







 文章探讨了时间感受野(TRF),即回归权重在神经计算中的概念,涉及如何在绝对音高、相对音高和音高变化上分析神经元的响应。TRF通过卷积操作模拟神经元对时间刺激的敏感性,其权重表示神经元对特定时间特征的响应选择性。文章还解释了如何通过数学模型如岭回归计算TRF的权重,以及在实验中的应用方法。
文章探讨了时间感受野(TRF),即回归权重在神经计算中的概念,涉及如何在绝对音高、相对音高和音高变化上分析神经元的响应。TRF通过卷积操作模拟神经元对时间刺激的敏感性,其权重表示神经元对特定时间特征的响应选择性。文章还解释了如何通过数学模型如岭回归计算TRF的权重,以及在实验中的应用方法。
temporal receptive field(TRF)
学习资源
相关课程——Receptive Fields - Intro to Neural Computation(YouTube)
对应的 PPT——Receptive fields
使用 TRF 相关分析方法的文献——Human cortical encoding of pitch in tonal and non-tonal languages
专业术语
temporal receptive field 时间感受野
regression weight 回归权重
absolute pitch 绝对音高
relative pitch 相对音高
pitch change 音高变化
spatial receptive fields 空间感受野
convolution 卷积
spike 尖峰
spiking rate 尖峰频率(放电率)
问题
在阅读这篇文献的时候,有下面这张图,图的对应描述是The temporal receptive field (regression weights) from the model with regard to absolute pitch, relative pitch height and pitch change, indicating selectivity to positive pitch change. 在这里,时间感受野也被称作回归权重。
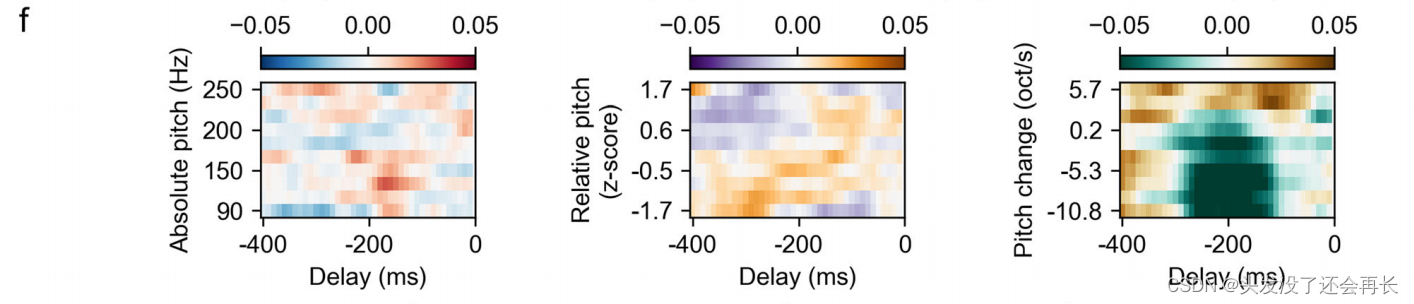
我的疑问是,什么是回归权重?什么是时间感受野?为什么这两个叫法可以指代同一个东西?如何得到每一个 delay 对应的 absolute pitch、relative pitch、pitch change 的回归权重的?
带着这些问题开始学习:)
什么是时间感受野(temporal relative change)?
总结来说,时间感受野其实就是一个 filter!
