






目录
摘要
在机器学习的训练模型过程中,为了得到更好的结果需要分析loss的变化,当训练集中结果更好而测试集中结果却变现得更差,有可能是过拟合导致的,但是并不是每次这样的结果都是过拟合的现象,就需要从更多的方面考虑因素,比如optimization失败、bias不合理等。当遇到梯度下降中梯度为零的点时,或许会觉得就是局部最小值,但是也有可能是鞍点,可以通过计算来判断是最小值还是鞍点。梯度下降中的learning rate是优化算法中的调谐参数,该参数可确定确定每次迭代中的步长,使损失函数收敛到最小值,但如果是固定的,有时候训练并不能得到更好的结果,能够自动调整的学习率在坡度比较陡的地方能够及时的进行调整,也往往可以得到更好的结果,得到更小的loss。得到一个好的训练结果需要考虑多方面的因素,损失函数选择的不恰当也会导致得到较差的结果。
Abstract
In the process of training models in machine learning, in order to get better results, we need to analyze the change of loss. When the result in the training set is better and the result in the test set is worse, it may be caused by overfitting, but not every such result is the phenomenon of overfitting, so we need to consider more factors, such as the failure of optimization, bias unreasonable, etc. When you encounter a point with zero gradient in gradient descent, you may think it is a local minimum, but it may also be a saddle point, and you can calculate it to determine whether it is a minimum or a saddle point. The learning rate in gradient descent is a tuning parameter in the optimization algorithm, which can determine the step length in each iteration to make the loss function converge to the minimum value, but if it is fixed, sometimes the training does not get better results, the learning rate can be automatically adjusted in a steeper slope can be adjusted in time, but also often can get better results, get smaller loss. The loss. to get a good training result needs to consider a variety of factors, the loss function is not properly selected can also lead to get poor results.
