






论文(CVPR):Unleashing the Potential of SAM for Medical Adaptation via Hierarchical Decoding
源码:https://github.com/Cccccczh404/H-SAM
题目:Unleashing the Potential of SAM (释放SAM潜力)for Medical Adaptation(医学自适应) via Hierarchical Decoding(分层解码器)
SAM解码器如下,本文在图像编码和掩码解码器上都进行了较大的改进,并去处理SAM提示操作:
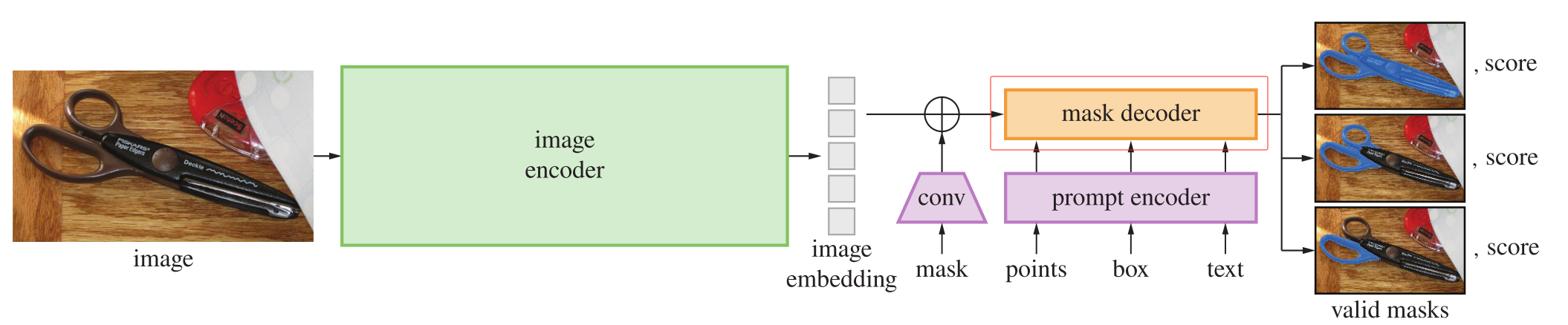
一、摘要
研究背景:Segment Anything Model (SAM) 因其强的分割能力和直观的基于提示的界面而受到广泛关注。
研究问题:然而,它在医学成像中的应用带来了挑战,需要大量的训练成本和大量的医学数据集来进行全模型微调,或者需要高质量的提示来获得最佳性能。
主要工作:本文提出H-SAM,一种无需提示的自适应SAM,通过两阶段分层解码过程对医学图像进行高效微调。在初始阶段,H-SAM利用SAM的原始解码器生成先验概率掩码(像素属于目标类的概率),指导第二阶段更复杂的解码过程。提出两个关键设计:
- 1)一个类别平衡的掩码引导的自注意力机制,解决标签分布不平衡的问题,增强图像嵌入;
- 2)基于先验掩码的空间调制不同图像区域之间相互作用的可学习掩码的跨层注意力机制。
此外,H-SAM中包含的分层像素解码器增强了其捕获细粒度和局部细节的能力。该方法能够有效地融合已学习的医学先验知识,增强对有限样本医学图像分割的自适应性。(结论)
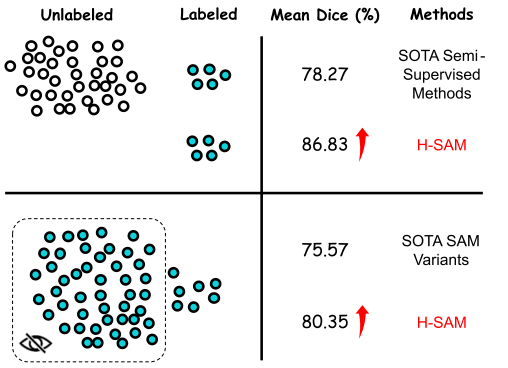
实验结果:与现有的用于多器官分割的无提示SAM变体相比,H-SAM的平均Dice提高了4.78%,仅使用10%的 2d 切片(器官图像)。值得注意的是,在不使用任何未标记数据的情况下,H-SAM甚至依靠各种医疗数据集的大量未标记训练数据,胜过最先进的半监督模型。
二、引言
