










论文地址:https://arxiv.org/abs/2112.11790
项目地址:https://github.com/HuangJunJie2017/BEVDet
在anaconda中创建虚拟环境并启动
conda create bevdet_ckpt python=3.7 -y
进入虚拟环境
conda activate bevdet_ckpt
阅读论文,想要复现BEVDet的Tiny版本,在原作者的Github最新branch分支中,./configs/bevdet下已经没有tiny的py文件了。查看另外5个brach发现,在checkpoint和master分支下还保留了tiny文件。
通过git进行clone为dev3.0的最新分支,所以通过zip下载。
https://github.com/HuangJunJie2017/BEVDet/archive/refs/heads/checkpoint.zip
解压后进入bevdet-checkpoint文件夹。
安装相关依赖
conda install -c pytorch pytorch torchvision -y
# pip install torch==1.10.0+cu111 torchvision==0.11.0+cu111 torchaudio==0.10.0 -f https://download.pytorch.org/whl/torch_stable.html
pip install mmcv-full==1.3.13
pip install mmdet==2.14.0
pip install mmsegmentation==0.14.1
pip install -v -e .
进入nuscenes官网注册账号登陆后https://www.nuscenes.org/nuscenes#download下载mini数据集

将mini dataset下载后的v1.0-mini.tgz解压出来可得到名为v1.0-mini的文件夹,改名为nuscenes,并移动到项目根目录下的./data文件夹中;
Map expansion下载解压后将文件移动到nuscenes解压出来的Map文件夹中,作为地图扩展;
对nuscenes中的v1.0-mini复制一份并改名为v1.0-trainval

