








单位:华东师范大学, 斯坦福, JHU, 港大等
代码:https://github.com/Cccccczh404/H-SAM
论文:https://arxiv.org/abs/2403.1827
📜 研究背景 现状 目标
Tips: 问题提出的背景,国内外现状如何,目标是什么?
⚙️ 背景
SAM应用在医疗图像上很难,需要大量的训练和医疗图像进行微调,或者需要高质量的提示。深度学习模型需要在大型注释数据集上进行广泛的训练,而这一资源在医学领域往往很难获得。
💡 现状
SAM有显著的零样本学习能力,很适合应用在医疗图像上。但是因为训练都在自然图像上,在医疗图像上现在表现不是很好。
🚀 目标
这种方法使SAM能够有效地集成学习到的医学先验,促进对有限样本的医学图像分割的自适应。为了提高模型的通用性和适应性,同时避免依赖于密集的专家知识和大量的训练资源。
🔁 研究内容
🧩 数据
训练集
-
Synapse数据集:用于多器官分割的数据集,来源于MICCAI 2015 Multi-Atlas Abdomen Labeling Challenge。训练集包含2212个轴向增强的腹部CT图像。
-
LA数据集:来自2018年房室分割挑战赛,共包含100个3D心房MRI扫描,其中80个用于训练,20个用于测试。
-
PROMISE12数据集:来自前列腺MR图像分割2012挑战赛,包含50个3D横断面T2加权MR前列腺图像。
验证集
同样的以上3个
损失函数:结合了Dice损失(权重为0.9)和MSE损失(权重为0.1),并引入了两阶段的超参数λw,从0.4逐渐衰减到0。
👩🏻💻 研究方法
本文介绍了H-SAM:通过简化的两级分层掩码解码器集成医学知识,同时保持图像编码器冻结。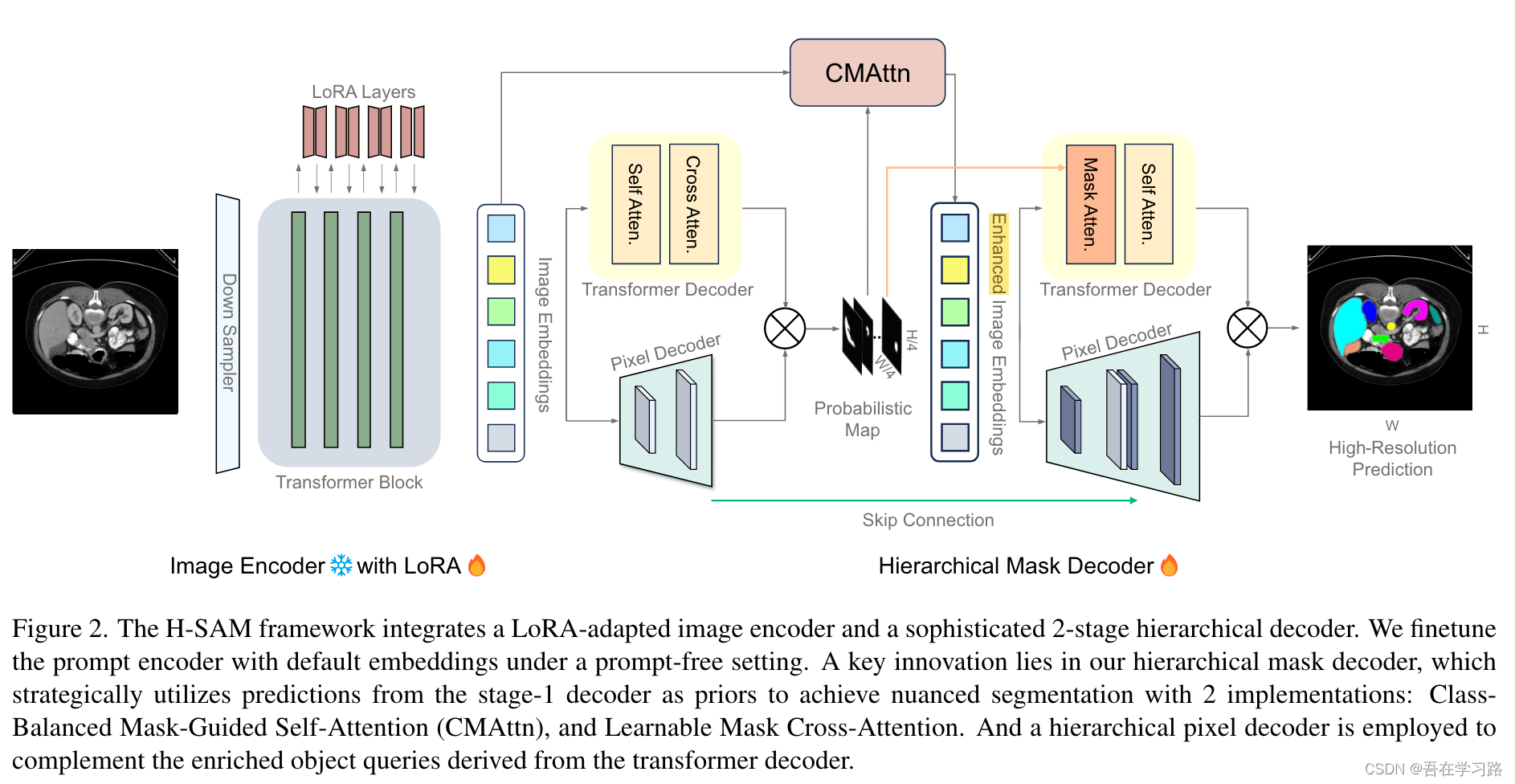
在初始阶段,H-SAM使用SAM的原始解码器来生成先前的概率掩码,从而在第二阶段指导更复杂的解码过程。具体来说,提出了两个关键设计:
1)一种类平衡的、掩模引导的自注意机制,解决了标签分布不平衡的问题,增强了图像嵌入;
2) 一种可学习的掩模交叉注意力机制,基于先前的掩模在空间上调制不同图像区域之间的相互作用。
此外,在H-SAM中包含分层像素解码器提高了其捕获细粒度和局部细节的熟练程度。