背景概述(医学图像分割精度的意义、作用)——> SAM简介(优点、不足:在医学图像上表现效果衰减,在训练过程中缺乏医学图像)——> 前人工作(针对SAM在医学图像上的不足,前人工作主要集中在将适配器层插入到图像编码器中,并对解码器进行最小程度的更改,并保留了SAM的提示机制)——> 引出SAM的提示机制的缺点(创建准确的提示需要医学专家的领域知识)——> 引出非提示SAM相关工作和不足(不足:由于提示提供的医学知识缺乏,它们通常产生比提示方法更差的结果)——> 提出本文工作:
1. 通过简化的两级分层掩码解码器来整合医学知识,同时保持图像编码器的 frozen(模型微调方法)。(补充了分层 tranformer 解码器,提高了模型的精度和捕捉局部细节的能力。)
2. 最初,输入图像由 LORA(模型微调方法)适配的图像编码器处理。H-SAM在第一阶段使用SAM原有的轻量级掩码解码器来生成先前的概率掩码,从而引导更复杂的第二解码阶段。
3. 两个关键设计:
- 一种分类平衡的、掩模引导的自注意机制(使用来自先验掩模的自注意来重新校准图像嵌入)
- 一种可学习掩码交叉注意机制(使用先验掩码在空间上调制随后的 transformer 解码器内的跨层注意力)
——> 实验结果(在大量未标记的训练数据集上表现超越了先进的半监督方法,在全监督任务中表现超越了现存的非提示SAM变体)
LoRA(调参方法):低阶自适应(LORA)主张在 transformer 模块内逐步更新参数,旨在用低秩近似来细化大规模模型。在H-SAM中,将LoRA适配器引入SAM图像编码器,以避免医学图像数据集自适应过程中的过拟合。
Freeze(调参方法):是指冻结部分参数。
三、方法
3.1 H-SAM Overview(概述)
H-SAM框架主要包括一个LoRA-adapted 的图像编码器和一个两阶段分层解码器,在第一阶段包含一个类别平衡掩码引导的自注意力(CMAttn),在第二阶段包含一个可学习的掩码跨层注意力(Mask Atten),如下图所示:
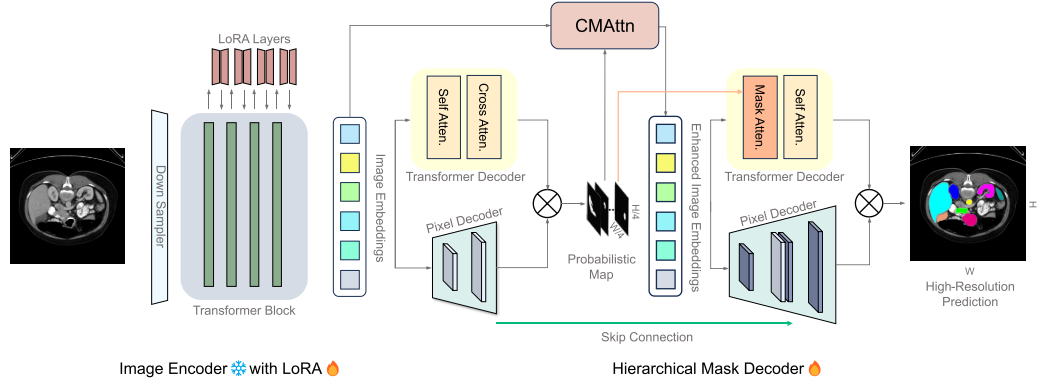
任务概述:给定大小为 W × H 的图像 I,本文的目标是预测其对应的 W × H 分割图,该图中的每个像素都被分配到预定义的类列表中的一个类别,旨在与真值最大对齐。
框架概述:分割框架 H-SAM 建立在 SAM 之上,集成了一个 LoRA-adapted 的图像编码器和一个简单但有效的两阶段分层解码器。
