score,当k1-4拼起来形成的矩阵与q1-4拼起来形成的矩阵相乘时得到的新的矩阵的每一列就是分别每一个向量与其他向量的attention score。
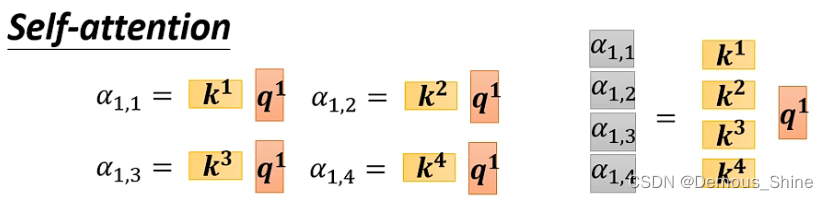
计算得到
α
’
\alpha^’
α’ 之后,就可以计算经过self-attention输出的向量,b1是通过
α
’
\alpha^’
α’乘以V1得到,将所有的vi拼成一个矩阵,乘以每一个向量与其他向量之间得到的attention score,得到的新矩阵的每一列分别对应输入向量进过self-attention的的输出向量。
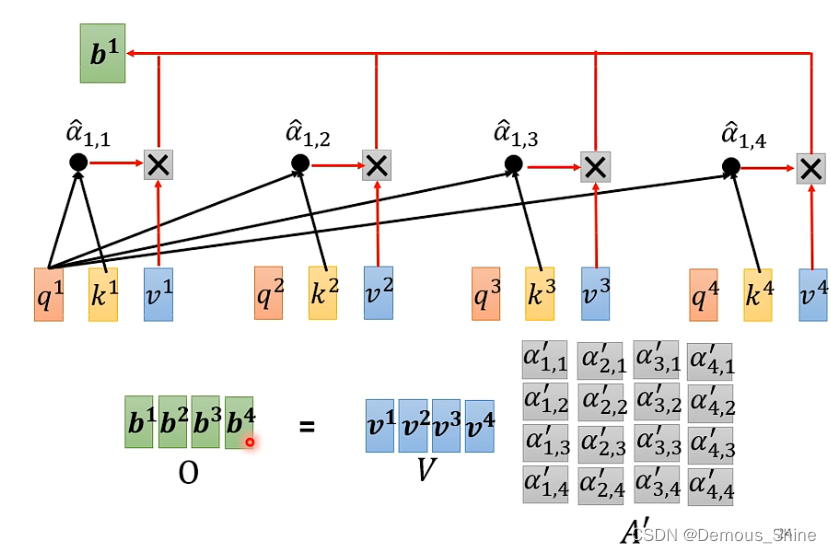
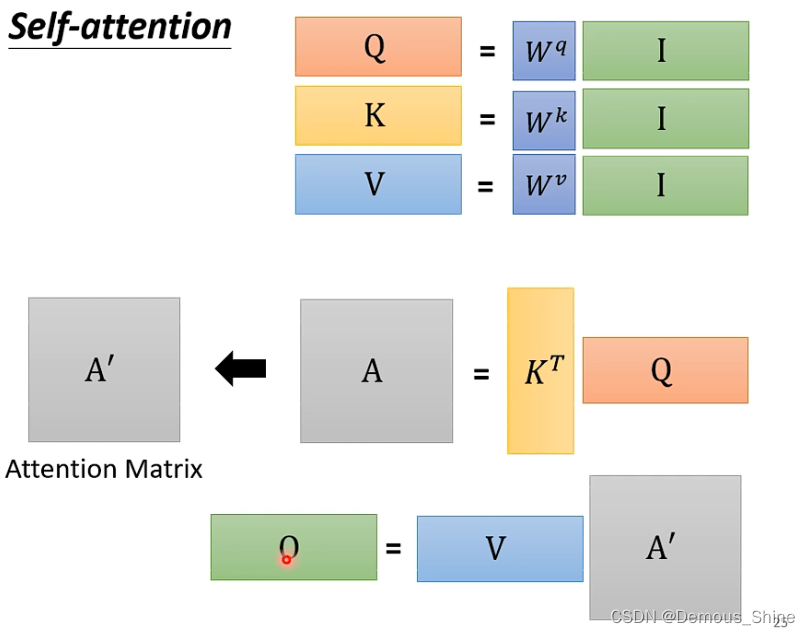
说明:self-attention的输入是I,输出是O, 所有的矩阵只有 Wq, Wk, Wv 这三个矩阵才需要通过数据 train
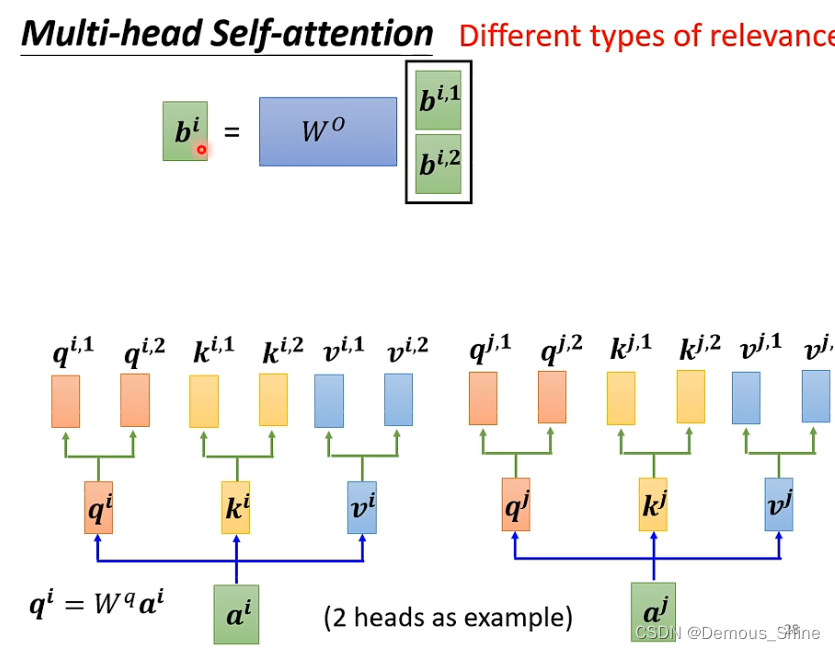
Multi-head Attention
一种 relevance 还不够,需要多种 relevance。也即是需要多个 q,k,v。
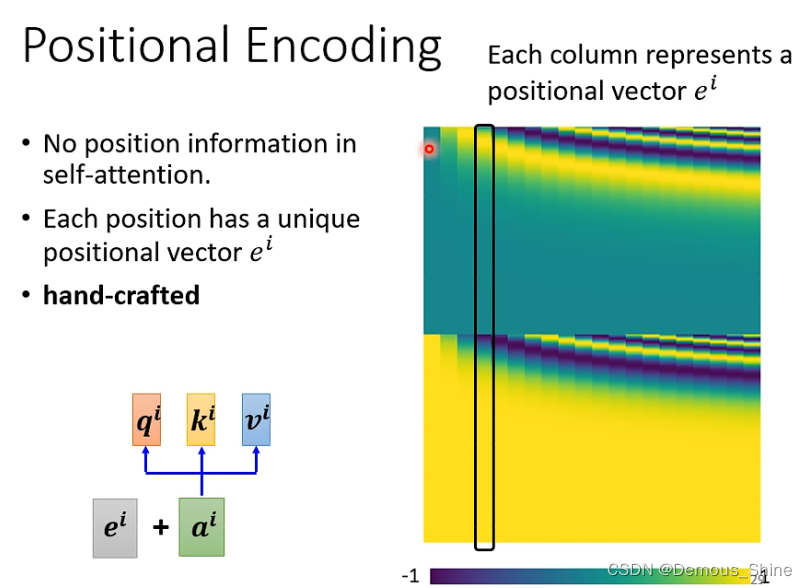
输入一个句子,对句子中每个单词的词性分类的例子中,self-attention并没有考虑向量之间的位置,但这样会产生一个问题,当位置的资讯可能会很重要,例如:输出一个句子中每个单词的词性,句子第一个单词为动词的概率比较小,当做self-attention时,如果位置是重要的就可以将位置的资讯放入到self-attention中,每一个位置中有一个单独 位置向量
