







卷积神经网络
1. 卷积神经网络
神经元存在局部感受区域----感受野
.
第一个卷积神经网络雏形----新认知机缺点:没有反向传播算法更新权值,模型性能有限
第一个大规模商用卷积神经网络----Lenet-5
缺点:没有大量数据和高性能计算资源。
第一个全面的卷积神经网络----AlexNet
2. 卷积操作
图像识别的特点
1.特征具有局部性
2.特征可能出现在任何位置
3. 下采样图像不会改变图像目标填充(Padding)
在输入图像的周围添加额外的行/列
作用:
1.使卷积后的图像分辨率不变
2.弥补边界信息的丢失步幅(stride)
卷积核滑动的行数和列数,控制输出特征图的大小,被缩小1/s倍。
公式:
F o = ∣ F i n − k + 2 p s ∣ + 1 \color{red}F_o =| \frac{F_{in}-k+2p}{s}|+1 Fo=∣sFin−k+2p∣+1
参数:F i n : \color{green}F_{in}: Fin:输入特征图的大小
k : \color{green}k: k:Kernel的大小(一般长和宽是保持一致的)
p : \color{green}p: p:填充值大小
s : \color{green}s: s:步幅值大小
F o : \color{green}F_o: Fo:输出特征图的大小多通道卷积:
3. 池化操作
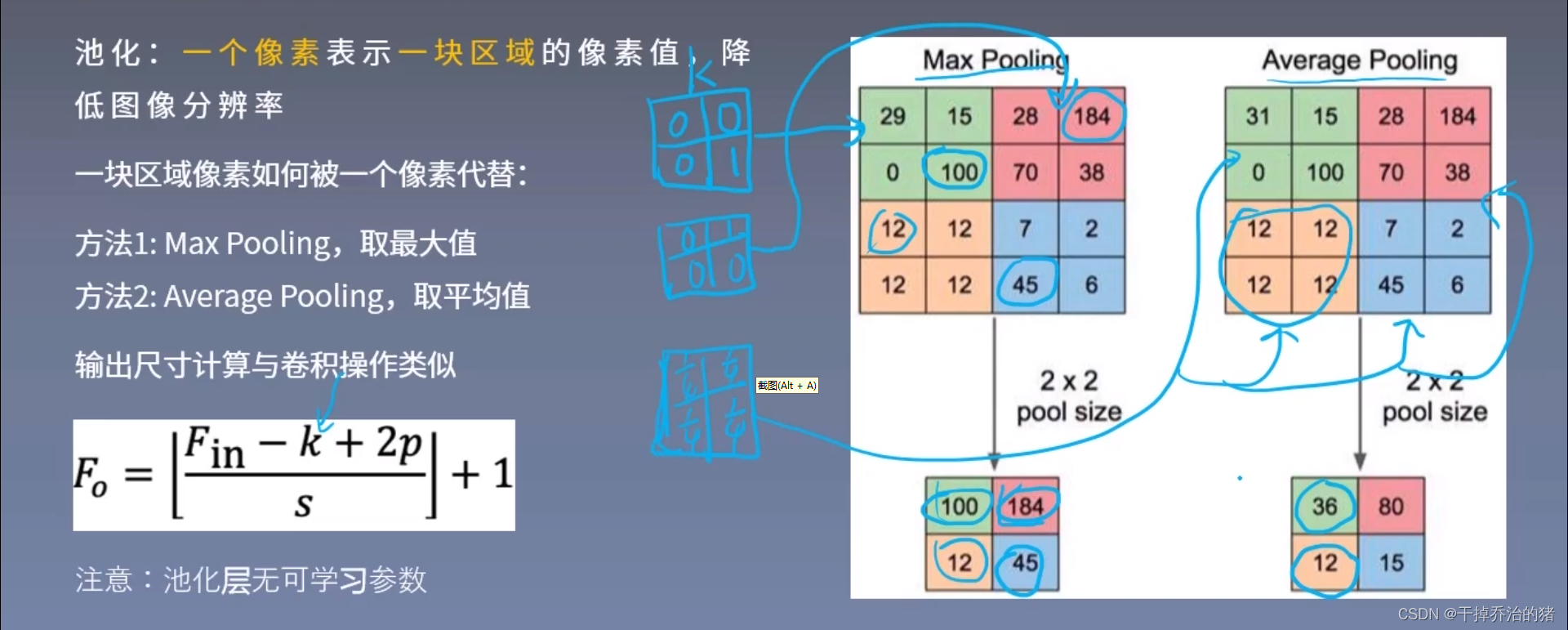
池化:
一个像素表示一块区域的像素值,降低图像的分辨率
池化方法:
1.Max poolling(1取最大值)
2.Average Pooling(取平均值)目前很多网络模型不需要使用池化操作,直接使Stride步长等于2就可以代替池化操作。
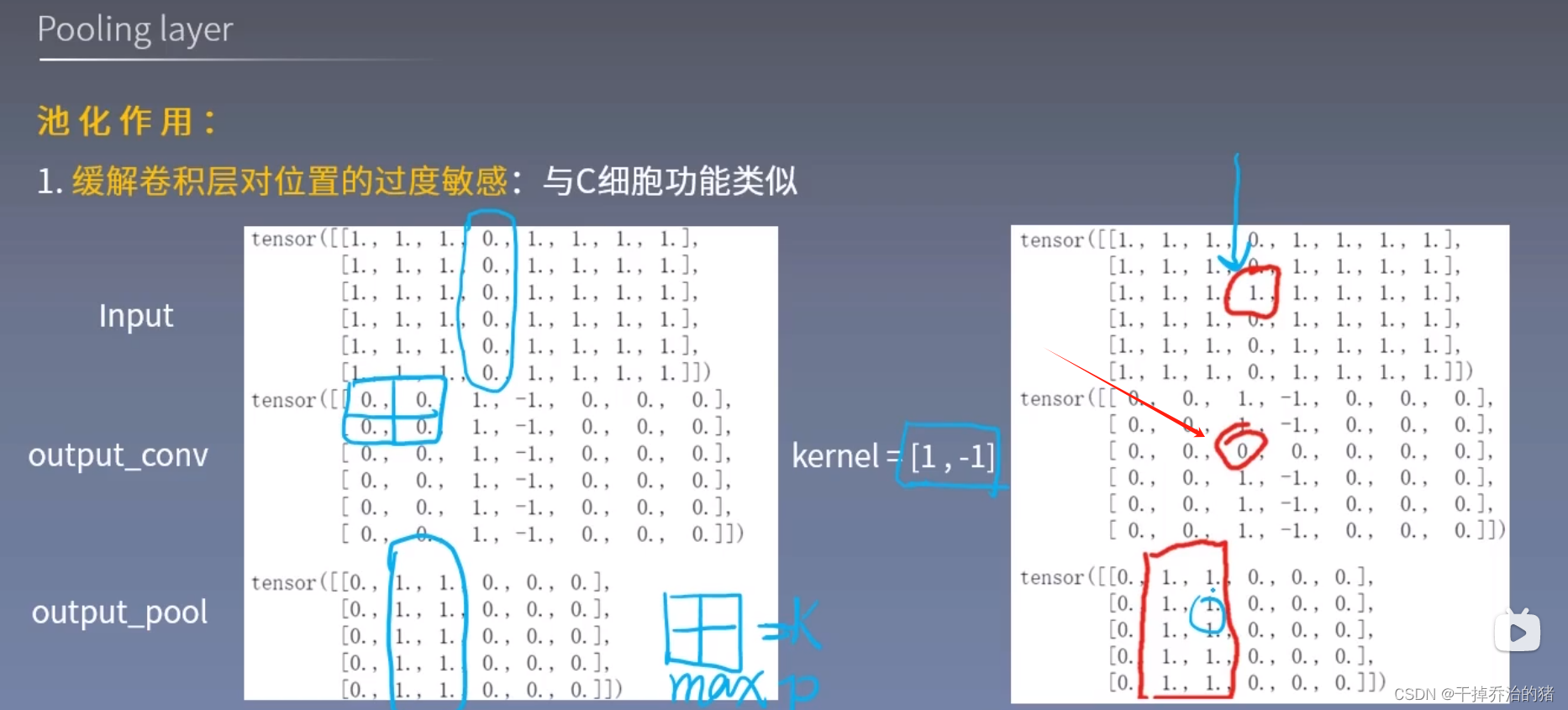
池化的作用:
1.缓解卷积层对位置的过度敏感