1)LoRA-adapted 的图像编码器
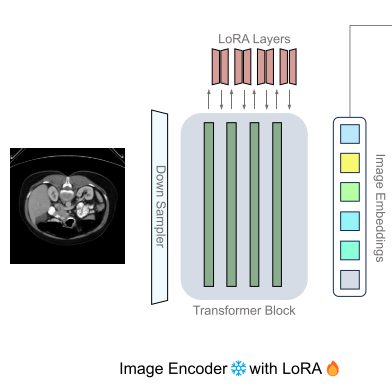
过程(LoRA + transformer):H-SAM 利用 SAM 的原始图像编码器并冻结所有层以保留预先学习到的知识。然后,采用与SAMed(前人工作)相同的 LoRA 实现来添加由两个低秩矩阵组成的较小的可训练旁支。与LoRA一致,这些旁支首先将 transformer 特征压缩到低秩空间。随后,重新投影这些浓缩的特征,以匹配冻结的 transformer 模块的输出特征通道。只有这些旁支矩阵在训练期间进行更新,从而允许进行较小但有效的模型调整。对于提示编码器,H-SAM不需要任何提示,只是在训练期间更新默认嵌入。
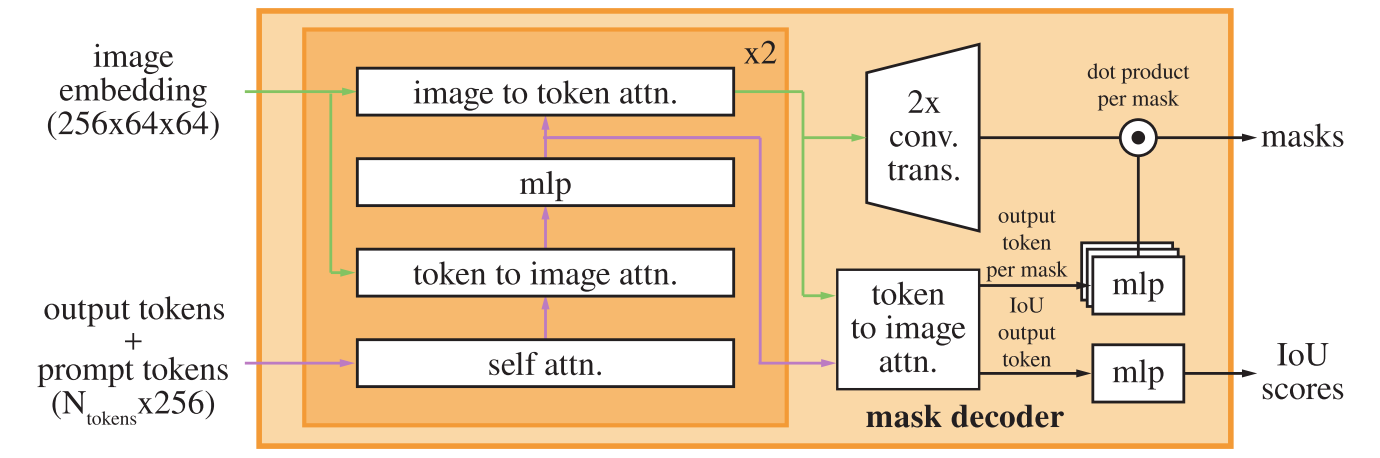
2)Mask Decoder(掩码解码器)
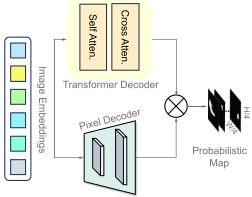
结构:(原始)SAM掩模解码器由一个 transformer 解码器和一个像素解码器组成。(没错,本文第一层解码器的设计便是参考了原始SAM的掩码解码器)
过程:
- 1. 使用自注意力机制来评估各个图像区域的重要性。
- 2. 使用交叉注意机制来聚焦相关区域进行分割。
- 3. 像素解码器细化该输出,生成详细的分割图,并为每个像素分配一个类(class)。
3)Hierarchical Decoding(分层编码器)
分层解码H-SAM引入了一个更复杂的两阶段分层解码过程。
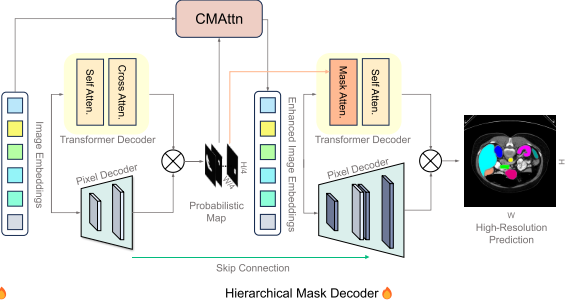
过程:
1> 第一阶段,H-SAM利用SAM的原始解码器生成一个先验(概率)掩码,该掩码将用于指导第二阶段更复杂的解码。
2> 第二阶段,他的第二阶段与第一阶段相似,既有变压器解码器,也有像素解码器。为了增强图像嵌入输入并在第二个Transformer解码器中优化跨层注意力,引入了两个新的模块。
- 首先,提出了一种类别平衡的、掩码引导的自注意力机制(CMAttn),以纠正标签分布不平衡的问题,从而增强第二层Transformer解码器的图像嵌入。
- 在第二个Transformer解码器中加入了一个可学习的掩码跨层注意力机制(Mask Atten)。这种机制在先验掩模信息的指导下,巧妙地调节不同图像区域之间的空间动态,从而增强分割过程。