预处理nuscenes数据集
python tools/create_data.py nuscenes --version v1.0-mini --root-path ./data/nuscenes --out-dir ./data/nuscenes --extra-tag nuscenes
如果数据集不在data文件夹下,需要替换–root-path为相应文件路径,并且在后续训练测试时需要修改config文件。
直接开始训练
# single-gpu
python tools/train.py ${CONFIG_FILE} [optional arguments]
# multi-gpu
./tools/dist_train.sh ${CONFIG_FILE} ${GPU_NUM} [optional arguments]
单gpu和多gpu分别使用上面的命令;本次复现通过单gpu进行测试:
python tools/train.py ./configs/bevdet/bevdet-sttiny.py
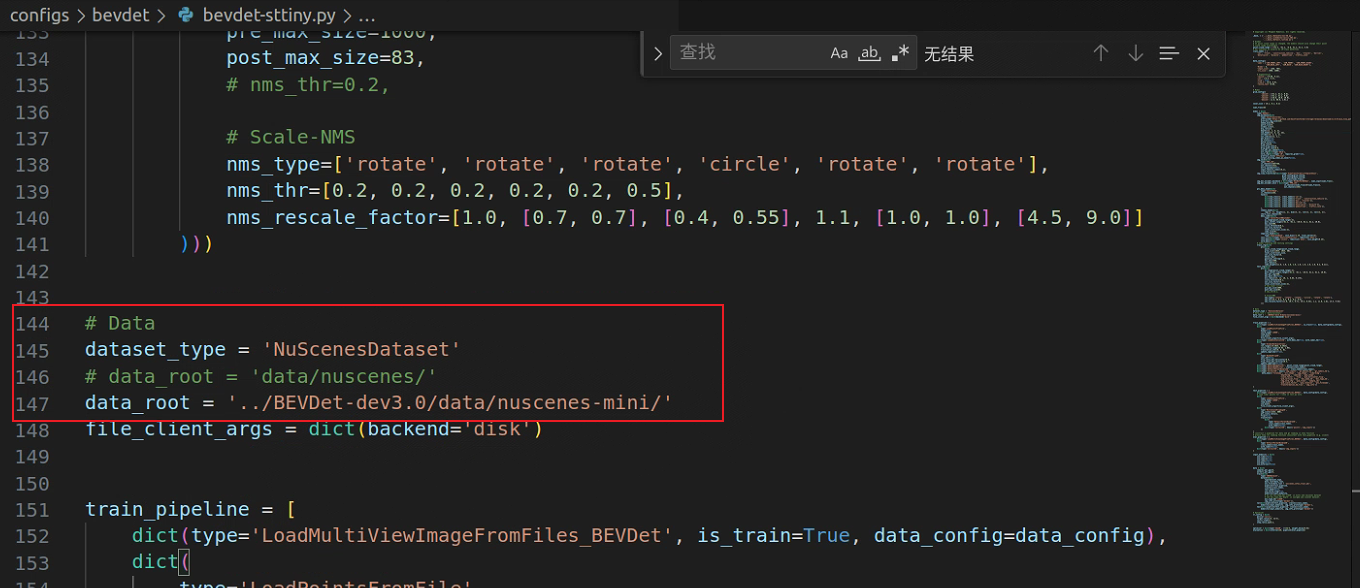
如果数据集并不在./data/nuscenes中,需要修改bevdet-sttiny.py中的相关代码为数据集路径:
运行后出现报错,查找相关解决方案:
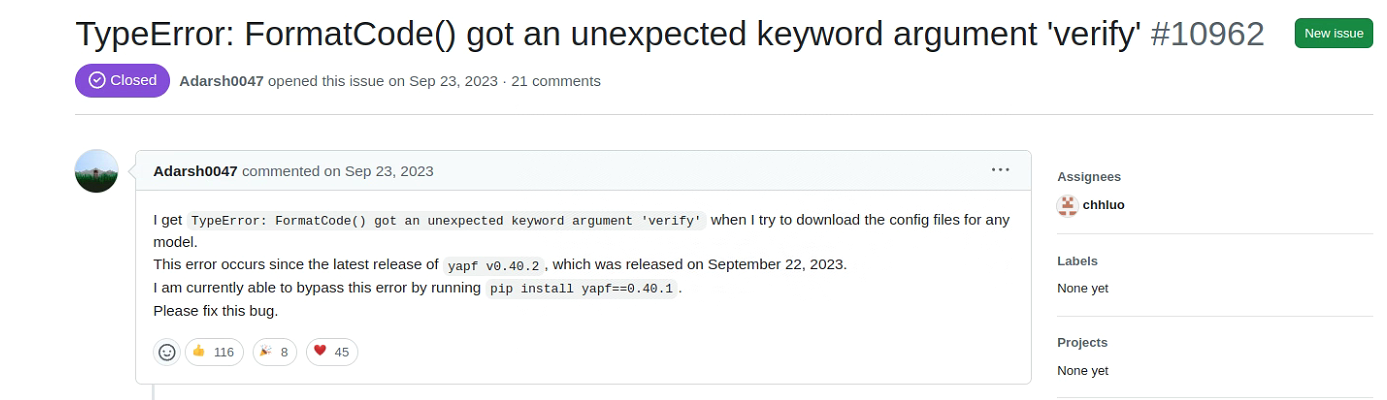
通过运行pip install yapf==0.40.1解决,并重新进行训练,继续出现报错,查找相关解决方案:
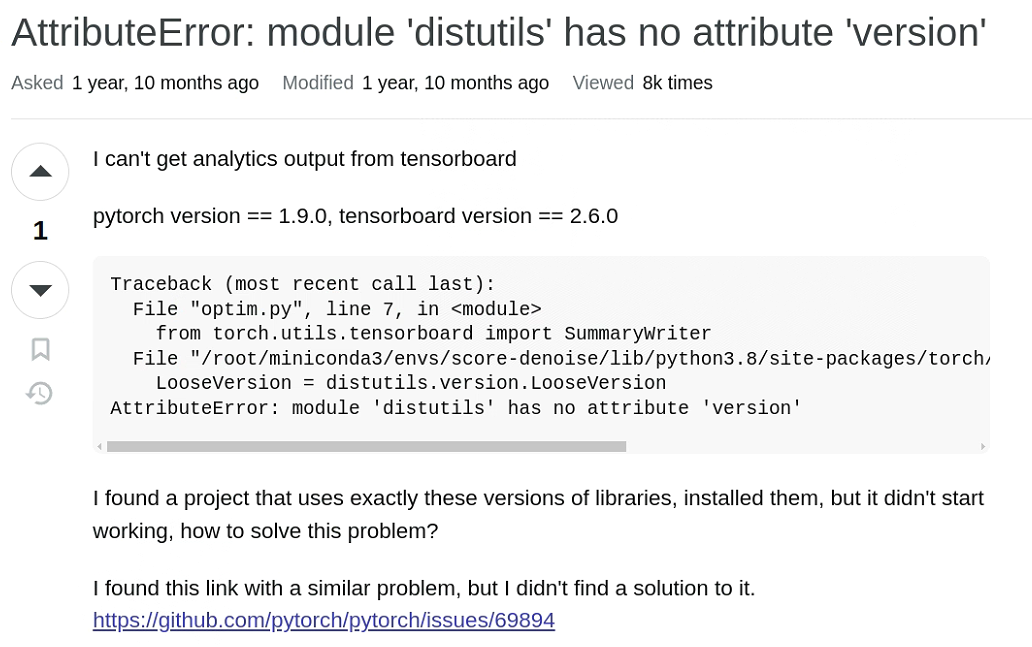
通过运行pip install setuptools==59.5.0解决,并重新进行训练。
测试如下:
# single-gpu testing
python tools/test.py ${CONFIG_FILE} ${CHECKPOINT_FILE} [--out ${RESULT_FILE}] [--eval ${EVAL_METRICS}] [--show] [--show-dir ${SHOW_DIR}]
