






摘要
卷积神经网络在图像识别中有着很强大、广泛的应用,但是也有一些场景是CNN无法得到有效解决的,例如:语音识别,需要按顺序处理每一帧的声音信息,有些结果需要根据上下文进行识别;自然语言处理,要依次读取各个单词,识别某段文字的语义,这些场景都有一个特点,就是与时间序列有关,并且输入的序列数据长度不是固定不变的。在现实生活中,例如对一个演讲进行语音识别,演讲者每讲一句话的时间几乎都不太相同,而识别演讲者的讲话内容还必须要按照讲话的顺序进行识别。因此需要有一种能力更强的模型:该模型具有一定的记忆能力,能够按时序依次处理任意长度的信息。
Abstract
Convolutional neural networks have a very powerful and wide range of applications in image recognition, but there are also some scenarios that CNNs can not be effectively solved, for example: speech recognition, the need to sequentially process each frame of voice information, some results need to be recognized according to the context; natural language processing, to read each word in turn, to identify the semantics of a certain text, these scenarios have a feature that is related to time series and the input sequence data length is not fixed. In real life, for example, speech recognition of a speech, the time of each sentence spoken by the speaker is almost never the same, and the recognition of the speaker’s speech must also be recognized in accordance with the order of the speech. Therefore a more capable model is needed: the model has a certain memory capacity and can process information of arbitrary length in chronological order.
RNN
循环神经网络(Recurrent Neural Networks,RNN) :一种特殊的神经网络结构,它是根据"人的认知是基于过往的经验和记忆"这一观点提出的。它与DNN,CNN不同的是:它不仅考虑前一时刻的输入,而且赋予了网络对前面的内容的一种’记忆’功能。
首先我们在学习RNN之前先看一个例子,在订票系统中我们需要有slot filling,而slot filling我们需要知道那些词汇是属于对应slot中的,比如destination中的词是Taipei,而time of arrival中的词是November
2
n
d
2^{nd}
2nd,其他的词汇不属于任何slot中。
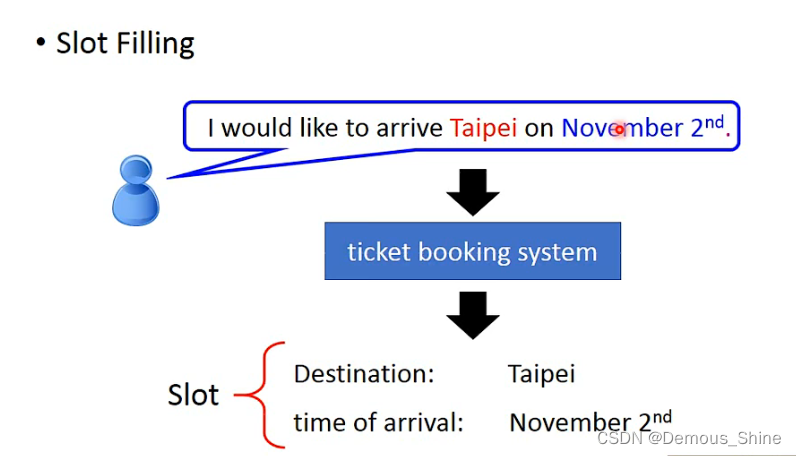
需要解决这个问题我们可以使用feedbacknetwork,需要把词汇输入到network中,那么就需要把一个词汇用一个向量来表示,
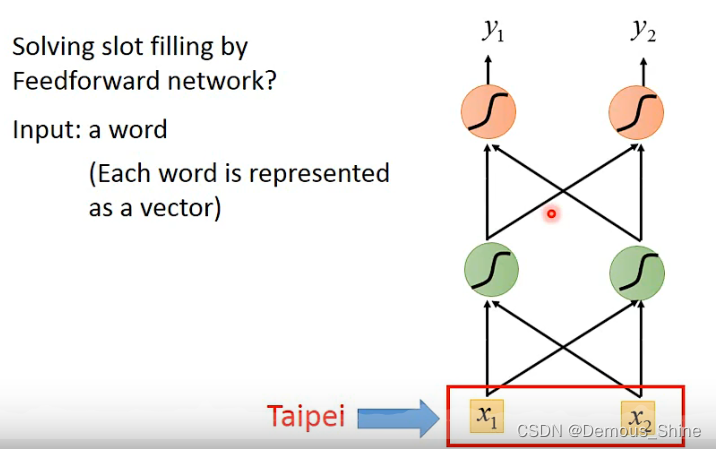
可以使用1-of-N encoding来表示一个词汇,也可以使用Beyond 1-of-N encoding来表示一个词汇,因为有一些词汇我们并没有见过,那么就需要再=dimension中增加一维other,把没有见过的词汇归类到里面去,比如Gandalf,也可以使用word hashing,这样就不会出现不认识的词汇不知道如何归类的情况,例如: apple中出现了 app ppl ple,那么对应的三个维度就是1,其他维度都是0。
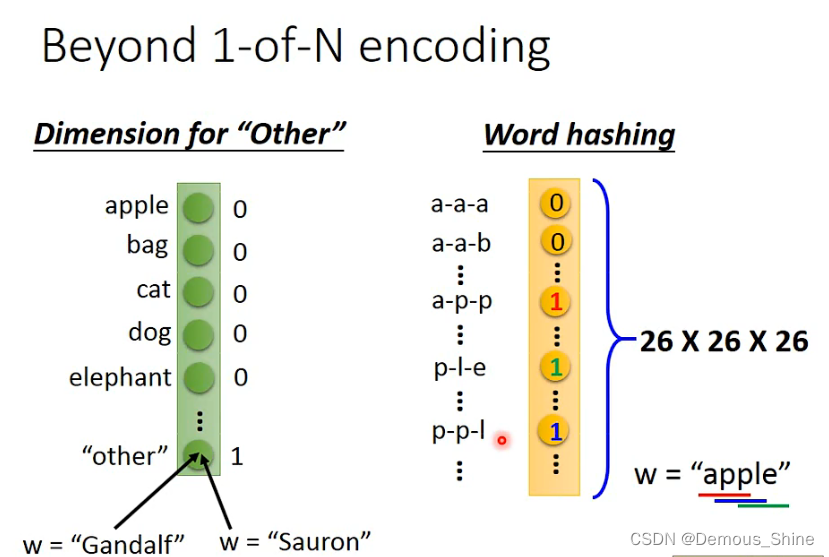
再将词汇向量放入到network中,就可以输出属于每个slot分布的可能性,但是当有两个人都说了Taipei这个词汇时,对于network来说同样的输入会得到同样的输出,而实际上这两个相同的输入应该对应不同的输出,那么就需要network有记忆力,如果network有记忆力,那么当network看见Taipei时之前就已经分别看见过arrive和leave,这样就可以产生不同输出,这样就解决了同样的输入得到不一样的输出。