e
i
e^i
ei,
self-attention vs CNN
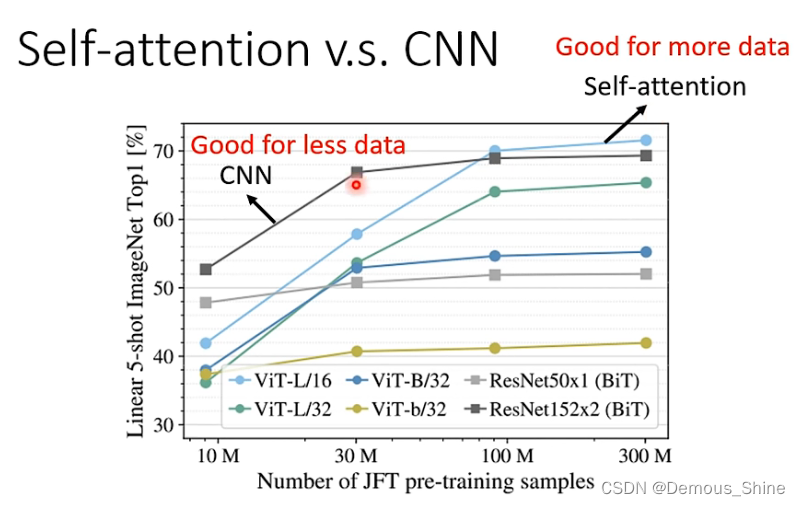
- CNN 可以看作简化版的 self-attention。
- 或者 self-attention 是复杂版的 CNN, receptive field 不再是人工画出来,而是自动学习出来。

CNN是self-attention中的一个子集,控制self-attention可以使其做到和CNN一样的结果,对于小模型而言,使用CNN可以得到更好的结果,比self-attention更少的资料也能得到更好的结果,随着资料量的增加,self-attention的训练结果会比CNN更好,当资料量不够的时候self-attention可能会出现过拟合的现象,是因为它的弹性比较大,而CNN弹性比较小,更少的资料也能够得到比self-attention更好的结果。
总结
CNN的目的是以一定的模型对事物进行特征提取,而后根据特征对该事物进行分类、识别、预测或决策等。最重要的步骤在于特征提取,即如何提取到能最大程度区分事物的特征,实现这个伟大的模型就需要对CNN进行迭代训练;而CNN可以看做是简化版的self-attention,self-attention能够解决多输入的问题。















 8万+
8万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