课程中的描述—A convolution of a temporal receptive field with the stimulus.(使用时间感受野与刺激进行卷积来描述)
时间感受野一般是听觉计算中使用的,在视觉中,有另一种分析叫做空间感受野(spatial receptive fields)。
spatial receptive fields
我们可以将 receptive field(RF)看做可以导致神经元激活(spike)的视觉空间(visual space)。但是一个在哦这个 RF 内的视神经并不会对所有的刺激(stimulus)都产生反应,而是选择性的对刺激中的特定特征产生反应。
我们可以认为一个神经元有一个 filter(G),这个 filter 可以pass时间和空间上的特定特征。神经元的激活水平可以通过计算加权输入与过滤器的重叠(overlap)程度来确定。如果输入与过滤器的特征高度匹配(越重叠),即输入中存在与过滤器期望的特征非常相似的模式,那么加权输入与过滤器的重叠将更高。这种高度匹配的情况会导致神经元更容易产生动作电位,从而更容易被激活。
使用数学描述感受野
实验中让老鼠感受光刺激,将光的位置(x,y)表示,这个就是stimulus的强度用 I(x,y) 表示,然后将刺激放入过滤器filter中,这个 filter 模拟的就是神经元,这个过滤器G有一个输出 L,即神经响应,L=G[I(x,y)],然后将我们有了一个非线性,将 L 添加到某个自发发射率(firing rate)
r
0
r_0
r0,然后取该总和的正部分,并将其称为发射率(firing rate)$r=[r_0+L]_+$。决定神经元是否会尖峰的是什么?那么实际上在大多数模型中,都有一个概率尖峰发生器(spike generator),这基本上是一个随机过程。
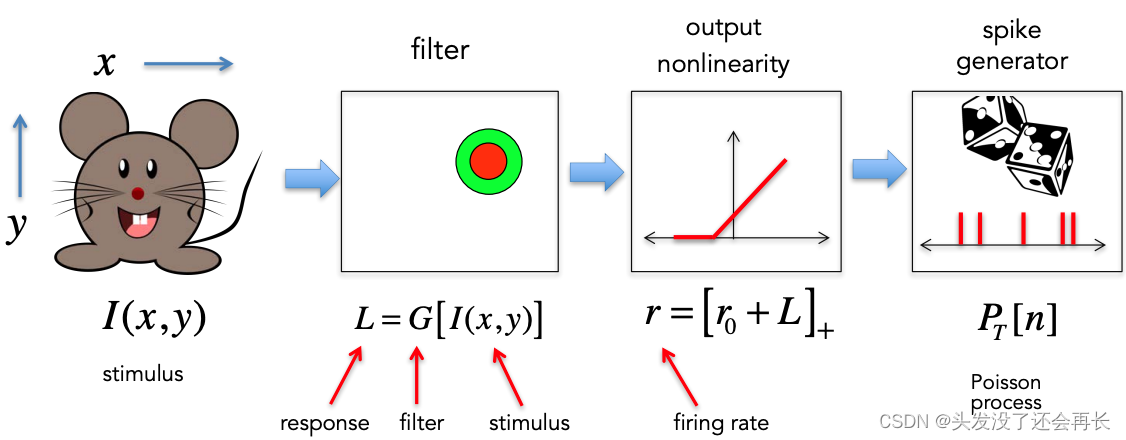
如何用数学表述 RF,正如前面所说 “神经元的激活水平可以通过计算加权输入I与过滤器G的重叠(overlap)程度来确定”。
