










原文链接:https://arxiv.org/pdf/2112.11790.pdf
1 引言
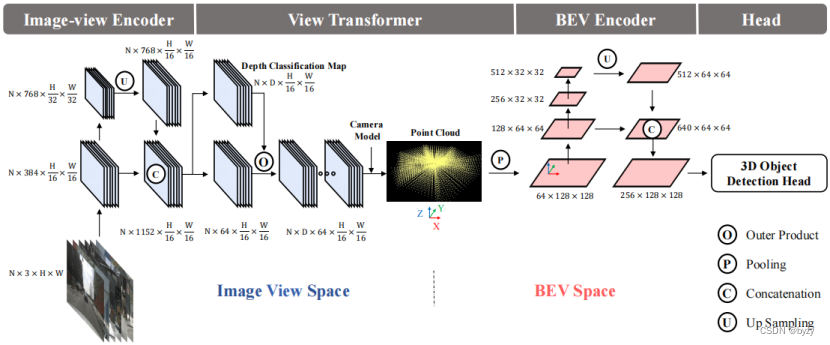
如下图所示,本文提出的BEVDet包含4个部分,即图像编码器(提取图像特征)、视图转换器(将图像视图转化为BEV)、BEV编码器(进一步提取BEV特征)和检测头(BEV下检测3D物体)。
由于BEVDet在BEV空间的过度拟合能力,以及使用多视图数据导致的数据不足,训练时出现了过拟合。仅对图像进行数据增广时,仅在移除BEV编码器后能带来性能提升,这是因为视图转换器以像素对像素的方式将图像与BEV连接,而导致了数据增广的解耦。故文章在图像和视图转化器输出的BEV特征图上均进行数据增广操作。
此外,本文改进了非最大抑制(NMS)策略,并通过移除顺序操作加快推断过程。由此,BEVDet实现了精度和速度的平衡。
3 方法
3.1 网络结构
图像编码器:为了利用多分辨率特征,图像编码器包含高级特征提取主干和多分辨率特征融合的颈部。
视图转换器:类似Lift-Splat-Shoot的方法,即先从图像以分类的方式预测密集的深度,从而得到点云,然后通过轴方向上的池化操作生成BEV特征。
BEV编码器:结构与图像编码器类似,包含主干和颈部。但其需要感知高精度的线索如尺寸、朝向和速度。
检测头:直接使用CenterPoint的检测头,而不使用第二阶段的细化。
3.2 数据增广策略
独立视图空间:设图像像素坐标对应深度
,相机内参为
,则相应的3D坐标为
常规数据增广操作如翻转、裁剪、旋转可表达为的变换矩阵
,即
。注意在视图转换时,为保证空间一致性,需要进行逆变换,即
。因此对图像进行数据增广操作,不会对BEV特征的空间分布产生影响。
BEV空间数据增广:由于多视图图像在BEV进行了特征融合,BEV编码器的学习数据比图像编码器的学习数据少。翻转、缩放和旋转被应用于BEV特征图的数据增广(同时对视图转换器的输出以及检测目标进行操作以保证空间一致性)。注意该增广方法需要视图转换解耦的条件,因此其余方法可能不适用。
3.3 尺度NMS
在图像平面进行2D检测时,物体的边界框可能有较大交叉;但在BEV平面上,实例边界框之间的重叠应该接近0。且小型物体的边界框尺寸可能小于BEV分辨率,常规方法会产生不相交的冗余检测,如下图所示。
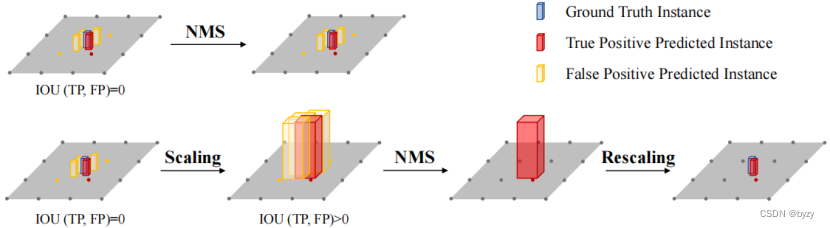
为解决上述问题,本文提出尺度NMS方法,首先根据预测类别放缩物体,再进行NMS操作。合适的放缩率通过验证集上的超参数搜索选取。
4 实验
4.1 实验设置
本文使用nuScenes数据集及其标准评价指标。
本文通过将视图转换器的累加和操作替换为其等价实现,从而加速推断(见4.3节最后)。
4.2 实验结果
本文方法若使用低分辨率图像输入,可以达到其余方法(使用高分辨率图像)相近的性能,但速度快上许多;若使用相同的高分辨率图像输入,可以以相近的速度达到好很多的性能。
在nuScenes验证集上,BEVDet在位置、尺寸、朝向和速度的估计上准确率高,但在属性的估计上相比于基于图像的3D检测准确率较低。这可能是由于属性判断依赖于外观线索,更容易在图像中感知。结合两种视图可能是一个有前途的方法。
在nuScenes测试集上,BEVDet能达到使用激光雷达预训练视觉检测模型的相当性能,且与基于激光雷达的经典3D检测方法PointPillars性能相当。
4.3 消融研究
数据增广:仅使用BEV编码器而不适用任何数据增广的方法(A)性能最差,且很早就开始过拟合。如果仅加上图像数据增广(B),能延缓过拟合出现时间,但未过拟合时的最优性能甚至不如A方法。若仅加上BEV数据增广(C),能更有效地减轻过拟合,且最优性能超过A方法。这说明BEV数据增广比图像数据增广更加有效。同时使用两种数据增广(D)的过拟合时间和性能均最大,且过拟合现象很弱。
若上面四种方法(A~D)均移除BEV编码器(对应方法E~H):D和H比较可得BEV编码器能提高性能;比较E和F可知,图像数据增广仅在无BEV编码器时有正面效果。这表明BEV编码器有强感知能力,仅在BEV数据增广下才能避免过拟合。
尺度NMS:与普通的NMS以及CenterPoint中提出的环形NMS比较,尺度NMS在小物体的检测精度上有很大提升,其余物体也有一定提升。
分辨率:增大输入图像和BEV特征图的分辨率均能带来性能提升,但会带来额外的推断时间。
加速:该加速是基于Lift-Splat-Shoot用图像产生的点云形状是固定的,因此每个点可以预先分配一个体素索引,用于指示其属于哪一个体素。
本文的改进如下图所示,除了点的体素索引,还建立辅助索引,用于统计每个体素索引的出现次数。然后将点分配到2D矩阵上,沿辅助轴求和。

如果推断时相机的内外参不变,每个点的体素索引和辅助索引均是固定的,在初始化阶段即可预先计算;但此方法会带来额外空间需求,且该空间与体素数量和最大辅助索引值有关。本文设定一个辅助索引最大值,辅助索引值超过
的点被丢弃,而几乎不会对性能产生影响。


















 2475
2475

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