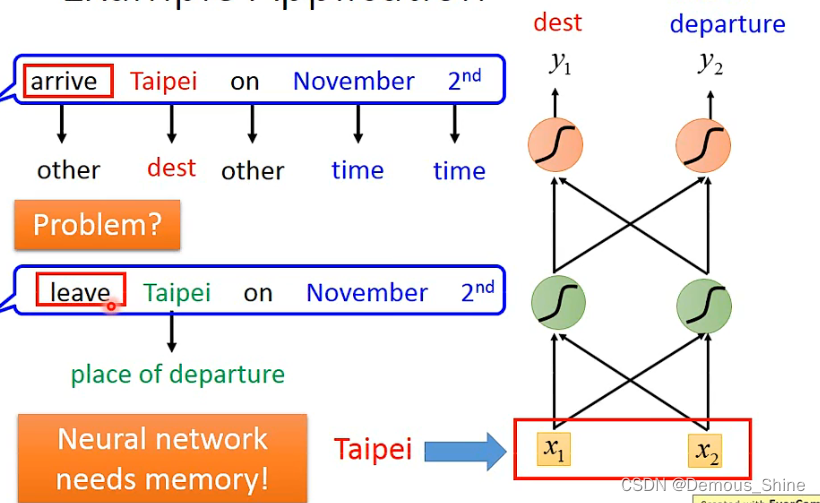
那拥有记忆力的network就是循环神经网络,每次神经元产生的输出都会被存入到memory中,当下次输入时,隐藏层中的神经元就不只是考虑输入的值,会同时考虑存在memory中的值,
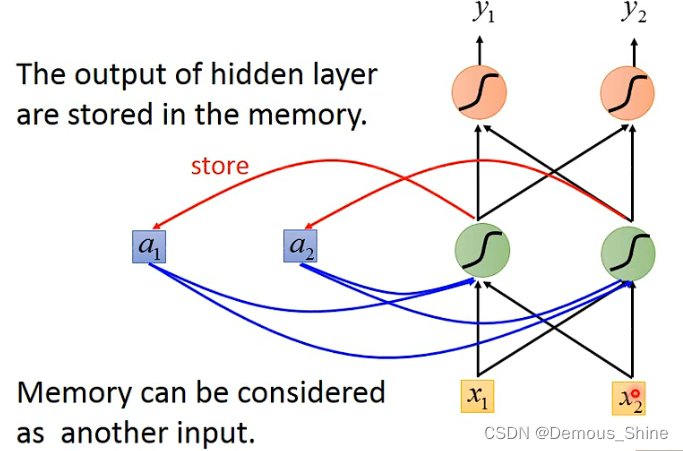
RNN的简单结构
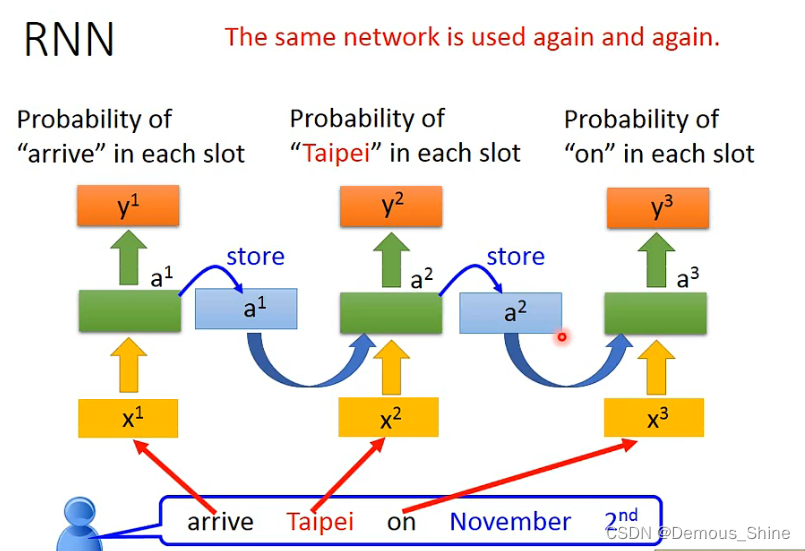
在循环神经网络中会考虑输入的顺序,当我们使RNN来做slot filling时就可以将输入放进network中,那么当输入arrive时,隐藏层产生a1,根据a1产生y1,a1存入到memory中,当输入Taipei时隐藏层会同时结合a1的值,产生a2,再根据a2产生y2,以此类推,就可以得到每一个词汇输入每一个slot的几率。下面是同一个network,在不同的时间使用 了三次。
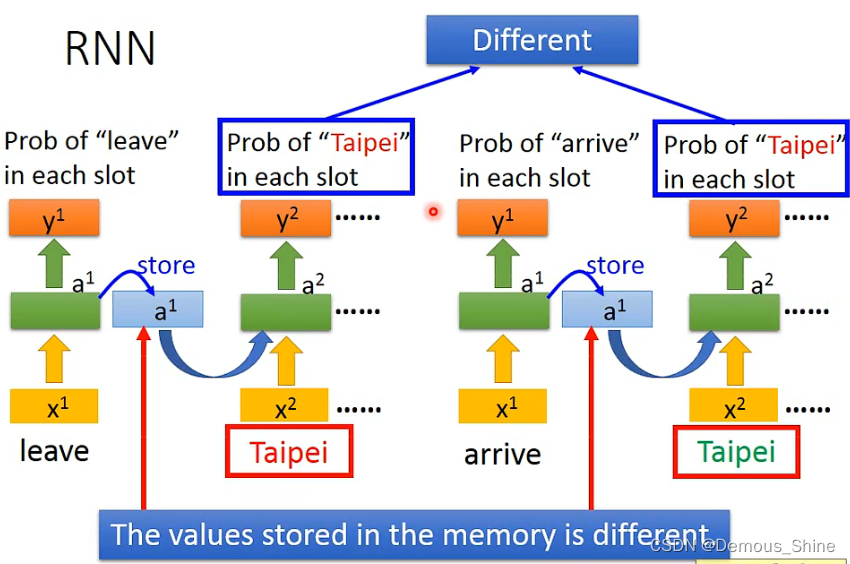
当输入都是Taipei时,由于memory中的内容不同,那么就会得到不同的a2,最终得到的输出也会不一样。
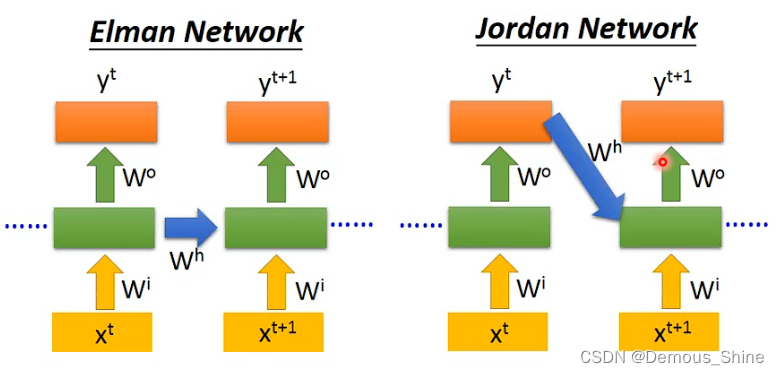
Elman network 是将前面一个时间点的值存起来,在下一次输入的时候考虑前一次memory中的值,Jordan network存的是输出的值,在下一个时间点将前一个时间点输出的值读进来,Jordan的效果比elman效果好是因为Jordan的输出是有目标的,而Elman是没有目标的,
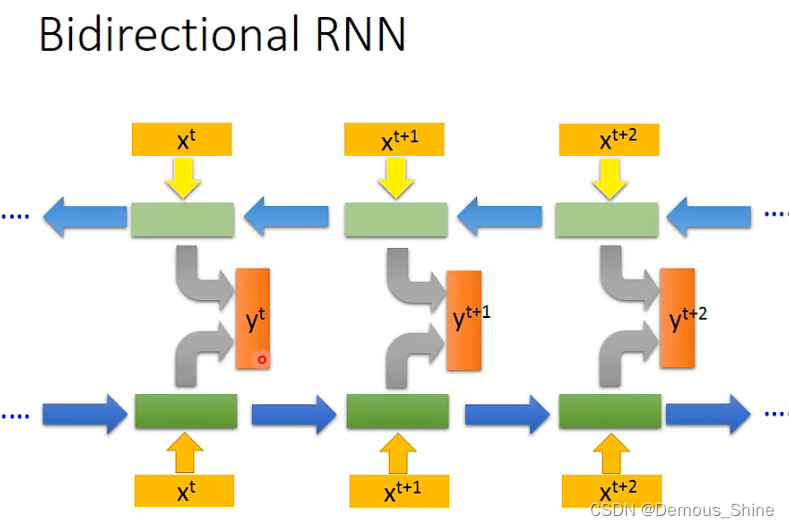
bidirectional RNN中,可以正向进行输入,也可以反向进行输入,但实际上可以同时正向输入和反向输入,在两种不同输入的隐藏层都拿出来接到一个输出层中产生输出,使用这个RNN的好处是,network看的范围是比较广的,如果只是使用正向的就只是看过前面的内容,但是正向和反向同时时,是看过整个句子时得到的结果。
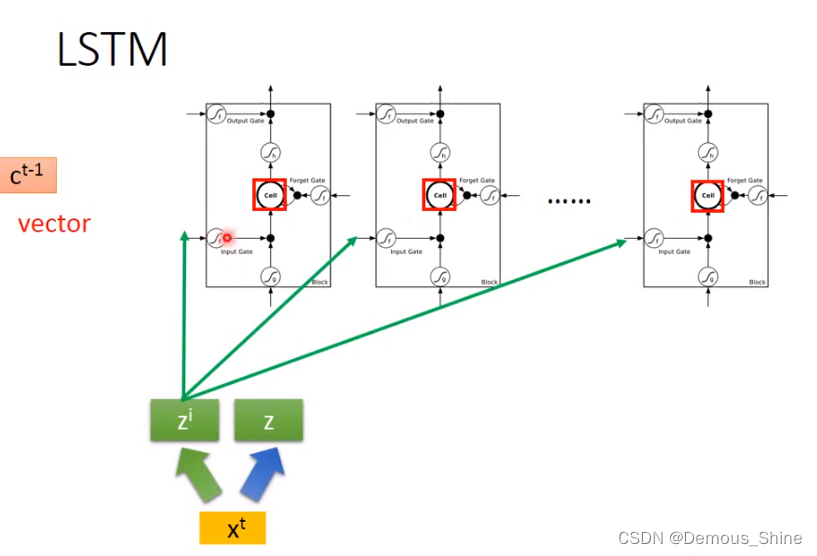
LSTM(Long short-term memory)
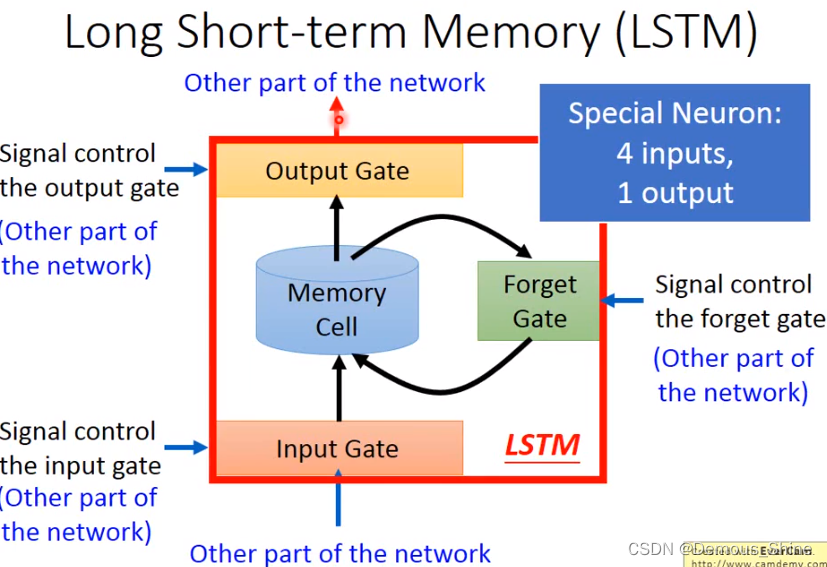
