






目录
摘要
卷积神经网络是一种前馈型神经网络, 它的出现是受到了生物处理过程的启发,因为神经元之间的连接模式类似于动物的视觉皮层组织。现在,CNN 已经成为众多科学领域的研究热点之一, 特别是在模式分类领域,由于该网络避免了对图像的复杂前期预处理,可以直接输入原始图像,因而得到了更为广泛的应用。可应用于图像分类,目标识别,目标检测,语义分割等等。由于CNN的特征检测层通过训练数据进行学习,所以在使用CNN时,避免了显式的特征抽取,而隐式地从训练数据中进行学习;卷积神经网络以其局部参数共享的特殊结构在图像处理和语音识别方面有着独特的优越性,其布局更接近于实际的生物神经网络,权值共享降低了网络的复杂性,特别是多维输入向量的图像可以直接输入网络这一特点避免了特征提取和分类过程中数据重建的复杂度。
Abstract
Convolutional neural network is a feed-forward neural network, which is inspired by biological processing because the connection pattern between neurons is similar to the organization of the visual cortex in animals. Nowadays, CNN has become one of the research hotspots in many scientific fields, especially in the field of pattern classification, where the network is more widely used because it avoids complex pre-processing of images and can be directly input to the original image. It can be applied to image classification, target recognition, target detection, semantic segmentation and so on. Since the feature detection layer of CNN learns through training data, it avoids explicit feature extraction and implicitly learns from training data when using CNN; convolutional neural network has unique superiority in image processing and speech recognition with its