如下图所示,神经元的响应由作用于刺激的线性滤波器G(x,y)决定。 然后只需计算 I 和 G 的积分,再加上自发发射率变得到了神经元的发射率 r。
在一维上,只考虑 x,可以的看到正向的和负向的 G,表示激活和抑制。
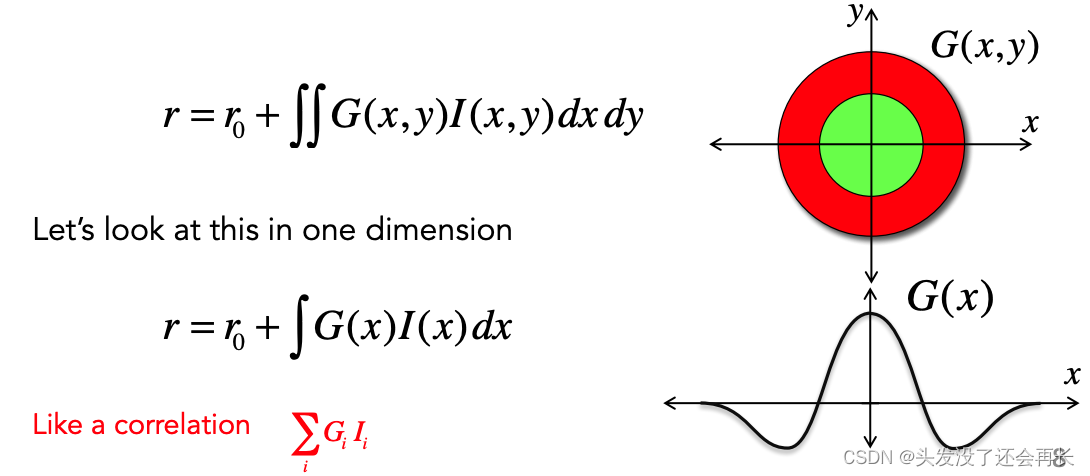 下面两个例子,给出不同的 G(x) 和 I(x),对于左侧的例子,正的 G(x) 和正的 I(x) 相乘为正,得到中间对称的绿色,表示激活,而负的 G(x) 和负的 I(x) 相乘为正,得到两边对称的绿色,这样的表示重叠度高,我们可以得到较大的响应。右侧图类似,得到较小的响应。
下面两个例子,给出不同的 G(x) 和 I(x),对于左侧的例子,正的 G(x) 和正的 I(x) 相乘为正,得到中间对称的绿色,表示激活,而负的 G(x) 和负的 I(x) 相乘为正,得到两边对称的绿色,这样的表示重叠度高,我们可以得到较大的响应。右侧图类似,得到较小的响应。
Temporal receptive fields
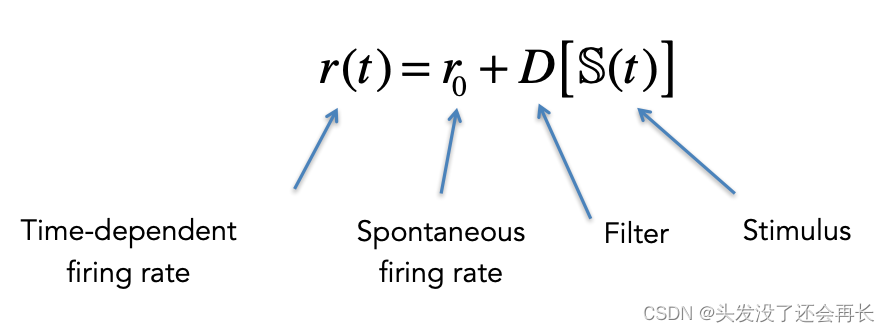
时间感受野的滤波器不再是对位置刺激进行操作,而是对时间的刺激。将时间刺激 S(t) 输入到滤波器 D,得到 D(S(t)) ,再加上自发发射率$r_0$,得到神经元基于时间的发射率r。
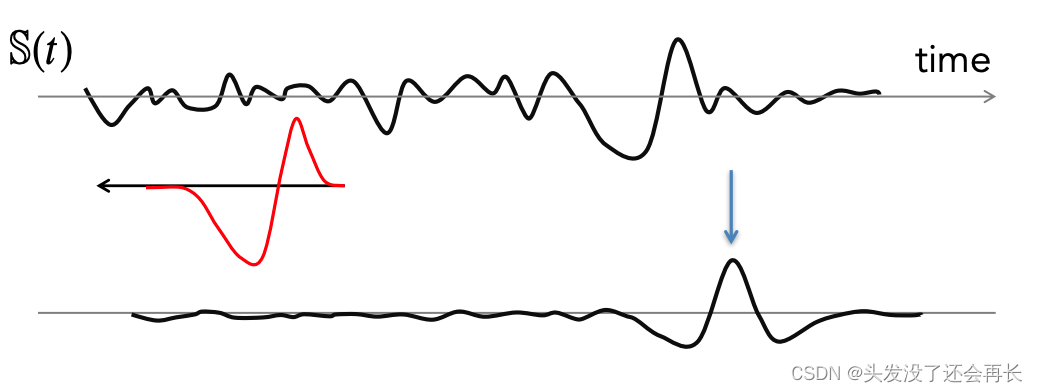
下面是一个时间感受野的例子,时间刺激的波形如下图所示,我们可以在时间域中考虑"overlap"的概念!这意味着刺激具有特定的"时间特征",可以使神经元发放动作电位。
下图红色的表示一个时间感受野,即滤波器 D,将这个滤波器不断向后移动并策略每次时间感受野与刺激的重叠,即 D(S(t))。这个时间感受野是假设先有一个负面的部分,然后一个正的部分,当 S(t) 中有相同的部分时,重叠度最高,随着时间推移整合,就会有一个最大的响应,这个响应就是下图蓝色剪头指示的 spike。
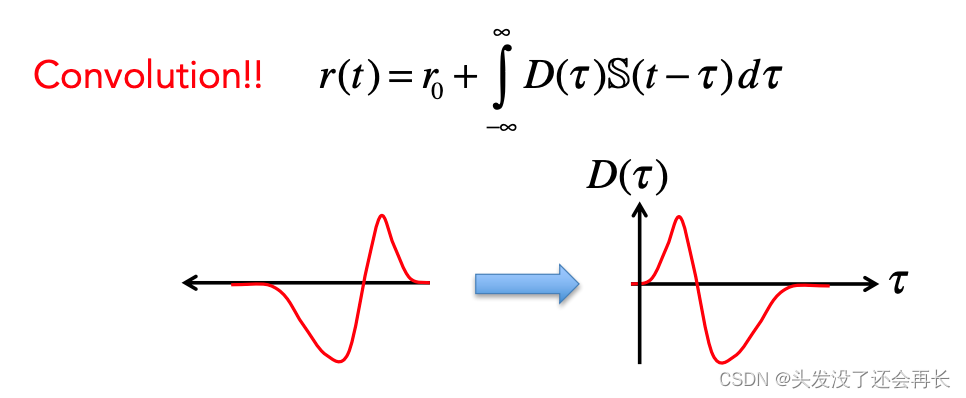
上面这个滑动红色的滤波器 D 和 S(t) 进行计算,就是一个卷积(convolution)操作!!