刚刚的类型是最简单的RNN,可以随时将值存入到memory中,也可以随时把值从memory中取出来,但现在比较常用的memory叫LSTM,它包含三个gate,只有当gate打开时才可以将信息存储到memory中,这个input什么时候打开和关闭是机器自己学到的,同时输出也有一个output gate,当gate打开时,才可以将信息取出来,第三个是forget gate是什么时候memory需要把存储的信息忘记,LSTM可以看做有四个输入一个输出,一个是想要被存入到memory中的值,一个是操控input和output和forget的信号。
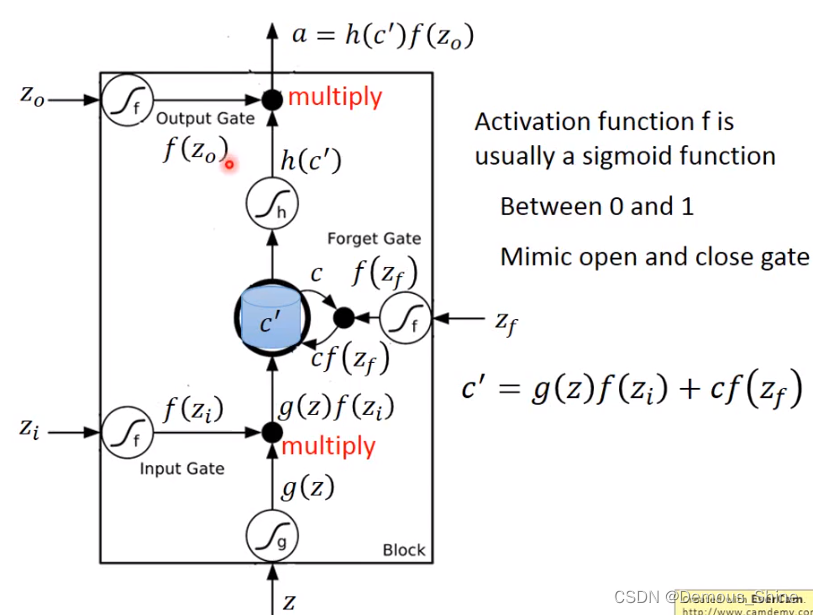
在图中含有三个gate,分别是输入,输出、遗忘门,外界输入 信息为Z,控制输入门的信号是
Z
i
Z_i
Zi,输出门的是
Z
o
Z_o
Zo ,遗忘门的是
Z
f
Z_f
Zf,分别经过SIGMOD函数之后得到
f
(
Z
i
)
,
f
(
Z
o
)
,
f
(
Z
f
)
f(Z_i),f(Z_o),f(Z_f)
f(Zi),f(Zo),f(Zf),输入经过SIGMOD函数之后得到
g
(
z
)
g(z)
g(z)使用SIGMOD函数是因为可以将值的范围在0-1,当为0的时候代表门关闭,为1的时候代表门打开。当输入门打开时,将
g
(
z
)
f
(
Z
i
)
g(z)f(Z_i)
g(z)f(Zi)相乘,接下来将存在memory中的c乘以
f
(
Z
f
)
f(Z_f)
f(Zf),
c
’
=
c
f
(
Z
f
)
+
g
(
z
)
f
(
Z
i
)
c^’=cf(Z_f)+g(z)f(Z_i)
c’=cf(Zf)+g(z)f(Zi),这是存在memory中的新值。f(Zi)是控制是否可以输入的关键,
f
(
Z
f
)
f(Z_f)
f(Zf)为1时forget gate就会记得之前的值,如果为0 时就会讲之前的值忘记,将memory中的值设为0,再将
c
’
c^’
c’经过SIGMOD得到
h
(
c
’
)
h(c^’)
h(c’),当
f
(
Z
o
)
f(Z_o)
f(Zo)为1 时
h
(
c
’
)
h(c^’)
h(c’) 就可以通过output,如果为0时就不能通过,就不能被取出来。
- Input Gate:中文是输入门,在每一时刻从输入层输入的信息会首先经过输入门,输入门的开关会决定这一时刻是否会有信息输入到Memory
Cell。 - Output Gate:中文是输出门,每一时刻是否有信息从Memory Cell输出取决于这一道门。