special structure of local parameter sharing, and its layout is closer to the actual biological neural network, and the weight sharing reduces the complexity of the network. In particular, the feature that images with multidimensional input vectors can be directly input to the network avoids the complexity of data reconstruction in the process of feature extraction and classification.
1 CNN
卷积神经网络(Convolutional Neural Networks)是一种深度学习模型或类似于人工神经网络的多层感知器,卷积神经网络的创始人是着名的计算机科学家Yann LeCun,常用来分析视觉图像。
1.1 卷积神经网络的架构
在影像辨识中,通过辨识图片中的形状分别是什么东西,将所有的形状放入到系统中,但有时候分辨一个种类的东西并不需要将整张图片的特征都输入到神经元中,只需要将部分的特征进行输入,就可以辨识一些具有特征性的东西。如果用全连接神经网络处理大尺寸图像具有三个明显的缺点:
1、首先将图像展开为向量将会丢失空间信息;
2、其次当参数过多时训练困难并且效率低;
3、最后大量的参数也很快会导致网络出现过拟合的现象。
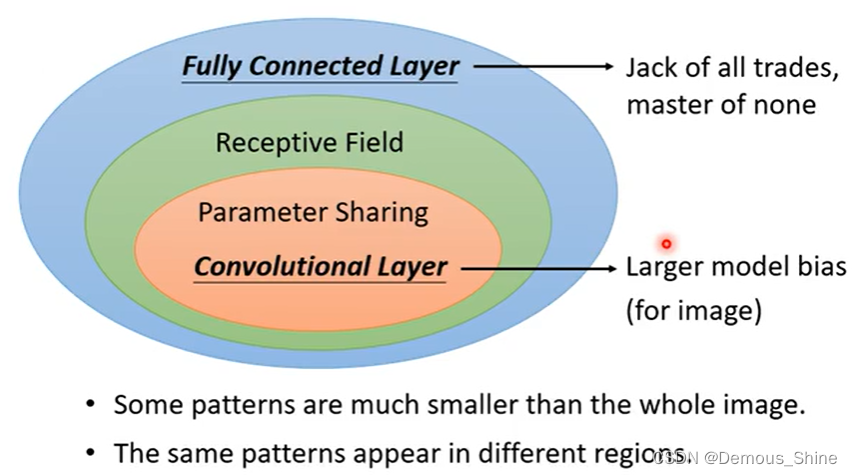
但如果使用CNN的话就可以很好的避免这几个问题:卷积神经网络的各层中的神经元是3维排列的:宽度、高度和深度。其中的宽度和高度是很好理解的,因为本身卷积就是一个二维模板,但是在卷积神经网络中的深度指的是激活数据体的第三个维度,而不是整个网络的深度,整个网络的深度指的是网络的层数。
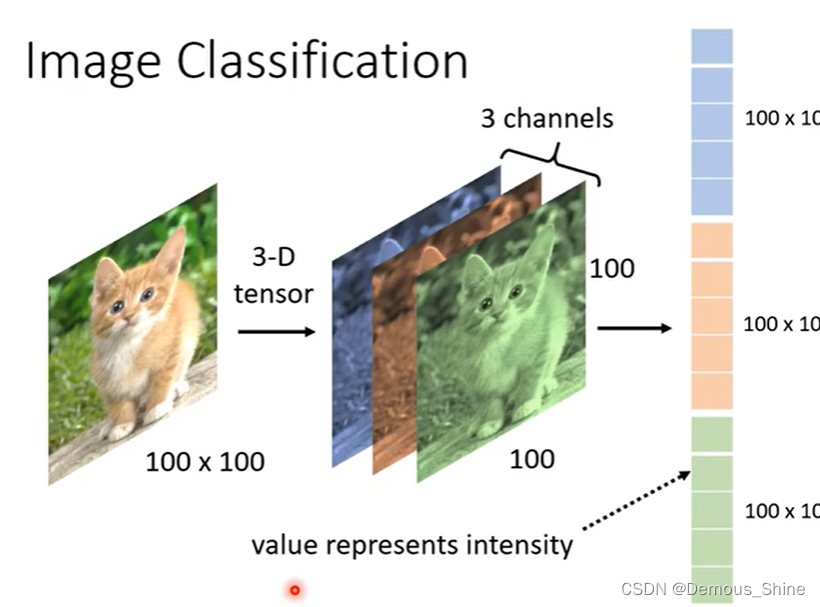
对下面这张图片进行影像的辨识,分辨图片中的是什么动物,对于机器而言一张图片是由三维的Tensor组成,一维代表宽度,一维代表长度,另外一维代表深度;在深度学习里,Tensor实际上就是一个多维数组, 而Tensor的目的是能够创造更高维度的矩阵、向量。 在计算机视觉中,彩色图片就是用3阶张量描述的,黑白图片可以用矩阵描述,加上高度维度描述RGB后就可以描述彩色图片了。将一张三维的Tensor拉直就可以将其放进神经网络中,将图片变成一个向量,即可作为神经网络的输入。将三维Tensor拉直之后,每一维分别代表了RGB三种颜色的不同强度。
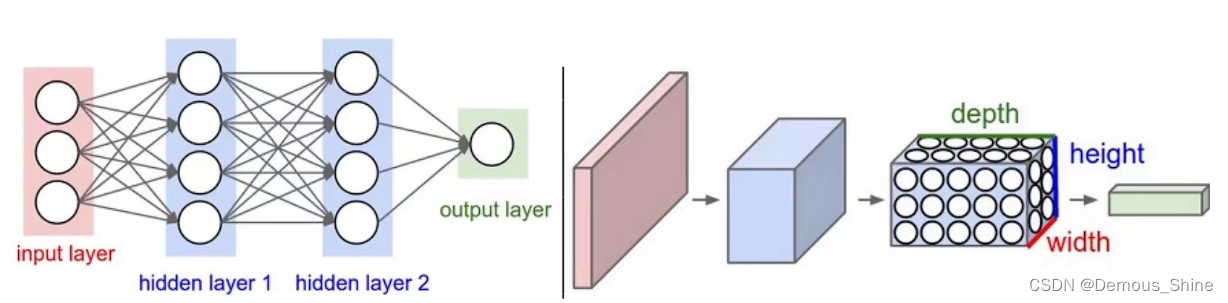