1 机器学习攻略
1.1 机器学习的步骤
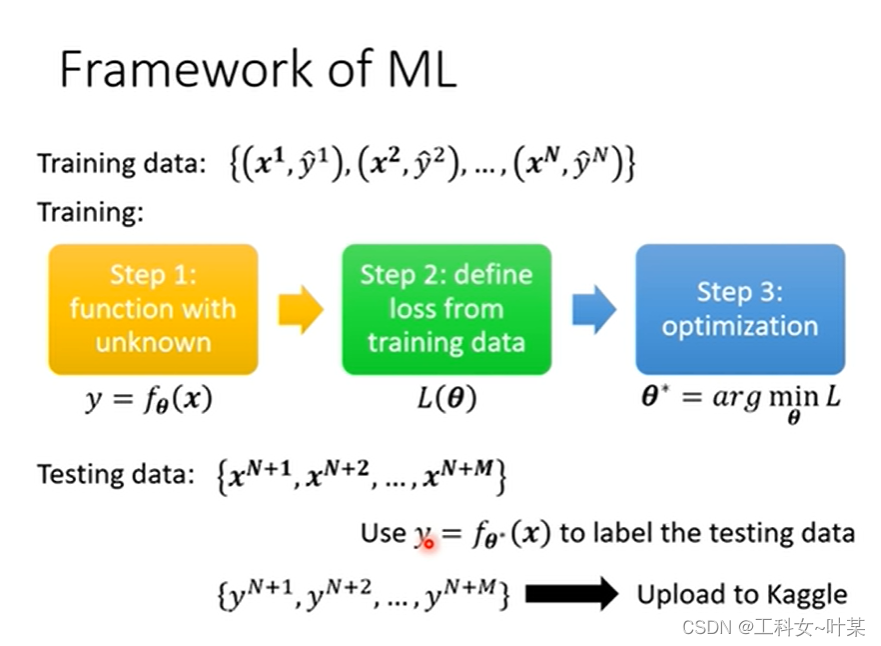
在机器学习的步骤中,首先有training data,和testing data,第一步是建立一个带有位置参数的function,下图中
θ
\theta
θ是一组未知数向量,第二步是定义training data的loss,第三部是找出最小的loss,
θ
\theta
θ*,再将最小的
θ
\theta
θ*带入到testing data中,将得到的所有数据都放到kaggle(一个数据建模与数据分析平台)中训练。
1.2 学习攻略
当我们训练模型时,我们想得到更好的结果应该怎么做呢?如果觉得结果不满意的话,首先需要检查training data,看看model是否在training data中训练起来,如果发现training data的loss大,则在训练资料中没有学好,则分析没有学好的原因是什么:有可能是model 的bias,即model太过简单,(在经过训练之后得到的loss中没有一个能够使testing data中的loss减小,即使是最小的loss,也不能让testing data中的loss减小,解决办法是重新设计model,那就是使model更复杂)
但是并不是training loss大的时候就是bias,可能会遇到另外一个问题,就是optimization做的不够好,也就是可能会卡在local minimal的地方,使用梯度下降的方法没有办法找到真正最优的loss。
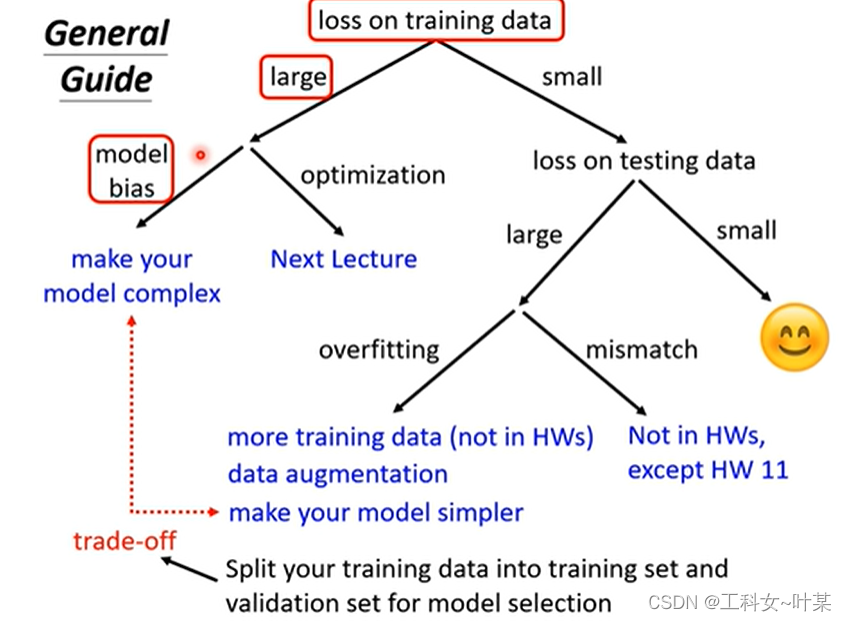
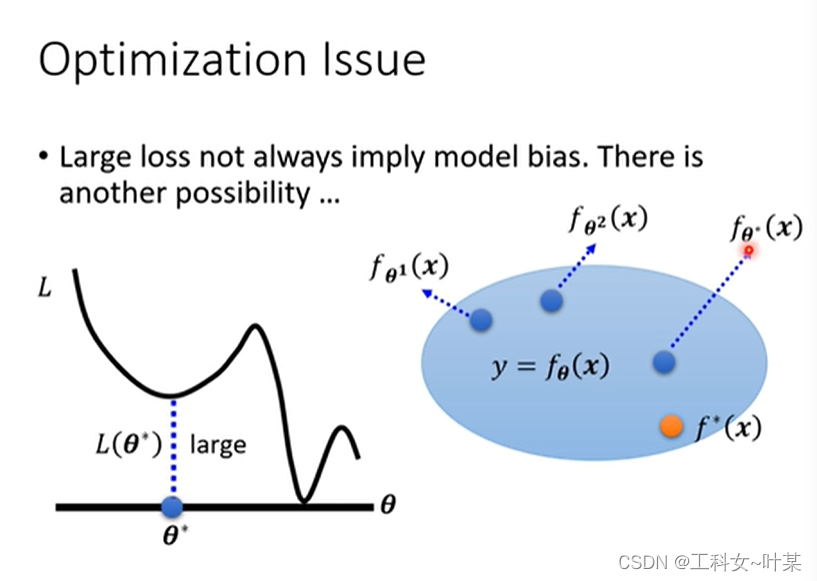
那么我们发现training data loss大的时候具体是因为bias还是因为optimal的呢?到底是因为model够大还是不够大呢?那么我们可以使用下面的方法判断model是否够大,可以先使用别的方法来看一下,可以使用更浅的model,比如线性model,如果使用更深的model也乜有获得更小的loss在训练数据上,那么就是最优化没有做好的问题。
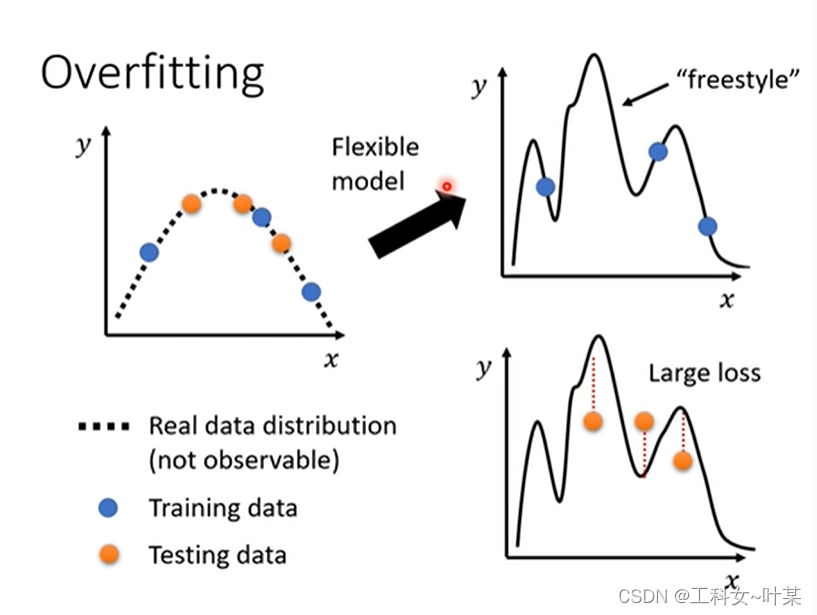
 假设经过一番努力之后可以让training data的loss变小之后,就可以来看testing data了,如果testing data的loss也变小了,那么就已经结束。那么如果不是,testing data的loss还是变大,那么有可能就是过拟合的问题了。
假设经过一番努力之后可以让training data的loss变小之后,就可以来看testing data了,如果testing data的loss也变小了,那么就已经结束。那么如果不是,testing data的loss还是变大,那么有可能就是过拟合的问题了。
为什么会发生过拟合呢?是因为当训练数据不够多的时候,model的弹性比较大,那么model就有更多的freestyle,这时候就有可能会出现training data中的loss更小而testingdata中的loss更大的问题,那么具体为什么弹性更大的model会有更多的freestyle呢,将在以后的课程中学习。
如何解决过拟合的问题呢:
增加训练数据、数据扩大(但是有些并不能随意的放大,需要放大的合理)、不要让模型有过大的弹性限制,模型的弹性(给model一些限制:缩小model的选择空间:比如减少参数、减少神经元的个数或者共用参数)正则化、early stopping、dropout。
当模型限制太大的时候,就有可能出现bias的问题,是因为弹性太大没有办法找到真正适合的model。
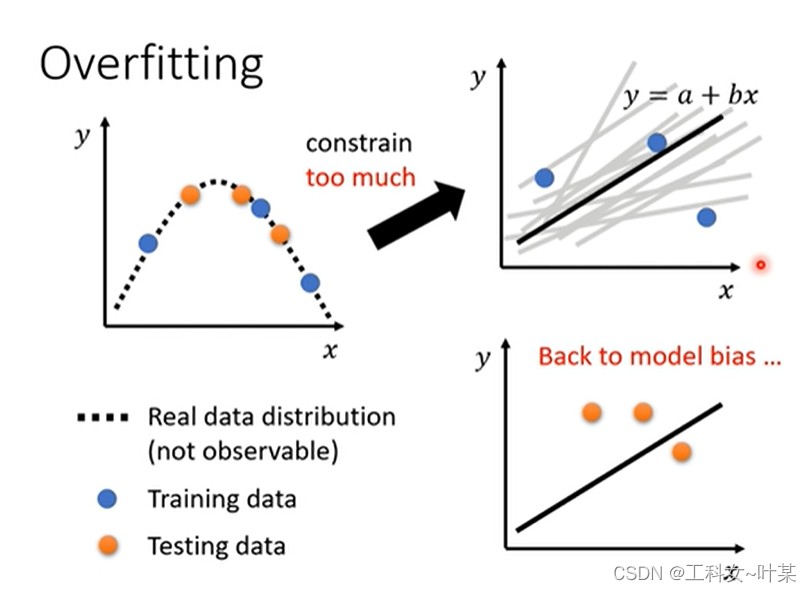
复杂程度:简单来说就是参数越多,feature越多越复杂。
当模型的弹性越来越大、越复杂时,training data中的loss减小,但是超过一定复杂程度时,testing data中的loss越来越大,这时候就出现了过拟合的现象。那么我们可以选择那个最适合的model,使得training和testing中的loss都最小。
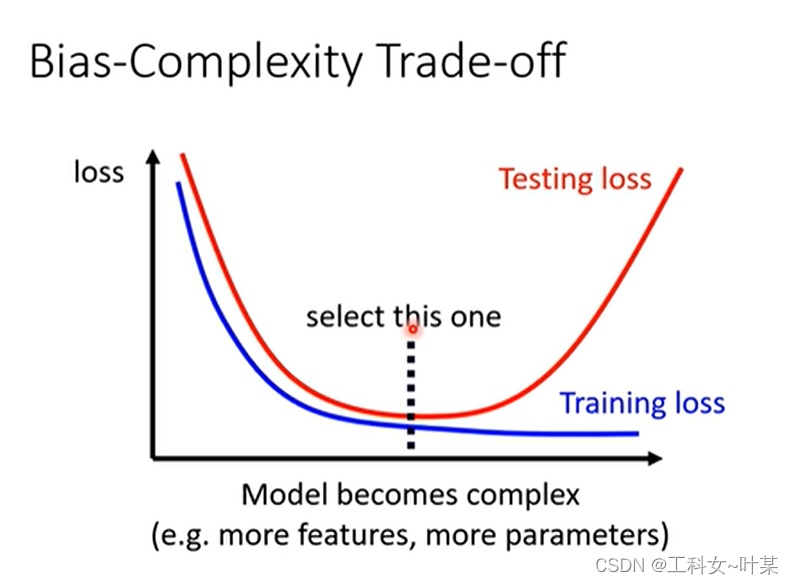
1.3 交叉验证
交叉验证:验证是指的在机器学习模型训练时对模型好坏程度的衡量。
交叉验证就是一种常用的模型选择方法,使用部分数据集进行验证模型的有效性。
1.3.1 常见交叉验证方法
常见方法:
1、简单交叉验证:将数据集分为两部分(或者是三部分),70%作为训练集,30%作为验证集。使用70%的数据,选择不同的模型参数,进行训练。结束后使用30%的数据(未经过训练)进行验证。选择最优的模型。
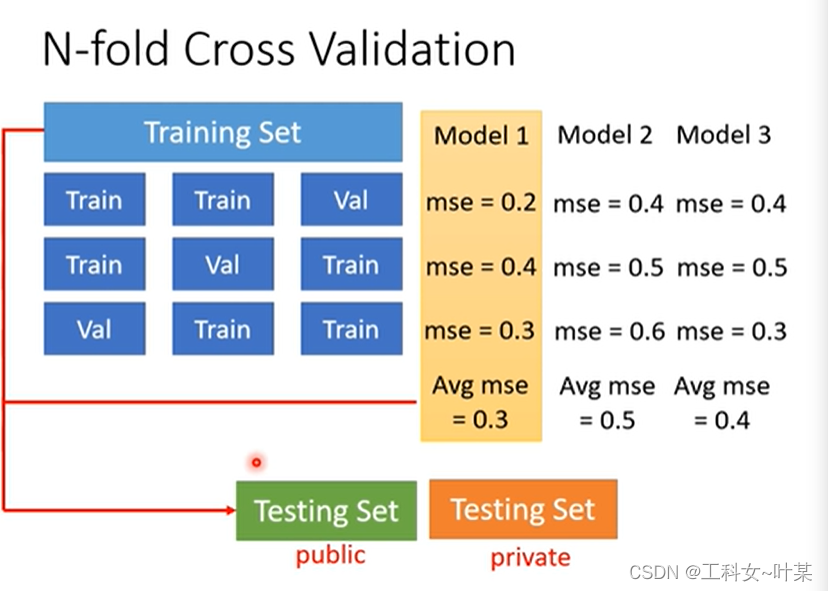
2、S折交叉验证(S-Folder Cross Validation):将数据集分为规模大小相近的S个互不相交的数据集,利用S-1部分数据去训练模型,剩下的1部分数据进行验证 。经过多次训练选出最优的模型。(注意)每次的验证集都有可能不同。
3、留一交叉验证(Leave-one-out Cross Validation):其实就是S折交叉验证的特殊形式,即在数据集规模及其小的时候(小于100条,甚至更夸张)。将S折的S=N,其中N为数据规模。留下1条数据做验证。所有的数据集在选择的时候,都需要强调独立同分布的选择(随机采样),因为机器学习就是在这个框架下所产生的科学理论。
那么如何做才能够得到更好的结果呢,可以使用交叉验证:将训练数据分成两个部分:一边时training data 另一边是验证集,10用来训练,90拿来验证,最后使用验证集的最小loss。
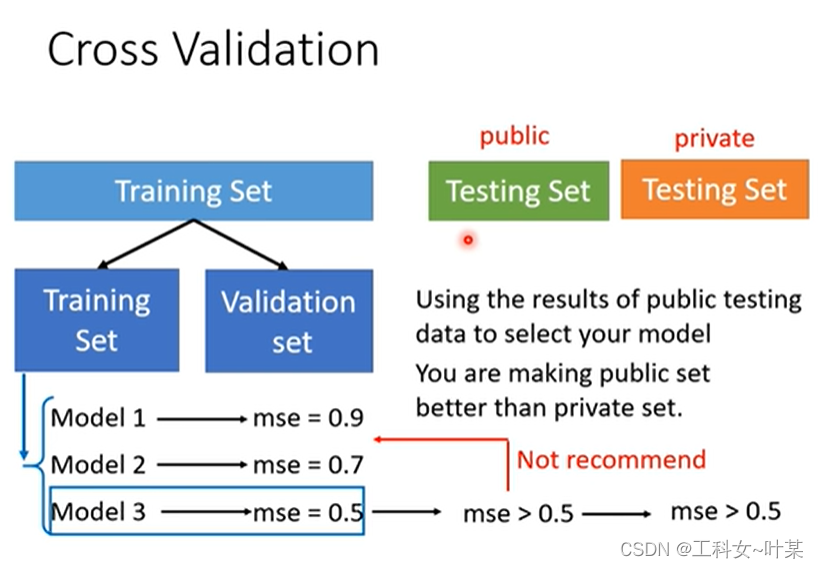
如何分训练数据和验证数据,可以使用N-fold折叠
假设有一个训练数据将其分成三个部分,一个部分作为验证集,另外两部分作为训练集,依次排列,再将所有的划分跑一遍,之后将得到的loss求平均值,取最小的loss的组合。
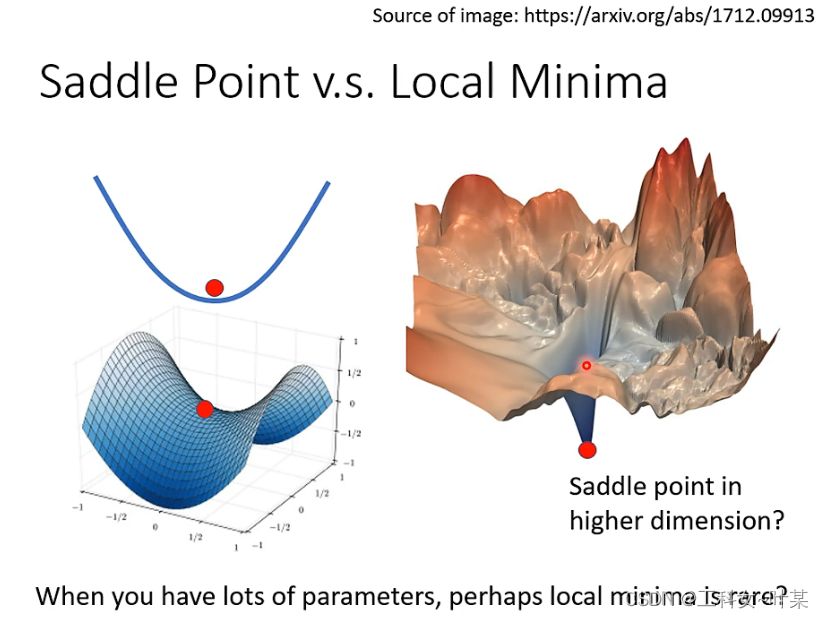
2 局部最小值与鞍点
当t梯度下降时,可能会出现,training loss一直不下降的问题,这时候可能是到了梯度为零的地方,但是这个地方有可能是local minimal,但是也有其他可能,比如saddle point(鞍点),这种点也是梯度为零的地方,也是局部最优的点。梯度为零的点就叫做临界点,不能说是local minimal。但是卡在某个点的时候有没有办法知道是局部最优还是鞍点呢,当是局部最优时:周围就没有路可以走,但是鞍点可以有路可以走,使得loss更小。
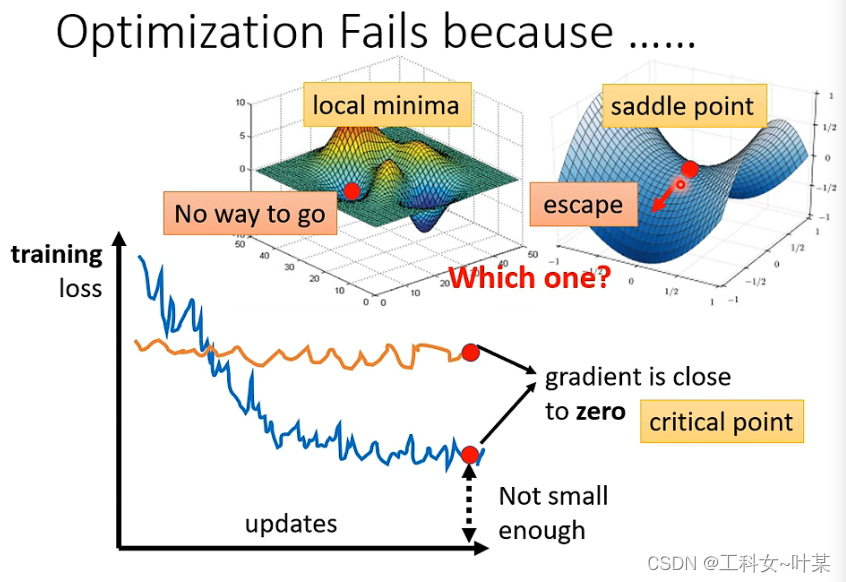
有没有办法知道是局部最优还是鞍点?