- Forget Gate:中文是遗忘门,每一时刻Memory
Cell里的值都会经历一个是否被遗忘的过程,就是由该门控制的,如果打卡,那么将会把Memory Cell里的值清除,也就是遗忘掉。
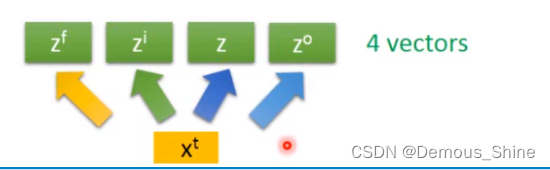
在原来的network中,一个输入对应一个输出,但是在LSTM中需要有四个输入才会有一个输出,x1和x2在每一个门分别乘不同的weight,得到不同的值,同神经元的数量相同时,LSTM所需要的参数将是原始network的四倍。
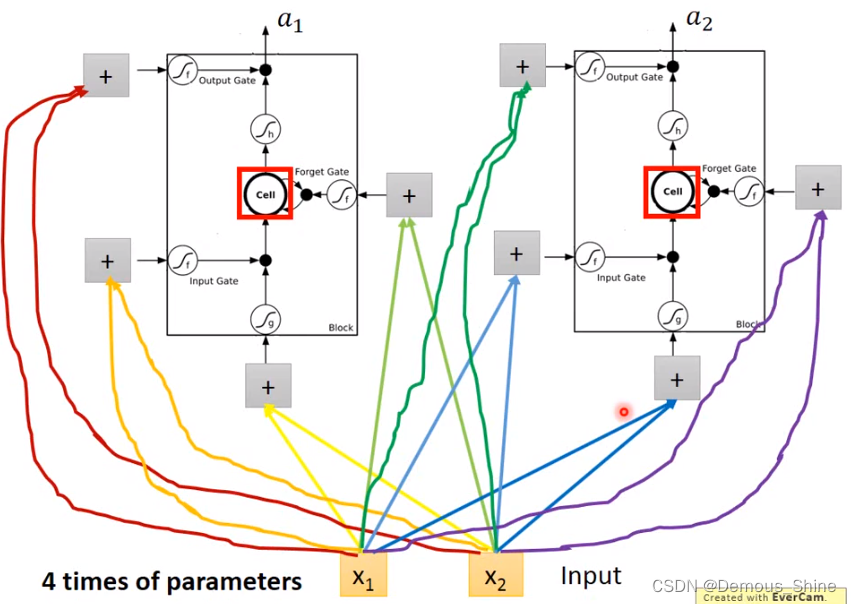
当有多个memory cell时,可以将输入时间点t输入的向量x乘以一个线性的transfome得到Z,得到的向量Z中每一维对应一个memory cell的输入,xt乘以另外一个transfom之后得到的向量Zi每一维对应一个input gate的信号。将xt乘以四个不同的transform得到四个不同的向量,四个向量的维度都与memory cell的数量相同。
CNN代码实例
导入需要使用到的包库
import torch
import torch.nn as nn
from torch.autograd import Variable
import torch.utils.data as Data
import torchvision
import matplotlib.pyplot as plt
超参数的配置以及将下载的文件转换成pytorch认识的tensor类型,且将图片的数值大小从(0-255)归一化到(0-1)
#Hyper prameters
EPOCH=1
BATCH_SIZE=50
LR=0.001
DOWNLOAD_MNIST=False
train_data=torchvision.datasets.MNIST(
root='./mnist',
train=True,
transform=torchvision.transforms.ToTensor(), #将下载的文件转换成pytorch认识的tensor类型,且将图片的数值大小从(0-255)归一化到(0-1)
download=DOWNLOAD_MNIST
)
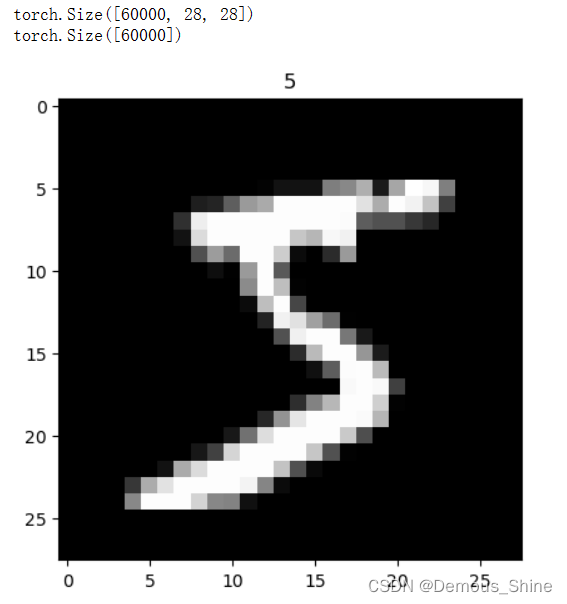
画一个图片显示出来:
print(train_data.data.size())
print(train_data.targets.size())
plt.imshow(train_data.data[0].numpy(),cmap='gray')
plt.title('%i'%train_data.targets[0])
plt.show()
显示结果:
只取前两千个数据,然后将其归一化。
train_loader=Data.DataLoader(dataset=train_data, batch_size=BATCH_SIZE, shuffle=True)
test_data=torchvision.datasets.MNIST(
root='./mnist',
train=False,
)
with torch.no_grad():
test_x=Variable(torch.unsqueeze(test_data.data, dim=1)).type(torch.FloatTensor)[:2000]/255 #只取前两千个数据吧,差不多已经够用了,然后将其归一化。
test_y=test_data.targets[:2000]
开始建立CNN网络
class CNN(nn.Module):
def __init__(self):
super(CNN,self).__init__()
self.conv1=nn.Sequential(
nn.Conv2d( #--> (1,28,28)
in_channels=1, #传入的图片是几层的,灰色为1层,RGB为三层
out_channels=16, #输出的图片是几层
kernel_size=5, #代表扫描的区域点为5*5
stride=1, #就是每隔多少步跳一下
padding=2, #边框补全,其计算公式=(kernel_size-1)/2=(5-1)/2=2
), # 2d代表二维卷积 --> (16,28,28)
nn.ReLU(), #非线性激活层
nn.MaxPool2d(kernel_size=2), #设定这里的扫描区域为2*2,且取出该2*2中的最大值 --> (16,14,14)
)
self.conv2=nn.Sequential(
nn.Conv2d( # --> (16,14,14)
in_channels=16, #这里的输入是上层的输出为16层
out_channels=32, #在这里我们需要将其输出为32层
kernel_size=5, #代表扫描的区域点为5*5
