






自我注意机制对远程依赖进行建模的能力推动了它在视觉模型中的应用。与卷积运算符不同,自我注意提供了无限的接受场,并能够对全局依赖进行高效的计算建模。然而,现有的注意力机制存在较高的计算和/或参数开销,因此不适合紧凑型卷积神经网络(CNN)。在这项工作中,我们提出了一种简单而有效的“超轻量级子空间注意机制”(ULSAM),它为每个特征图子空间推断出不同的注意图。我们认为,为每个特征子空间学习单独的注意图可以实现多尺度和多频率的特征表示,这对于细粒度的图像分类是更可取的。我们的子空间注意方法与现有视觉模型中使用的最先进的注意机制是正交的,并且是互补的。ULSAM是端到端可培训的,可以作为即插即用模块部署在现有的紧凑型CNN中。值得注意的是,我们的工作是首次使用子空间注意机制来提高紧凑CNN的效率。为了显示ULSAM的有效性,我们以MobileNet-V1和MobileNet-V2为骨干架构,在ImageNet-1K和三个细粒度图像分类数据集上进行了实验。在≈-1K和细粒度图像分类数据集上,我们分别使MobileNet-V2的Flop数和参数数减少了13%和≈25%,TOP-1准确率分别提高了0.27%和1%以上。
原理
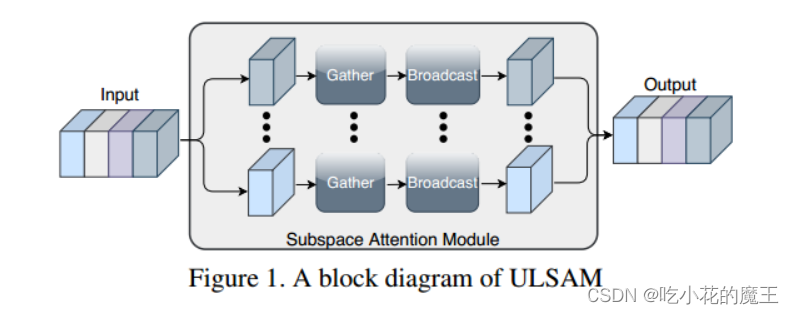
基本思想:假设给定input100channels,分为20组(20个子空间),对每个sunspace进行分别的相应操作,然后进行合并为新的形状
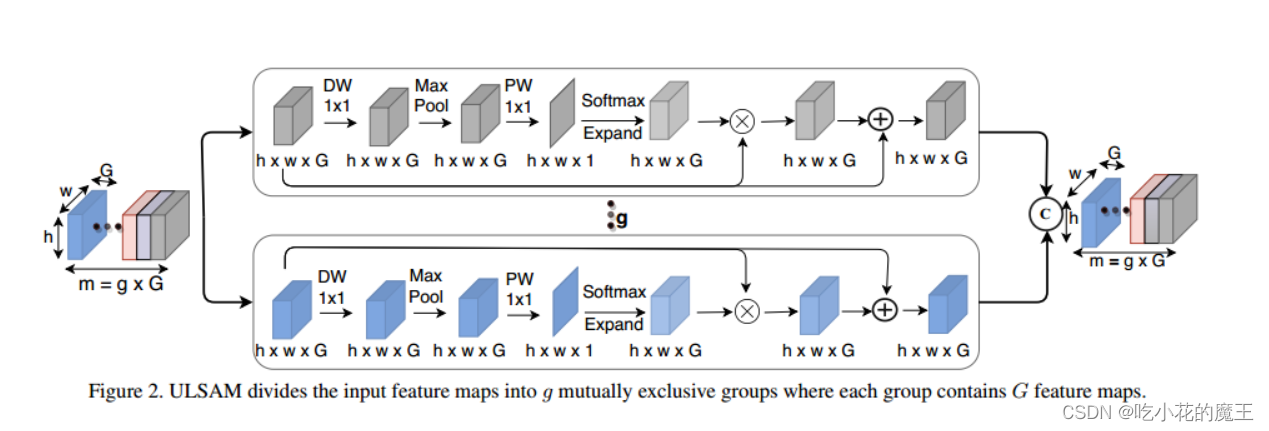
在这个主网络示意图中可见,输入和输出同形同通道,子空间用了深度可分离卷积,还有res结构(恒等映射)
深度可分离卷积,这是我写的机制讲解:depthwise separable conv讲解
机制对比一览

ULSAM模块代码
可以无缝集合到现有的架构中
import torch
import torch.nn as nn
class SubSpace(nn.Module):
def __init__(self, nin: int) :
super(SubSpace, self).__init__()
self.conv_dws = nn.Conv2d(
nin, nin, kernel_size=1, stride=1, padding=0, groups=nin
)
self.bn_dws = nn.BatchNorm2d(nin, momentum=0.9)
self.relu_dws = nn.ReLU(inplace=False)
self.maxpool = nn.MaxPool2d(kernel_size=3, stride=1, padding=1)
self.conv_point = nn.Conv2d(
nin, 1, kernel_size=1, stride=1, padding=0, groups=1
)
self.bn_point = nn.BatchNorm2d(1, momentum=0.9)
self.relu_point = nn.ReLU(inplace=False)
self.softmax = nn.Softmax(dim=2)
def forward(self, x) :
out = self.conv_dws(x)
out = self.bn_dws(out)
out = self.relu_dws(out)
out = self.maxpool(out)
out = self.conv_point(out)
out = self.bn_point(out)
out = self.relu_point(out)
m, n, p, q = out.shape
out = self.softmax(out.view(m, n, -1))
out = out.view(m, n, p, q)
out = out.expand(x.shape[0], x.shape[1], x.shape[2], x.shape[3])
out = torch.mul(out, x)
out = out + x
return out
class ULSAM(nn.Module):
"""
Grouped Attention Block having multiple (num_splits) Subspaces.
num_splits : int
number of subspaces
"""
def __init__(self, nin: int, nout: int, h: int, w: int, num_splits: int) :
super(ULSAM, self).__init__()
assert nin % num_splits == 0 #judege
self.nin = nin
self.nout = nout
self.h = h
self.w = w
self.num_splits = num_splits
self.subspaces = nn.ModuleList(
[SubSpace(int(self.nin / self.num_splits)) for i in range(self.num_splits)]
)
def forward(self, x) :
group_size = int(self.nin / self.num_splits)
# split at batch dimension
sub_feat = torch.chunk(x, self.num_splits, dim=1)
out = []
for idx, l in enumerate(self.subspaces):
out.append(self.subspaces[idx](sub_feat[idx]))
out = torch.cat(out, dim=1)
return out















 4100
4100











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