下图中左侧是一个3层的神经网络;右侧是一个卷积神经网络,将它的神经元在成3个维度(宽、高和深度)进行排列。卷积神经网络的每一层都将3D的输入数据变化为神经元3D的激活数据并输出。在图1的右侧,红色的输入层代表输入图像,所以它的宽度和高度就是图像的宽度和高度,它的深度是3(代表了红、绿、蓝3种颜色通道),与红色相邻的蓝色部分是经过卷积和池化之后的激活值(也可以看做是神经元) ,后面是接着的卷积池化层。
2 CNN层级结构
2.1 Input layer(输入层)
数据输入层主要是对原始图像数据进行预处理,其中包括:
- 去均值:把输入数据各个维度都中心化为0,如下图所示,其目的就是把样本的中心拉回到坐标系原点上。
- 归一化:幅度归一化到同样的范围,如下所示,即减少各维度数据取值范围的差异而带来的干扰,比如,我们有两个维度的特征A和B,A范围是0到10,而B范围是0到10000,如果直接使用这两个特征是有问题的,好的做法就是归一化,即A和B的数据都变为0到1的范围。
- PCA/白化:用PCA降维;白化是对数据各个特征轴上的幅度归一化
2.2 CONV layer(卷积计算层)
这一层就是卷积神经网络最重要的一个层次,也是“卷积神经网络”的名字来源。
在这个卷积层,有两个关键操作:
- 局部关联。每个神经元看做一个滤波器(filter)。
- 窗口(receptive field)滑动, filter对局部数据计算。(receptive filed由自己划分,同一个神经元可以观察同一个receptive filed,多个的receptive filed之间也可以进行重叠)
在CNN中会设计一个receptive filed,每一个神经元只需要关心自己的神经网络所发生的的内容即可,不需要关心整个图片的内容。每一个神经元如何考虑自己所在可接受域中的内容?即将三个33的矩阵拉直,再将27维的数据进行输入,神经元会分布给每一维一个weight,再将得到的数据作为下一个神经元的输入。
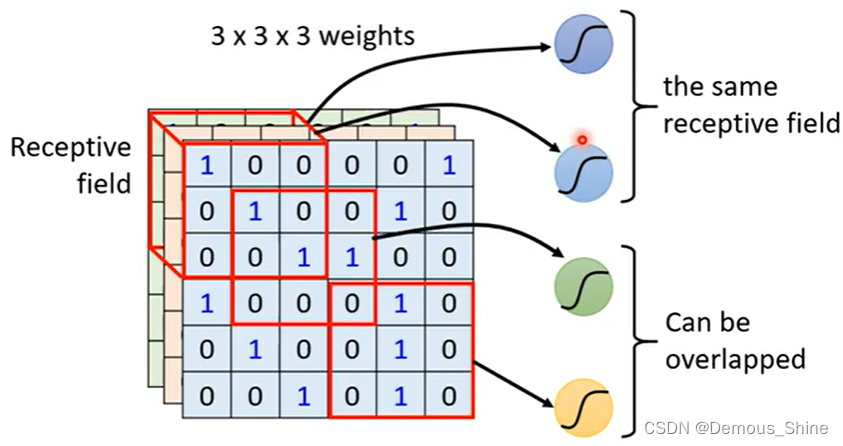
最经典的receptive filed安排方式:
常见的是33,如果其他的大小会有什么影响?在第一个receptive filed的基础上移动,就可以生成一个新的receptive filed,这样移动的量的大小叫做步长,加入步长太大会产生什么影响?(如果步长太大会使得有一些因为步长太大而不能被观测,将会遗漏,因此每一个receptive filed之间需要高度的重叠)当移动步长到边界时,receptive filed大于影像的范围,那么就将剩下没有的影像的部分设置为padding,这个填充值是用0来进行填充的。
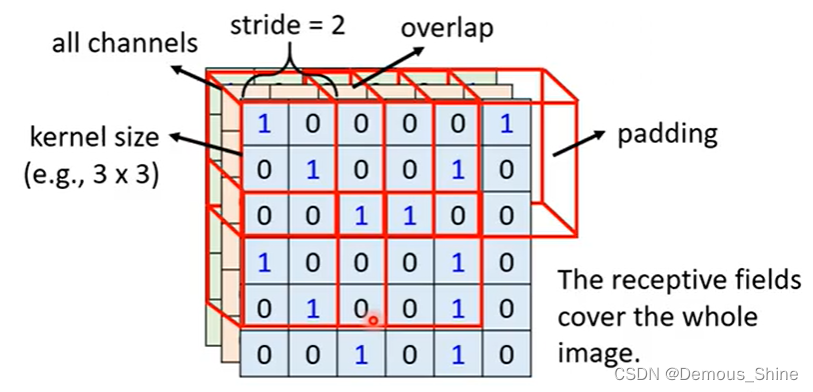
步幅(stride):窗口一次滑动的长度。
为何使用零填充?