这些解码器共同构成了一个层次化的Transformer解码器框架。具体来说,第二阶段的像素解码器通过跳连接集成了第一阶段像素解码器的特征,从而能够生成高分辨率的预测。
3.2 Enhanced Image Embedding(增强图像嵌入)via Class Balanced Mask-Guided Self-Attention(类别平衡的、掩码引导的自注意力机制)
头部类别和尾部类别:头部类别具有较多样本实例,尾部类别则具有较少样本 。
长尾问题:类别实例之间存在不平衡的问题。
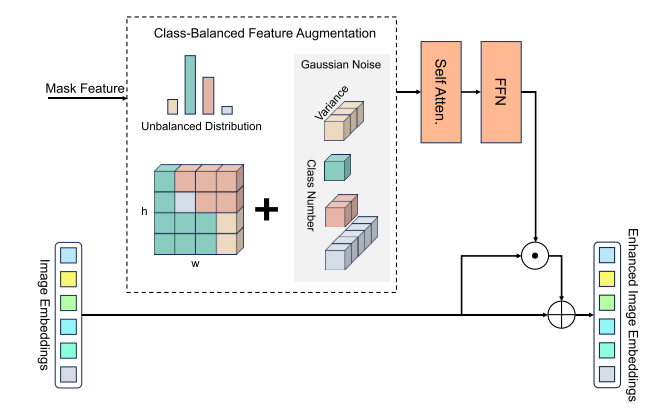
作用:当头部类别的丰富实例和尾部类别的缺乏实例之间存在不平衡时(长尾问题),这尤其有用。
输入:使用掩码特征作为CMAttn的输入掩码特征(第一阶段输出)。
过程:在自注意力模块之前,采用类别平衡增强来为尾部类别引入更多变化。受之前在长尾问题中使用logit调整的方法的启发,用高斯噪声扰动掩码特征,其方差与类别样本频率成反比:
![]()
其中,是归一化输入掩码特征。GT是调整到相同大小的真值掩码。N 是相加的高斯噪声。var 是方差列表。
然后,进行自注意力计算,采用一个线性层来压缩通道维度,并使用Hadamard乘积将得到的掩码特征纳入输入图像嵌入中。设计残差路径以保留初始图像嵌入的信息。
3.3 Learnable Mask Cross Attention(可学习掩码跨层注意力)
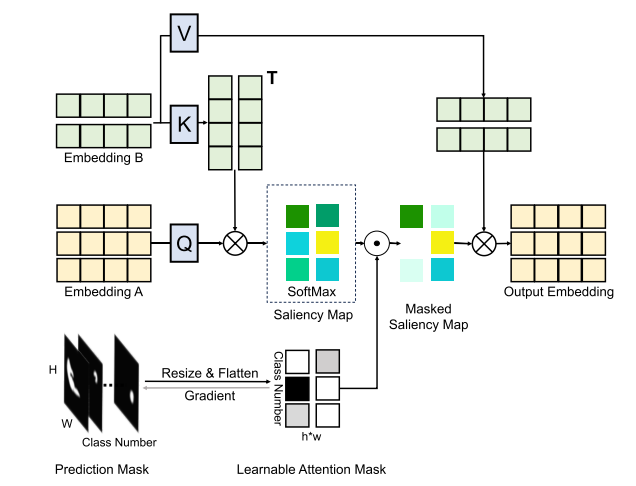
方法:与关注全局语义的跨层注意不同,掩码注意力只作用于预测掩码内的区域。
前人方法过程(Mask2Former):(原始掩码转换插入跨层注意力):掩码注意力通过以下方式将转换后的二进制掩码添加到跨层注意操作中:
![]()
其中,X是transformer模块的输入查询特征。K、Q、V是跨层注意力中的键、查询和值。t(M)是将二进制输入{0,1}映射到{−∞,0}的函数。
问题:该掩码公式具有两个局限:(1) 掩码M的梯度会通过 t(M) 而消失;(2) 二值化的掩码 M 不加区分地对待所有前景像素,限制了其从先验掩码解释更多信息的能力。