2.减少冗余
3.降低图像的分辨率,从而减少参数数量

循环神经网络
1.序列数据
前后的数据具有关联性
2.语言模型
1.文本在NLP中通常被看作是离散时间序列,长度为T的文本的词分别为:w1、w2… w T w_T wT,其中 w t ( 1 < = t < = T ) w_t(1<=t<=T) wt(1<=t<=T)是时间步t的输出或标签
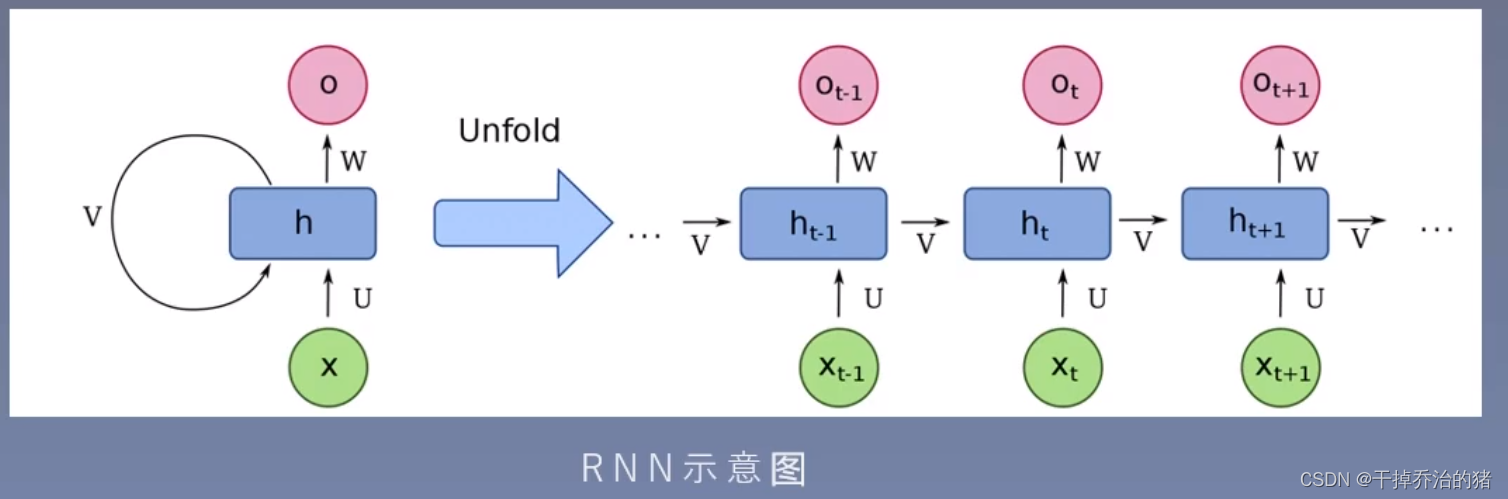
2.语言模型用于计算序列概率P(w1、w2、w3…wT)3.RNN-循环神经网络
优点:
1.循环使用网络层参数,避免时间步增大带来的参数激增
2.引入隐藏状态,记录历史信息,有效地处理数据前后的关联性
激活函数使用Tanh,将输出值域限制在(-1,1),防止数值呈指数性变化
RNN特性:
1.隐藏状态可以保存截止当前时间步的序列的历史信息
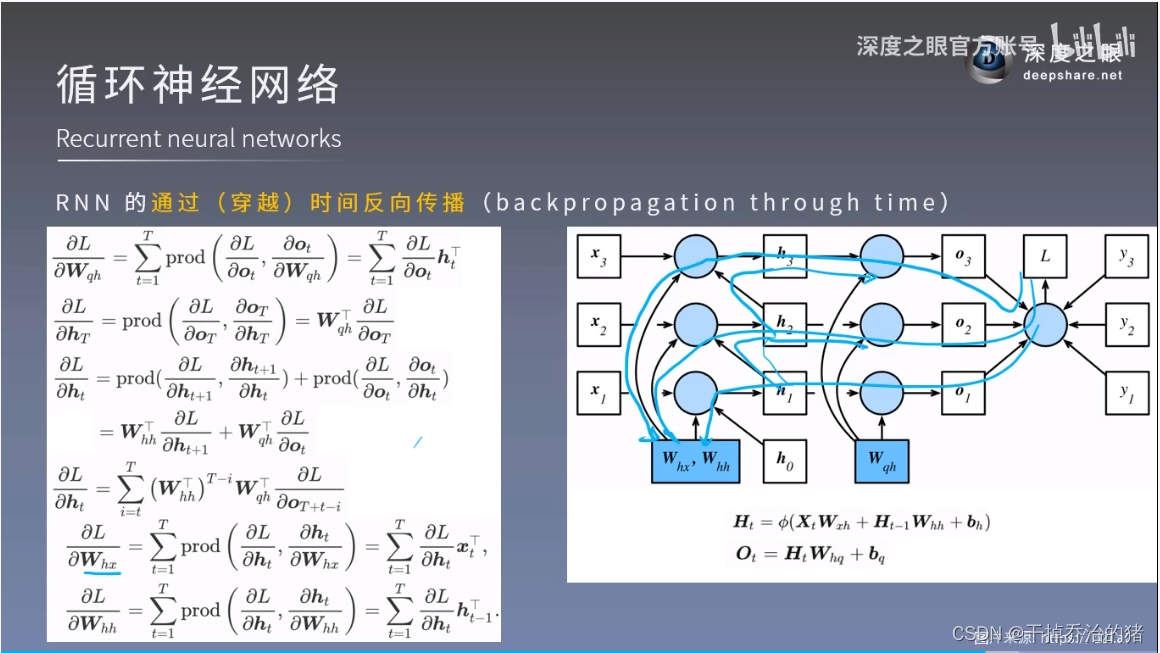