因为使用零填充可以提高算法性能。如果卷积层值进行卷积而不进行零填充,那么数据体的尺寸就会略微减小,那么图像边缘的信息就会过快地损失。
2.2.1 参数共享机制
参数共享:在局部连接中,每个神经元的参数都是一样的,即:同一个卷积核在图像中都是共享的。当参数一样的时候是否会出现输出也是一样的?答案是不会,是因为两个神经元的输入是不一样的,如果两个神经元的守卫范围是一样,当参数一样时就会出现输出一样的情况。
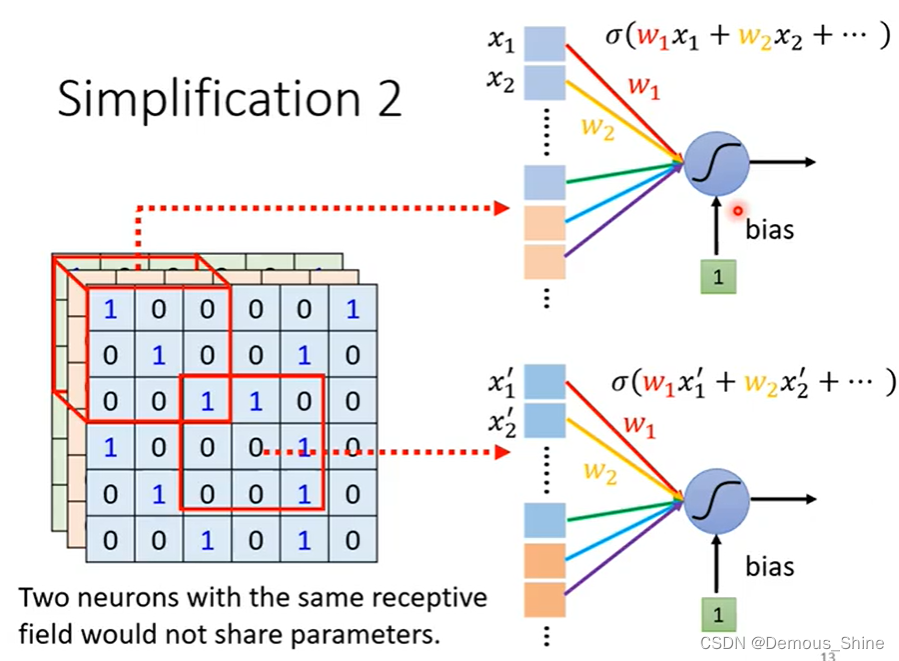
filter的定义:两个神经元公用一组参数,那么该组参数就叫做filter。
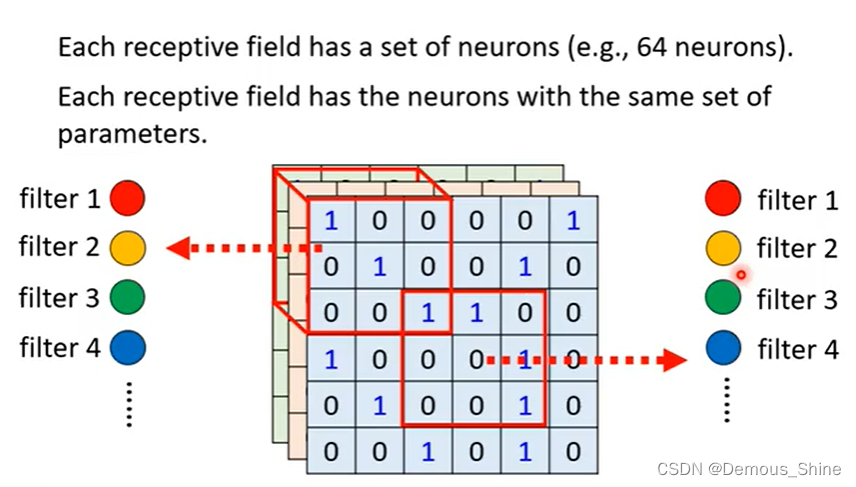
2.2.2 卷积层的好处
- 降低参数的数量。这个由于卷积具有“权值共享”这样的特性,可以降低参数数量,达到降低计算开销,防止由于参数过多而造成过拟合。
- 可以被看做是神经元的一个输出。神经元只观察输入数据中的一小部分,并且和空间上左右两边的所有神经元共享参数
2.3 ReLU layer(ReLU激励层)
CNN采用的激活函数一般为ReLU(The Rectified Linear Unit/修正线性单元),它的特点是收敛快,求梯度简单,但较脆弱。
2.4 Pooling layer(池化层)
池化层夹在连续的卷积层中间, 用于压缩数据和参数的量,减小过拟合。简单的来说,如果输入的是图像,那么池化层的是将图片进行缩小,但是实际图片中是什么并不会改变。