以下为使用到的一些数学微积分内容:

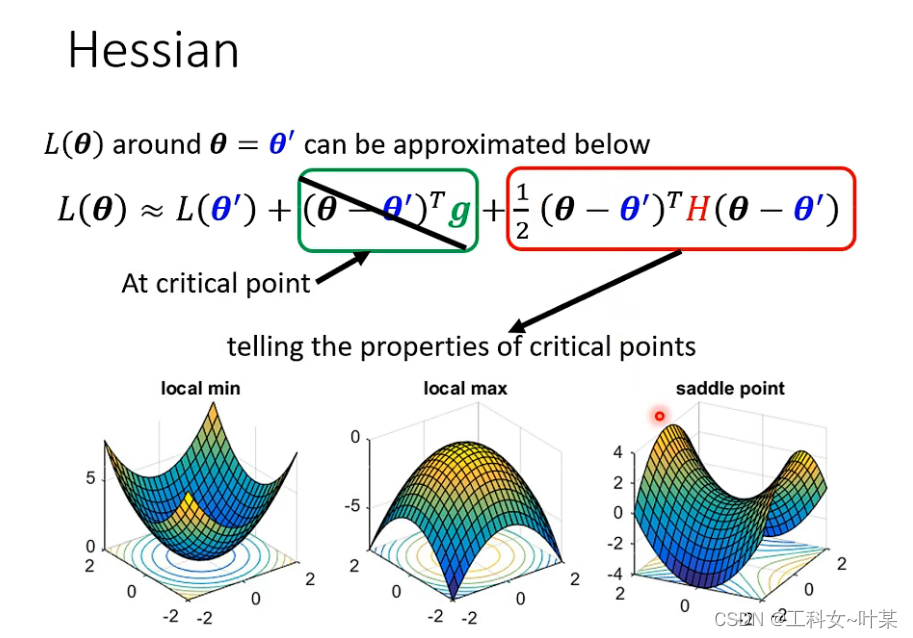
当出现梯度为0的时候,(
θ
\theta
θ-
θ
’
\theta^’
θ’)的值是0,那么就可以通过红色方框里面的内容来判断error surface周围的分布,这个就是hessian。
假设所有的
θ
\theta
θ-
θ
’
\theta^’
θ’是v,那么红色方框部分就可以表示为
v
T
H
v
v^THv
vTHv,
1、当
v
T
H
v
v^THv
vTHv不管
θ
\theta
θ-
θ
’
\theta^’
θ’取任何值都是大于0,那么在
θ
’
\theta^’
θ’附近的loss function都是小于
θ
\theta
θ的loss function的值,那么就应该是local minima
2、当对所有的v,
v
T
H
v
v^THv
vTHv都小于0,那么就有在
θ
’
\theta^’
θ’附近的loss function都是大于
θ
\theta
θ的loss function的值,那么就应该是local maxima
3、当对所有v,
v
T
H
v
v^THv
vTHv的值有大于0,小于0,在loss附近说明有的地方高,有的地方低,那么就是鞍点。
当对所有的v都大于0,那么就只需要看H的正负,hessian是一个矩阵,当算出来的hessian是正的,那么就是局部最小,如果是负的那就是局部最大值,如果有正有负,那么就是鞍点。

为了更好的理解计算过程现在举个例子:
假设现在有一个极端的例子,只有两个参数,w1、w2,输入的值是1,真实值也是1,那么把error surface图画出来之后就可以看出来那些点是临界点,在临界点里面哪些是最小、最大与鞍点,
那么给出一个点,如何通过计算得出是什么点?如下图
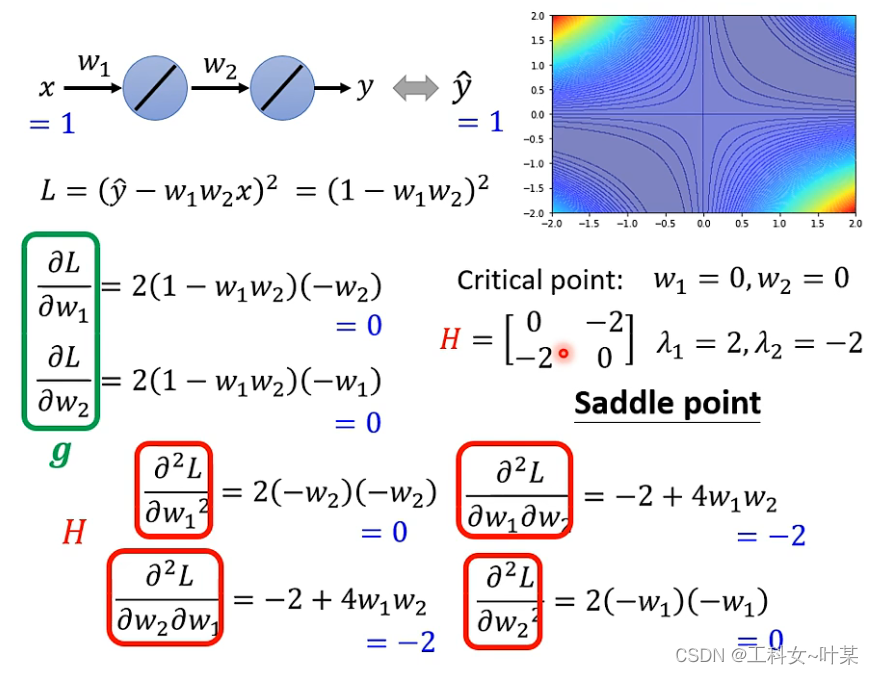
如果卡在的点是鞍点,当遇到梯度为零的地方就不能够观察g,但是还可以观察H,因为H不仅可以判断是不是鞍点,也可以判断更新的方向,
当梯度为零的地方时,g是0,那么得到如下的式子:
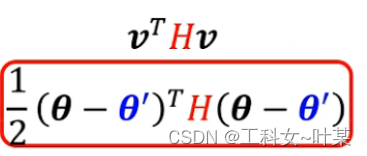

在一维的空间中,可能出现一个local值,但是放到更高维的空间中就可能出现不一样的结果,在高维空间中是一个鞍点,当模型变复杂一点时,高维空间中的变化也会很大,也有可能出现local。那么是不是空间维度越高,可以走的更新的路径就越多?
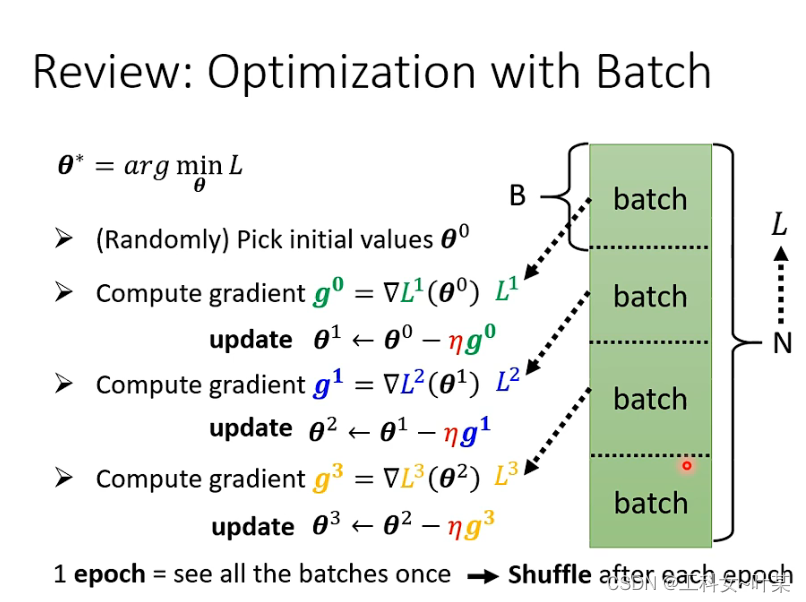
3 批次(batch)与动量(momentum)
3.1 批次(batch)