stride=1, #就是每隔多少步跳一下
padding=2, #边框补全,其计算公式=(kernel_size-1)/2=(5-1)/2=
), # --> (32,14,14)
nn.ReLU(),
nn.MaxPool2d(kernel_size=2), #设定这里的扫描区域为2*2,且取出该2*2中的最大值 --> (32,7,7),这里是三维数据
)
self.out=nn.Linear(32*7*7,10) #注意一下这里的数据是二维的数据
def forward(self,x):
x=self.conv1(x)
x=self.conv2(x) #(batch,32,7,7)
#然后接下来进行一下扩展展平的操作,将三维数据转为二维的数据
x=x.view(x.size(0),-1) #(batch ,32 * 7 * 7)
output=self.out(x)
return output
cnn=CNN()
# print(cnn)
# 添加优化方法
optimizer=torch.optim.Adam(cnn.parameters(),lr=LR)
# 指定损失函数使用交叉信息熵
loss_fn=nn.CrossEntropyLoss()
训练模型:
step=0
for epoch in range(EPOCH):
#加载训练数据
for step,data in enumerate(train_loader):
x,y=data
#分别得到训练数据的x和y的取值
b_x=Variable(x)
b_y=Variable(y)
output=cnn(b_x) #调用模型预测
loss=loss_fn(output,b_y)#计算损失值
optimizer.zero_grad() #每一次循环之前,将梯度清零
loss.backward() #反向传播
optimizer.step() #梯度下降
#每执行50次,输出一下当前epoch、loss、accuracy
if (step%50==0):
#计算一下模型预测正确率
test_output=cnn(test_x)
y_pred=torch.max(test_output,1)[1].data.squeeze()
accuracy=sum(y_pred==test_y).item()/test_y.size(0)