pooling layer第一可以保证特征不变性,也就是我们在图像处理中经常提到的特征的尺度不变性,池化操作就是图像的resize,平时一张猫的图像被缩小了一倍我们还能认出这是一张猫的照片,这说明这张图像中仍保留着猫最重要的特征,我们一看就能判断图像中画的是一只猫,图像压缩时去掉的信息只是一些无关紧要的信息,而留下的信息则是具有尺度不变性的特征,是最能表达图像的特征。
第二可以进行特征降维,我们知道一幅图像含有的信息是很大的,特征也很多,但是有些信息对于我们做图像任务时没有太多用途或者有重复,我们可以把这类冗余信息去除,把最重要的特征抽取出来,这也是池化操作的一大作用。
第三是在一定程度也能够防止过拟合,便于后期进行优化。
池化层用的方法有Max pooling 和 average pooling,而实际用的较多的是Max pooling。
Max pooling的运作方式如下:
每一个filter都产生一组数字,这组数字可以分成几个部分,每一个部分是一个2*2的矩阵,取每一个部分中最大的数字。
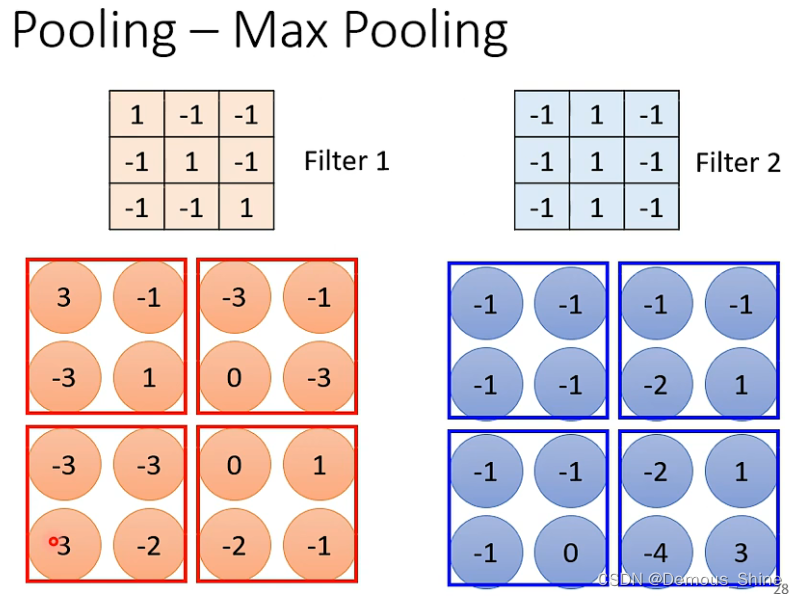
取每一组最大数字后得到的结果如下;
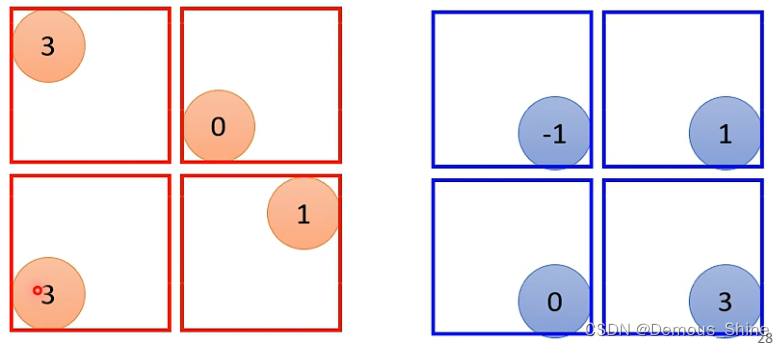
在经过convolution之后还需要进行pooling,这两者交叉进行。
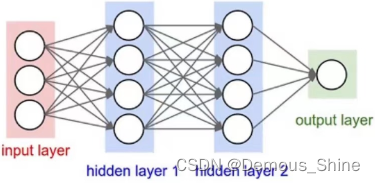
2.5 FC layer(全连接层 )
两层之间所有神经元都有权重连接,通常全连接层在卷积神经网络尾部。也就是跟传统的神经网络神经元的连接方式是一样的:
为什么使用了验证集之后还是出现了过拟合