t 是 D 滑动的位置,tau 是将他们相乘的积分变量,t-tau 决定了这个内核的时间长度。(不在 D 范围内的时间上的 S(t) 都取 0)。
以上就是关于时空感受野的介绍,这里是用数学方法去描述神经元中的感受野 ,因为在神经元中,确实存在这样的机制,而数学中的滤波器就是神经元对刺激的一种滤波,不同的神经元对不同的刺激有不同的 response,有一些刺激会产生 spike,但有些不会。通过计算感受野,我们可以研究一些特定刺激产生的响应,并通过计算得到,哪些神经元对这些刺激激活程度更高,那这些神经元很可能就和编码这些刺激相关。
什么是回归权重?
回归权重(Regression weights)是指在回归分析中用于估计自变量与因变量之间关系的权重或系数。回归分析是一种统计方法,用于建立自变量与因变量之间的关联模型,并通过拟合数据来估计模型中的参数。
在简单线性回归中,只有一个自变量与一个因变量之间的关系被建模。回归权重表示自变量对因变量的影响程度,它们表明当自变量的值增加或减少时,因变量的预期变化量。
在多元线性回归中,多个自变量与一个因变量之间的关系被建模。每个自变量都有一个对应的回归权重,用于衡量该自变量对因变量的独立影响。这些回归权重可以解释自变量之间的相关性以及它们对因变量的相对重要性。
为什么回归权重可以指代时间感受野?
在某些上下文中,回归权重也被称为"时间感受野"(temporal receptive field)。这个术语源自神经科学领域,用于描述神经元对于时间上的特定范围内的输入的敏感程度。
在回归模型中,特别是在时序数据分析中,回归权重可以被理解为模型对于不同时间点上输入特征的重要性或贡献程度。每个时间点上的回归权重决定了模型对于该时间点附近的输入的敏感度。
前面说的时间感受野,计算的重叠度和这里的回归权重是一个意思,重叠度越大,说明这个神经元对于该刺激的响应越大,即该刺激是产生该响应的关键因素!(最开始给出的回归权重图便可以这样解释,图 a 表示的是绝对音高的回归权重,每一个时间点起始就是绝对音高对于正向音高的响应程度,也即重要程度)
所以,如果回归模型用 y=ax+b 来表示,回归模型中的 x 就是刺激 S,a 即权重系数,也是感受野 D,当 a 和 x 的乘积,就表示刺激S和感受野D的乘积积分,当 a 越大的时候,表示该自变量 x 对于 y 的影响越大,在 TRF 中,高权重表示神经元对于特定时间点或时间段的输入更加敏感或具有更强的选择性。
因此,将回归权重称为"时间感受野"是一种类比,将回归模型中权重的作用与神经元在神经科学中的感受野的概念进行类比。它强调了回归模型在时间维度上对输入的敏感程度和影响范围。
时间感受野其实也是一个模型,这个模型使用的是岭回归,训练得到一组最优权重,用来预测给定特征的神经活动。
如何计算得到问题中的矩阵的?
矩阵中每一个点表示一个权重值,颜色深浅表示对正向音高的选择性权重大小,颜色深的区域表示模型对于正向音高变化具有较高的选择性或敏感度,而颜色浅的区域表示模型对于音高变化的影响较小。
拿图 b 相对音高举例,计算回归权重的步骤如下:
(1)定义输入特征:确定用于回归模型的输入特征。在本实验中,输入特征是 Hg 活动所有相对音高特征。
(2)准备训练数据:收集包含输入特征和目标变量(例如正向音高变化)的训练数据集,然后将音高划分为训练集,验证集,测试集,本实验采用的是 5 折交叉验证。
(3)训练模型:先用训练数据训练,对每一个 alpha,分别使用岭回归计算训练数据的相关系数和回归权重,找到相关系数最大的 alpha,并得到最好的回归权重,然后使用这个回归权重对测试集做预测,得到测试集的相关系数和回归权重。
(4)获取权重值:在训练完成后,求 5 折的平均值,便得到了回归权重和相关系数。
在训练过程中,相关系数最大的 alpha 对应的回归权重也是最优的。因为相关系数是预测和实际响应之间的相关性。
这里输入的时间和相对音高便是自变量(x),而正音高变化就是因变量(y),可以描述为模型 y=ax+b, 回归权重便是回归模型得到的 a。
图 a 和图 c 类似,自变量(x)变成了绝对音高和音高变化,即模型输入改变。

















 2342
2342

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









