







 本文详细介绍了QAT量化的基本流程,包括定义量化模型、准备数据、训练、重新量化和微调,以及提供了一个使用PyTorch实现的QAT量化代码示例。
本文详细介绍了QAT量化的基本流程,包括定义量化模型、准备数据、训练、重新量化和微调,以及提供了一个使用PyTorch实现的QAT量化代码示例。
一、QAT量化基本流程
QAT过程可以分解为以下步骤:
- 定义模型:定义一个浮点模型,就像常规模型一样。
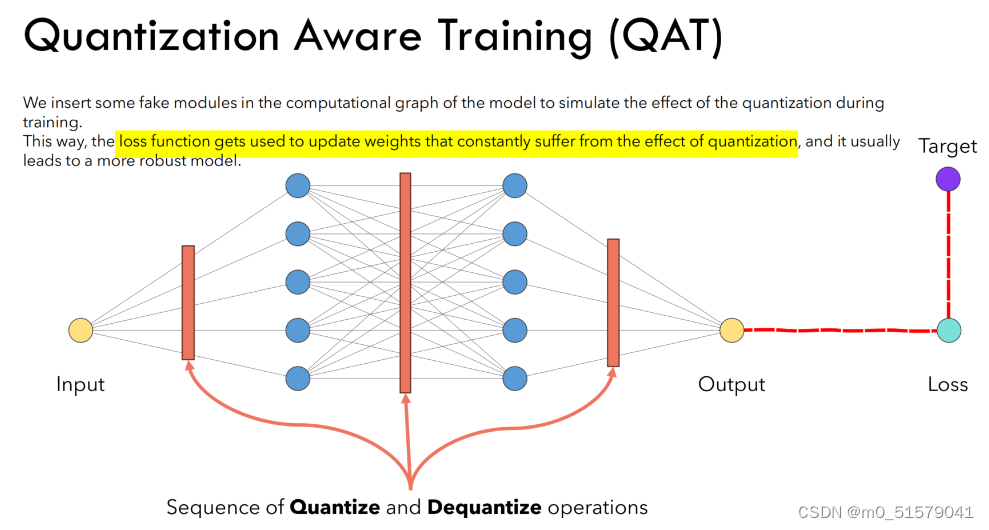
- 定义量化模型:定义一个与原始模型结构相同但增加了量化操作(如torch.quantization.QuantStub())和反量化操作(如torch.quantization.DeQuantStub())的量化模型。
- 准备数据:准备训练数据并将其量化为适当的位宽。
- 训练模型:在训练过程中,使用量化模型进行正向和反向传递,并在每个 epoch 或 batch 结束时使用反量化操作计算精度损失。
- 重新量化:在训练过程中,使用反量化操作重新量化模型参数,并使用新的量化参数继续训练。
- Fine-tuning:训练结束后,使用fine-tuning技术进一步提高模型的准确率。
二、QAT量化代码示例
import torch
import torch.nn as nn
import torch.optim as optim
import torchvision.datasets as datasets
import torchvision.transforms as transforms
from torch.quantization import QuantStub, DeQuantStub, quantize_dynamic, prepare_qat, convert
# 模型
class MyModel(nn.Module):
def __init__(self):
super(MyModel, self).__init__()
# 量化
self.quant = QuantStub()
self.conv1 = nn.Conv2d(3, 64, kernel_size=3, stride=1, padding=1)
self.relu = nn.ReLU(inplace=True)
self.conv2 = nn.Conv2d(64, 128, kernel_size=3, stride=1, padding=1)
self.avgpool = nn.AdaptiveAvgPool2d((1, 1))
self.fc = nn.Linear(128, 10)
# 反量化
self.dequant = DeQuantStub()
def forward(self, x):
# 量化
x = self.quant(x)
x = self.conv1(x)
x = self.relu(x)
x = self.conv2(x)
x = self.relu(x)
x = self.avgpool(x)
x = x.view(x.size(0), -1)
x = self.fc(x)
# 反量化
x = self.dequant(x)
return x
# 数据
transform = transforms.Compose([transforms.Resize(256),transforms.CenterCrop(224),transforms.ToTensor(),transforms.Normalize(mean=[0.485, 0.456, 0.406],std=[0.229, 0.224, 0.225])])
train_data = datasets.CIFAR10(root='./data', train=True, download=True,transform=transform)
train_loader = torch.utils.data.DataLoader(train_data, batch_size=1,shuffle=True, num_workers=0)
# 模型 优化器
model = MyModel()
optimizer = optim.SGD(model.parameters(), lr=0.001, momentum=0.9)
# Prepare the model
model.qconfig = torch.quantization.get_default_qat_qconfig('fbgemm')
model = prepare_qat(model)
# 训练
model.train()
for epoch in range(1):
for i, (data, target) in enumerate(train_loader):
optimizer.zero_grad()
output = model(data)
loss = nn.CrossEntropyLoss()(output, target)
loss.backward()
optimizer.step()
if i % 100 == 0:
print('Epoch: [%d/%d], Step: [%d/%d], Loss: %.4f' %
(epoch+1, 10, i+1, len(train_loader), loss.item()))
# Re-quantize the model
model = quantize_dynamic(model, {'': torch.quantization.default_dynamic_qconfig}, dtype=torch.qint8)
# 微调
model.eval()
for data, target in train_loader:
model(data)
model = convert(model, inplace=True)

















 3987
3987











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