🔬 实验
1、Dice系数的改进:H-SAM在使用仅10%的2D切片进行多器官分割任务时,平均Dice得分提高了4.78%,相比于现有的无提示SAM变体来说是显著的改进。
2、与现有方法的比较:在不使用任何未标记数据的情况下,H-SAM甚至超过了依赖大量未标记训练数据的最新半监督模型。
3、具体器官分割性能:在前列腺和左心房分割任务中,仅使用3到4个案例进行训练的情况下,H-SAM达到了87.27%和89.22%的Dice得分,这突显了其在医学成像应用中的潜力。
4、数据集上的性能:
- 在Synapse数据集上,H-SAM在少量样本设置下的平均Dice系数达到了80.35%,明显优于其他SAM变体和最新的医学分割网络。
- 在LA数据集上,使用4个标记扫描进行训练,H-SAM的Dice系数为89.22%,表现优于半监督方法。
- 在PROMISE12数据集上,H-SAM在少量样本设置下的Dice系数为87.27%,也优于SAM的有效适应方法。
📜 结论
H-SAM模型的主要贡献在于通过一个精心设计的分层解码策略,优化了SAM的能力,从而实现了高效且有效的医学图像分割任务适应。这一创新方向为SAM在医学图像分割领域的应用提供了强大的潜力,并且不依赖任何未标注数据就能超越最先进的半监督模型。
🤔 个人总结
Tips: 个人收获与记录?
💭 思考启发
1、分层解码策略:采用两阶段分层解码,能够更细致地处理图像的分割任务。这种策略首先利用较粗糙的分割作为后续更精细分割的先验,可以有效提升分割的准确性。对于优化自己的模型,考虑引入类似的分层或多阶段方法,可能会有助于捕捉更细粒度的特征。
2、对于数据集中不同类别样本量不平衡的情况,采用CMAttn来增强模型对尾部类别的识别。这一点提示我们,如果数据不平衡问题,可以考虑通过对特征的加权或者增强来提高模型对少数类别的识别能力。
3、在传统的掩膜注意力机制上进行改进,引入可学习的mask以提供更灵活的空间注意力引导。可以探索如何改进现有的注意力机制或引入可学习参数来提高性能。

















 2725
2725

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