本文方法过程(解决原始掩码的局限):为了解决这些限制,本文提出了可学习掩码交叉注意力,该算法采用了一个未变换的概率图 M,并将其调整为与跨层注意力中的 saliency map 相同的空间分辨率。通过掩码和 saliency map 之间的元素乘积,背景区域将通过乘以接近零的概率被忽略。第二层 transformer解码器中的可学习掩码交叉注意力利用了概率图中的更多信息,可以为不同的前景区域分配不同的重要性程度。它可以表示为:
![]()
3.4 损失函数
训练损失由像素分类损失和二进制掩码损失组成:
![]()
其中,像素分类损失 和
分别表示二进制交叉熵损失和骰子损失。对于本文的两阶段分层结构,在每个阶段都有一个
参数。最终损失
是
和
的总和。
四、实验
4.1 数据集和评估指标
数据集:Synapse multi-organ CT 数据集, the left atrial (LA) 数据集和 PROMISE12数据集。
评估指标:Dice系数和平均Hausdorff距离(HD)作为评价指标。
4.2 实验细节
实验设备:所有的实现都是在PyTorch上实现的,在4个NVIDIA RTX A5000 GPU上训练我们的所有型号。
数据增强方法:在训练过程中,采用了弹性变形、旋转和缩放的数据增强组合。
损失函数:训练损失是交叉熵损失和骰子损失的组合。
LoRA调参配置:采用与SAMed相同的LoRA设置,其中LORA的等级设置为4。
训练模式:分别采用VIT-B和VIT-L骨干进行少样本和全监督训练。为了进行公平的比较,我们使用与其他SAM变体和SOTA方法相同的224×224分辨率对Synapse进行完全监督训练。
训练周期:最大训练周期设置为300。
优化方法:用于更新的优化器算法基于ADAMW,β1、β2和权重衰减设置为0.9%、0.999和0.1。
4.3 定量结果
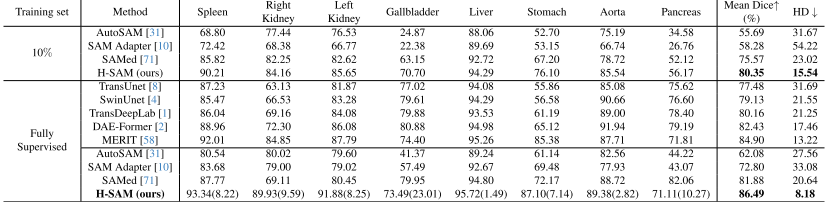
对比网络:ransUnet、SwinUnet、TransDeepLab、DAEFormer和MERIT,以及其他SAM无提示设置变体,如Auto SAM、SAM Adapter和Samed。
对比结果:本文的方法在多器官分割中取得了令人满意的结果,平均Dice系数为86.49%,高于最新发布的医学分割网络DAE-FORFER(82.43%)和PRIMITE(84.90%)。H-SAM的表现也轻松超过其他无提示的SAM变体(86.24%对81.88%)。