2.循环神经网络的模型参数数量不会随着时间步的增加而增强RNN的通过(穿越)时间反向传播:
公式:
∂ L ∂ h t = ∑ i = 1 T ( W h h T ) T − i W q h T ∂ L ∂ O T + t − i \color{red}\frac{\displaystyle\partial {L}}{\displaystyle\partial h_t} = \sum_{i=1}^{T}(W_{hh}^T)^{T-i}W_{qh}^T\frac{\partial L}{\partial O_{T+t-i}} ∂ht∂L=i=1∑T(WhhT)T−iWqhT∂OT+t−i∂L
∂ L ∂ W h x = ∑ t = 1 T p r o d ( ∂ L ∂ h t , ∂ h t ∂ W h x ) = ∑ t = 1 T ∂ L ∂ h t x t T \color{red}\frac{\partial L}{\partial W_{hx}} = \sum_{t=1}^Tprod(\frac{\partial L}{\partial h_t},\frac{\partial h_t}{\partial W_{hx}}) = \sum_{t=1}^T\frac{\partial L}{\partial h_t}{x_t}^T ∂Whx∂L=t=1∑Tprod(∂ht∂L,∂Whx∂ht)=t=1∑T∂ht∂LxtT
∂ L ∂ W h h = ∑ t = 1 T p r o d ( ∂ L ∂ h t , ∂ h t ∂ W h h ) = ∑ t = 1 T ∂ L ∂ h t h t − 1 T \color{red}\frac{\partial L}{\partial W_{hh}} = \sum_{t=1}^Tprod(\frac{\partial L}{\partial