print('now epoch : ', epoch, ' | loss : %.4f ' % loss.item(), ' | accuracy : ' , accuracy)
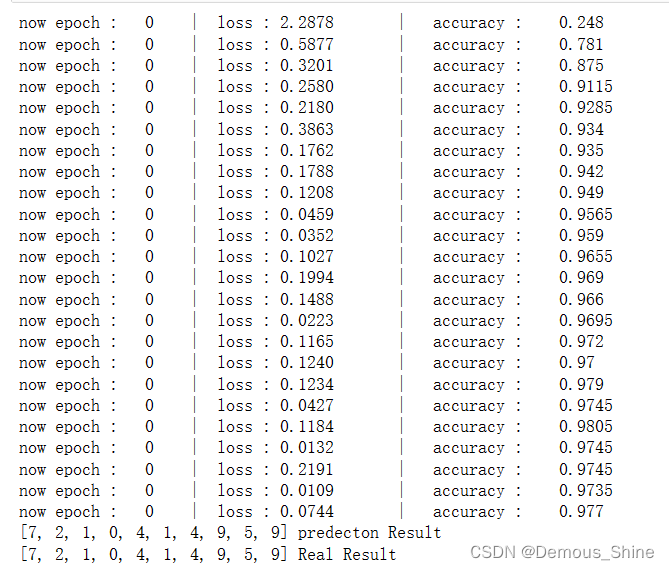
打印十个测试集的结果:
test_output=cnn(test_x[:10])
y_pred=torch.max(test_output,1)[1].data.squeeze() #选取最大可能的数值所在的位置
print(y_pred.tolist(),'predecton Result')
print(test_y[:10].tolist(),'Real Result')
结果如下:
该例子是手写数字识别;在该例子中首先需要获取数据集,数据是来源于MNIST,在本例中是取了前面2000个数据作为数据集,获取数据之后,将下载的文件转换成pytorch认识的tensor类型,且将图片的数值大小从(0-255)归一化到(0-1);接下来就是建立CNN网络,一般来说CNN包括:卷积层、神经网络、池化层。
在建立CNN网络的卷积层中使用了二维卷积进行特征提取,第一层的输入长度与宽度均为28,通道为1,扫描区域为5*5,步长是1,padding为2,使用的非线性激活函数时ReLU;池化层使用MaxPooling;损失函数使用交叉信息熵,接下来就是训练模型,首先加载训练数据,分别得到训练数据的x和y的取值,再调用模型预测,计算损失值,每一次循环之前,将梯度清零,反向传播、梯度下降,每执行50次,输出一下当前epoch、loss、accuracy,计算一下模型预测正确率,最后将打印十个测试集的结果,从最后的结果可以知道模型的损失是0.0744,而准确率达到了0.977。
总结
在本周的学习中,先学习了循环神经网络的一些基础内容,循环神经网络简称RNN,它能够解决时间序列的问题,也拥有“记忆能力”,这种记忆能力的实现是通过将前一步的结果存储在memory中,当需要时就将其取出来,RNN有一种升级版,那就是LSTM长短期记忆。它是一种特殊的RNN,就是相比普通的RNN,LSTM能够在更长的序列中有更好的表现;跑CNN实例代码过程中也遇到了许多的问题,比如torch以及torchvision不能导入,以及CNN实例的每一步应该做什么与怎么做,经过几天的学习也有了一点进步。















 8万+
8万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