# multi-gpu testing
./tools/dist_test.sh ${CONFIG_FILE} ${CHECKPOINT_FILE} ${GPU_NUM} [--out ${RESULT_FILE}] [--eval ${EVAL_METRICS}]
使用单gpu进行测试:
python tools/test.py ./configs/bevdet/bevdet-sttiny.py ./work_dirs/bevdet-sttiny/latest.pth --eval mAP
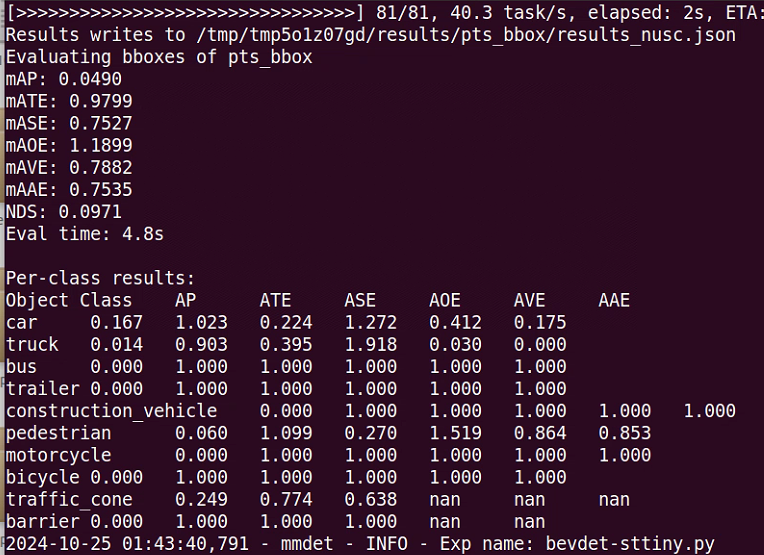
测试结果
可视化:
因为checkpoint分支下的./tools/analysis_tools中没有vis.py文件,所以从别的分支中下载vis.py文件并移动至./tools/analysis_tools中。
https://github.com/HuangJunJie2017/BEVDet/raw/refs/heads/master/tools/analysis_tools/vis.py
可视化前需要得到json文件,所以重新运行:
python ./tools/test.py ./configs/bevdet/bevdet-sttiny.py work_dirs/bevdet-sttiny/latest.pth --format-only --eval-options jsonfile_prefix=$savepath
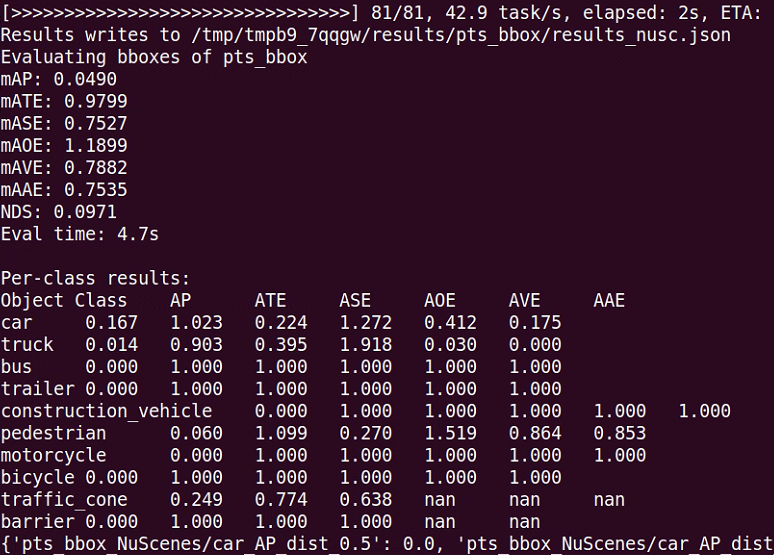
在./pts_bbox中得到results_nusc.json
运行
python tools/analysis_tools/vis.py ./pts_bbox/results_nusc.json
在根目录下出现vis文件夹,里面为mp4视频文件


















 1106
1106

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