h_t},\frac{\partial h_t}{\partial W_{hh}}) = \sum_{t=1}^T\frac{\partial L}{\partial h_t}{h_{t-1}}^T ∂Whh∂L=t=1∑Tprod(∂ht∂L,∂Whh∂ht)=t=1∑T∂ht∂Lht−1T
梯度随时间t呈指数变化,容易引发梯度消失和爆炸
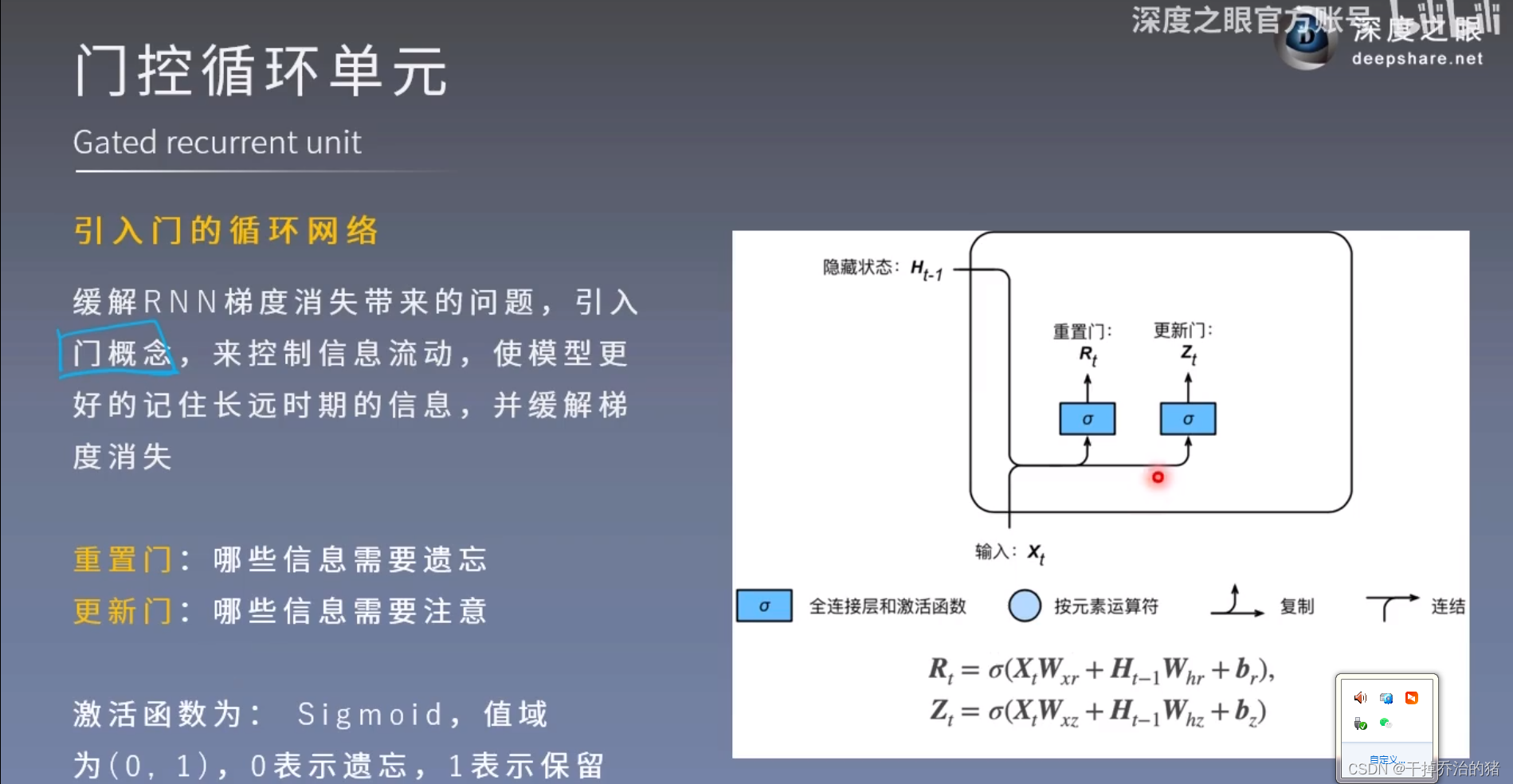
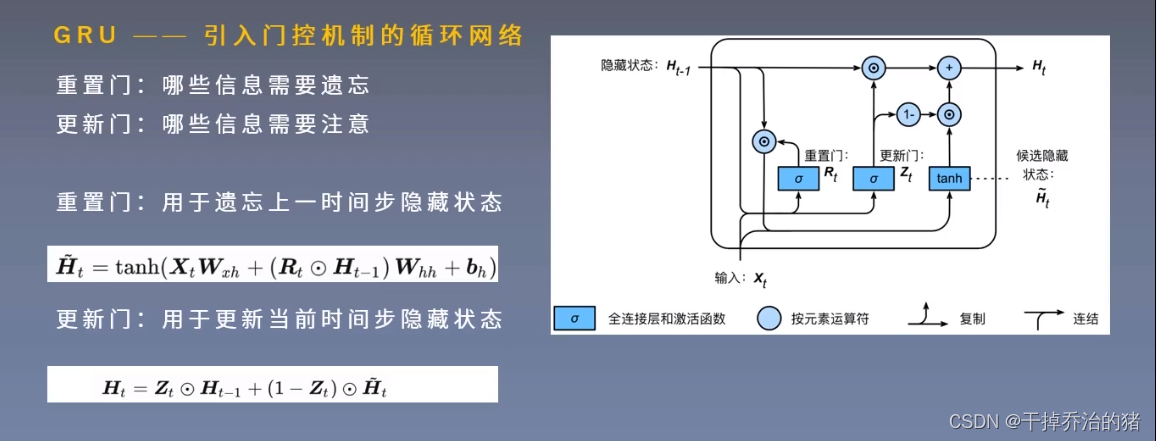
4.GRU-门控循环单元
1.引入门的循环网络
需要注意的是:
1.门控循环单元是为了解决RNN梯度消失的问题!
2.重置门和更新门的计算公式里,四个权重参数是不一样的!
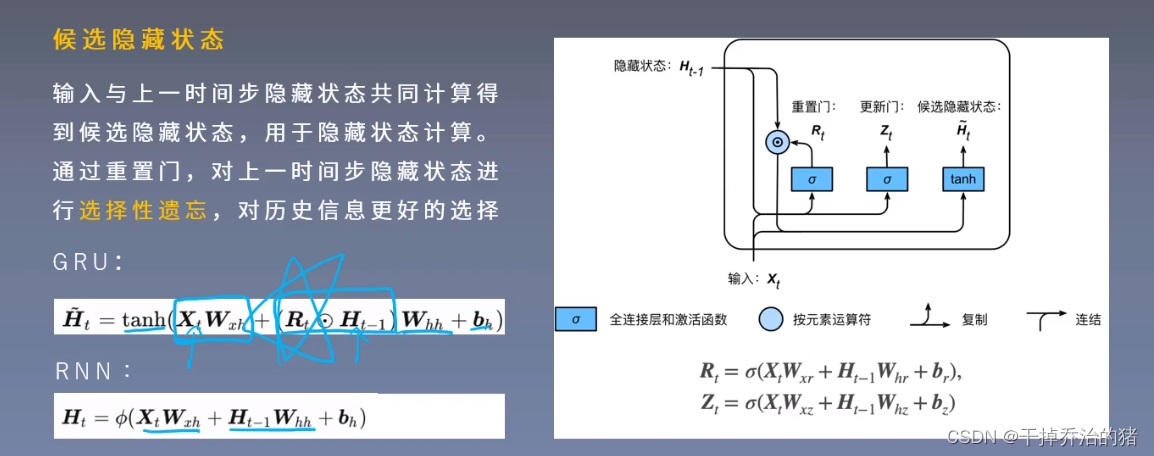
3.此处使用的激活函数是Sigmoid函数!2.候选隐藏状态
用来辅助计算隐藏状态的!