batch的做法是什么样的呢,当我们做微分时,不是对所有的数据进行微分,而是对每个batch的数据进行微分,每一个batch是一个B,当我们计算微分时,拿每一个batch的数据来计算得到一个L1,计算一个gradient,再更新参数,以此类推,不会拿所有的数据进行计算L,而是拿每一个batch中的数据来计算得到每一个Loss,将所有的batch都看过一遍叫做epoch,再每一个epoch之前会有一个shuffle。
shuffle的含义:shuffle(中文意思:洗牌,混乱)。shuffle在机器学习与深度学习中代表的意思是,将训练模型的数据集进行打乱的操作。原始的数据,在样本均衡的情况下可能是按照某种顺序进行排列,如前半部分为某一类别的数据,后半部分为另一类别的数据。但经过打乱之后数据的排列就会拥有一定的随机性,在顺序读取的时候下一次得到的样本为任何一类型的数据的可能性相同。
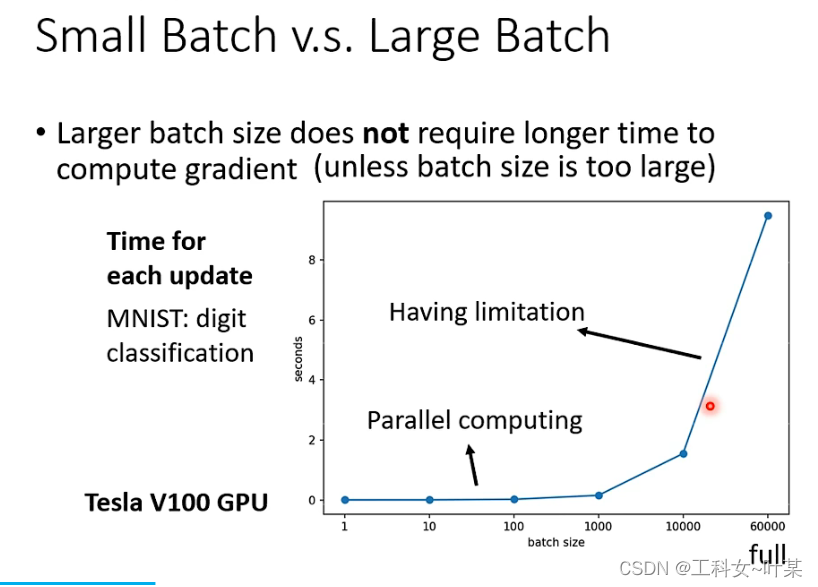
对比大的batch size,与小的batch size,大的batch size并不一定需要更多的时间去进行梯度下降(除非batch size过于大)在计算梯度下降时,可以使用GPU进行平行计算。由下图中可以看出随着batch size的增大,梯度下降的时间也是会增长的,因为GPU的平行计算能力也是有限的。
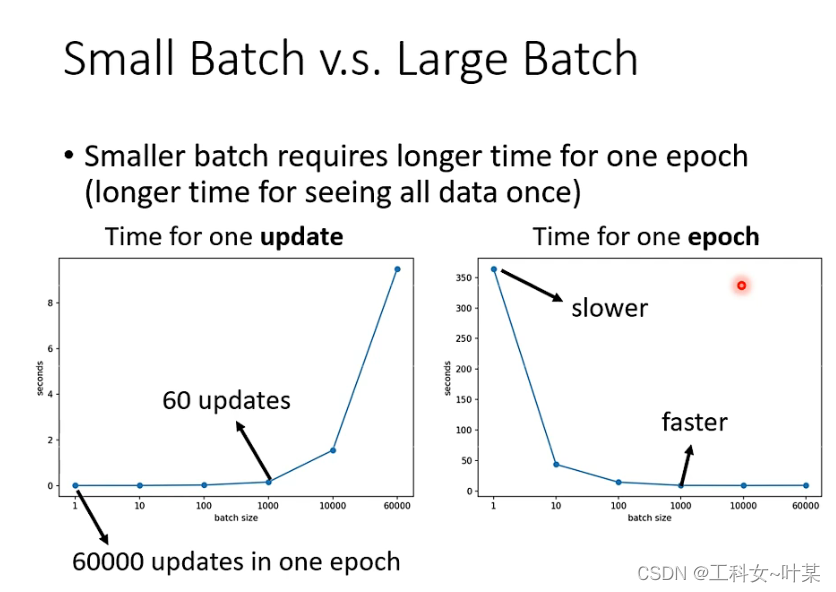
当不考虑平行计算时,可能小的batch size所需要的梯度下降时间更短,但实际上考虑平行运算的时候,一个epoch中batch大的所需要的时间更短。
当不考虑梯度下降所需时间时,大的batch是有力的,小的batch是noisy的,但是并不是所有的大的batch就是会比小的batch好,随着size的增大,验证集的正确率会下降,这个时候小的size就会变现的更好,这个时候并不是过拟合的问题而是optimization失败的原因。
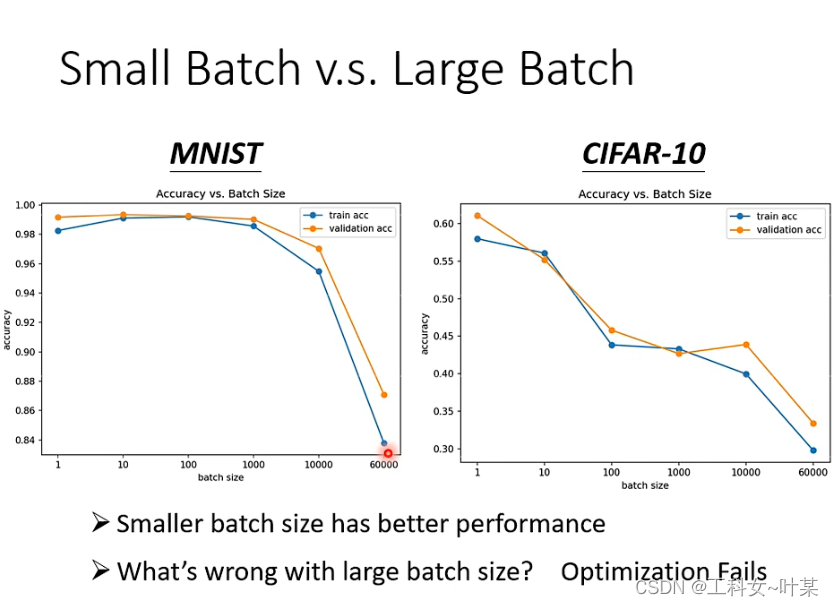 那么为什么小的batch size会得到更好结果的原因是什么?
那么为什么小的batch size会得到更好结果的原因是什么?
是因为大的batch size在梯度下降的过程中沿着loss更新参数,当遇到梯度为零的时候,如果不看hessian的时候就容易卡住,但小的batch size时,相当于每次挑一个batch出来更新参数,也就是每一个batch的loss function是略有差异的, 第一个batch时是L1计算梯度,第二个batch是L2,当L1卡住的时候L2不一定会卡住,当第一个卡住时,可以换第二个loss来继续更新,来达到让loss变小。
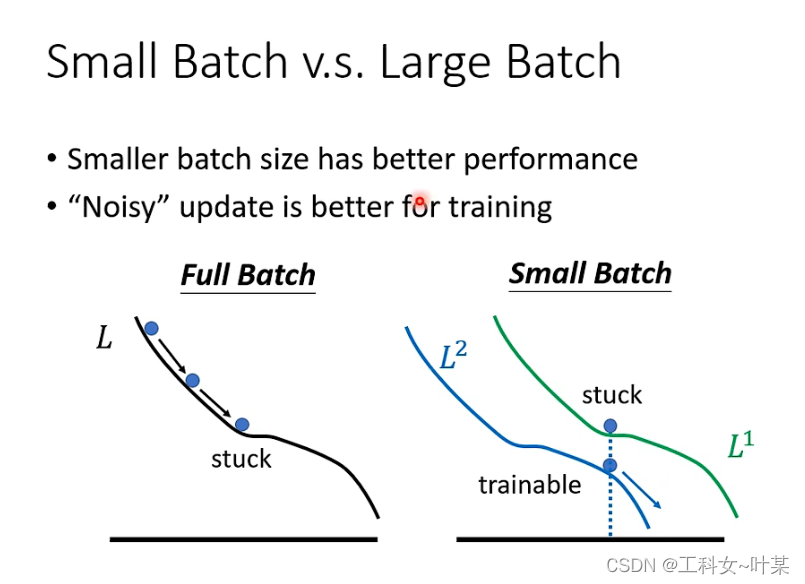
