






我们写论文或者作报告可能需要作自己设计的网络的架构,目前这个代码是比较热门的PlotNeuralNet,可以根据readme进行实践。
💡如果想快速完成自己的一个小实例,并且不遇到什么环境问题,可以按照我下面的步骤实践:
# 我在学校的超算平台进行的下面实践
# 拉取代码
git clone https://github.com/HarisIqbal88/PlotNeuralNet
# 我通常习惯拿到一个新的任务先创建虚拟环境
conda create create --name plotnet python=3.9
# 激活虚拟环境
conda activate plotnet
# 根据ubuntu版本,安装Tex相关软件包:
sudo apt-get update
sudo apt-get install texlive-latex-base
sudo apt-get install texlive-fonts-recommended
sudo apt-get install texlive-fonts-extra
sudo apt-get install texlive-latex-extra
# 进入目标文件夹
cd pyexamples
# 运行代码自带的一个小的画图实例
bash ../tikzmake.sh test_simple
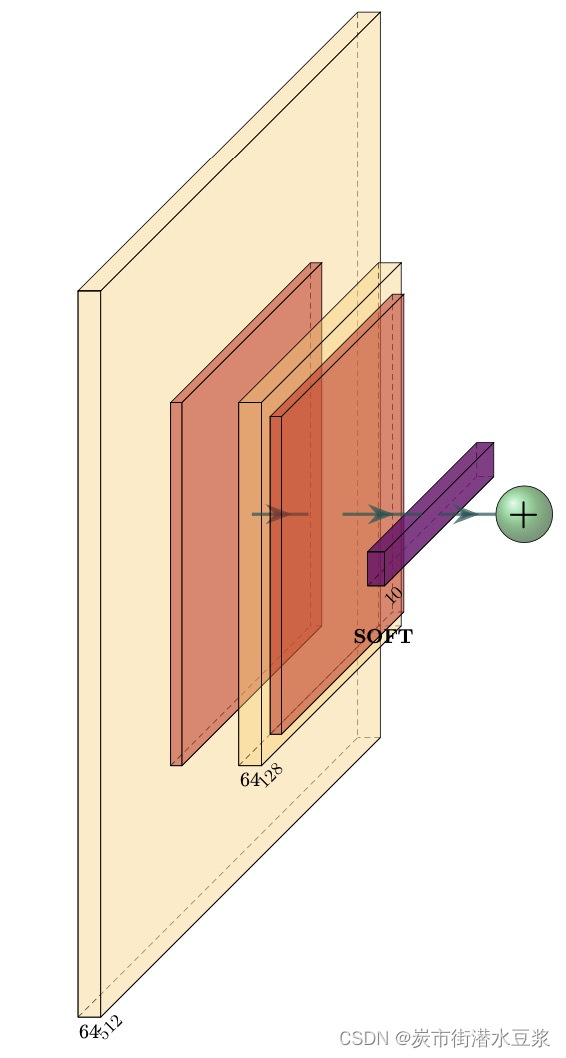
执行完之后,你会在当前文件夹下看到生了一个test_simple.pdf,这个pdf里就是我们画出来的图像,如下图所示:
实例2:画示例unet神经网络,结果如下:
cd pyexamples/
bash ../tikzmake.sh unet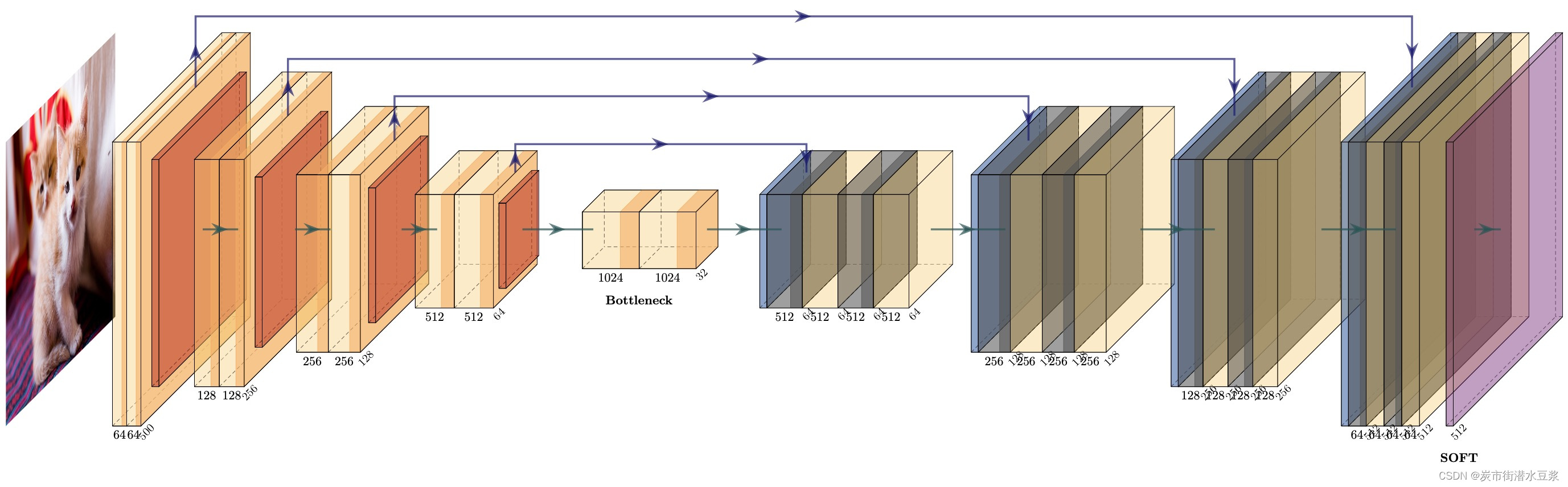
若想自己写一段构建网络的代码,只需要创建一个xxx.py然后仿照test_simple里的格式写即可,我可能会在下篇帖子给出我的网络构建代码,但是会删减和给出部分(为保证科研成果发表前的保密性)

















 6625
6625











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