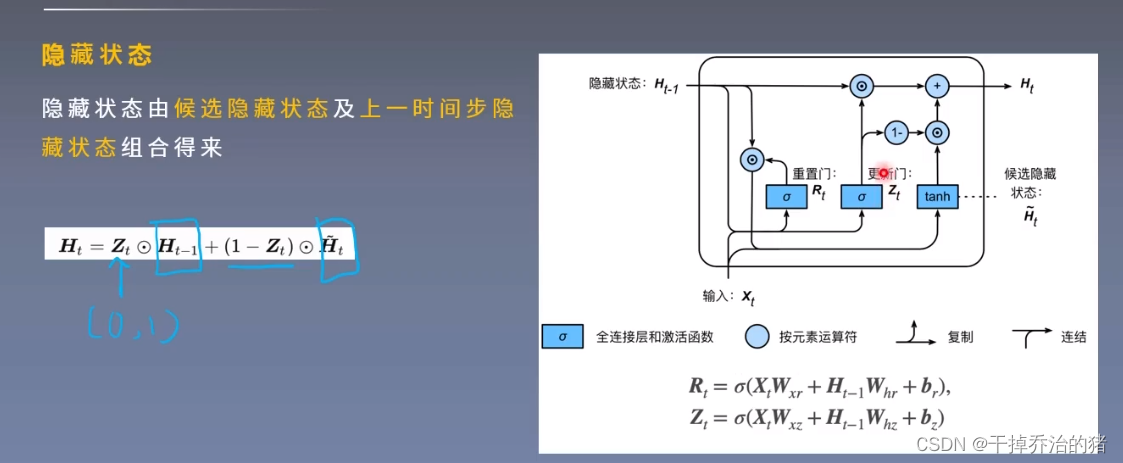
Tips:RNN最终的隐藏状态 = 候选隐藏状态 + 上一时间隐藏状态组合
3.GRU
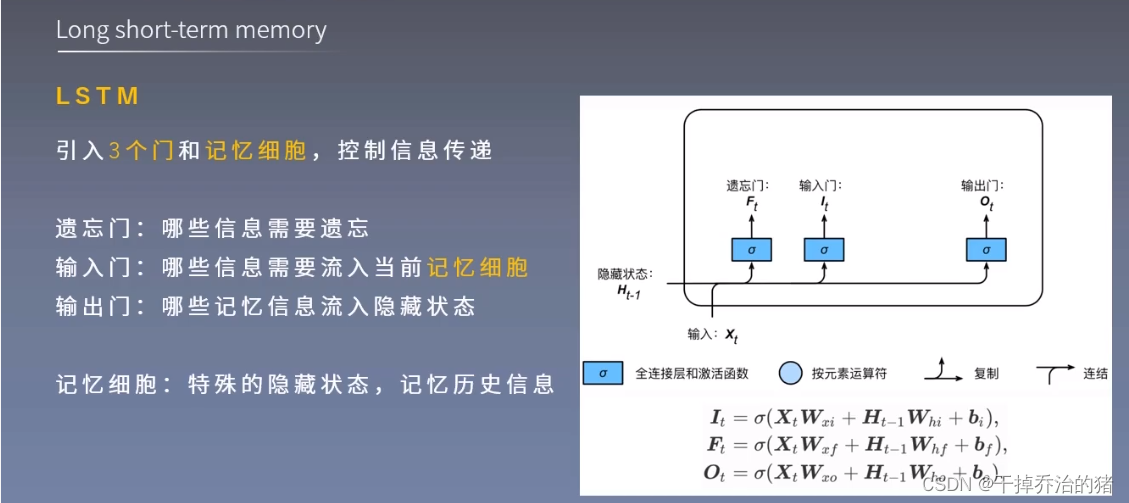
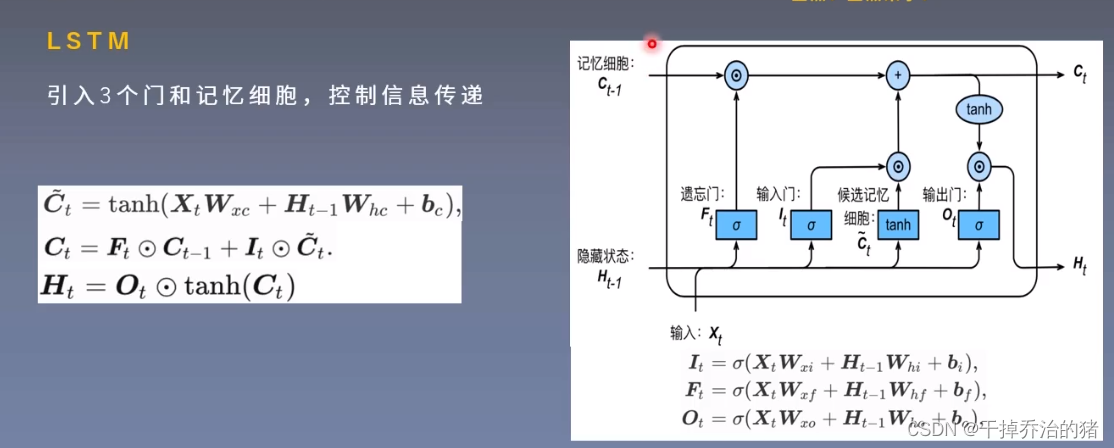
5.LSTM-长短期记忆网络
1.三个门