3.1.1 small batch与large batch的比较
以下是大的batch和小的batch的比较如下:
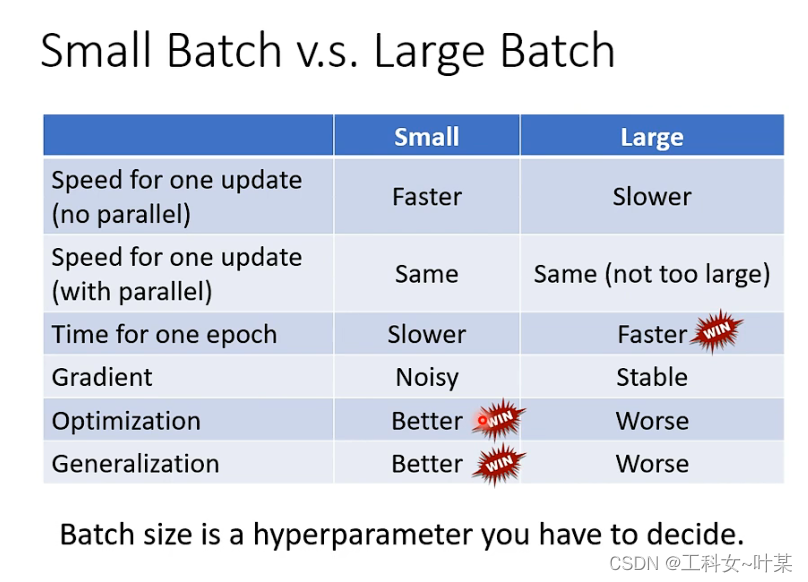
小的batch和大的batch两者中各有优劣,小的batch在最优化和generalization时表现的更好,而大的batch在一个epoch中训练所需时间表现更快。
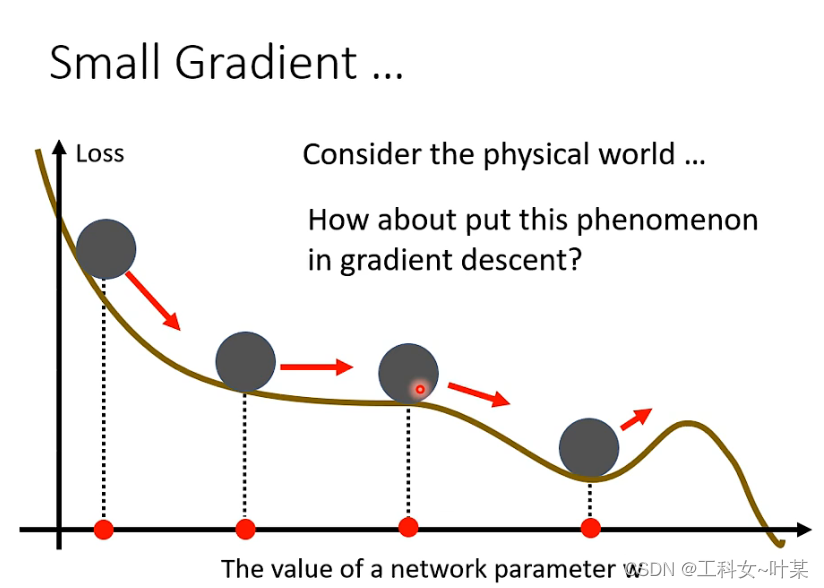
3.2 动量(momentum)
Momentum(动量)优化算法是对梯度下降法的一种优化, 它在原理上模拟了物理学中的动量,已成为目前非常流行的深度学习优化算法之一。
在物理世界中,将一个球从高处滚下来,遇到local minimum的时候就不一定会停住,会因为惯性越过local minimal,不一定会卡住。
3.2.1 momentum计算过程
当梯度下降加上momentum的时候,当我们更新参数时,并不是按照梯度下降的反方向移动参数,而是返反方向加上前一步的方向去调整参数:假设初始参数,
θ
0
\theta0
θ0 ,m0,首先计算g0,第二步就是加上梯度下降的方向和前一步的方向共同决定需要往哪个方向走,接下来反复进行。加上momentum的时候就不是单独考虑梯度下降,而是综合之前所有的梯度方向。
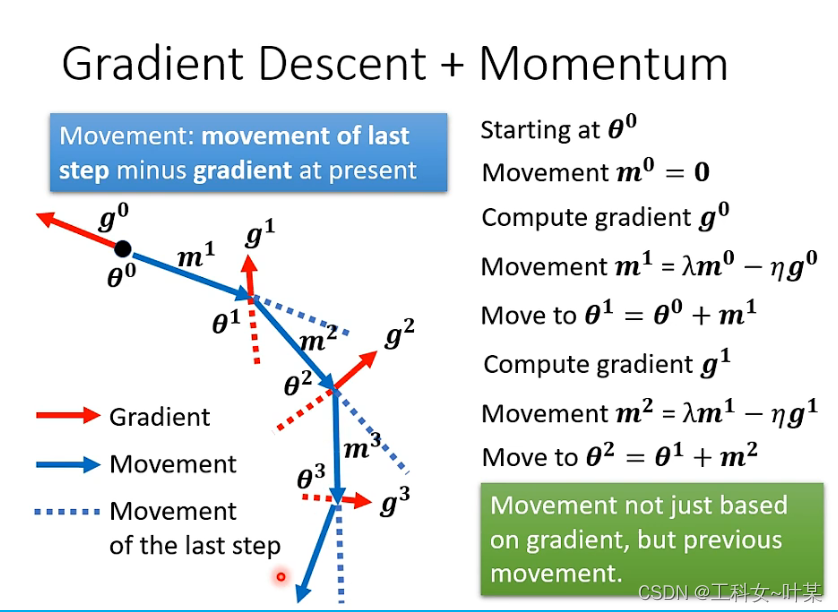
说明:红色方向代表梯度方向,蓝色实线代表更新方向,蓝色虚线代表动量方向(即前一次更新的方向)
3.3 自动调整learning rate
有时候遇到梯度为0的时候不能够以为就是鞍点或者local最小,需要再次计算hessian,做进一步的判断。
特质化学习率:当error surface在某一个方向上非常平坦,希望学习率可以设置大一点,当某一个方向很陡峭的时候,希望学习率能够设小一点,那么学习率应该如何根据梯度下降自动调整?
在一般的梯度下降更新时,learning rate是固定的,
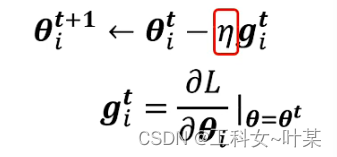
现在将learning rate换成会克制化的learning rate
η
\eta
η/
σ
i
t
\sigma^t_i
σit,这个部分是,这个参数表示,不同的参数需要设置不同的
σ
\sigma
σ,接下来就是看这个
η
\eta
η/
σ
i
t
\sigma^t_i
σit 的计算方式:
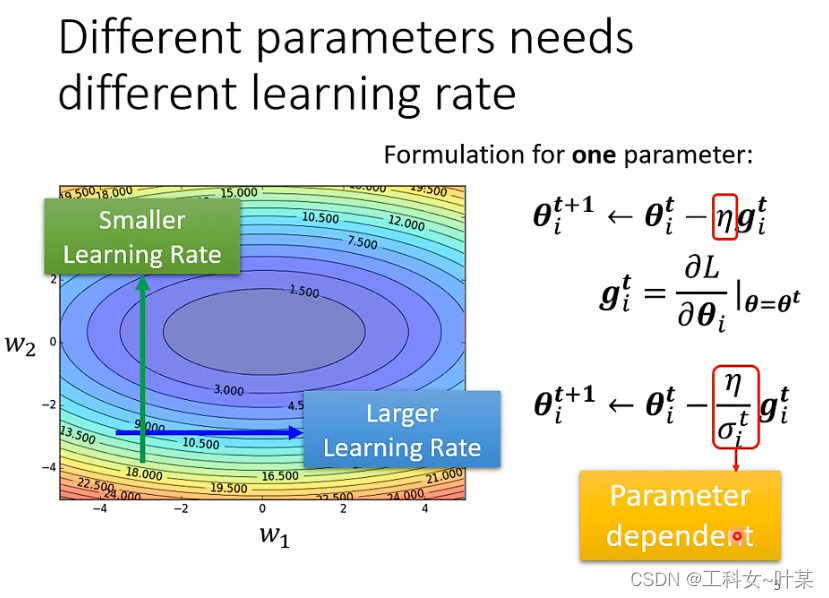
常见的计算方式:常见的类型是计算梯度下降的root mean square如下图:
RMSE(Root Mean Square Error)均方根误差:均方根误差是预测值与真实值偏差的平方与观测次数n比值的平方根。衡量的是预测值与真实值之间的偏差,并且对数据中的异常值较为敏感。