4.4 定性结果
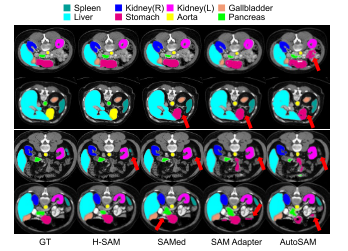
对比网络:H-SAM与其他非提示医疗SAM变体进行了比较,包括AutoSAM、SAM Adapter和SAMED。
对比结果:与其他SAM变体相比,H-SAM以更低的噪声提供了精确的掩码预测。在第二行中,其他方法将主动脉和胰腺误认为胃和主动脉,H-SAM提供了正确的每个器官的类别属性。H-SAM在小器官方面的表现也很好。在第三排,虽然所有其他变体都没有脾,但只有H-SAM对所有器官都能提供正确的预测。
4.5 消融实验
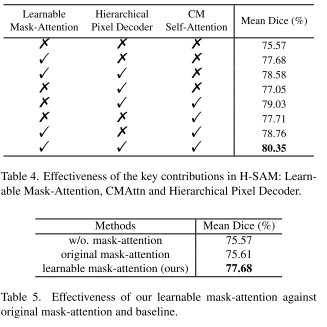
1)可学习掩码跨层注意力的有效性研究
对比对象:基线,正常跨层注意和不可学习掩码注意力。
对比结果:如表,可学习掩饰注意力使基线提高了2.1%。本文还比较了表5中的可学习掩码跨层注意力与正常跨层注意和不可学习掩码注意力。值得注意的是,由于缺乏梯度反向传播,不可学习掩码注意力操作带来的改善很小。相反,提出的可学习掩码跨层注意力在联合训练和继承掩码引导的先验知识的情况下,立即带来2.1%的性能提升。
2)CMAttn的有效性
对比对象:基线和原始掩码注意力。
对比结果:仅CMAttn一项就为基线带来了1.2%的改进,表明SAM受益于更多信息的图像嵌入作为掩码解码器的输入。与可学习掩蔽注意相结合,两种掩码引导的实现在均值dice指标方面将基线模型提高了3.2%。
五、结论
主要工作:提出了一种简单高效的分层掩码译码算法H-SAM,用于医学图像分割中的分段任意模型自适应。H-SAM算法使用默认掩码的概率图来指导连续的解码单元中更精细的医学分割,从而提出了SAM自适应的新方向。
实验结果:值得注意的是,H-SAM在不依赖任何未标记数据的情况下实现了这种卓越的性能,甚至超过了在各种医学成像环境中使用大量未标记数据集的最先进的半监督模型。
评价:这突显了H-SAM在推进医学图像分割领域的巨大潜力,提供了一个健壮、高效和数据经济的解决方案。


















 2603
2603

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