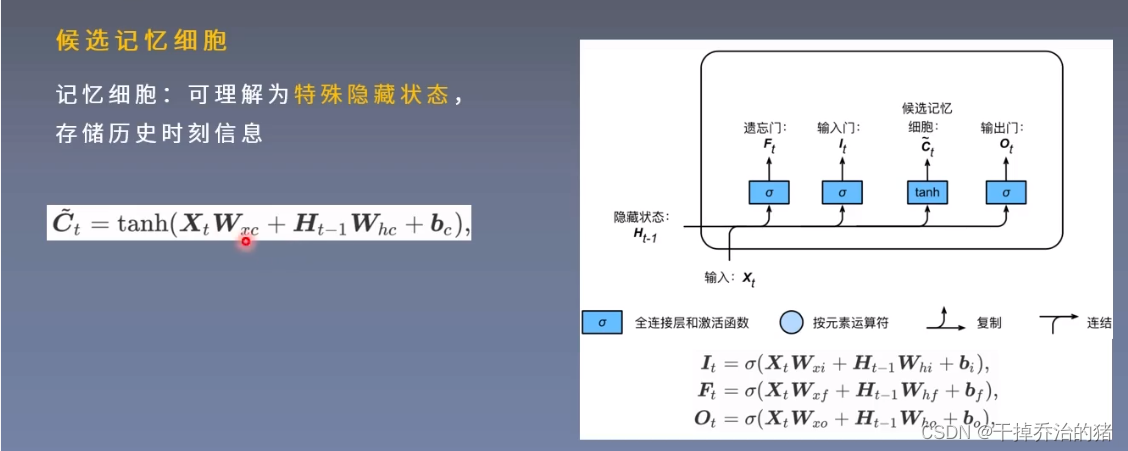
2.候选记忆细胞
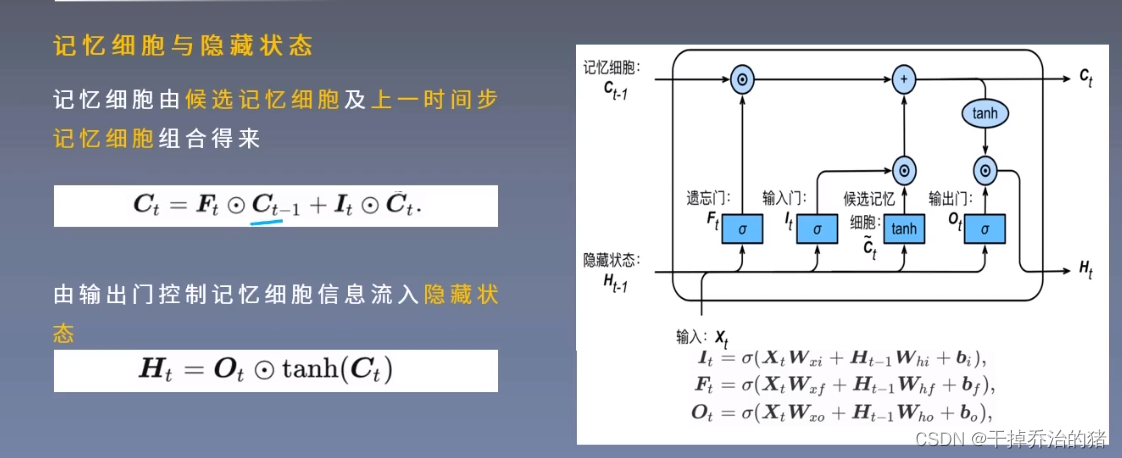
3.记忆细胞和隐藏状态
4.LSTM
















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