RMSE与标准差对比:
1、标准差是用来衡量一组数自身的离散程度,而均方根误差是用来衡量观测值同真值之间的偏差,它们的研究对象和研究目的不同,但是计算过程类似。
RMSE与MAE对比:
1、RMSE相当于L2范数,MAE相当于L1范数。次数越高,计算结果就越与较大的值有关,而忽略较小的值,所以这就是为什么RMSE针对异常值更敏感的原因(即有一个预测值与真实值相差很大,那么RMSE就会很大)。
下图中是在更新参数时的root mean square的计算过程:
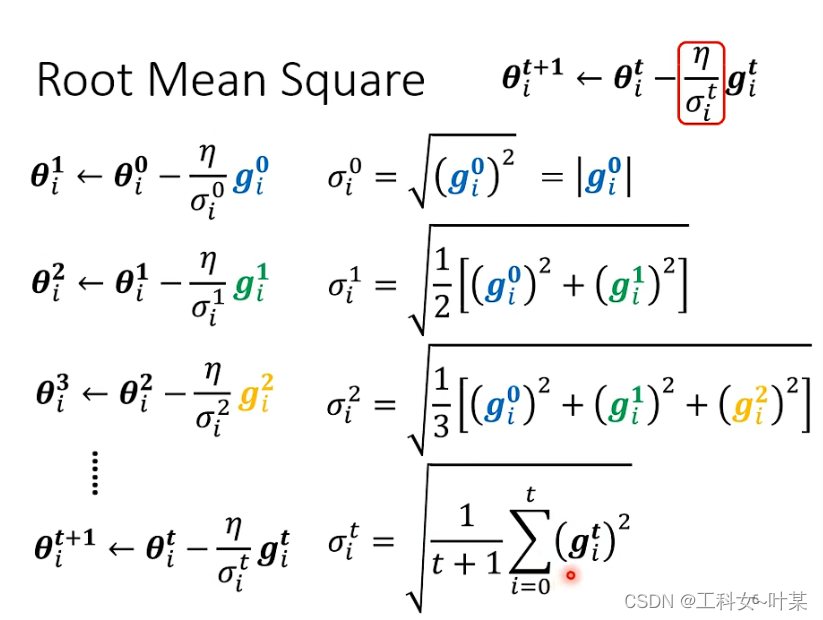
这个会使用在Adagrad中,那么有了这个之后就可以根据参数的不同来自动的调整learning rate的大小。
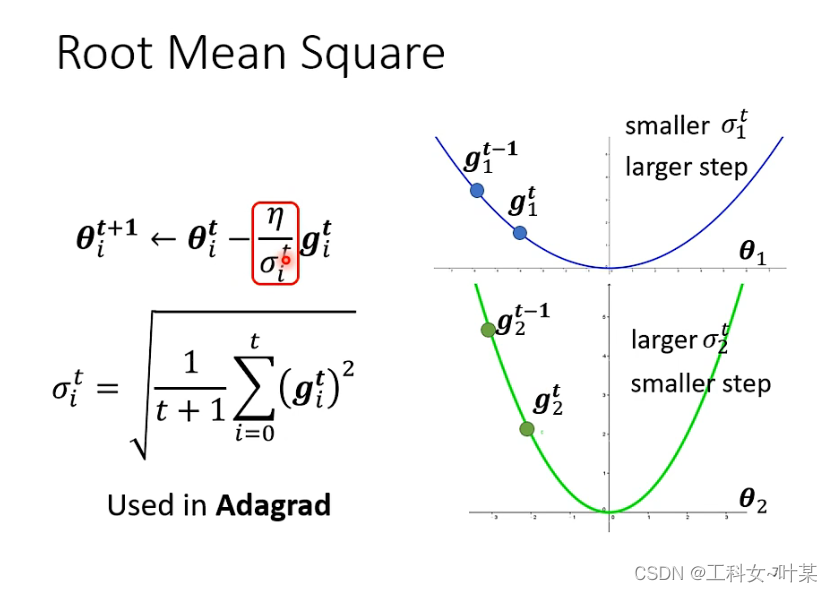
刚才的版本还有什么样的问题?刚刚的假设是同一个参数的梯度好像会固定是什么样子,但实际上不一定是那样,比如下图中星月型的loss,在中间的地方,又变得平滑,在同一个方向,同一个参数,我们也希望learning rate能够动态的调整大小,就有一个新的方法:
3.3.1 RMSProp优化算法
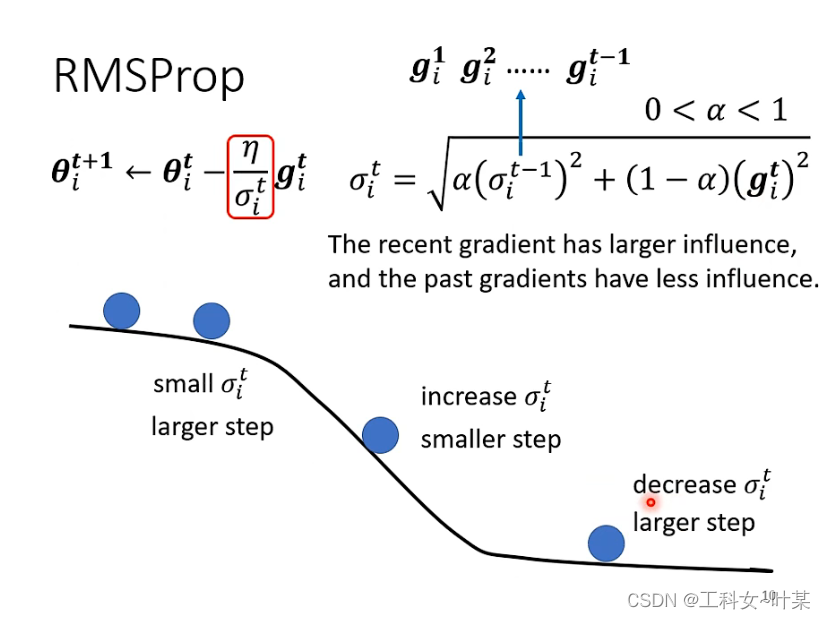
RMSProp的直观理解:RMSProp算法不是像AdaGrad算法那样暴力直接的累加平方梯度,而是加了一个衰减系数来控制历史信息的获取多少。简单来讲,设置全局学习率之后,每次通过,全局学习率逐参数的除以经过衰减系数控制的历史梯度平方和的平方根,使得每个参数的学习率不同。
RMSProp的作用:起到的效果是在参数空间更为平缓的方向,会取得更大的进步(因为平缓,所以历史梯度平方和较小,对应学习下降的幅度较小),并且能够使得陡峭的方向变得平缓,从而加快训练速度。
RMSProp方法:第一步与上面计算方法一样,第二步可以自己调整梯度的重要性
α
\alpha
α。
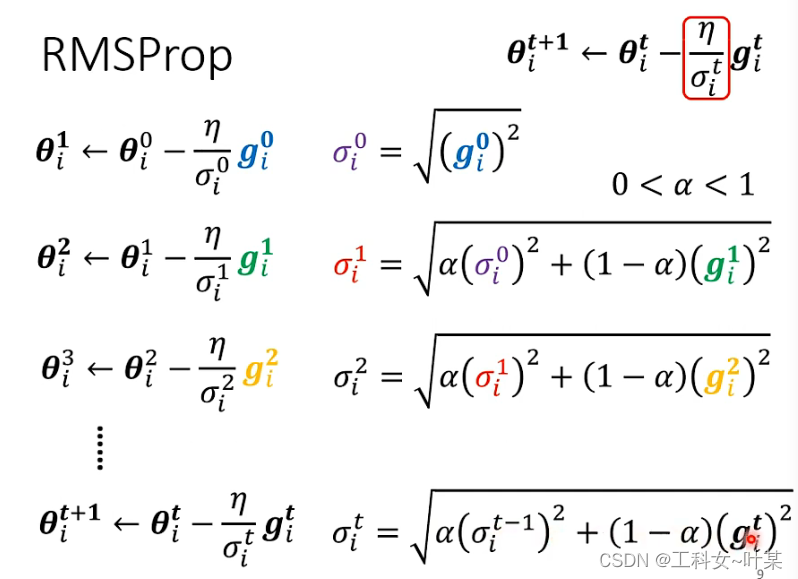
新的学习率深度计算方法可以通过
α
\alpha
α来进行自动调整,如果当前计算出来的
g
i
t
g^t_i
git比较重要就可以减小
α
\alpha
α,如果前一个计算出来的比较重要就可以增大
α
\alpha
α来调整learning rate。
当我们利用梯度下降法的时候,虽然横轴也在前进,但纵轴摆动太大。假设纵轴是b横轴是w,假如我们想减弱b的幅度,加快或者不减少w的前进,RMSProp算法就可以起到这个作用。
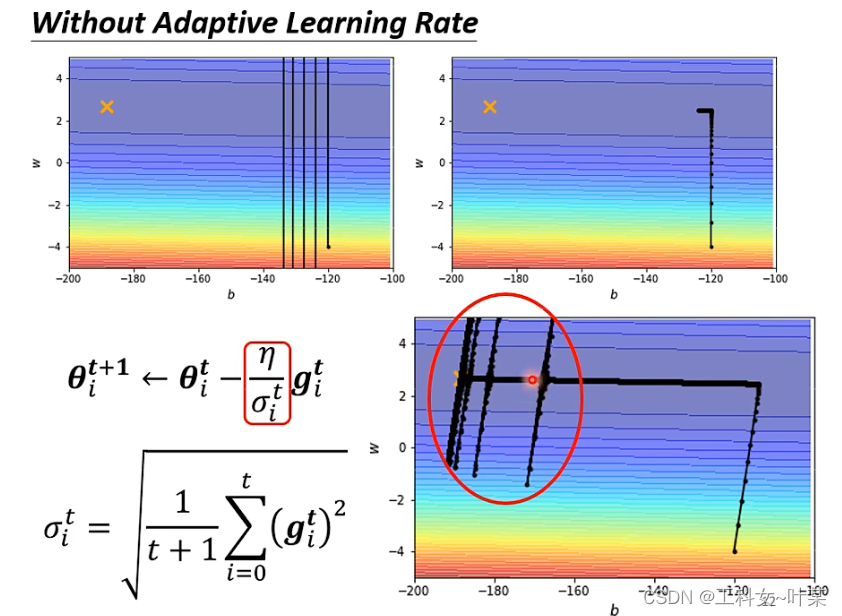