实际上我们会在验证集上来评估
h
1
∗
h^*_1
h1∗、
h
2
∗
h^*_2
h2∗、
h
3
∗
h^*_3
h3∗的好坏,看哪一个在验证集上的Loss最小,最后再确定用哪一个function在testing set上;用验证集来挑选model的过程其实也可以想成是一种在
D
v
a
l
D_{val}
Dval上的training;如下图的分析,P(
D
v
a
l
D_{val}
Dvalis bad) 取决于|
H
v
a
l
H_{val}
Hval|和
N
v
a
l
N_{val}
Nval ,若|
H
v
a
l
H_{val}
Hval|大,例如有十万个model需要验证集去挑选,那么也很有可能会overfitting。

总结
这周主要学习了可用于图像分类的卷积神经网络的基本结构。卷积网络在本质上是一种输入到输出的映射,它能够学习大量的输入与输出之间的映射关系,而不需要任何输入和输出之间的精确的数学表达式,只要用已知的模式对卷积网络加以训练,网络就具有输入输出对之间的映射能力。用验证集决定你的model的时候,如果待选的model太多了,仍然有可能会过拟合。CNN在一定程度上能够减少参数的数量,也能够一定程度上减少过拟合发生。CNN的卷积操作实际上是一个个局部信息,而局部信息而局部信息的一些统计特性和其他部分是一样的,也就意味着这部分学到的特征也可以用到另一部分上。















 8万+
8万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