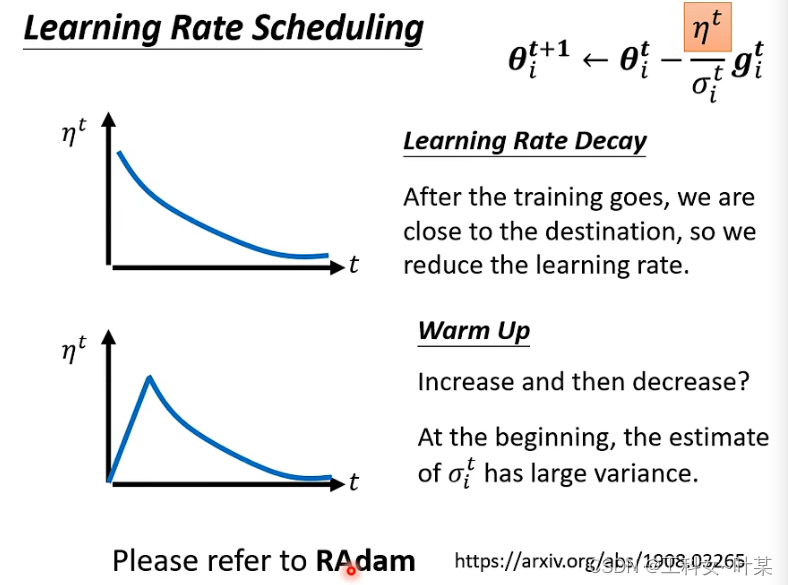
warm up:是在ResNet论文中提到的一种学习率预热的方法,它在训练开始的时候先选择使用一个较小的学习率,训练了一些epoches或者steps(比如4个epoches,10000steps),再修改为预先设置的学习来进行训练。
一开始的时候设置0.01,是因为一开始的时候让学习率掌握error surface的情报,搜集有关
σ
\sigma
σ的信息,精准以后再让learning rate慢慢增加。
4 损失函数(Loss)可能影响网络训练失败
4.1 softmax函数
softmax含义: 在机器学习尤其是深度学习中,softmax是个非常常用而且比较重要的函数,尤其在多分类的场景中使用广泛。他把一些输入映射为0-1之间的实数,并且归一化保证和为1,因此多分类的概率之和也刚好为1。
SoftMax的计算公式如下:
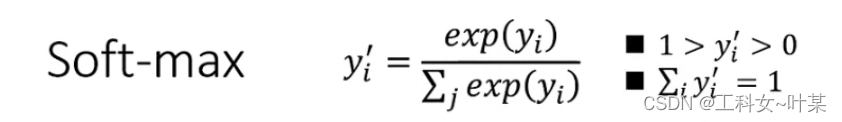
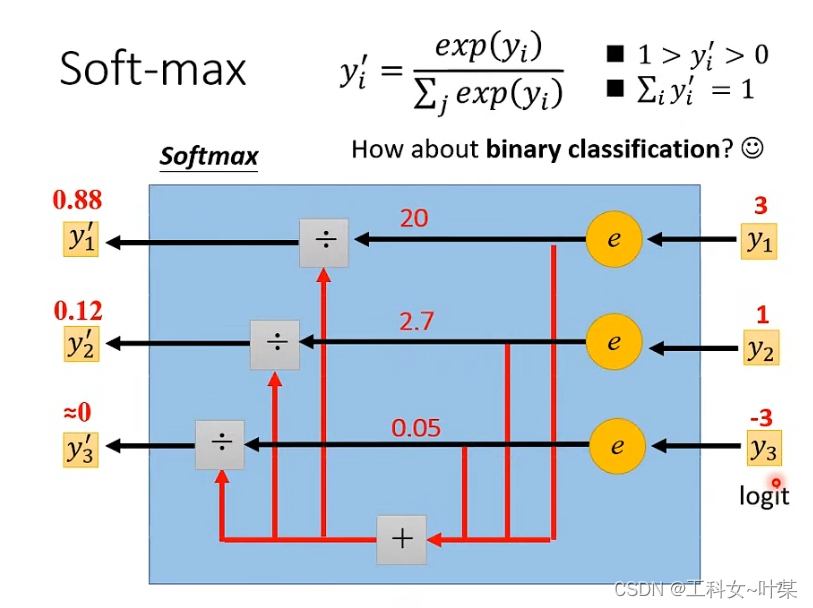
注意点:
当使用Softmax函数作为输出节点的激活函数的时候,一般使用交叉熵作为损失函数。由于Softmax函数的数值计算过程中,很容易因为输出节点的输出值比较大而发生数值溢出的现象,在计算交叉熵的时候也可能会出现数值溢出的问题。为了数值计算的稳定性,TensorFlow提供了一个统一的接口,将Softmax与交叉熵损失函数同时实现,同时也处理了数值不稳定的异常,使用TensorFlow深度学习框架的时候,一般推荐使用这个统一的接口,避免分开使用Softmax函数与交叉熵损失函数。
总结
在本周的学习中,学习了如何分析loss的变化与原因,梯度下降中遇到临界点不能单一的判断是局部最小值或者是鞍点,需要通过合理的计算与推测,可以使用hessian来进行计算,hessian是一个矩阵,当算出来的hessian是正的,那么就是局部最小,如果是负的那就是局部最大值,如果有正有负,那么就是鞍点,通过判断具体是什么类型的临界点,就可以更好的确定更新参数的方向。调整学习率的时候使用到warm up进行优化是因为刚开始训练时,模型的权重(weights)是随机初始化的,此时若选择一个较大的学习率,可能带来模型的不稳定(振荡),选择Warm up预热学习率的方式,可以使得开始训练的几个epoches或者一些steps内学习率较小,在预热的小学习率下,模型可以慢慢趋于稳定,等模型相对稳定后再选择预先设置的学习率进行训练,使得模型收敛速度变得更快,模型效果更佳。















 8万+
8万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









